說真的,我第一眼看到這篇論文的時候,
我真的以爲是誰在惡搞開玩笑,要麼就是出來騙的。
還以爲是哪個煉丹佬重雲之後產生的幻覺。
之前但凡折騰過AI視頻生成的人都懂:開始生成任務後,去搞點別的是基本操作。
回來能看到幾秒視頻算你運氣好,運氣差點,可能只等來一個顯存溢出/流程錯誤的報錯,改完了又得重新生成重新等。
可在那份剛出爐的技術報告裏,清華大學、生數科技和加州大學伯克利分校的一羣研究員,幾乎是用不講道理的方式,把視頻生成的速度給硬生生提了一大截。

他們爲這個框架起的名字頁絲毫沒有辜負其性能:TurboDiffusion (渦輪增壓式擴散模型)。

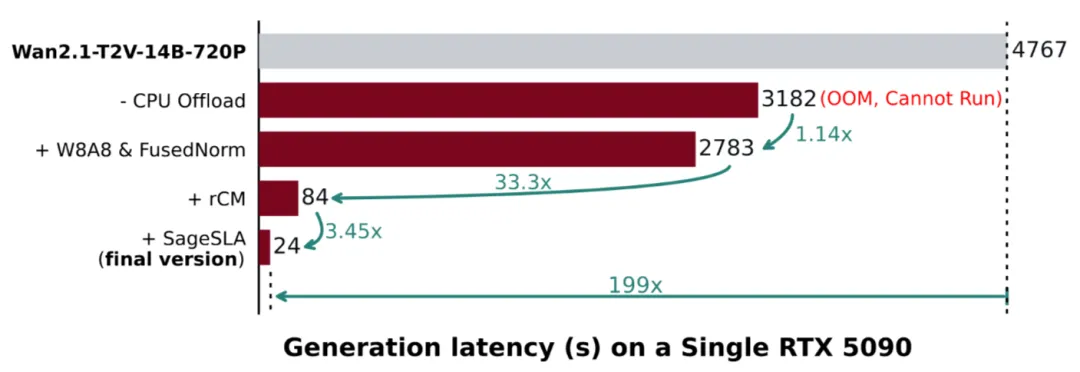
實驗平臺是一張 RTX 5090(甚至都不是 RTX 6000Pro)。
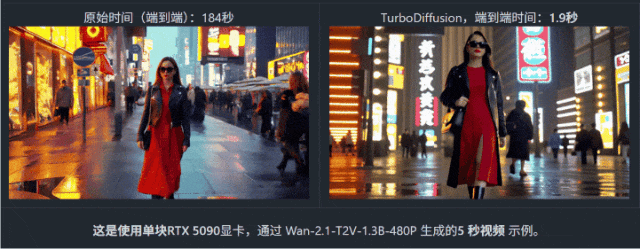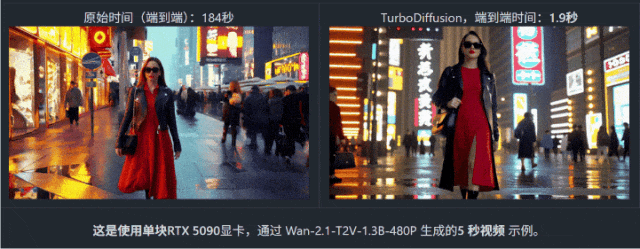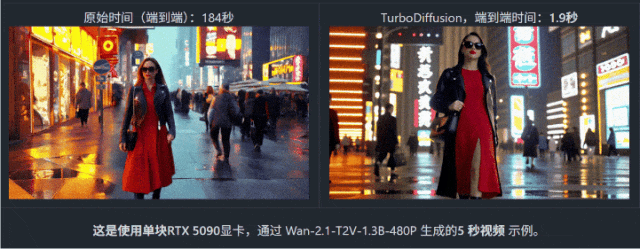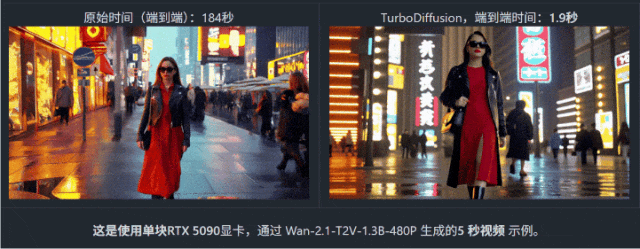
在 Wan2.1 (阿里通義萬相 2.1視頻生成模型)上生成一段 5 秒視頻,原本需要 184 秒——刷幾條短視頻綽綽有餘。但在 TurboDiffusion 加持下,耗時直接被壓到 1.9 秒。
不是快一倍、十倍,而是一百倍以上!什麼概念?很多生圖模型都沒它快!甚至你網速慢一點甚至沒它生成出來的快!
這意味着視頻生成,正在向工業流水線轉變。以前要做一個AI視頻,可能需要大半天,但是現在,也許10分鐘就能搞定。
那麼,他們到底往模型到底怎麼實現的?
邏輯其實不復雜,主要動了三刀。
第一刀,砍在注意力機制上。
視頻模型慢,很大一部分原因就是注意力太喫算力。
他們引入了低比特的 SageAttention,相當於給計算過程換了一套更省力的做法,在幾乎不損失畫質的前提下實現插件級提速。同時配合 SLA(稀疏線性注意力),讓模型在超長序列下也能輕裝上陣。
第二刀,是把擴散步數濃縮了。
傳統擴散模型,本質就是反覆去噪,動輒幾十上百步。TurboDiffusion 用的是 rCM 步數蒸餾,原本要走一百步的路,被硬生生壓縮成三五步。
第三刀,直接對參數動手。
他們採用 W8A8 量化,把模型參數壓到 8 位,不僅算得更快,顯存壓力也直接鬆了一大口。
同時,這一整套方案已經全家桶式開源了。模型權重、訓練代碼、推理腳本,全都擺在 GitHub 上。大家可以去共同完善,有了社區支持,會讓框架變得更完美。

這對普通開發者和個人創作者來說,幾乎是天上掉餡餅,純福利。
以前想玩視頻生成,得租服務器、燒算力,財力不雄厚,根本玩不轉;現在一張頂級民用顯卡,就能體驗接近實時的創作反饋。
這種技術紅利的釋放,科技平權這詞的含金量在此時被無限放大。

使用通義萬相2.2生成
不過呢,
大家冷靜下來想一個問題:當視頻生成真的進入“秒級時代”,那些靠賣算力、賣等待時間盈利的公司,那不就完蛋了嘛?
以前一段 AI 視頻能火,是因爲大家默認它背後燒了大量算力和耐心;可當兩秒鐘就能出一個,創作門坎被無限降低。
對創作者來說,終於熬到春天了,效率不再束縛靈感;但我也擔心,這會帶來一場更嚴重的視覺垃圾氾濫。
當門檻低到幾乎不存在時,真正值錢的,就不是視頻本身了。更值錢的東西就是那自動化無法複製的創意原點。
清華這波操作,不只是把視頻生成加速,整個行業的成本結構都撬鬆了。
當算力不再是瓶頸、速度快到可以忽略,人還能拿什麼作爲自己的核心競爭力?
這,或許纔是 TurboDiffusion 真正丟給整個行業的問題。
(論文與GitHub地址在下方。)
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
GitHub:
https://github.com/thu-ml/TurboDiffusion
論文:
https://arxiv.org/pdf/2512.16093
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com












