想必视频内容已经成为人们获取知识、记录观点和进行内容创作的重要媒介。相比图文,视频的信息呈现更丰富,但也更难检索、难以快速复盘。尤其在面对教育讲座、操作教程、会议录播等类型的视频时,不少人往往希望能够提炼出一份清晰的笔记以备后用。然而,手动整理视频笔记的过程不仅繁琐、耗时,而且极易遗漏重点信息。因此,借助 AI 工具自动提取视频内容、生成结构化笔记,已成为一种高效且趋势化的解决方案。
本期来介绍一个开源的AI视频笔记生成工具,能够让AI替你的视频做笔记:BiliNote。
📖 项目介绍
BiliNote 是一款开源的 AI 视频笔记助手,支持通过哔哩哔哩、油管、抖音、本地视频链接或文件,自动提取语音内容,并将其结构化为清晰、重点明确的 Markdown 格式笔记。
它内置 FastAPI 后端和 React 前端,支持本地部署的大模型或调用 API 接口完成语言总结,同时可选集成 Whisper 本地模型进行语音识别。BiliNote 提供截图插图、原片跳转(时间戳)、任务追踪等功能,适配不同工作流需求;部署方式上,既可使用 Windows/Mac 打包版,也可通过 Docker Compose 容器部署,适用于本地自用或私有化部署环境。
🤔 应用场景
以下这些都是 BiliNote 可以高效介入的实际使用场景,包含但不局限于此:
在处理 B 站公开课、技术讲座等学习类视频时,用户可以使用 BiliNote 生成包含段落标题、要点总结的 Markdown 笔记,方便后续复习。也可通过笔记直链跳转到对应时间节点,直接从对应部分观看。
在运营或产品部门回看公司内部培训录播视频时,可以快速提取要点、同步任务记录,免去重复观看的烦恼。
在进行短视频选题调研、内容剪辑时,可以将视频链接导入系统,自动生成视频结构草稿、抓取关键语句与截图素材。
在录制视频播客或会议纪要后,也可以本地上传音视频文件,通过 Whisper 转写与 GPT 总结组合,自动生成完整内容笔记。
🍀 部署流程
先啰嗦几句
演示设备为威联通NAS,型号TS-464C,处理器N5095。
本文会介绍Docker Compose的方式进行部署使用。关于配置文件,以及包含Windows打包版的包体在内,会放在文末,网络不方便的朋友可取用。
项目名:JefferyHcool/BiliNote,想了解更多的朋友直接在GHUB搜索即可。
修改配置可通过vi命令,或者NAS自带的工具对配置文件进行编辑。除非你清楚自己在做什么,否则建议只修改docker-compose.yml或.env.example,或者不改动直接部署。
如果你的设备有独显,或对自己的设备性能不够自信,又或是非常自信,请至到注意事项章节查看。
情况一:能成功连通GHUB(简单)
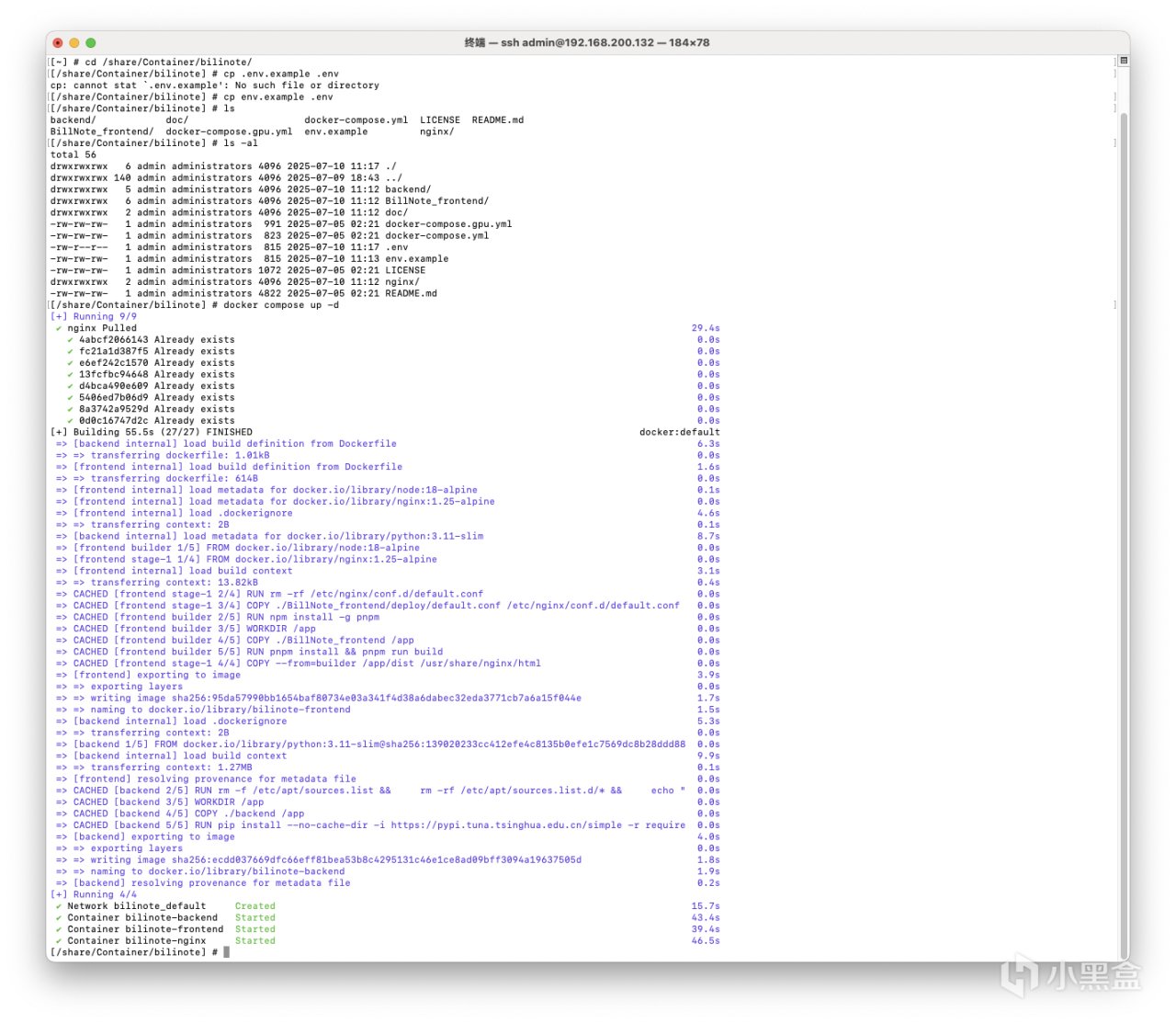
SSH链接至NAS,输入以下命令,克隆部署仓库。
cd <docker 目录下> # 例如威联通NAS输入 cd /share/Container
git clone https://github.com/JefferyHcool/BiliNote.git
cd BiliNote
接着输入命令,查看文件:
ls -al
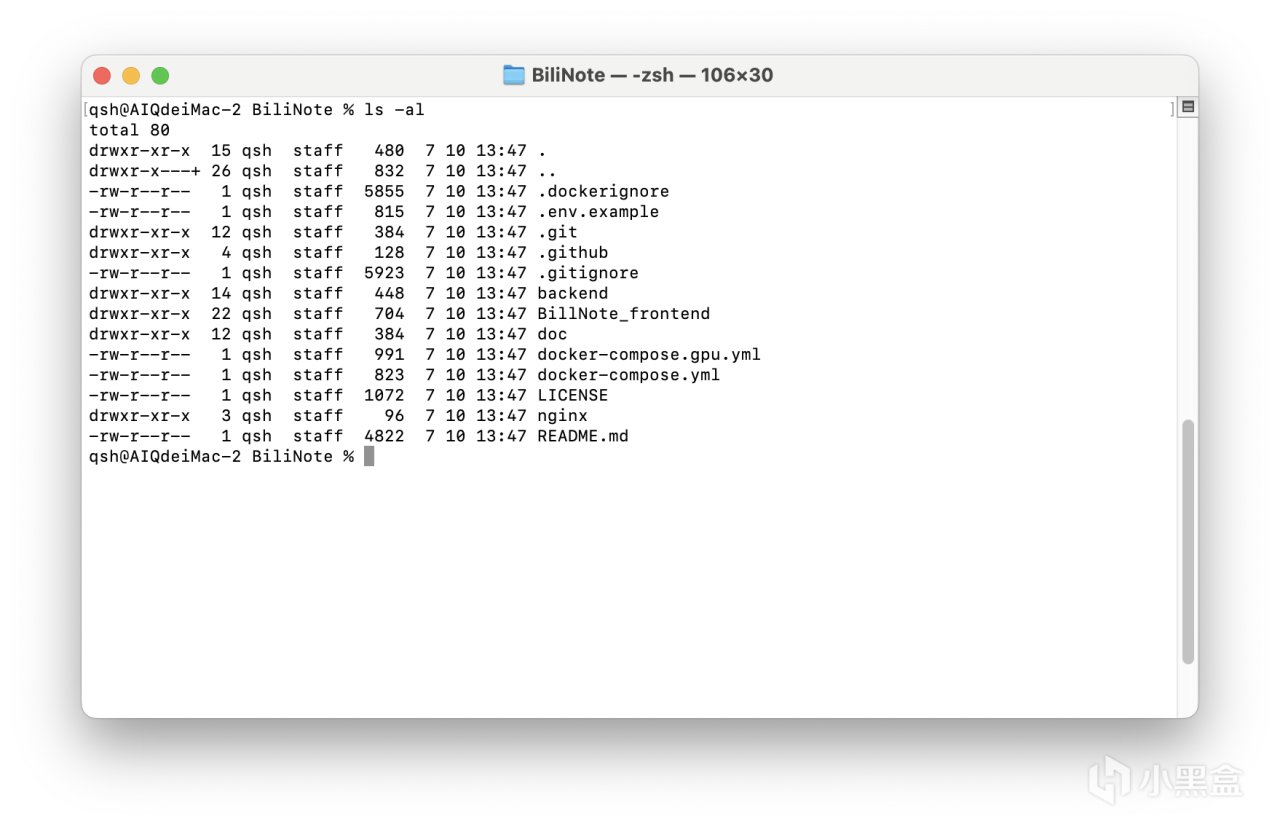
确认无误后,接着输入以下命令:
# 将环境文件重命名
mv .env.example .env
# 构建Docker镜像并启动
docker compose up -d # 或 docker-compose up -d
等待部署即可。
情况二:无法连通GHUB(简单)
文末我提供的文件包先下载下来。
在NAS准备好对应的文件目录,威联通为例:/share/Container/BiliNote,将解压好的全部内容全部拖入该目录下。
可选择用自带的编辑器重命名另存为.env,也可重复情况一的操作用命令行重命名。如果你看不到.env文件,请勾选显示隐藏文件。
命名完毕后接着重复:
# 情况一二都必须执行该命令
cd /share/Container/BiliNote
# 已改名的忽略
mv .env.example .env
# 情况一二都必须执行该命令
docker compose up -d
等待部署即可。
⚠ 注意事项
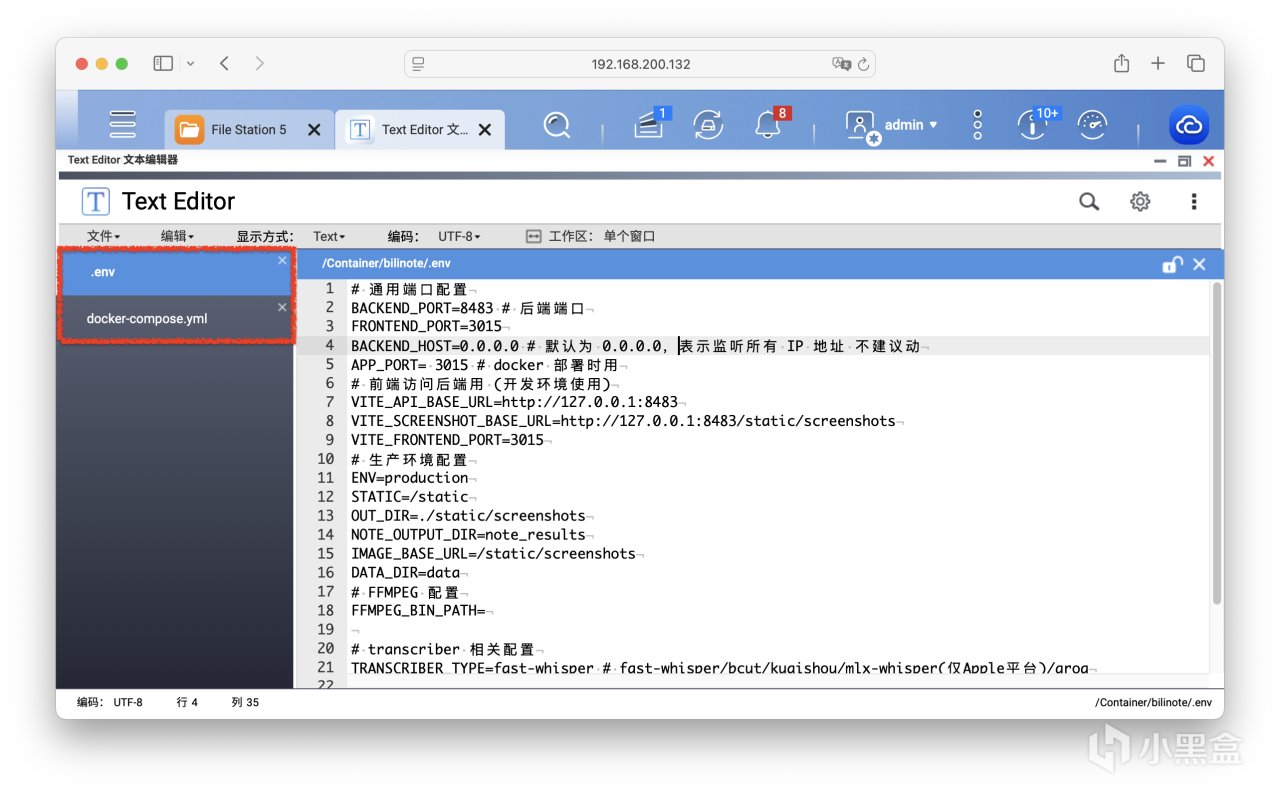
文件.env 详解
BACKEND_PORT=8483 # 后端服务监听端口,默认 8483
FRONTEND_PORT=3015 # 前端 Web 页面监听端口,默认 3015
BACKEND_HOST=0.0.0.0 # 后端服务监听的地址。默认 0.0.0.0 表示监听所有 IP,不建议修改
APP_PORT= 3015 # 容器前端的访问端口,与 FRONTEND_PORT 保持一致
VITE_API_BASE_URL=http://127.0.0.1:8483 # 前端访问后端 API 的基础地址(开发时用)
VITE_SCREENSHOT_BASE_URL=http://127.0.0.1:8483/static/screenshots # 前端访问截图资源的地址
VITE_FRONTEND_PORT=3015 # 前端项目运行端口,与上面一致
ENV=production # 环境模式,可选:development / production
STATIC=/static # 静态资源的 URL 路径前缀,默认 /static
OUT_DIR=./static/screenshots # 视频截图保存路径(相对路径)
NOTE_OUTPUT_DIR=note_results # 笔记结果输出目录(markdown 和状态文件将保存在此)
IMAGE_BASE_URL=/static/screenshots # 前端访问图片的路径前缀
DATA_DIR=data # 数据文件保存目录,例如转录中间件产生的缓存数据等
FFMPEG_BIN_PATH= # 可选项:如果需要自定义 ffmpeg 路径可填此项;默认使用系统自带 ffmpeg
TRANSCRIBER_TYPE=fast-whisper # 语音转文字使用的模型类型
# 可选项:
# - fast-whisper(推荐,支持 CPU/GPU)
# - bcut(字节跳动转写 API)
# - kuaishou(快手转写 API)
# - mlx-whisper(仅限 Apple MLX 框架)
# - groq(使用 groq 平台 Whisper)
WHISPER_MODEL_SIZE=base # fast-whisper 模型尺寸(base、small、medium、large)
# 如果 TRANSCRIBER_TYPE 设置为 groq,使用以下模型
GROQ_TRANSCRIBER_MODEL=whisper-large-v3-turbo # groq 平台提供的 whisper-large-v3-turbo 模型,
关于语音识别配置
如果你的设备带有独立的显卡,请修改.env并运行docker-compose.gpu.yml文件进行构建。
威联通TS-464C的CPU性能在默认配置下跑得还算可以,如果你的配置较低则建议降低模型版本,否则更容易出现幻觉导致结果不准确。
.env中的默认配置如下:
TRANSCRIBER_TYPE=fast-whisper # fast-whisper/bcut/kuaishou/mlx-whisper(仅Apple平台)/groq
WHISPER_MODEL_SIZE=base
GROQ_TRANSCRIBER_MODEL=whisper-large-v3-turbo # groq提供的faster-whisper 默认为 whisper-large-v3-turbo
Fast-Whisper 模型选择
截图来自项目Wiki。

🎉 使用展示
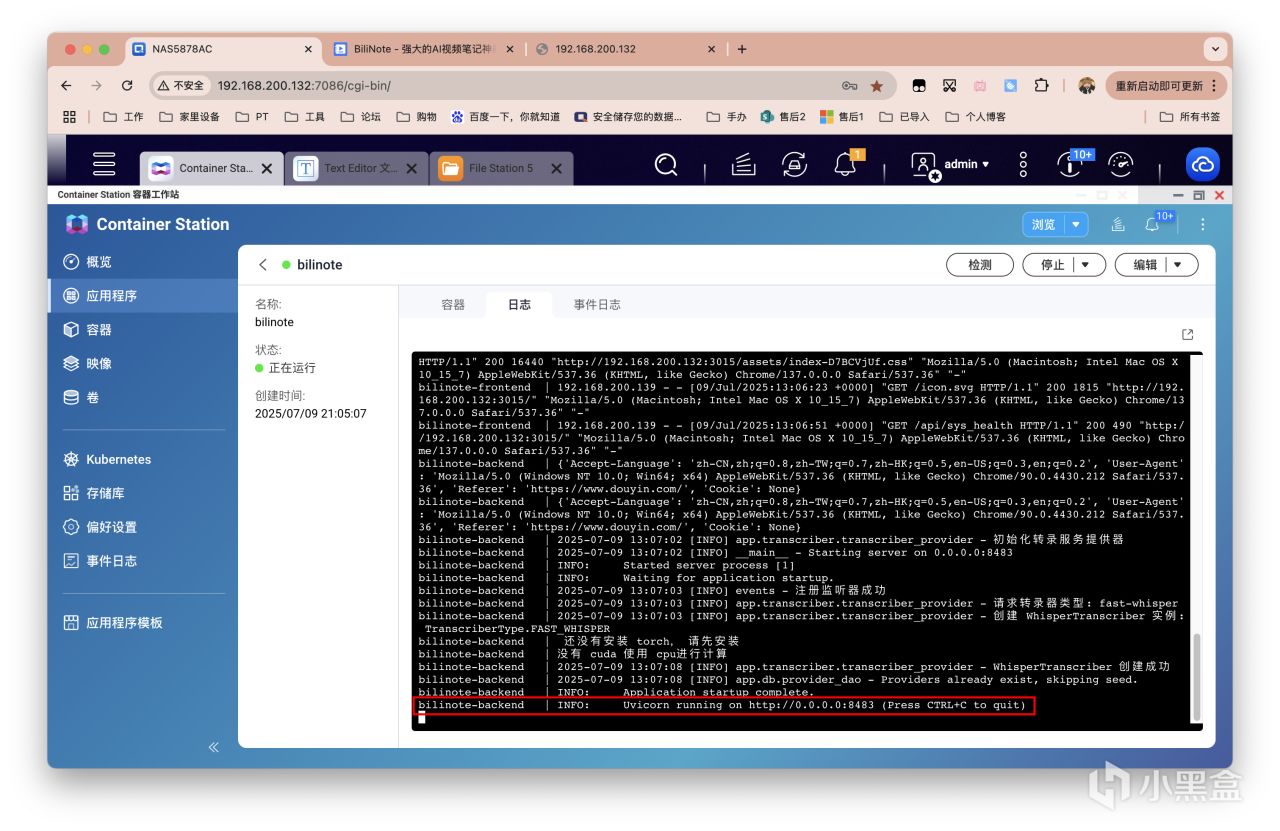
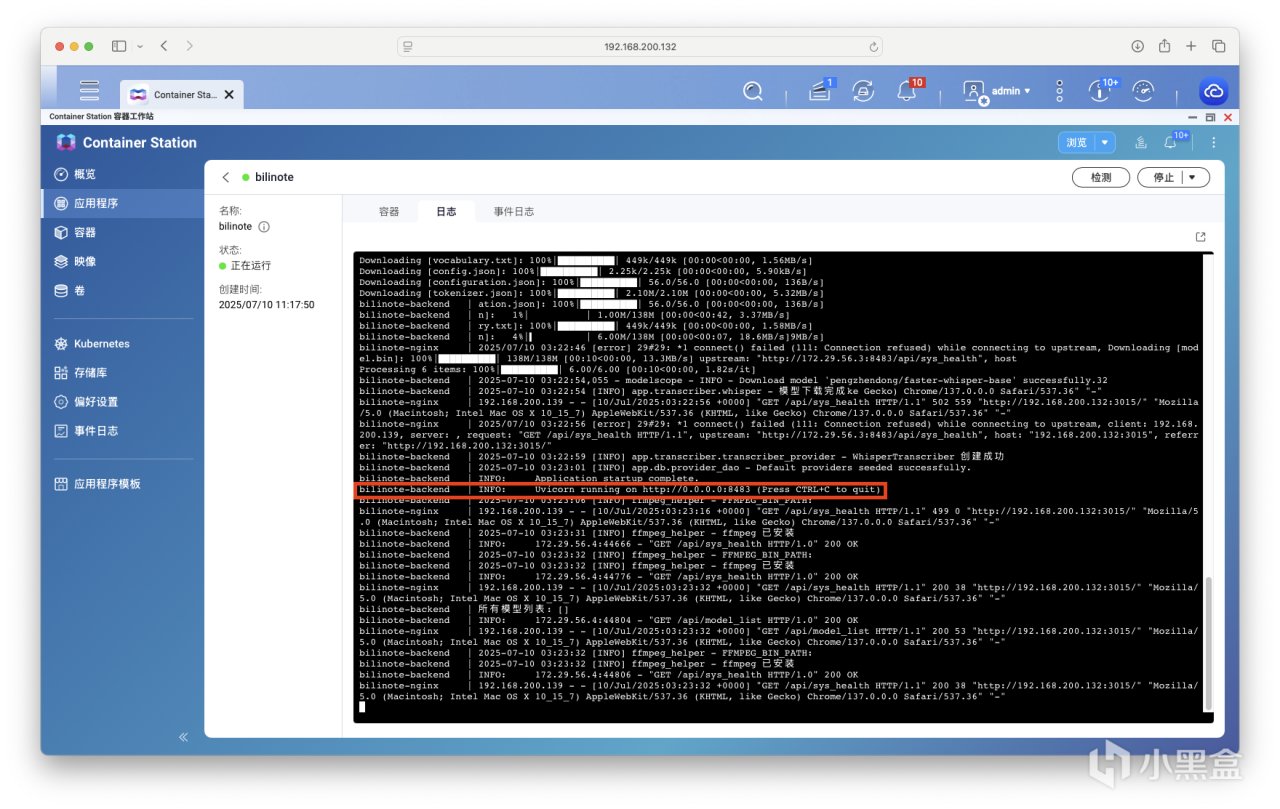
因为项目问题,需要等系统初始化环境配置完成后才可成功访问并使用,如果你在日志中看到以下输出则证明部署成功,此时可以访问前端界面。
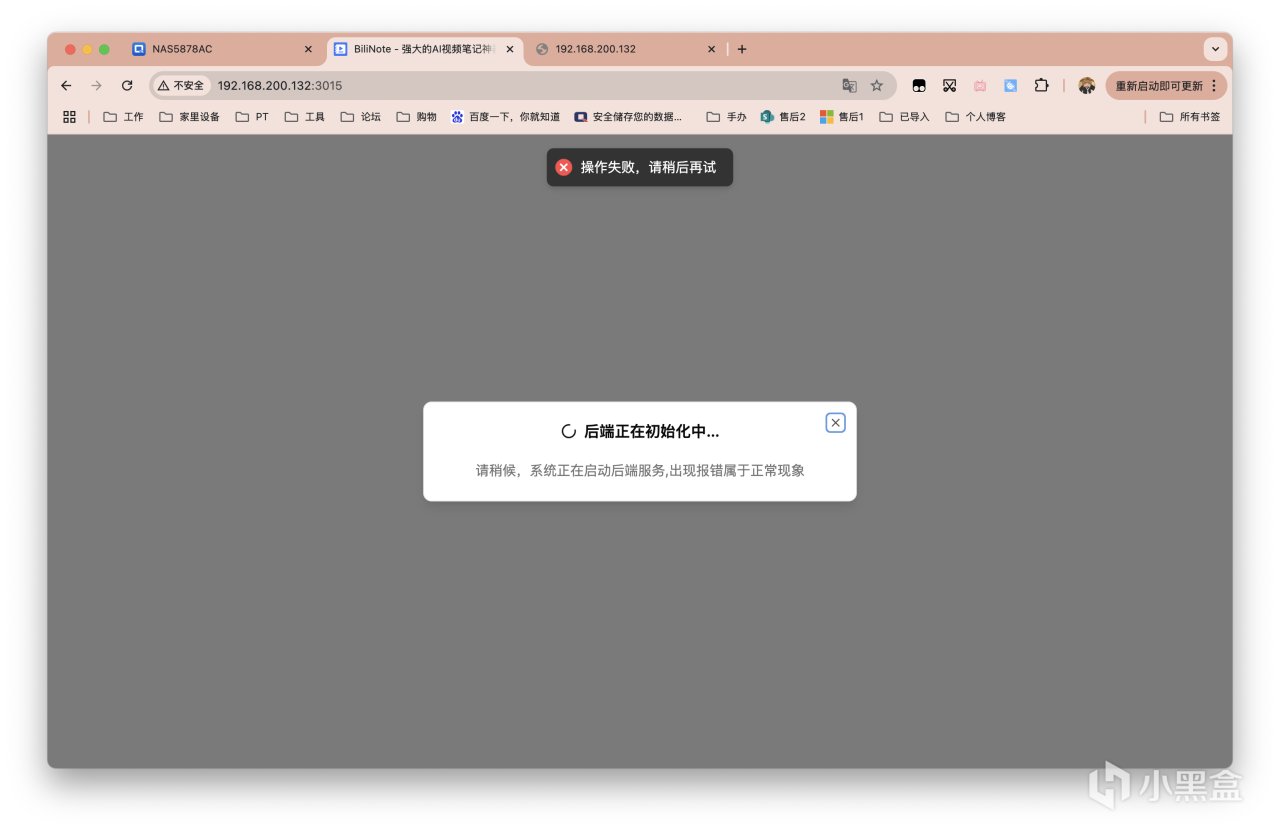
此时浏览器输入NAS_IP:3015即可访问。大概率会出现如下界面,提示报错(大概率),再耐心等项目跑会儿。
我成功进入项目界面的日志输出如下,可作参考。此时便可使用了。
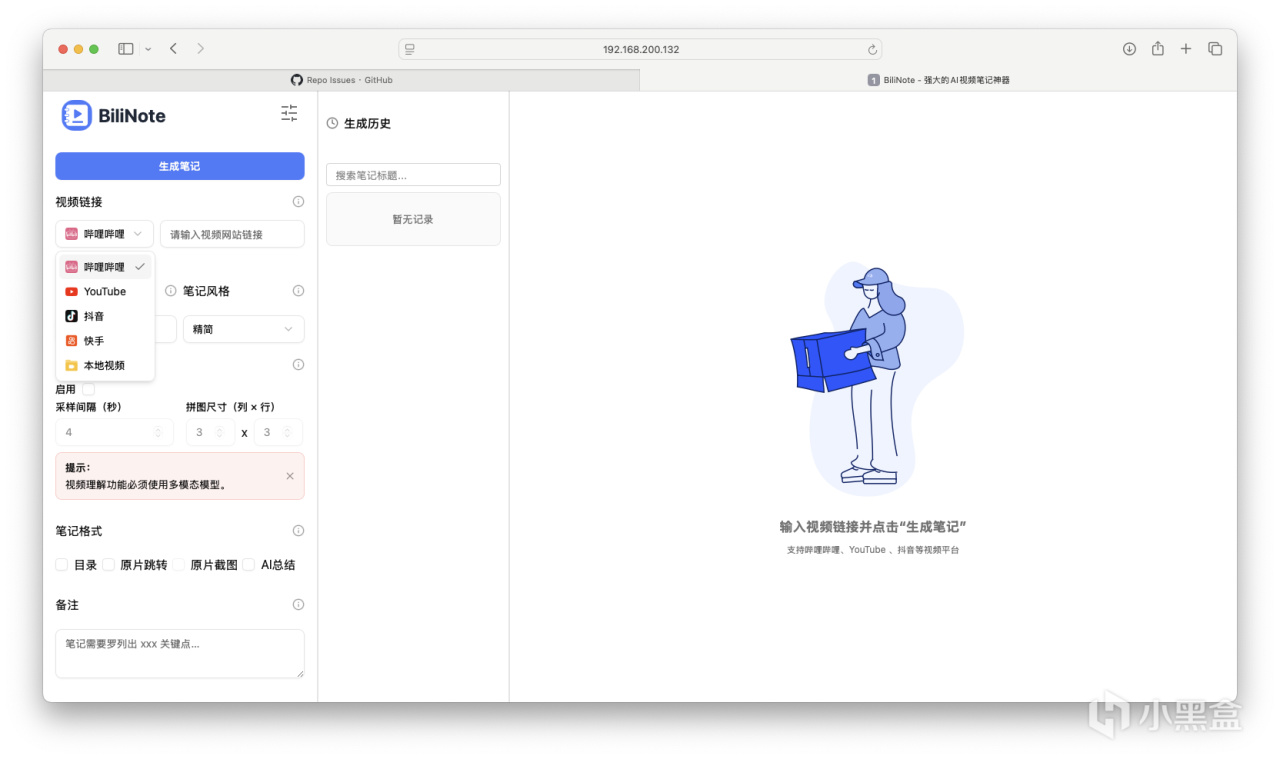
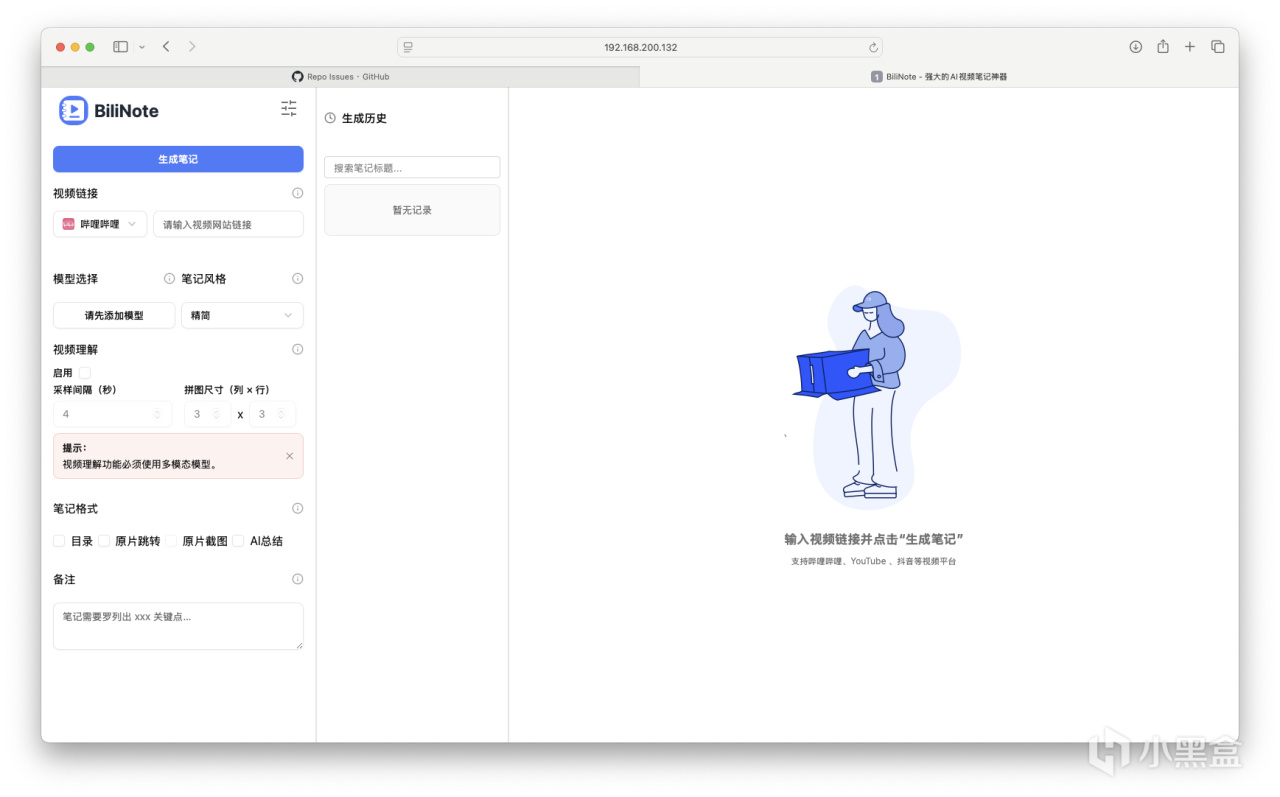
界面如下。支持B站、油管、快手、抖音的链接直接导入,也支持本地视频导入。
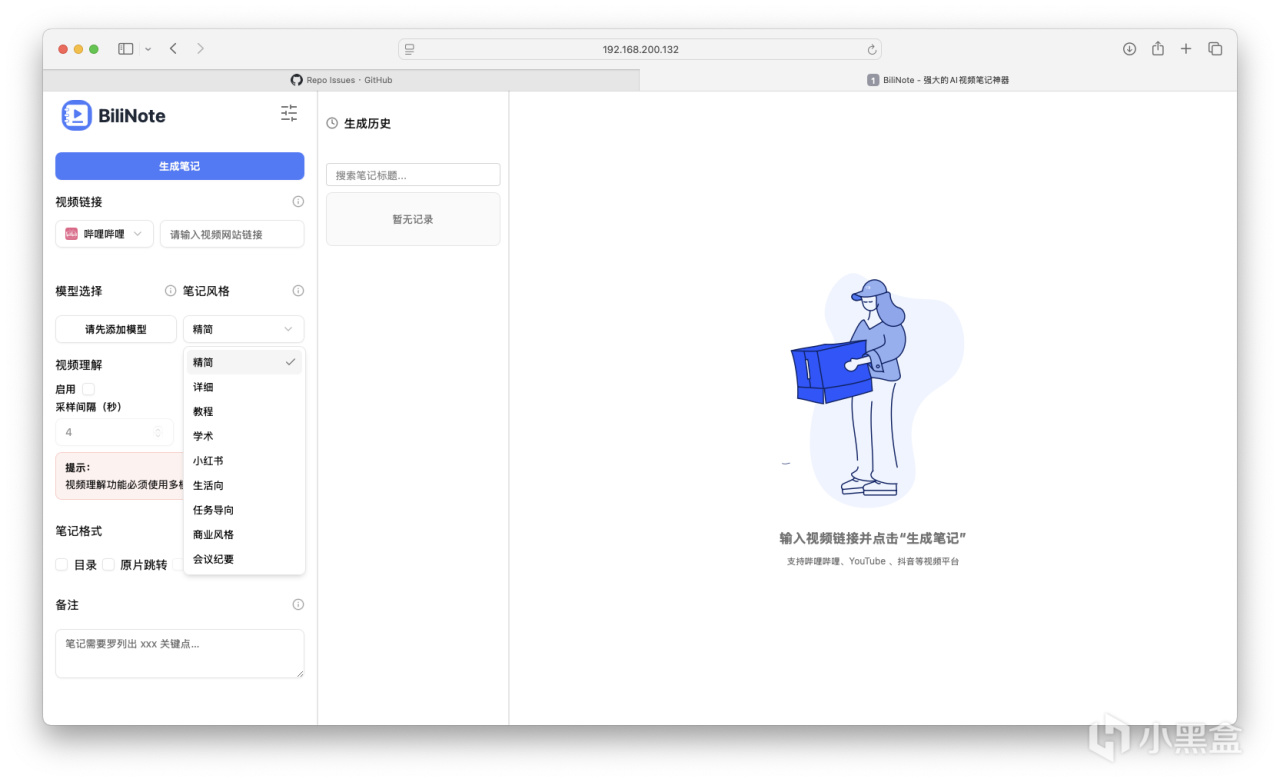
支持各种不同文案风格的输出,可选择目录、原片跳转/截图、AI总结等多种输出格式。
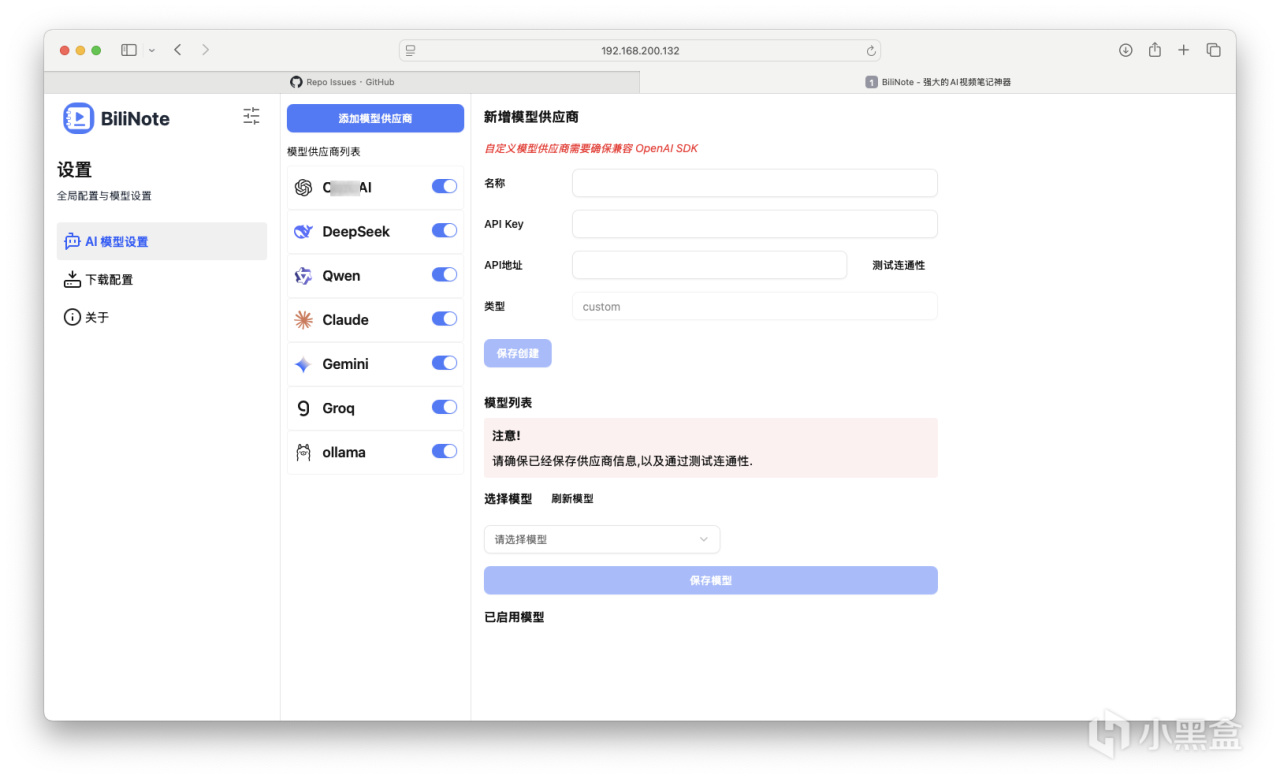
内置默认支持的大模型供应商如下,Ollama本地部署也同样支持。如果要得到理想输出结果,请选择具备相应功能的大模型版本。关于API如何获得使用还请自行搜索。(通义千问有白嫖福利)
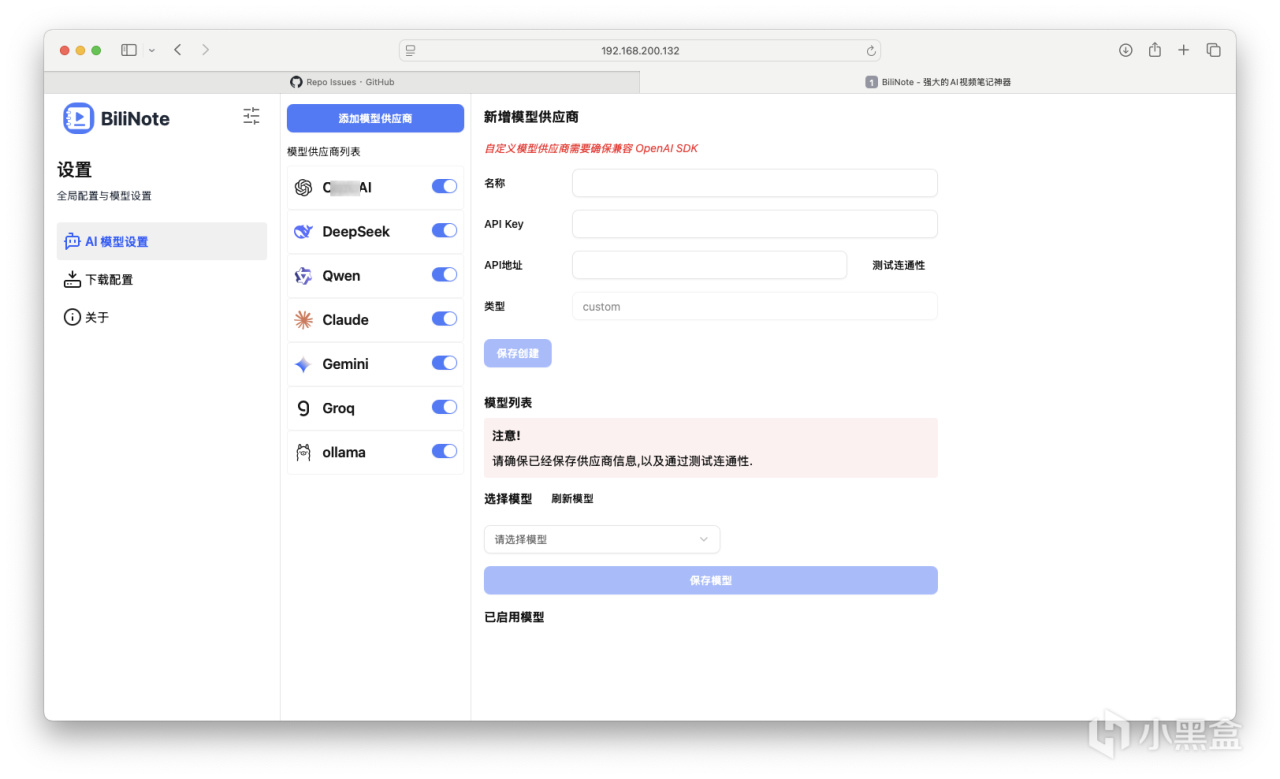
也可自行添加其他提供商例如硅基流动,不过要确保兼容性。
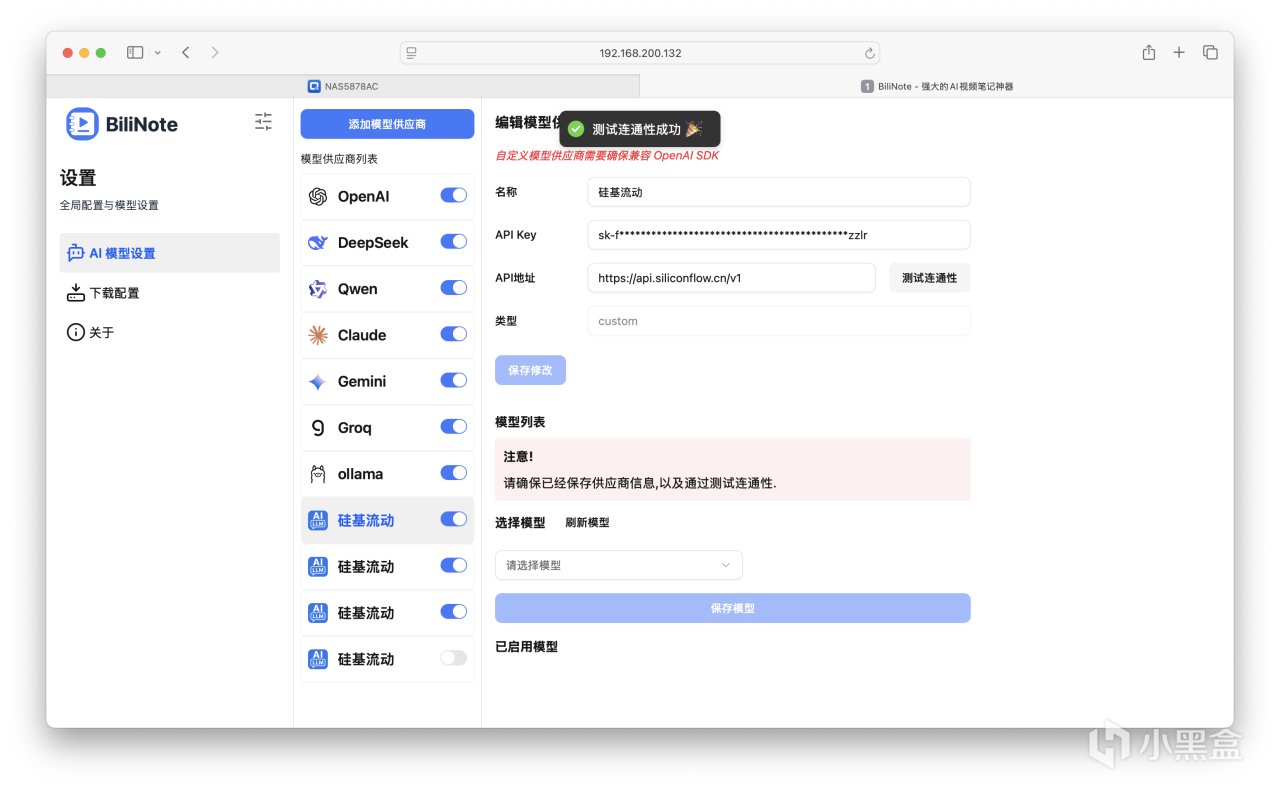
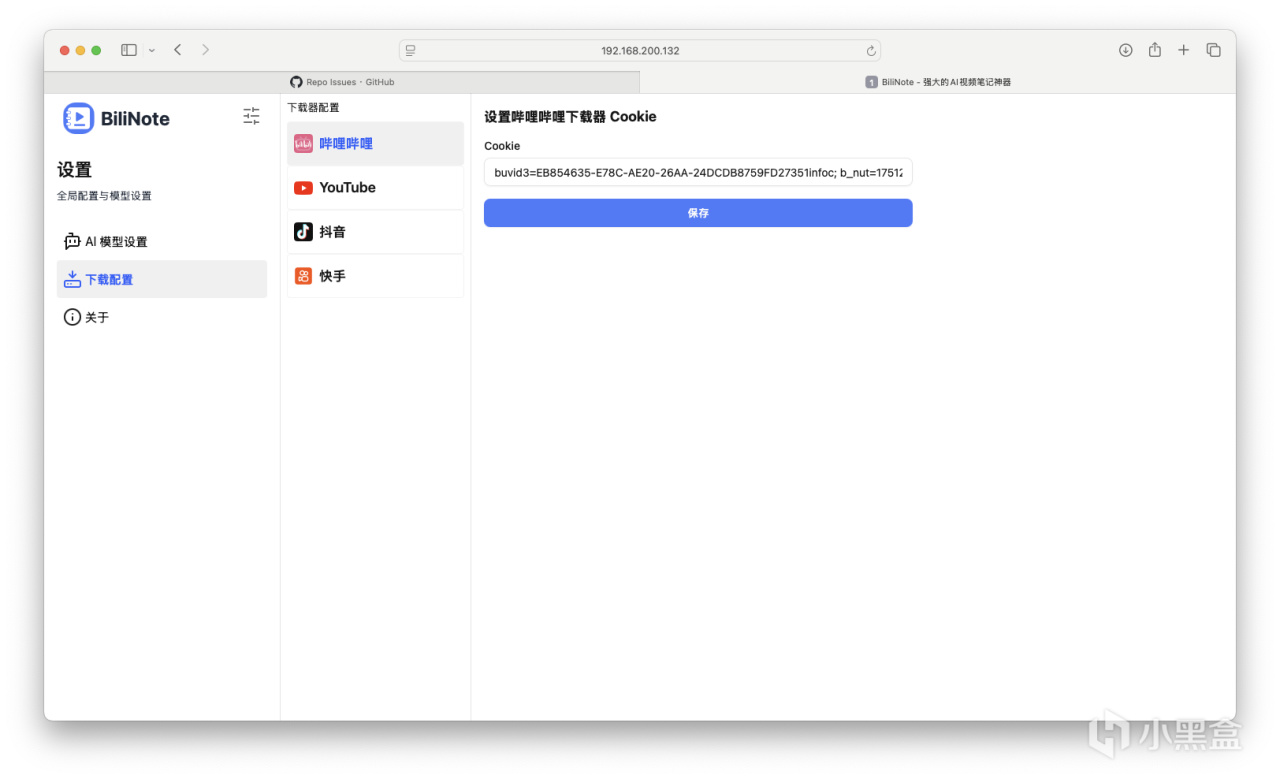
配置相关Cookie,这个也不再进行赘述。
下面我用油管链接进行演示。随机刷到一个时长8min的三星手机评测,链接搞进去进行笔记生成。还蛮快的。动图为2.5倍速。
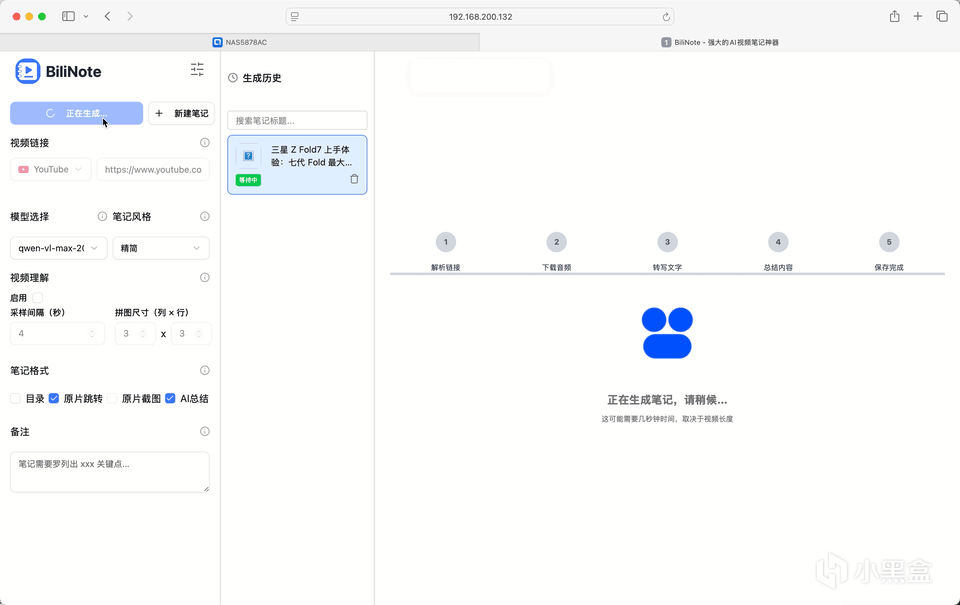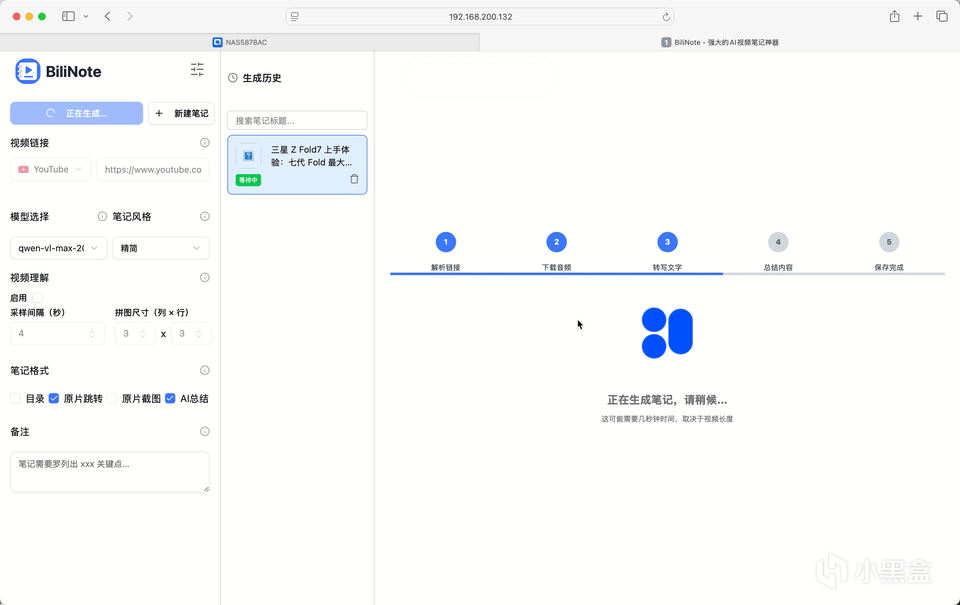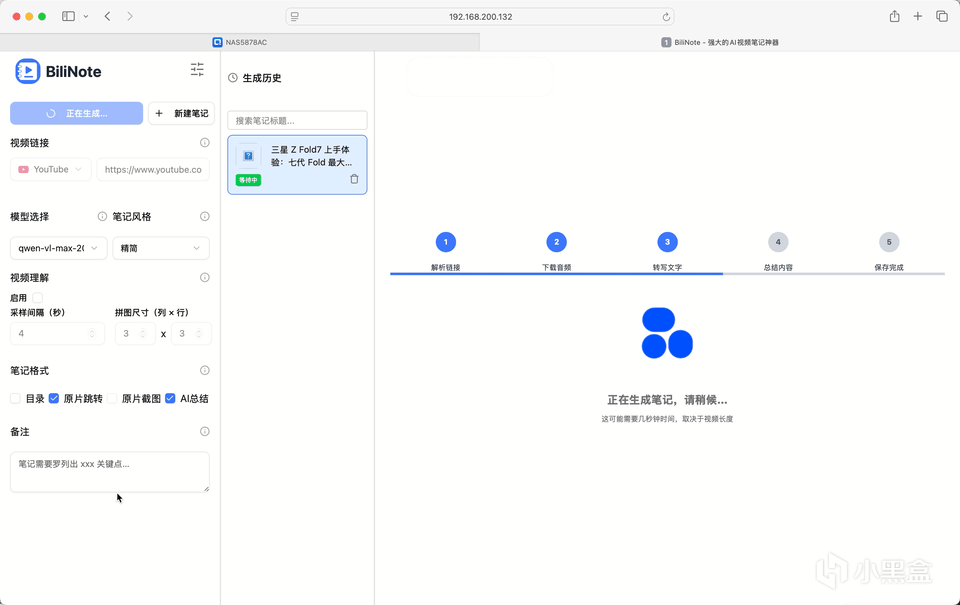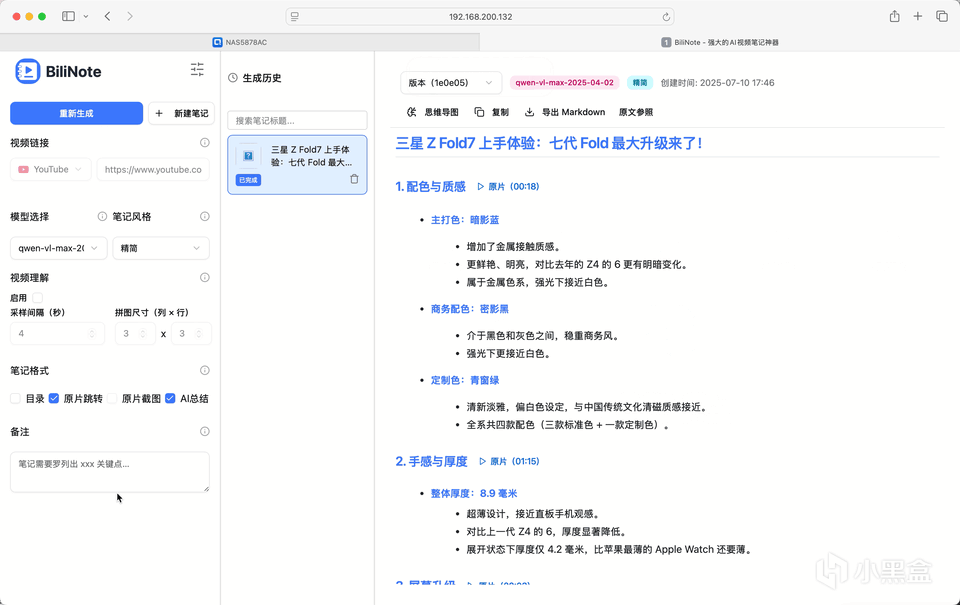
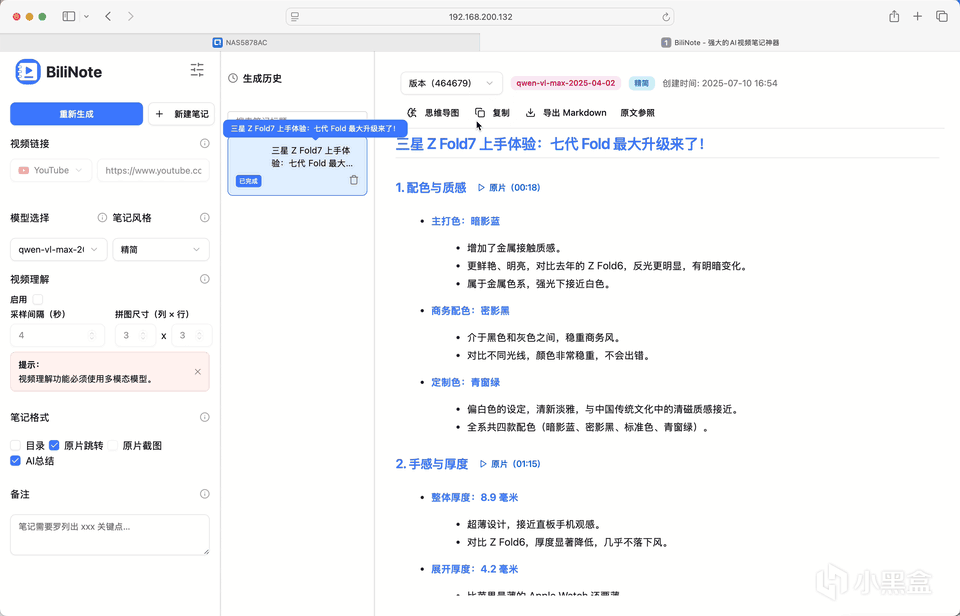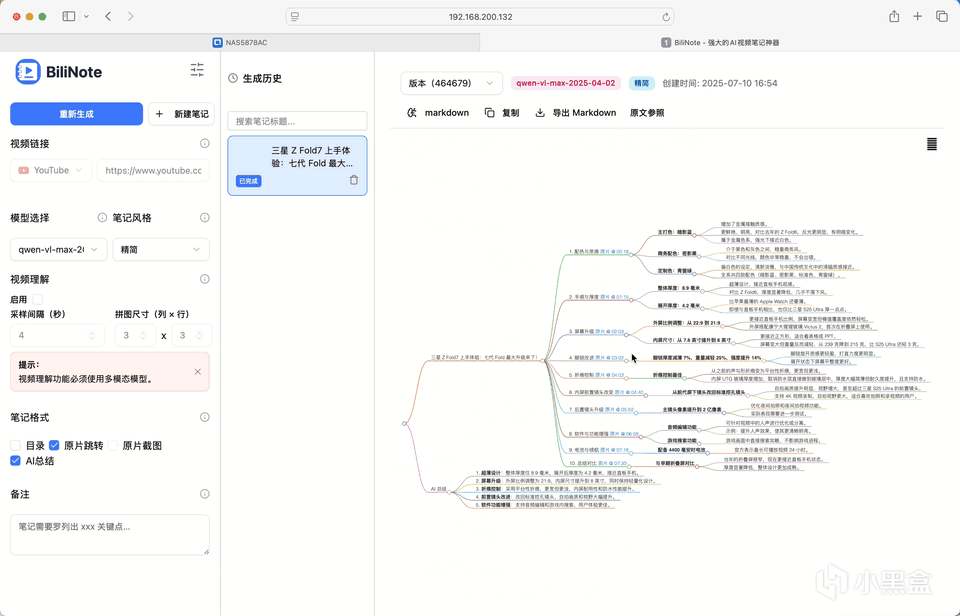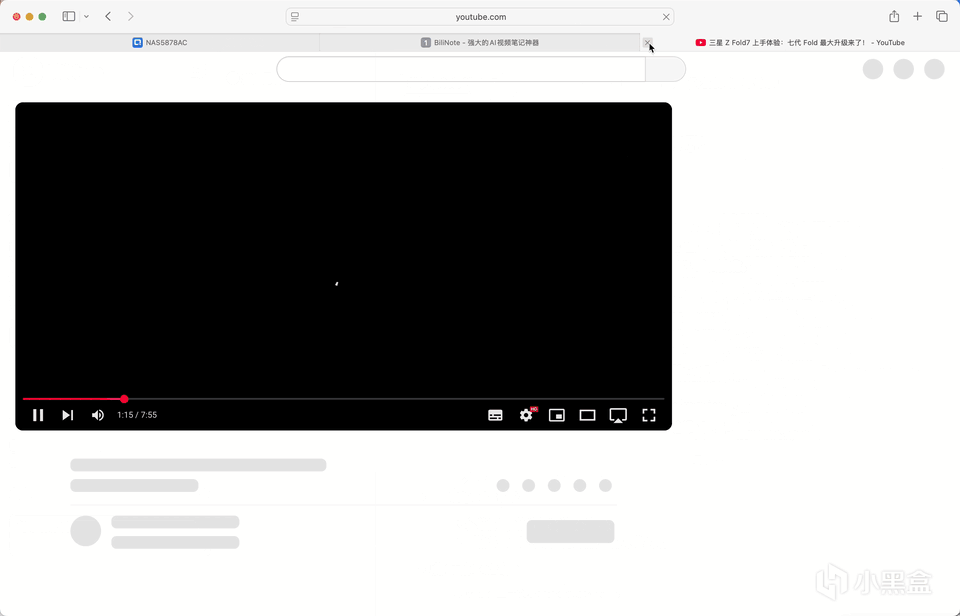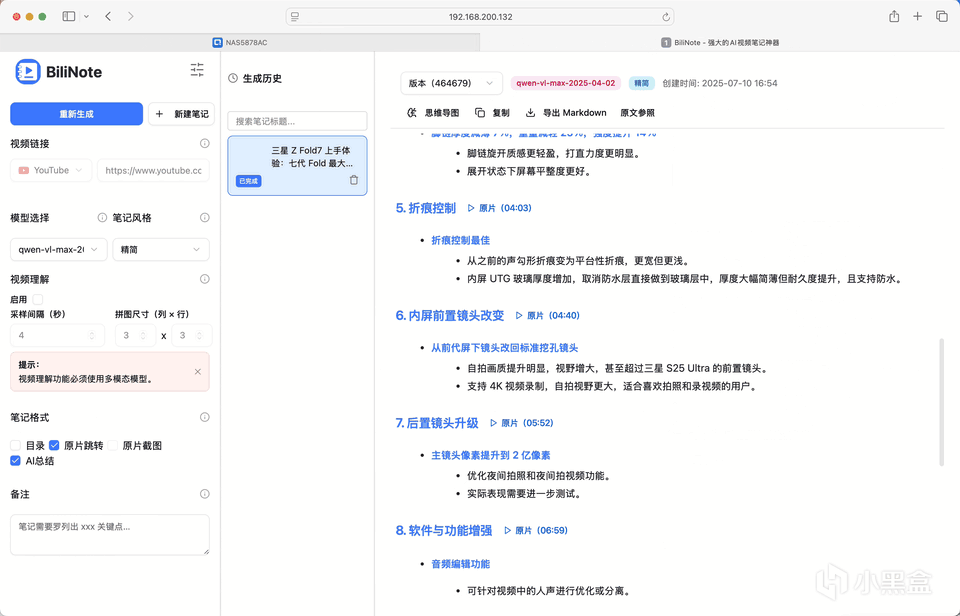
生成的效果如下。可以展示为思维导图,支持直接内容复制,可导出为Markdown,支持原文参照。点击时间戳,便可跳转到对应的章节进行阅读。
总结
原片跳转这个功能我个人觉得非常实用,作者应该会在后增加直接导入字幕文件的总结功能。
大家有需要的建议搞个强一些的CPU或GPU进行部署~
感谢观看,本文完。
PS:相关文件点我下载,提取码:zLQV。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















