就在大家都在琢磨元旦節怎麼玩的時候,阿里通義實驗室又悄悄往桌上扔了兩顆深水炸彈。
通義 Qwen3-TTS 家族一次性更新了兩款模型:一個負責音色創造的 VD-Flash,一個負責音色克隆的 VC-Flash。
名字聽着平平無奇,但你且聽我細細道來,你就會發現這次確實有點超前。
過去玩 AI 語音,路子其實很窄。要麼從廠商給的幾個預設音色裏挑一個不那麼“機器人”的,要麼丟一段現成錄音,讓 AI 照着模仿。但 Qwen3-TTS 這次明顯想得更遠——它想讓你直接用嘴“畫”出一個聲音。
先說 Qwen3-TTS-VD-Flash。
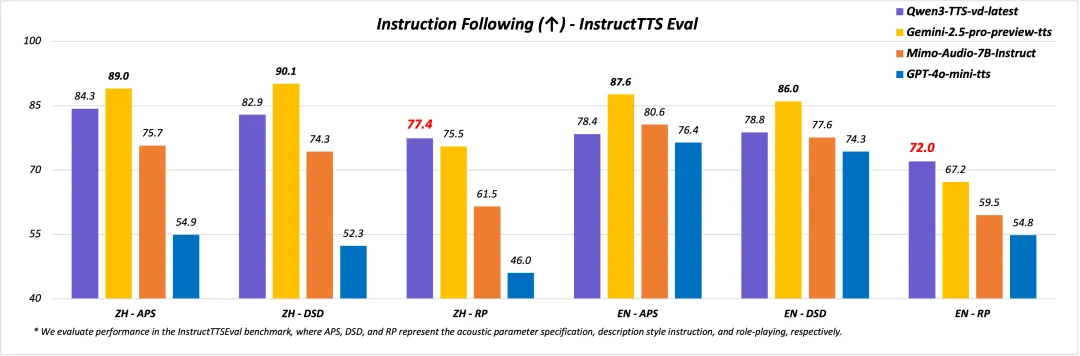
VD 就是 Voice Design,你不需要任何素材,只要一段自然語言描述。比如“身形挺拔、兩鬢斑白、語氣裏帶着幾十年風雨的國家老科學家”,或者“內心邪惡但非要裝成蘿莉賣萌的女魔頭”。只要你描述得夠具體,AI 就能把人設、情緒和那點說不清的“氛圍感”一起還原出來。

這其實是一次關鍵跨越——從“說什麼”升級到“怎麼說”。
官方測試裏,這個音色創造模型在角色扮演和指令遵循上,已經把 GPT-4o-mini-tts 和 Gemini 甩在了後面。
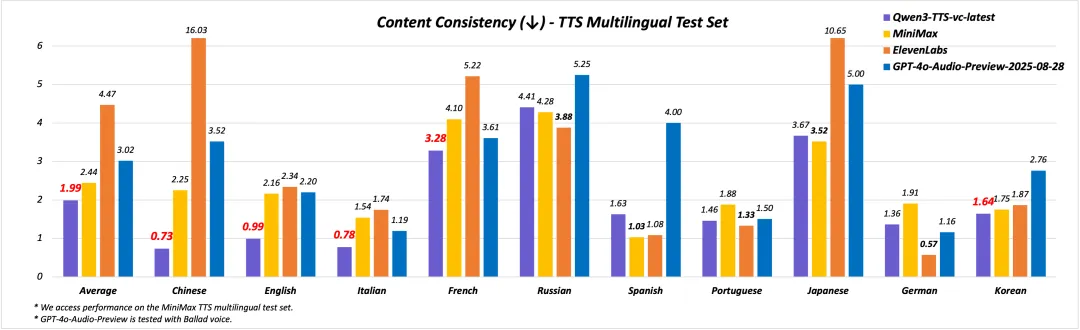
AI 對人類語言中那些細微的情緒起伏,理解得已經相當深了。
但真正讓我覺得事情開始變得“離譜”的,是 VC(Clone克隆)-Flash。
音色克隆本身不新鮮,三秒樣本學個七八成像已經是行業常態。但 Qwen3-TTS 展示了一個非常清奇的方向:跨物種克隆。比如你家狗汪了兩聲,錄下來,AI 就能用它的“聲線”開口說人話。
你可以想象一下,你家的狗,用略帶不耐煩的語氣抱怨你怎麼還沒開飯;或者你家的貓,嘟囔着讓你別打擾它午睡。
曾經聽着像科幻片的事情,現在的 Qwen3-TTS 模型真能做到。
這對技術的要求其實很高。動物叫聲本身就是高度“野生”的音頻,背景嘈雜,聲帶結構又和人類完全不同。AI 需要從非人類信號裏抽取聲學特徵,再遷移到人類語言體系中, Qwen3-TTS 不只做到了,還能在中英法德等十種語言之間無縫切換(我家的狗會說八門外語!)。

更實用的一點在於穩定性。很多 TTS 遇到公式、代碼、生僻字或者拼音混排就會翻車,但 Qwen3-TTS 能把這些看着就頭疼的內容順暢讀出來(其實我都不會讀)。
對做知識類視頻、論文播報的人來說,之後連自己配音都不需要了,用模型配出來的聲音又快又真實,效率直接再提高一截。

在多語種評測中,它的詞錯誤率拿到了第一,阿里的語音技術,已經能和不少國際一線廠商正面掰手腕了。
但問題也隨之而來。
當聲音可以被隨意設計和克隆,甚至連你家貓都能“開口說話”時,耳聽爲實正在迅速失效。如果 AI 只憑一段人設描述,就能生成一個你從未聽過卻極其真實的聲音,我們該如何重新定義何爲真實。
再往前一步,跨物種克隆一旦普及,真假難辨的萌寵內容,可能會直接改變短視頻生態。(更多的 AI 答辯視頻)
另一個繞不開的問題是創作邊界。
當 AI 生成的音色在表現力上超過普通配音演員,它究竟是在提升創作效率,還是在擠壓人類藝術家的空間。低成本生成多角色、高情緒密度的內容在商業上幾乎無可替代,但它是否還能保留應有的情感價值,仍然值得討論。
最後,阿里這次推出的 Qwen3-TTS,我覺得是在拋出一種新可能:聲音不止是固定的數字信號,還可以是一種可以被深度定製、隨意調度的設計元素。無論是給遊戲角色配音,還是讓你家主子“開口說話”,技術門檻已經低到只要會敲字就行。

這種技術爆炸的爽感確實讓人上頭。但新鮮感退去之後,我們如何在一個充滿定製音色的世界裏,找到真正不可複製的震顫,可能纔是阿里留給我們的下一個難題。
現在的 AI 已經能讓豬開口說話了。
等哪天它讓路邊的石頭給你講個笑話,屆時估計我也不會太驚訝。
這個世界被重新定義的速度,已經快到我們來不及眨眼。
我是 CyberImmortal,關注我們,帶你暢遊AI世界!

Qwen3-TTS 更新博客:
https://qwen.ai/blog?id=qwen3-tts-vc-voicedesign
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













![[6.27]夏促來襲!超多骨折!百款史低新史低這次你一定要入庫!](https://imgheybox1.max-c.com/web/bbs/2026/06/26/bfb8adfbb675422149a024f4b7064470.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)



