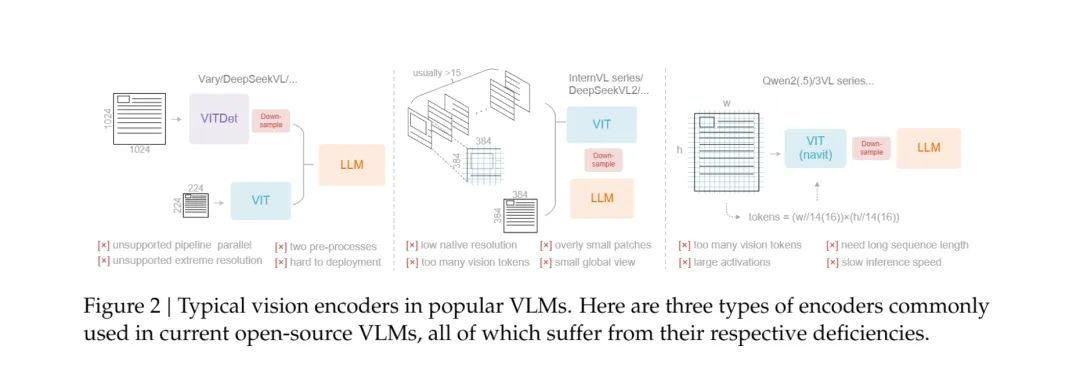
各位好,我們是果核剝殼旗下的AI方向新賬號 —— 飛碟AI,初來乍到小黑盒(來摸魚,真的),還請各位多多關注我們,感激不盡!!
DeepSeek 又雙叒叕發新模型了。
這次,不是語言模型,也不是圖像模型(就沒有),而是——DeepSeek-OCR模型。

但是但是,別被名字騙了。它不是“識字”的那個 OCR,而是反過來——讓 AI 更好地看懂圖片裏的字,還順帶學會了“把文字壓成圖”。
是的,這次它在“文字視覺化”上開始發力了。
First,what's is DeepSeek-OCR?
單從名字上看,你可能以爲這又是個類似 UniOCR 那樣的工具,拿來做識別發票、車牌、手寫字之類的工作。
但事實上,DeepSeek-OCR 其實是一個「文字—圖像聯合理解模型」。
它的核心思路非常有意思,我個人稱之爲邪修——
把原本只能靠語言理解的東西,轉成視覺信號,再交給模型去處理。
大家都知道,LLM 一遇到長文本就頭大——算力消耗是平方級漲的,文本越長越“燒卡”。於是乎,DeepSeek 的工程師乾脆腦洞大開:既然圖像能塞下更多信息,那要不把文字“畫成圖”?
這套操作他們稱爲「光學壓縮」,簡單說,就是讓 AI 用“看”的方式理解文本,而不是“讀”。
根據其論文給出的數據:壓縮 10 倍還能保持 97% 的準確率。
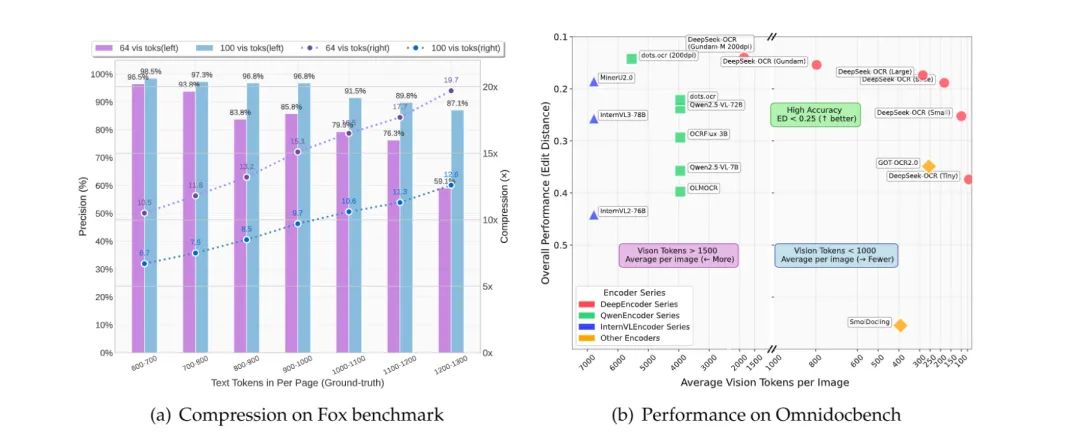
也就是說,一篇要 1000 個 token 才能讀完的長文,現在 100 個視覺 token 就夠了。
甚至在 20 倍壓縮下,準確率還有 60% 左右,AI 的“視覺帶寬”確實被狠狠拉開了。
簡單講,它讓“AI 看字”這件事,從“讀”變成了“看”。
我們繼續講。
文字→圖像,爲什麼反而更高效?
聽起來有點反直覺:文字不是比圖更容易處理嗎?
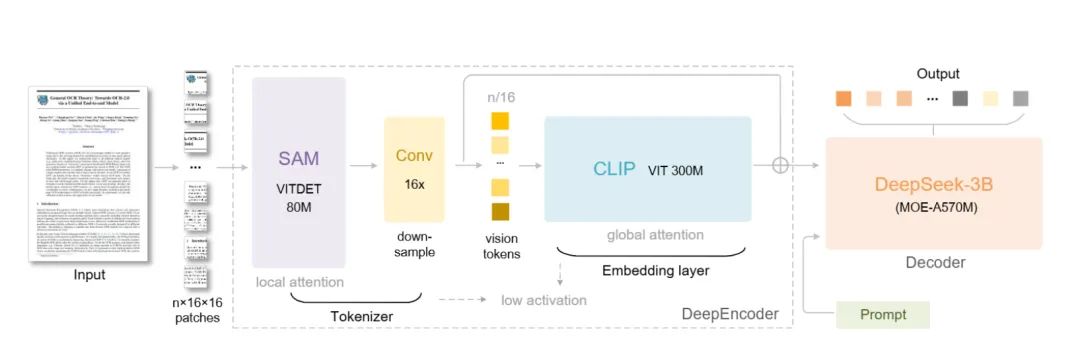
其實,DeepSeek 這裏利用的是一種叫「視覺壓縮」的思路。它用一種輕量的編碼器(DeepEncoder)把文字嵌進視覺特徵空間中,這樣模型在處理時,不需要再一個字一個字去理解,而是直接在一張“信息圖”上完成語義捕捉。
Tips:這個真是邪修了,但我個人感覺只適合中文等信息密度高的文字(其實就只有中文)才適合這種處理方式,有的語言(特別是英語)文字一大段,實際能傳達的信息其實沒多少,那麼這個方式就沒有那麼划算了。
這意味着在相同算力下,它能處理更長的上下文,甚至能一次“看完”一本 PDF、幾張截圖,或者一整個網頁。
如果類比一下,大多數語言模型像是看小說時用手指一行一行地滑;DeepSeek-OCR 則是直接拿無人機俯瞰整頁。

在官方展示的數據裏,DeepSeek-OCR 在中英文混排、公式識別、票據結構化任務上,都比主流模型(包括 Gemini-Vision 和 GPT 等)快兩倍以上,精度還更穩。
甚至在某些場景下(比如含有代碼截圖、表格或複雜標點的內容),DeepSeek-OCR 能“看出上下文邏輯”——比如識別 Python 代碼塊、理解函數縮進層級,這已經不是單純的 OCR,而是接近“視覺理解 + 語義補全”。
換句話說,它不止在“看”,它還能看懂你截圖裏想說什麼。
如果你把這當作一個獨立的 OCR 模型,那它確實是“強但沒太大用”的那種——畢竟普通人用不上這種高維識別,且嚴格意義上講,這個模型也不是爲了OCR類工具服務的。
但如果你把它看作 DeepSeek 在多模態方向上的佈局,這就有意思了。
這套技術的真正意義,是讓模型在語言、圖像之間自由切換信息表達方式。未來當它接入主力模型(比如 DeepSeek-V3 系列)搞多模態時,DeepSeek 的 AI 可能會出現一種新能力:
“看文檔像看圖一樣快,寫圖表像寫字一樣準。”
就像我們的大腦也有視覺記憶區、語言區一樣,DeepSeek 正在教模型學會“換個
最後,DeepSeek-OCR 看起來像個“小菜”級別的更新,若不是你看不本文,3B的參數量、名字裏帶OCR,你怎麼也想不到這是 DeepSeek 工程師的一大“邪修”成果。
AI 的瓶頸,已經不在“算力”或“理解力”,而在信息流怎麼輸入。
就像我們的大腦也有視覺記憶區、語言區一樣,DeepSeek 正在教模型學會“換個通道獲取信息和思考”。
所以,問題來了——AI 的下一步,是更聰明地記住,
還是更優雅地忘掉?
都看到這裏了,灌注我灌注我灌注我!!!!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















