知名科技公司英伟达,市值突破了4万亿美元,超过微软和苹果,成为全球市值最高的公司,在过去的30年时间里,英伟达从一家开发图形处理游戏显卡的小公司,一路成长为全球AI巨擘!欢迎大家来到老黄发家史的第11期,今天承接前十期内容,继续聊老黄的创业史!

01 技术偶然
上文讲到老黄的至暗时刻,
英伟达与微软合作破裂后,老黄转而秘密启动CUDA项目,
但是导致游戏显卡业务搁置、成本激增,
外部面临AMD的激烈竞争,内部股东分歧严重,
黄仁勋陷入创业以来最严峻的危机。
但是老黄依然自比为17世纪发明望远镜的荷兰工匠,
坚持CUDA战略,希望为科学家提供超级计算工具,
彼时,老黄心中其实并不知道未来会出现什么技术,
坦言自己缺乏马斯克那种目标明确的愿景,
自己只是感觉CUDA可以帮助到科学家,
但是具体在哪个领域,如何取得突破,
这些老黄都是一头雾水。

但他仍然坚信,在地球上的某个角落,
一定会有研究者使用英伟达GPU掀起一场技术革命!
首先登上历史舞台的是斯坦福教授李飞飞,
她毕业于成都七中,后前往Caltech深造,
受语言数据集WordNet启发,
她意识到数据是未来技术发展的新燃料,
于是构建了涵盖2200万张图像、2.2万类别的ImageNet数据集,
规模达同类1000倍,起初学术界并不看好李飞飞,
认为这只不过是规模更大的数据集,
要想取得突破还是需要算法。

02 数据还是算法?
于是,李飞飞在2010年推出了ImageNet挑战赛,
首届冠军由日本NEC(林元庆领队)和UIUC(黄煦涛领队),
以传统特征工程方法获得,Top-5错误率28.2%,
华人团队虽夺冠,但未突破算法瓶颈,
2011年,第二届ImageNet挑战赛,
获得冠军的是XRCE小组,
仍然是靠特征提取和降低特征维度这些特征工程取胜,
Top-5错误率25.7%,较2010年提升2.5个百分点,
如果未来每年都是这个进步速度,
那么李飞飞的ImageNet挑战赛也会成为无意义的刷榜,
特征工程+SVM的组合就是不可挑战的权威,
未来的AI革命自然也就无从谈起,
英伟达也无法达到今天4万亿美元的盛况。

03 AI教父
在2011年参赛人员中,还有一个非常不起眼的团队,
团队领队为多伦多大学的Hinton辛顿教授,
辛顿对李飞飞的ImageNet挑战赛很感兴趣,
他开始思考自己一直信奉的算法,
是否可以在ImageNet比赛上取得好成绩,
但学术界几乎所有人都对此嗤之以鼻,
因为辛顿在学界早就是过时老掉牙技术的代表了,
不过谁也没有想到,这位老头居然日后成为AI教父,
并且荣获图灵奖和诺贝尔奖双奖!

霍普菲尔德、辛顿 2024诺贝尔物理学奖
说来辛顿勉强也算是中国人的半个老朋友,
辛顿的高曾祖父是布尔代数的创始人乔治·布尔,
参与曼哈顿计划的核物理学家琼·辛顿是杰弗里的堂姑,
琼·辛顿师从费米,与杨振宁为同学,
而琼·辛顿的中文名大家更熟悉,名叫寒春,
寒春1948年随未婚夫阳早移居中国,投身农业机械化建设,
成为北京首位获得中国绿卡的外国人!
话扯远了,在2011年辛顿教授已经在神经网络上钻研了三十年,
但是一直无法获得学术界的广泛认可,
因为在当时,神经网络已经是被判“死刑”的技术。

黄仁勋与深度学习三巨头
04 老掉牙的技术
神经网络其实是起源于生物学,
1943年,神经生理学家沃伦·麦卡洛克和数学家沃尔特·皮茨
创建了神经网络的计算模型,他们利用电路模拟大脑神经元,
不过早期的模型都比较抽象,模型缺乏学习机制,
而且依赖同步时钟信号,与生物神经元的异步特性不符。
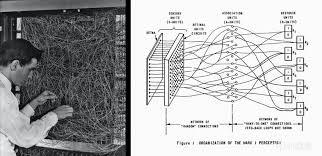
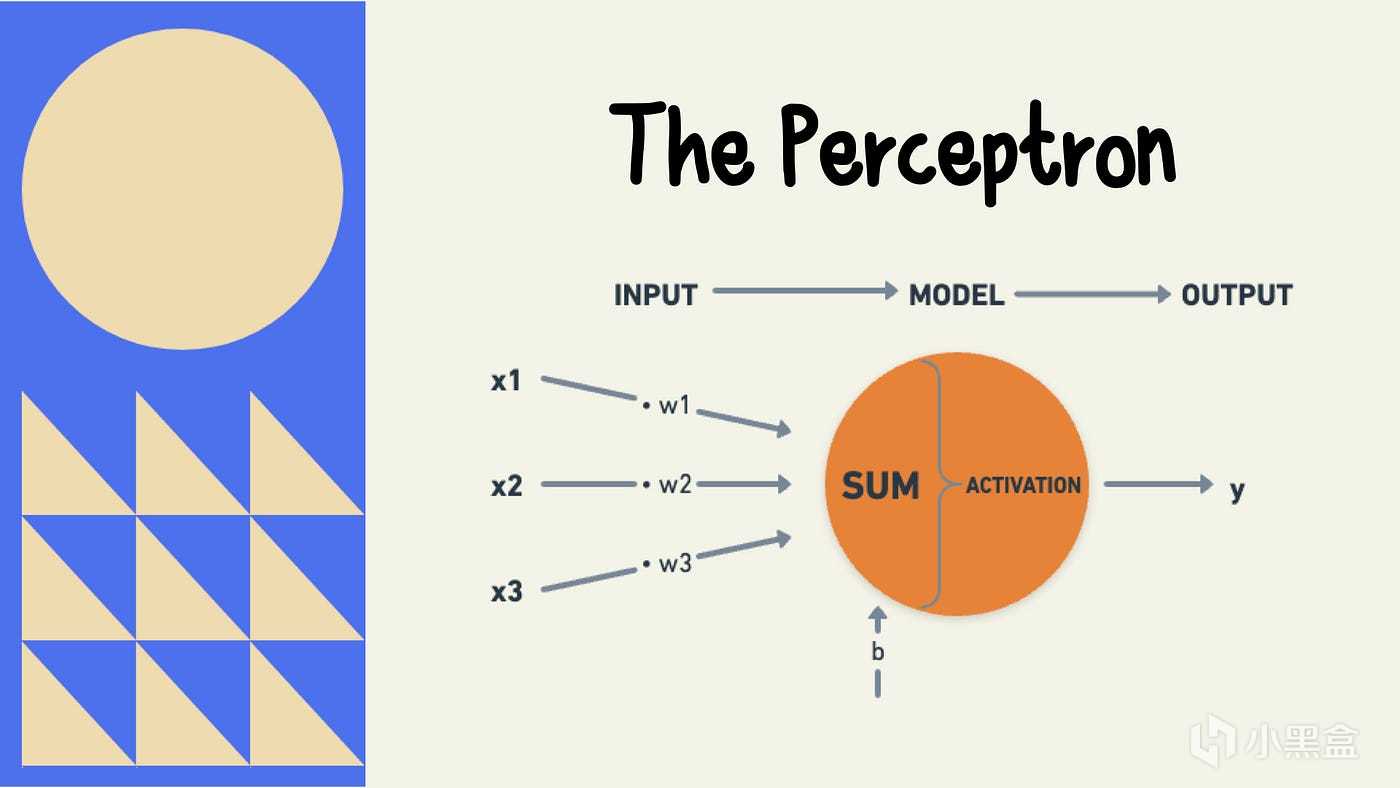
到了1958年,第一个采用神经网络结构的算法感知机(Perceptron)出现,
弗兰克·罗森布拉特教授从神经元工作方式得到启发,
搭建了单层神经网络感知机,
还成功在Mark I Perceptron计算机上实现,
1958年《纽约时报》头版宣称,
“感知机是胚胎计算机,未来可走路、说话、观察、写作!”
罗森布拉特的感知机直接掀起了60年代的AI热潮,
美国海军投入百万美元资助,引发学界与资本追捧。

05 AI寒冬
70年代初期,马文·明斯基和西摩尔·帕珀特对感知机进行了数学分析,
认为感知机无法解决异或(XOR)操作等非线性可分问题,
这一分析导致了研究的显著停滞,通常被称为“AI寒冬”。
单层感知机本质上是一个线性分类器,
决策边界只能是一条直线(或高维超平面),
而XOR问题在二维空间中无法被一条直线完全分割,
明斯基是MIT人工智能实验室联合创始人,
他把观点发布之后,几乎否定了感知机的所有实用价值,
学界基本上放弃神经网络,
转而探索符号主义AI,比如专家系统,
但是符号主义依赖人工规则,难以处理真实世界的模糊性,
进一步加剧了AI应用的瓶颈。
06 学新闻学的
所以在上世纪70年代后期,AI方面的研究几乎处于停滞状态,
当时的美国媒体也基本上是学新闻学的,
每次AI领域有一点突破,媒体立刻放大资本涌入,
人工智能领域多次经历这种炒作周期,
随后就是失望和批评,
一个技术往往几年甚至几十年后才重新获得兴趣。
明斯基和帕珀特的批判触发了AI寒冬,
但是并不代表神经网络和感知机毫无意义,
恰恰相反,神经网络和感知机正是这轮AI革命最早的起点,
只是当时大家的视野仍有局限性,
看不到神经网络未来的发展,
再加上公众和媒体往往功利性很强,
很多好技术最终也会被埋没,
好在这个世界上从来不缺像辛顿教授这样较真的人。
07 反向传播-1986
在上世纪80年代,AI寒冬短暂迎来复苏,
首先是霍普菲尔德在82年推出了霍普菲尔德网络(Hopfield Network)
(注:霍普菲尔德与辛顿同获诺奖),
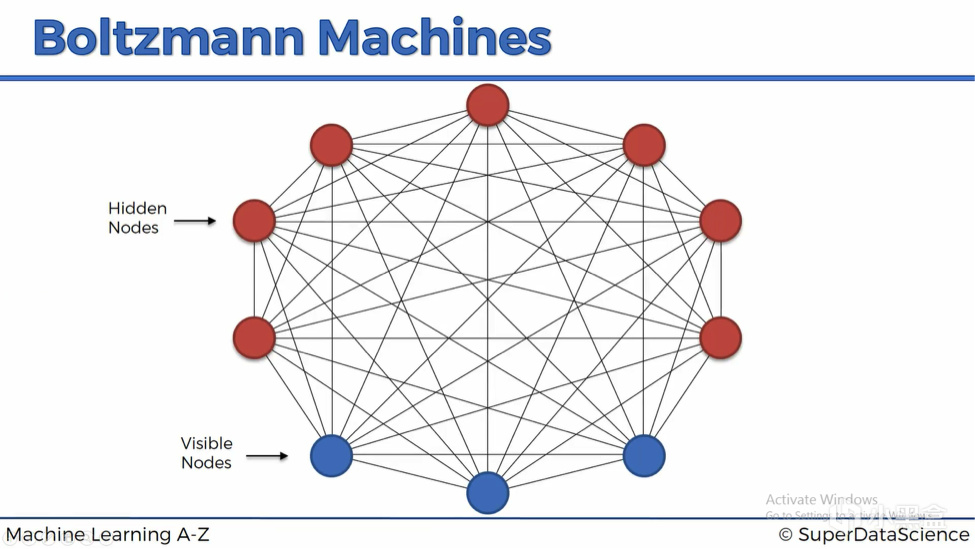
而辛顿教授与特伦斯·塞诺夫斯基,
在85年推出了大名鼎鼎的玻尔兹曼机(Boltzmann Machine)。
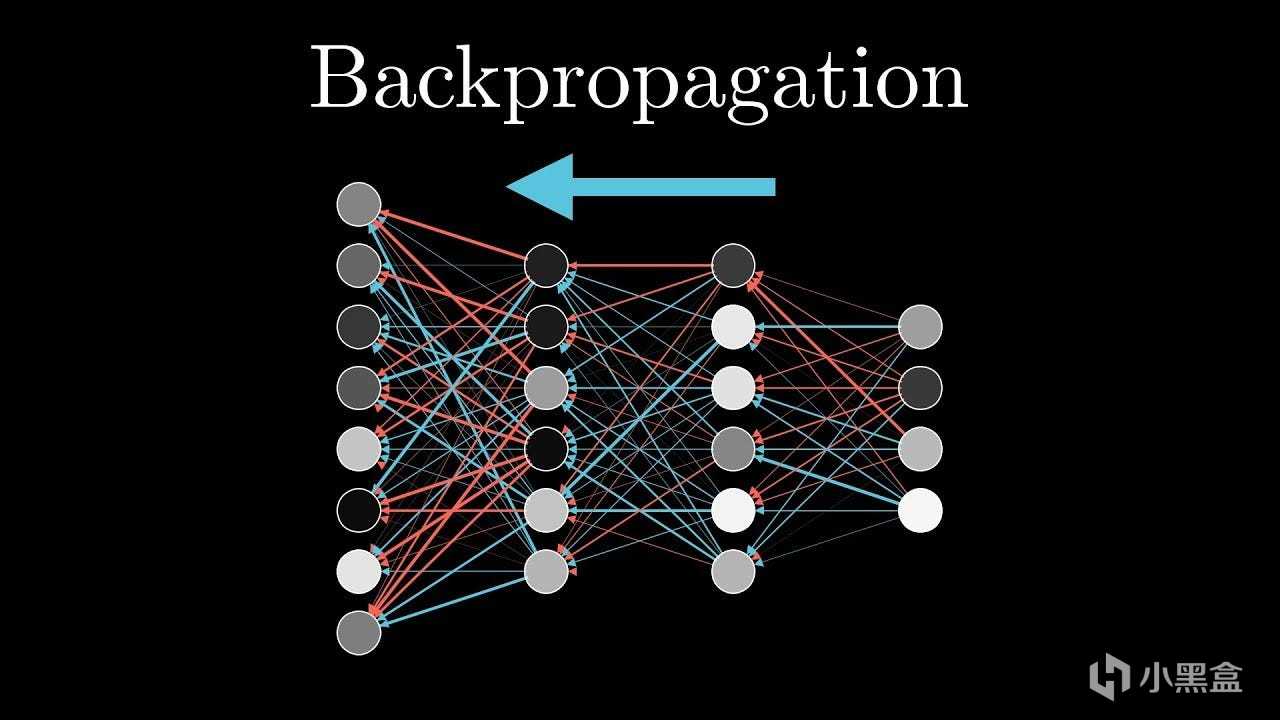
次年,辛顿、鲁梅尔哈特和威廉姆斯推广了反向传播算法,
提出了多层感知机(MLP),
与之前的感知机不同,多层感知机使用非线性(可微分)激活函数,
能够解决复杂的非线性问题,还能学习内部表示。
鲁梅尔哈特还引入了循环神经网络(RNN)的概念,
希望提高网络处理序列数据的记忆能力,
MLP和RNN的提出,
直接成为了日后计算机视觉CV和自然语言处理NLP腾飞的基石,
也直接造就了如今的AI大模型时代,
不过在80年代,由于大家已经厌倦了神经网络的营销,
再加上反向传播BP需要大量的算力资源,
英伟达CUDA显卡还没有出来,没有硬件可以支持这样的算法,
所以多数学者仍然对辛顿的研究比较冷淡。
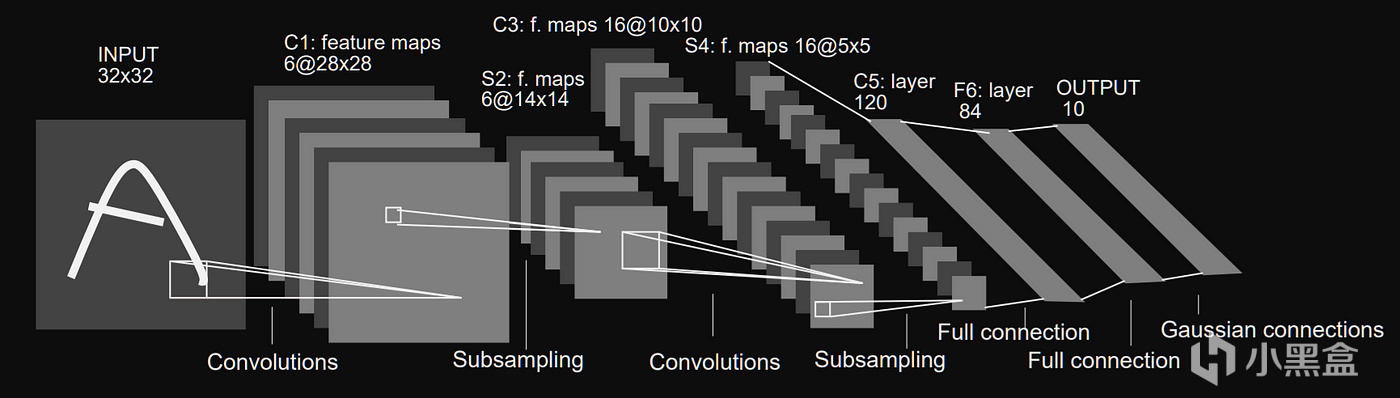
08 卷积神经网络-1998
等到神经网络下一次迎来跃迁,还要等到十年后,
1997年,Schmidthuber对RNN进行改进,
引入了长短期记忆网络(LSTM),
通过部分解决梯度消失问题提高了记忆能力,
成为自然语言处理的里程碑;

第二年,Yann LeCun开发了LeNet-5,
(Hinton、LeCun和Bengio日后一起获得2018图灵奖)
这是人类历史上第一个卷积神经网络(CNN),
与感知机神经网络相比,Lecun引入了卷积层的概念,
卷积(Convolution)本身其实是很基础的数学运算,
LeNet-5由7层神经网络组成,
分别是输入层+2个卷积层+2个池化层+3个全连接层,
用通俗语言来说,卷积层类似于侦探找线索,进行特征提取,
池化层类似总结报告,降维保留关键信息,
而全连接层是最终决策,整合所有信息做判断,
LeNet-5尤其适用于图像数据,
不过放在1998年,那时老黄英伟达才刚刚成立不久,
如果卷积神经网络层数增大,
仍然缺乏显卡来计算如此庞大的参数量,
所以遗憾的是,98年的卷积神经网络仍然没有引起大范围的注意。
09 深度学习-2000年代
进入21世纪,在80年代和90年代的理论基础上,
辛顿仍然没有放弃神经网络,
继续探索更深层的架构,
2006年,辛顿首次创建了深度信念/置信网络(Deep Belief Network,DBN),
这是一种通过堆叠受限玻尔兹曼机形成的生成模型,
深度学习的概念也是从这一时期开始萌芽的,
但实际上人工智能、深度学习、大模型这些范围很大的词,
都属于营销话术,真正的研究都有非常具体的方向,
比如反向传播这类研究属于优化方法,
DBN是早期深度学习的算法实体,
更具体来说是为了解决无监督特征学习问题,
后来常被泛化为“深度学习革命”的象征符号,
而且深度学习本身是个很大的概念,
单独拿出来讨论意义不大,大模型也是同理,
接下来的英伟达老黄发家史系列,
我也会给大家介绍各个领域的技术沿革发展。
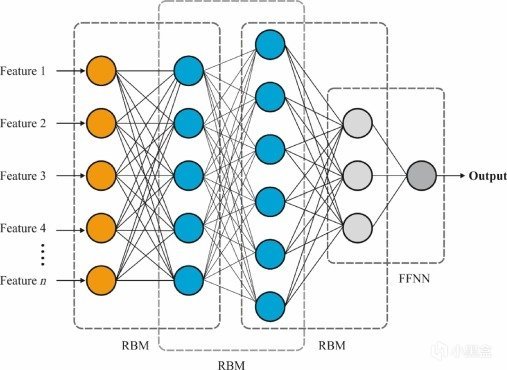
DBN
10 2011年-AI浪潮前夜
辛顿的DBN首次证明深层网络也可以高效训练,
2009年,辛顿再提出深度玻尔兹曼机(Deep Boltzmann Machine,DBM),
DBM和DBN类似,但DBM是完全无向图,
所有相邻层均为双向对称连接,训练复杂度高,
这类生成模型也展示出无监督预训练的潜力。
不过放在当时,训练深度网络需要巨大的计算能力,
而传统的CPU根本无法高效做运算,
而GPU也尚未被广泛用于通用计算,
再加上这类“深度学习模型”需要大量高质量的训练数据,
当时想要获取标注足够的数据非常耗时而且成本极高,
所以在数据有限的情况下,复杂模型容易过拟合,
而使用传统Sigmoid或Tanh激活函数的深度网络中,
还容易出现梯度消失问题,
反向传播过程中梯度会指数级缩小,使得模型难以学习。
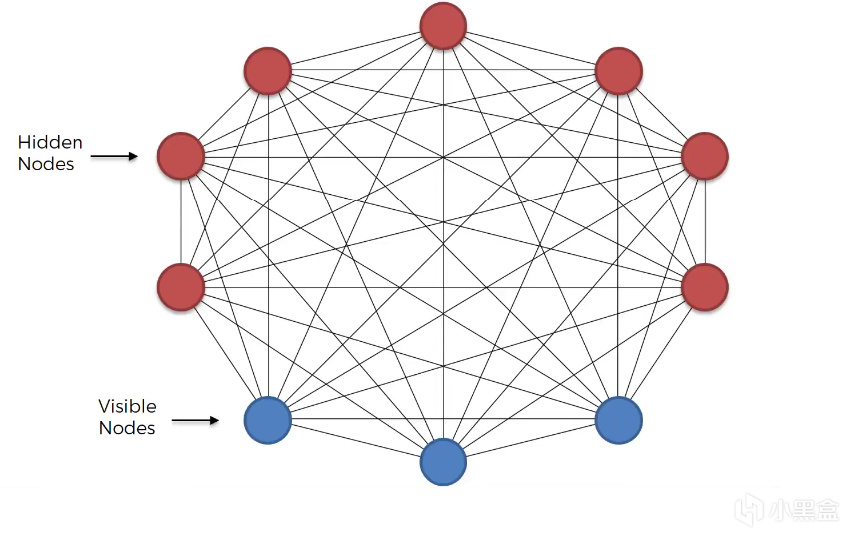
DBM
种种问题叠加之下,
多数学者都认为神经网络是效果不太好的黑箱模型,
决策过程难以理解,还需要大量的数据和计算资源,
想要取得突破几乎是不可能的事情,
但是在2011年,
属于黄仁勋、李飞飞和辛顿三条完全独立的人物线,
居然奇迹般地重合了,数据科学的三大难题——
算力(黄仁勋)、数据(李飞飞)和算法(辛顿),
也在人类历史上首次同时解决,
那么究竟是谁成就了这一切,
人类历史又是如何被改变的呢,
欲知后事如何,且听下回分解!

AlexNet团队
游戏&AI系列:
老黄发家史——英伟达市值突破4万亿,老黄的传奇人生!
老黄发家史——传奇AMD工程师,老黄人生的第一份工作!
老黄发家史——世嘉主机拯救英伟达,老黄曾差点破产!
老黄发家史——FPS天才成就英伟达,N卡的诞生!
老黄发家史——N卡大战A卡,上古芯片巨头ATI!
老黄发家史——英伟达创造显卡,PC游戏的崛起!
老黄发家史——极客玩家的一次灵感,启发英伟达进军AI!
老黄发家史——让玩家为 AI 买单,老黄成功的秘诀!
老黄发家史——CUDA崛起,英伟达AI的护城河!
老黄发家史——华人AI教母李飞飞,老黄发家的贵人!
AI——是游戏NPC的未来吗?
巫师三——AI如何帮助老游戏画质重获新生
你的游戏存档——正在改写人类药物研发史
无主之地3——臭打游戏,竟能解决人类大肠便秘烦恼
一句话造GTA——全球首款A游戏引擎Mirage上线
AI女装换脸——FaceAPP应用和原理
AI捏脸技术——你想在游戏中捏谁的脸?
Epic虚幻引擎——“元人类生成器”游戏开发(附教程)
脑机接口——特斯拉、米哈游的“魔幻未来技术”
白话科普——Bit到底是如何诞生的?
永劫无间——肌肉金轮,AI如何帮助玩家捏脸?
Adobe之父——发明PDF格式,助乔布斯封神
FPS游戏之父——谁是最伟大的游戏程序员?
《巫师3》MOD——制作教程,从零开始!
#gd的ai&游戏杂谈#
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com









![好想回到公司没钱的时候[cube_doge]](https://imgheybox1.max-c.com/bbs/2025/11/21/56ce39f9ee8ebbfa0618d755eb4b17a6.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)







