引言
截止到10月份,國內已發佈的大型模型數量達到了238個,這一數字在6月份時僅爲79個,這意味着在短短的4個月裏,大模型的數量增長了三倍。此外,相關數據顯示,截至2023年10月,在Hugging Face平臺上可供下載的文本生成模型數量已經接近3萬。
那麼,在這麼多模型中,國產模型與國外知名的模型差距又有多大呢?與ChatGPT相比,國產模型又有哪些優勢呢?
AI模型的分類
在對各個模型作出比較前,我們先要了解模型的分類。
監督學習模型:這種類型的模型在訓練過程中需要有標籤的數據,即每個輸入樣本都有一個已知的正確輸出。常見的監督學習模型包括線性迴歸、邏輯迴歸、支持向量機(SVM)、決策樹、隨機森林等。
無監督學習模型:與監督學習不同,無監督學習的訓練數據沒有標籤,模型需要自己發現數據中的模式和結構。常見的無監督學習模型有聚類算法(如K-means)、自編碼器(Autoencoder)、受限玻爾茲曼機(RBM)等。
半監督學習模型:這類模型介於監督學習和無?監督學習之間,它可以在有限的標註數據和大量的未標註數據上進行訓練。代表性模型有生成對抗網絡(GANs)、卷積神經網絡(CNN)等。
強化學習模型:強化學習是一種通過環境反饋來學習策略的機器學習方法。在這種方法中,智能體根據其行爲的結果來調整策略以最大化某種獎勵信號。著名的強化學習模型包括Q-learning、Deep Q-Network (DQN) 和Proximal Policy Optimization (PPO) 等。
深度學習模型:這是近年來最熱門的人工智能領域之一,利用多層神經網絡處理複雜任務。常見的深度學習模型有卷積神經網絡(CNN)用於圖像處理,循環神經網絡(RNN)和長短時記憶網絡(LSTM)用於序列數據處理,以及變分自編碼器(VAE)和生成對抗網絡(GAN)等。
大語言模型:這是最近幾年興起的一種新型深度學習模型,它們通常基於Transformer架構,並經過大規模文本數據集的預訓練。這些模型有能力理解和生成自然語言,可以用於問答、翻譯、摘要等多種NLP任務。代表性的大語言模型有GPT系列(如GPT-3、GPT-4)、BERT、Turing NLG、阿里雲的通義千問等。
在本篇中主要針對國內外大語言模型進行比較評測。
榜單
儘管評測榜單的權威性仍有待驗證,但它爲我們提供了一個評估和比較大模型性能的視角。
MMLU
在國際上,MMLU(Massive Multitask Language Understanding)是廣泛使用的評測集之一。這個測試集由加州大學伯克利分校的研究人員於2020年9月發佈,包含57個不同的任務,涉及初等數學、美國曆史、計算機科學、法律等多個學科領域。這一基準測試旨在通過僅在zero-shot和few-shot設置中評估模型來衡量預訓練期間獲得的知識。這使得基準測試更具挑戰性,並更類似於我們如何評估人類。
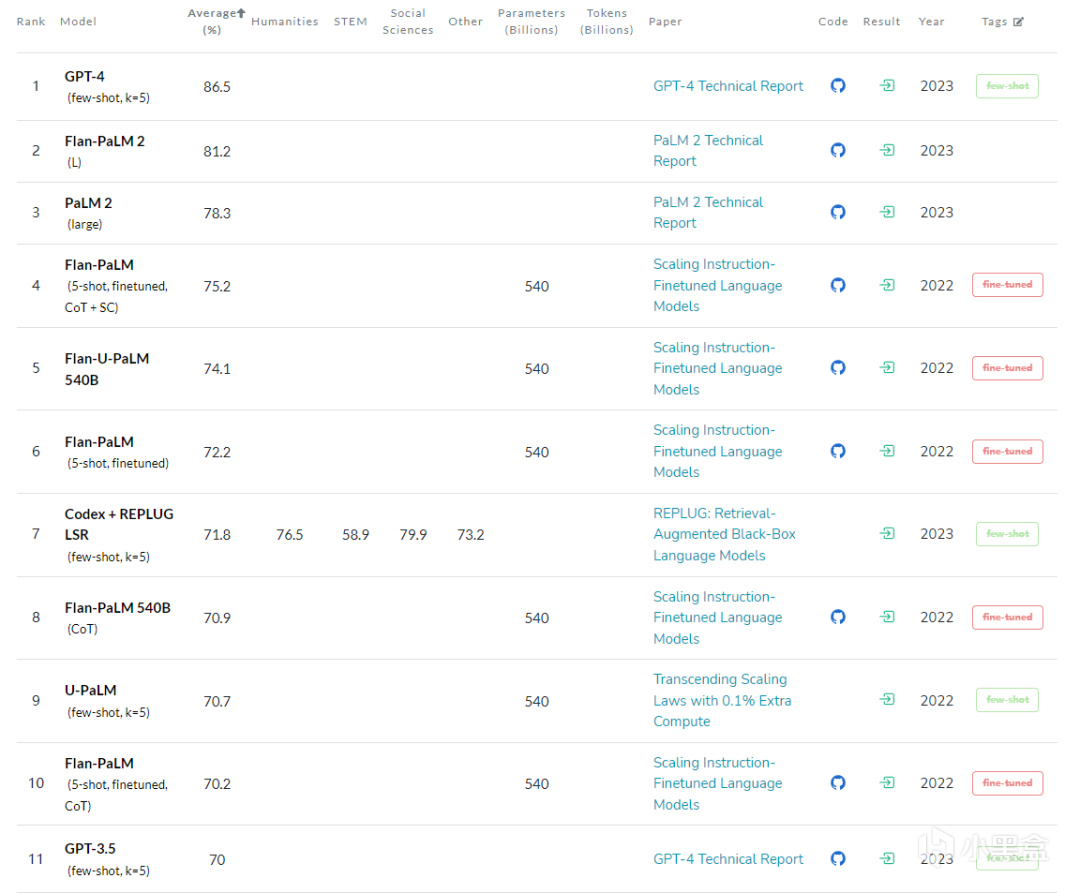
MMLU榜單
SuperCLUE
SuperCLUE,成立於2019年,是中國最早的自然語言理解測評基準社區之一。其專業性得到了廣泛認可,並且持續推動着中文語言模型評測體系的發展。該平臺推出了多個被廣泛應用的語言模型測評基準,如CLUE、FewCLUE和ZeroCLUE。
SuperCLUE是一個全面的中文通用大模型綜合性測評基準,包括多輪開放問題測評(SuperCLUE-OPEN)和三大能力客觀題測評(SuperCLUE-OPT)。這些測試旨在評估模型在中文能力上的表現,涵蓋了專業知識技能、語言理解和生成、AI智能體以及安全四大能力維度的上百個任務。
比起MMLU,SuperCLUE所得出的評測結果顯然更加適合國內環境。
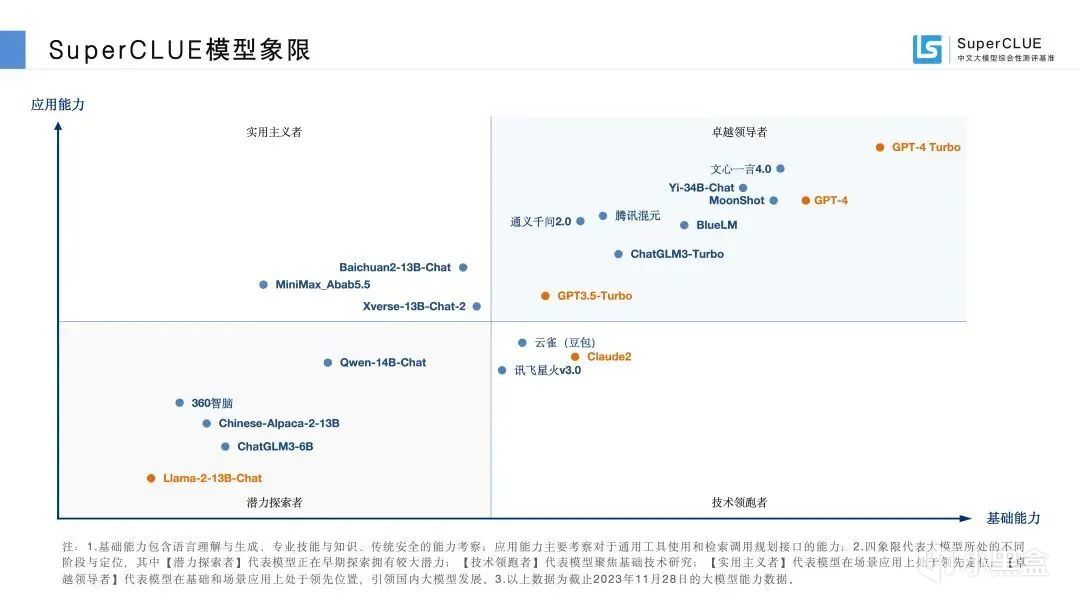
SuperCLUE模型象限
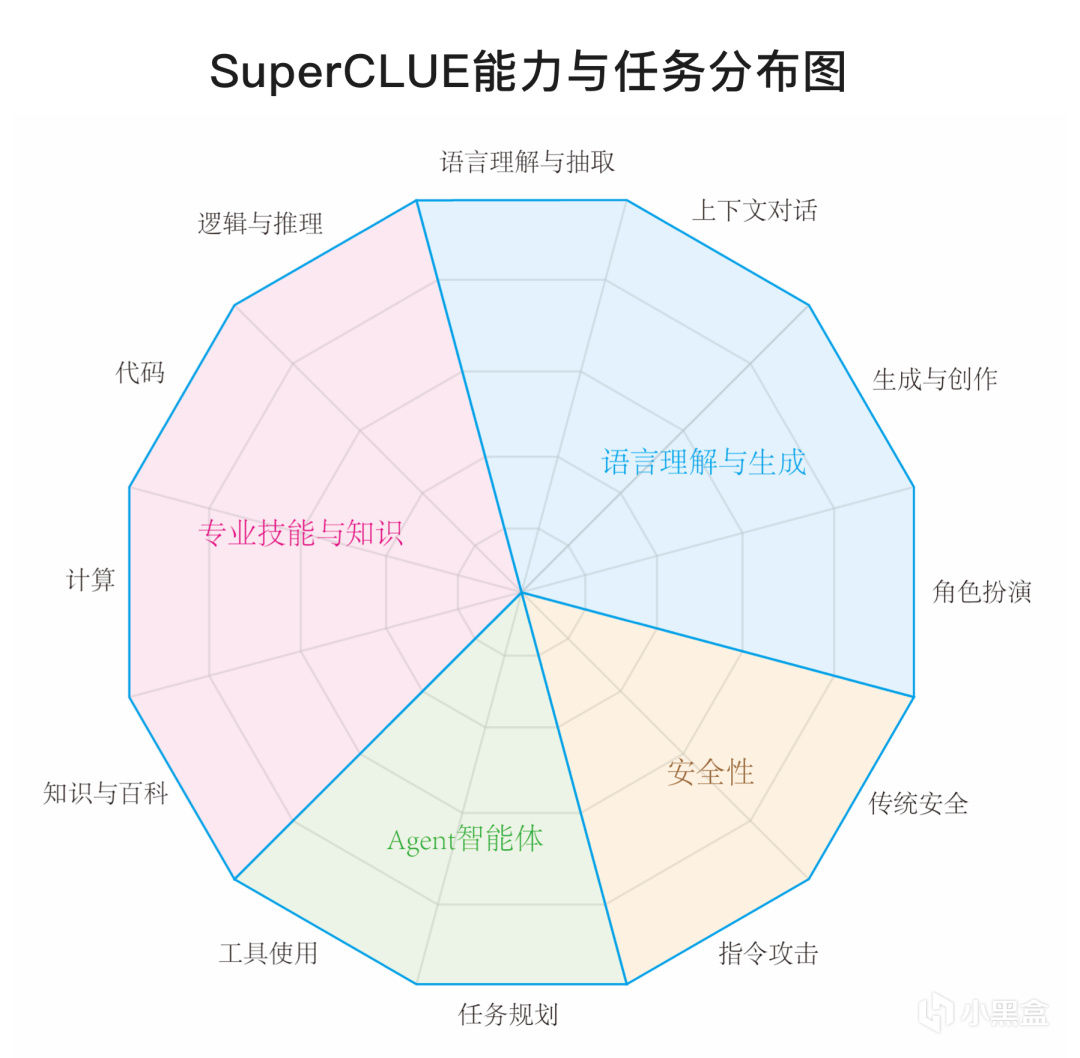
SuperCLUE評測方向
SuperCLUE每月都會發布榜單,11月30日,SuperCLUE發佈了中文大模型基準11月榜單。
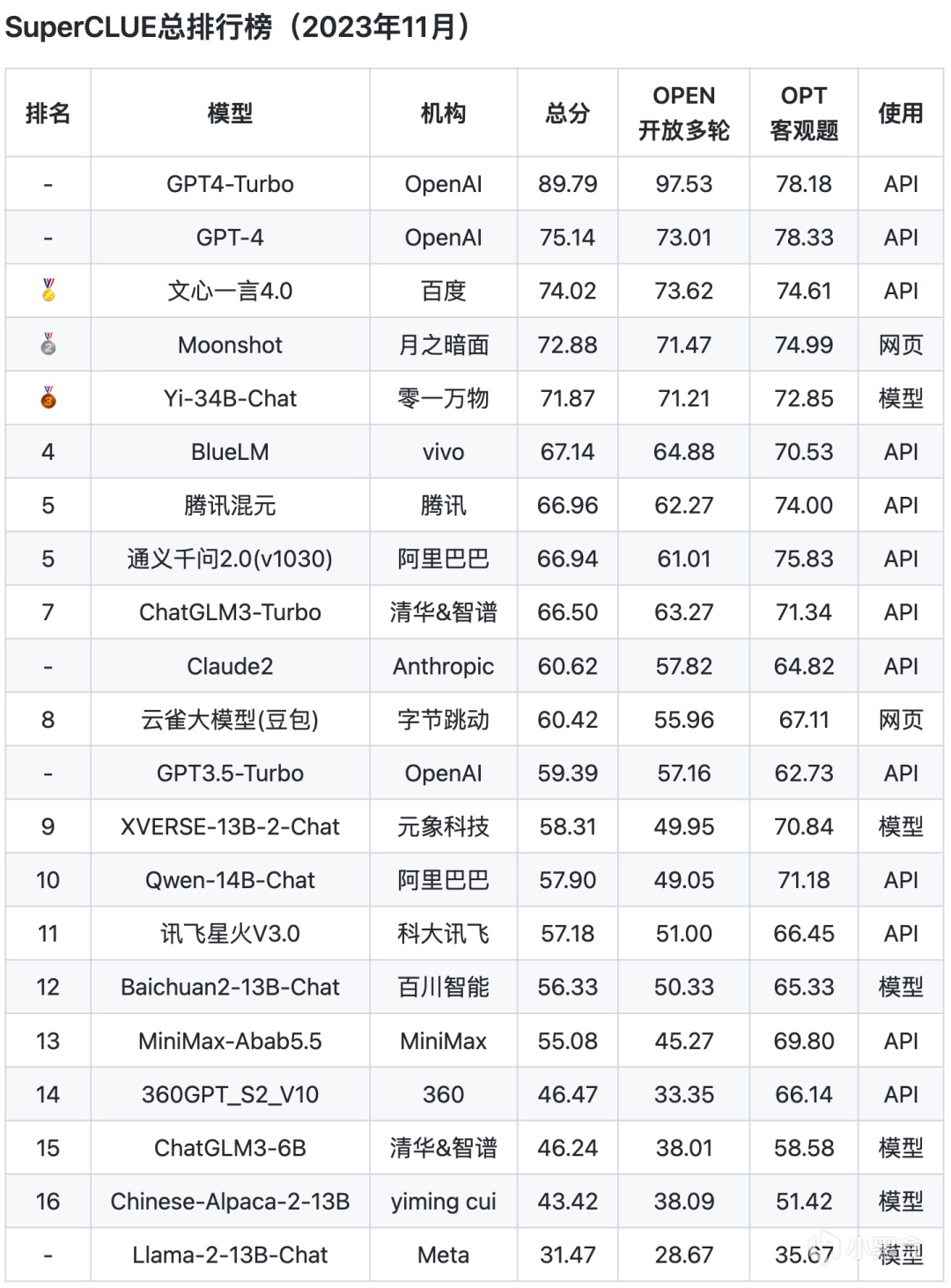
總排行榜
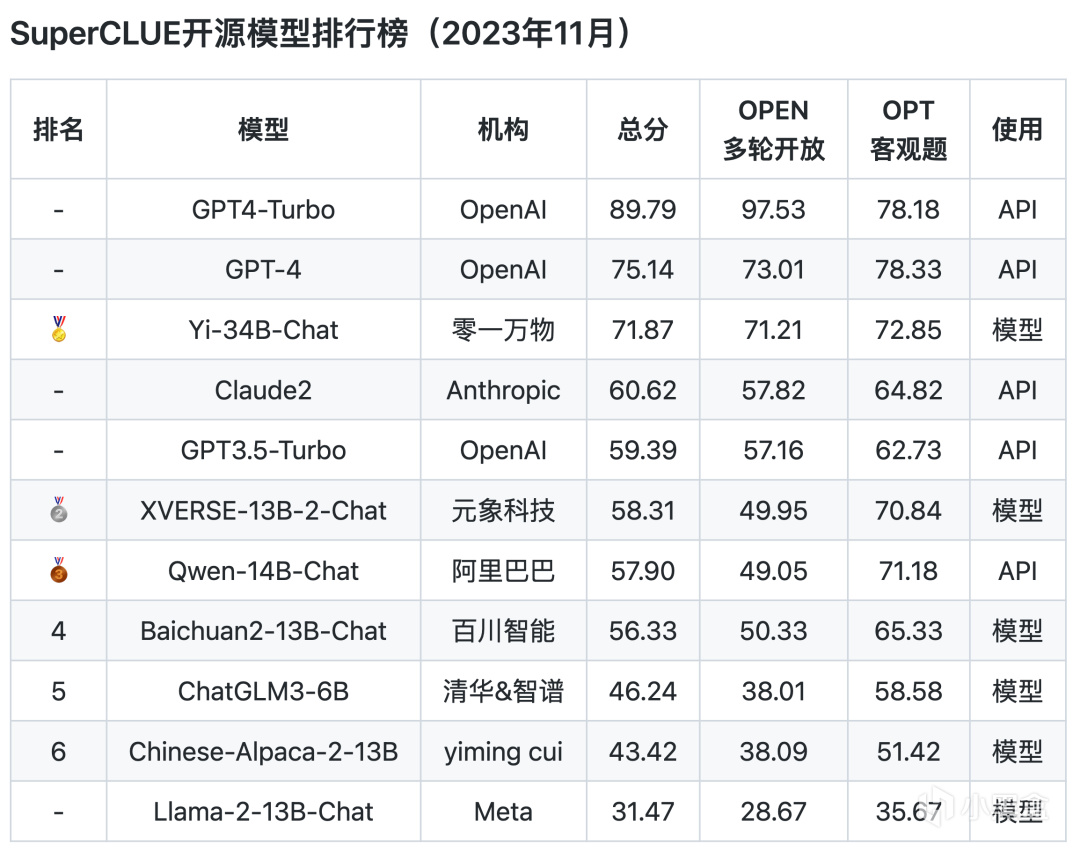
開源模型排行榜
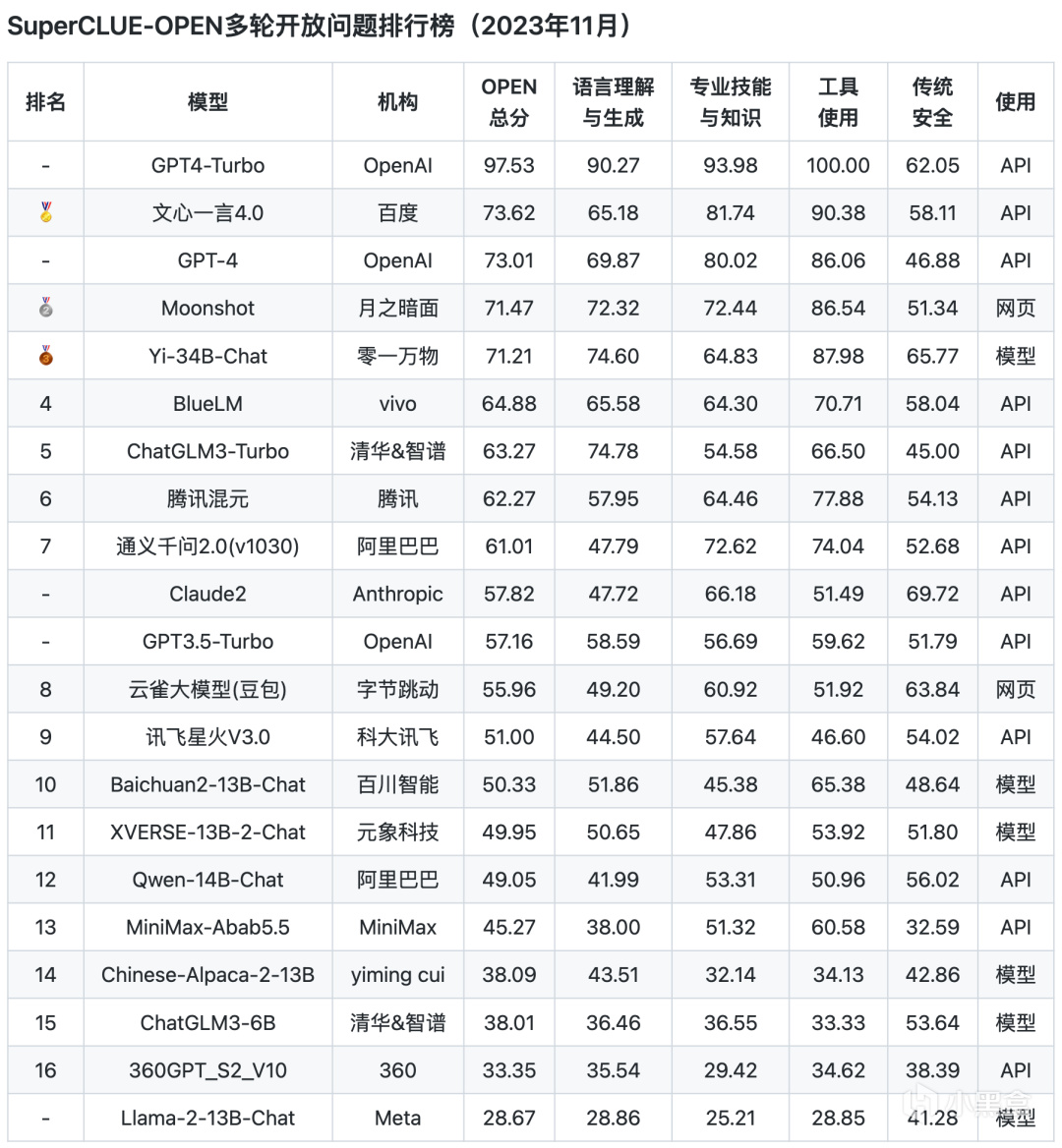
多輪開放問題排行榜
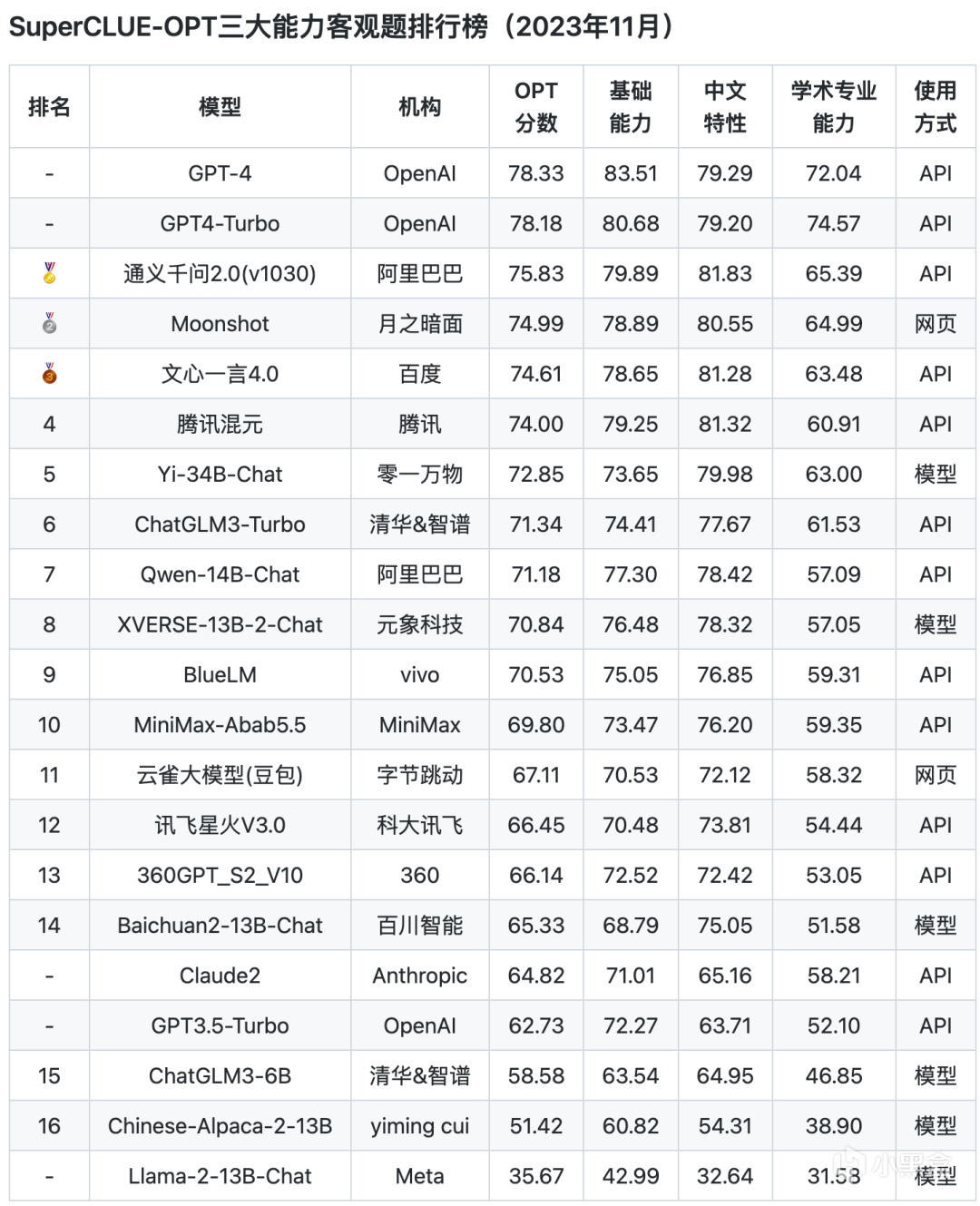
三大客觀能力排行榜
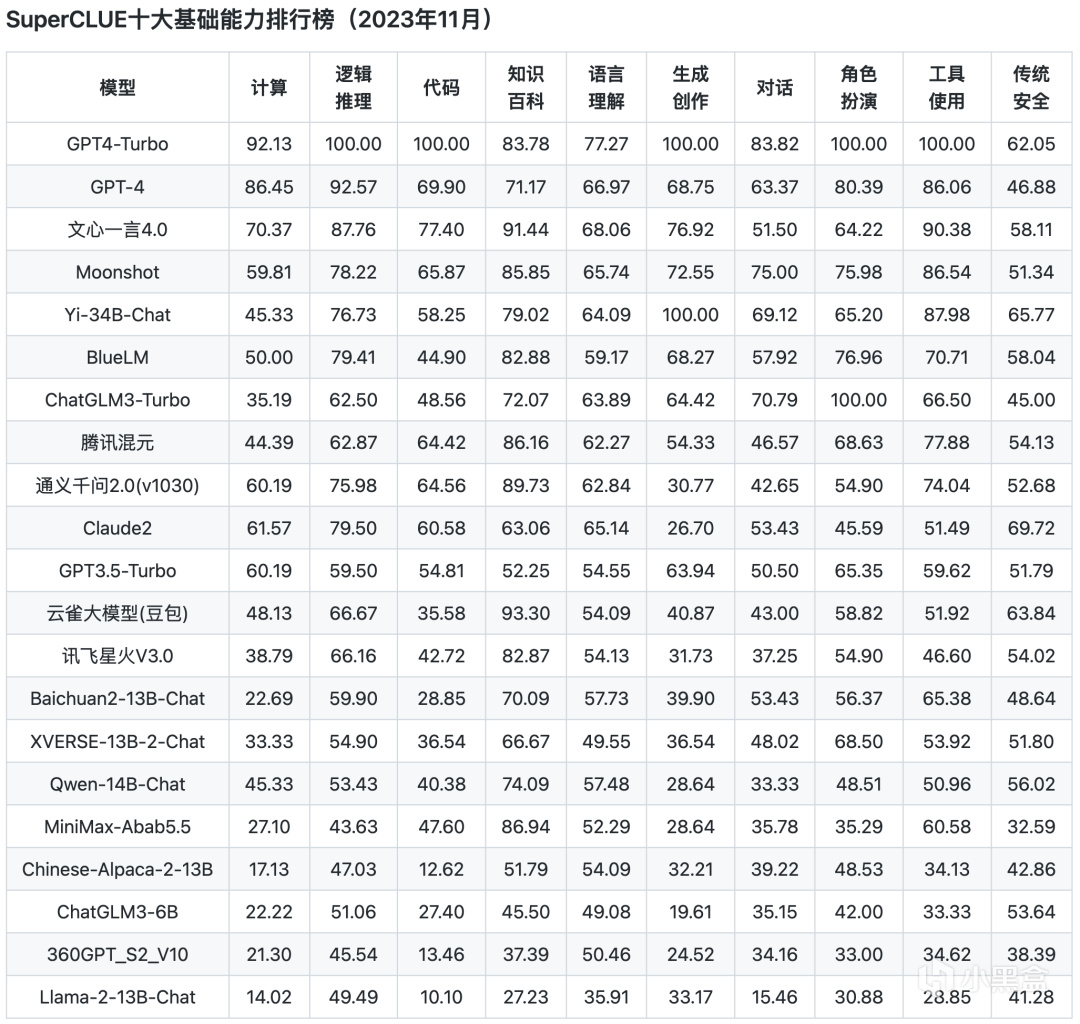
十大基礎能力排行榜
從以上評測數據來看,ChatGPT的綜合能力和單項能力都表現非常出色,各榜單中都是遙遙領先。而國內的文心一言、通義千問、騰訊混元、ChatGLM等頭部模型距離GPT都還是比較明顯。
讓人驚喜的是,零一萬物11月初發布的開源預訓練大模型Yi-34B在全球開源大模型排行榜上取得了顯著成就。
在斯坦福大學研發的大語言模型評測 AlpacaEval Leaderboard 中,Yi-34B-Chat 以 94.08%的勝率,超越 LLaMA2 Chat 70B、Claude 2、ChatGPT,在 Alpaca 經認證的模型類別中,成爲世界範圍內僅次於 GPT-4 英語能力的大語言模型。同一周,在加州大學伯克利分校主導的 LMSYS ORG 排行榜中,Yi-34B-Chat 也以 1102 的 Elo 評分,晉升最新開源 SOTA 開源模型之列,性能表現追平 GPT-3.5。
在開源模型中,Yi-34B-Chat 在英語能力上進入前十。LMSYS ORG 在 12 月 8 日官宣 11 月份總排行時評價:“Yi-34B-Chat 和 Tulu-2-DPO-70B 在開源界的進擊表現已經追平 GPT-3.5”。
作爲一家2023下半年才首度對外亮相的新公司,其發佈的模型能夠取得如此卓越的成績,無疑爲國內原本就熱度高漲的AI產業注入了一劑強心針。這一成就不僅彰顯了該公司在技術研發方面的實力和創新能力,也進一步提振了市場對AI行業的信心。(儘管Yi-34B有些爭議)
路且長
在GPT3.5被端上餐桌前,AI似乎一直在幕後默默工作,鮮有引起公衆關注的突破性產品。儘管如此,人工智能已經在我們的生活中發揮着重要作用,包括推薦系統和自動駕駛等技術。
當GPT-3.5在全球範圍內引發熱潮時,許多人不禁思考:“爲什麼中國沒有出現類似ChatGPT的產品?”其實,不僅在中國,德國、英國、法國等歐洲國家也面臨着同樣的問題。這反映出全球範圍內的創新和技術領導權之爭。
對於中國而言,算力是制約AI模型發展的重要因素。目前,國內大模型在算力方面與國際先進水平存在較大差距,這是阻礙我國大模型發展的客觀原因。沒有足夠的算力基礎,後續的算法研究和開發將難以進行。
算力需求主要包括訓練算力和推理算力。根據公開數據,ChatGPT的訓練算力消耗巨大,達到了3640PF-days(相當於每秒計算一千萬億次,需要計算3640天)。換算成英偉達A100芯片,單卡算力約爲0.6P,在理想情況下總共需要約6000張,考慮互聯損失後,則需要一萬張A100作爲算力基礎。
以A100芯片每張10萬人民幣的價格計算,硬件投資規模將達到10億人民幣。此外,數據中心還需要推理算力以及服務器等設施,總規模應在100億人民幣以上。
根據2020年全球計算力指數評估報告,美國以75分位居榜首,擁有Google、Facebook、Amazon、Microsoft、Apple等互聯網巨頭。中國得分66分,排名第二。中美兩國在AI算力支出佔總算力支出的比例均超過10%。截至2021年底,我國在用數據中心服務器規模達到1900萬臺,存儲容量爲800EB(1EB=1024PB),算力總規模超過140 EFlops(每秒浮點運算次數),過去五年年均增速超過30%,全球排名第二。
歐盟內部,德國、英國、法國等國的計算力指數分別爲54分、53分和51分,分別位列全球第三、第四和第五。歐洲也有知名的軟硬件企業,如SAP、ASML、ARM等。
算力的發展離不開算力芯片的支持。算力芯片種類繁多,包括GPU、DPU、NPU等,各有特點和優勢。對於人工智能大模型所需的芯片來說,更高的信息處理精度和計算速度至關重要。在超級計算領域,雙精度浮點計算能力FP64是衡量高計算能力計算性能的關鍵指標。英偉達的H100和A100是目前唯一具備這些能力的芯片。
2022年10月,美國限制英偉達和AMD向國內出售高性能計算芯片,國內互聯網大廠意識到風險,去找英偉達購買。但因爲從下單到拿貨的週期較長,國內互聯網廠商的優先級較低,國內互聯網大廠買到的A100以及H100芯片數量是比較有限的。
國內AI芯片已經批量生產的產品,大多都是A100的上一代。各公司正在研發的相關產品,如崑崙芯三代、思遠590、燧思3.0 等,都是對標A100,但由於“實體清單”的限制以及研發水平的原因,都還沒有推到市場。
美國製裁的背景下,國產化替代方案需要積累,在很長一段時間內,芯片與算力會是國產大模型與ChatGPT之間一道巨大的鴻溝。
算力問題外,語言問題也很影響AI模型的訓練。即使在國內大語言模型快速發展之際,互聯網中的中文訓練集仍然相對較少,而且語言的複雜性使得中文模型的訓練難度比英文更高。雖然中國擁有龐大的互聯網用戶基數和豐富的數據資源,但在自然語言處理(NLP)領域,尤其是在大規模預訓練模型的研究方面,仍面臨一些挑戰。
————————
一些AI相關的站點可以通過這個AI導航站訪問:ai.kuaida.link
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















