这就很DeepSeek。
没有发布会,没有预热视频,连张像样的倒计时海报都没有。就在大家还在回味前段时间各家大模型乱斗带来的震撼时,DeepSeek在昨天——也就是12月1日,搞了一波“偷袭”。
这次他们也不跟你废话,直接甩出来了两个新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。
说实话,这帮人确实有点“不讲武德”。
你看隔壁Sam Altman,发个GPT-5.1恨不得把地球都摇匀了再通知你,DeepSeek倒好,每次都是等各家都把大模型发差不多了,然后越共探头,直接把模型往那一扔,技术报告一丢。
然后说:东西在这,爱用不用,我要去训练下一个了。
先说说这个 DeepSeek-V3.2。
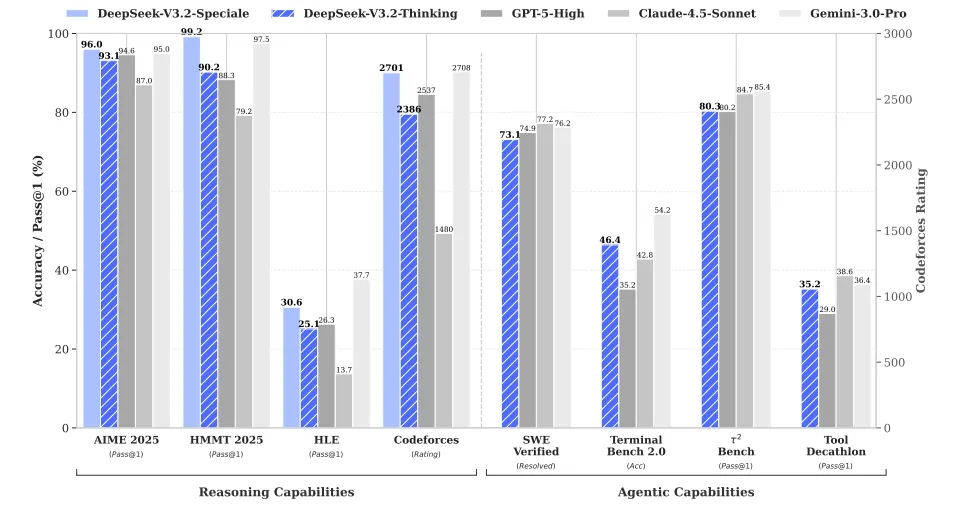
官方的说法是,这个版本平衡了推理能力和输出长度,适合咱日常拿来当聊天搭子或者干点正经活。我看了一下技术报告里的数据,这家伙在推理能力上已经摸到了GPT-5(就是8月份出的那个)的屁股,仅仅略微输给谷歌那个刚出的 Gemini-3.0-Pro。
最关键的是,它解决了一个痛点。
之前的思考模型(比如R1或者K2-Thinking)都有个毛病,就是啰嗦。为了想通一个问题,它们能在后台把上下五千年的逻辑都盘一遍,等你看到答案时黄花菜都凉了。V3.2 这次学聪明了,它大幅降低了输出长度,也就是“想得快了”,但脑子没变笨。
但真正让我觉得后背发凉的,是那个带后缀的家伙——DeepSeek-V3.2-Speciale。
这个词在意大利语里是“特别”的意思,但我看应该翻译成“变态”。
这个模型完全不考虑什么成本和速度,就是奔着极致推理去的。
它是个典型的“偏科生”,专门搞数学和编程。有多偏科?它在今年的国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)里都拿了金牌。
这还不算完,在 ICPC World Finals(国际大学生程序设计竞赛全球总决赛)里,它的水平相当于人类选手的第二名。
这意味着如果你把这货塞进一个编程比赛的现场,它能把绝大多数顶尖的人类选手按在地上摩擦。这已经不是“好用”的范畴了,这属于“降维打击”。
不过这玩意儿目前只给研究用,因为它思考起来消耗的算力简直是吞金兽,普通人拿来问“今天中午吃什么”不仅浪费,而且可能会破产。
除了秀肌肉,DeepSeek这次在技术上也整了点新活。
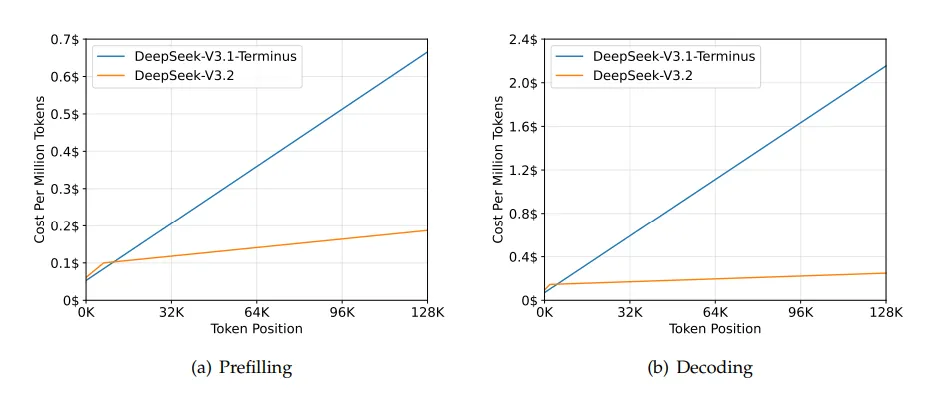
他们在报告里提到了一个叫 DSA(DeepSeek Sparse Attention)的技术。咱们都知道,大模型处理长文本特别费劲,因为字数越多,计算量是呈指数级爆炸的。DSA 简单来说就是给模型配了个“闪电索引”,它不用每次都把几万字全文背诵一遍,而是只挑相关的重点看。
这样一来,处理128K这种超长上下文的时候,计算量直接暴跌。报告里有个数据挺吓人,在长文本任务下,它的推理成本比上一代降低了好几倍。
这也解释了为什么他们敢在GPT-5.1涨价的背景下,把API的价格还能压得这么低,合着是家里真有省钱的秘方。
不过,这次更新里最让我感兴趣的,其实是“思考融入工具”这件事。
之前的推理模型有个很尴尬的短板:脑子很好使,但手脚不协调。它能给你推导出一套完美的数学公式,但你要让它顺手调个计算器算个结果,或者写段代码跑一下,它往往就歇菜了。
这就好比一个物理学家,理论无敌,但连个螺丝刀都不会拧。
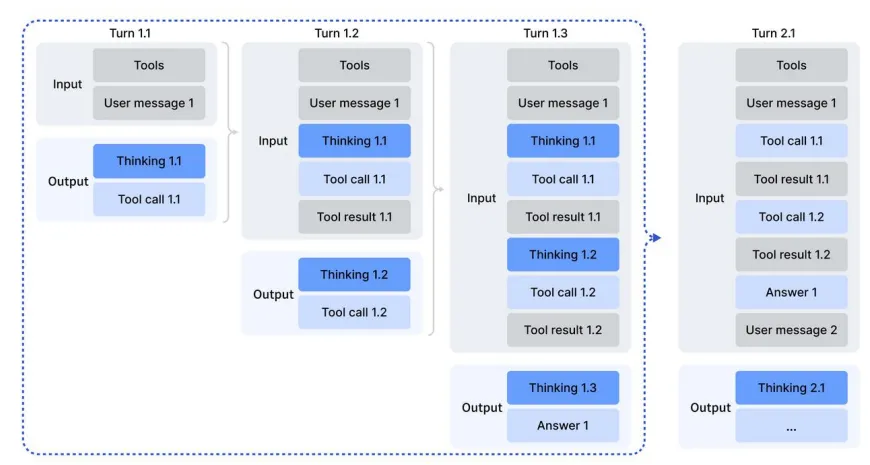
DeepSeek V3.2 这次打通了“思考”和“动手”的任督二脉。它可以在思考的过程中,发现自己算不过来,然后暂停思考,去调用外部工具(比如Python解释器或者搜索),拿到结果后接着思考。
这听起来好像没什么,但其实是质的飞跃。
以前的模型是“想完了再干”或者“干完了再想”,现在是“边干边想”。为了练成这招,DeepSeek搞了1800多个模拟环境和85000条复杂指令来特训它。
读完这份技术报告,我发现了一个很容易被忽略但极具深意的数据。
DeepSeek 提到,他们在后训练阶段(Post-Training)投入的算力,已经超过了预训练成本的10%。
这可不是个小数目。以前大家做模型,大头都在预训练,就是让模型海量阅读互联网数据。后训练通常只是微调一下,教它怎么说话好听点。但现在,DeepSeek把大量的资源砸在了让模型“学会思考”和“强化学习”上。
这说明大模型的游戏规则变了。光靠堆数据、堆显卡去“背书”已经不够了,现在的竞争核心,是谁能让模型在已有的知识上,通过反复的自我博弈和强化学习,把智商提上去。
当然,DeepSeek 也不是没缺点。报告里很诚实地承认,因为训练数据总量还是比不过那些闭源巨头(毕竟GPT-5.1背后的资源太恐怖了),V3.2 在“世界知识的广度”上还是差点意思。
说白了就是,做题它行,但聊些冷门的八卦或者百科知识,它可能不如 GPT-5.1 或者 Gemini 3.0 见多识广。
而且,Speciale 版本虽然强,但它是靠疯狂消耗 Token 换来的。为了达到 Gemini 3.0 Pro 的质量,它可能要多絮叨很久。这就是目前开源模型面临的现实:用效率换智商。
但不管怎么说,DeepSeek 这一波操作,确实给开源社区打了一针强心剂。
8月份GPT-5出来的时候,大家都觉得开源模型已经被甩得连尾灯都看不见了;11月GPT-5.1出来的时候,大家都觉得比赛结束了。结果这才过了半个月,V3.2 居然能跟 GPT-5 这种级别的模型掰掰手腕。
对于我们普通用户来说,这绝对是好事。毕竟,谁不喜欢一个更聪明、更便宜、还能帮你写奥数题的AI呢?
OpenAI,你们的 GPT-6 最好已经在路上了,不然这桌子可能真要被这群“卷王”给掀翻了。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com













![[6.27]夏促来袭!超多骨折!百款史低新史低这次你一定要入库!](https://imgheybox1.max-c.com/web/bbs/2026/06/26/bfb8adfbb675422149a024f4b7064470.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)

