系列前文:
引子
如果你看過本系列的前兩篇,你應該還記得:
我們的"老式電視機"(FSM,有限狀態機)只會一件事:換頻道。簡單、粗暴,但也傻得令人心疼。一個被遙控器綁架的電視,永遠不知道什麼叫"意外"。
接着是"管家"(Behavior Tree,行爲樹)。笨蛋管家比電視高級一點,他手裏有一份帶分支的待辦清單。優先級明確了,步驟清晰了,他終於不會在路口左右橫跳了。
但問題是……
新問題:清單有了,但先幹哪個?
想象一下:你給管家下了三條指令
"如果冰箱空了,去超市買菜"
"如果水槽有碗,把碗洗了"
"如果有人在敲門,去開門"
這三件事同時發生了。冰箱空了、水槽有碗、有人在敲門。
管家站在門口,手裏拿着洗碗布,背上揹着購物袋,滿臉困惑。他的待辦清單列明瞭每件事都要做,但面對同時湧來的任務,他不知道該先做哪件。
於是他只能隨機切換。去開門 -> 想起要買菜 -> 衝到門口 -> 又想起碗沒洗完 -> 衝回廚房 -> 門鈴又響了 -> 又衝回去……管家還是那個笨蛋。

管家的困境,正是FSM和BT結構上的限制。
FSM微波爐只有"加熱""解凍""燒烤"三檔。你把菜放進去只能選一個按鈕,微波爐不管菜涼了還是糊了。
BT菜譜能讓你按步驟來,先切菜、再熱油、再翻炒。但如果客人突然說不喫辣了,菜譜不會告訴你怎麼辦。
菜譜告訴他每道菜都要做,但沒告訴他先上哪道。 廚房裏三個竈都在喊"快處理我",而他只有兩隻手。
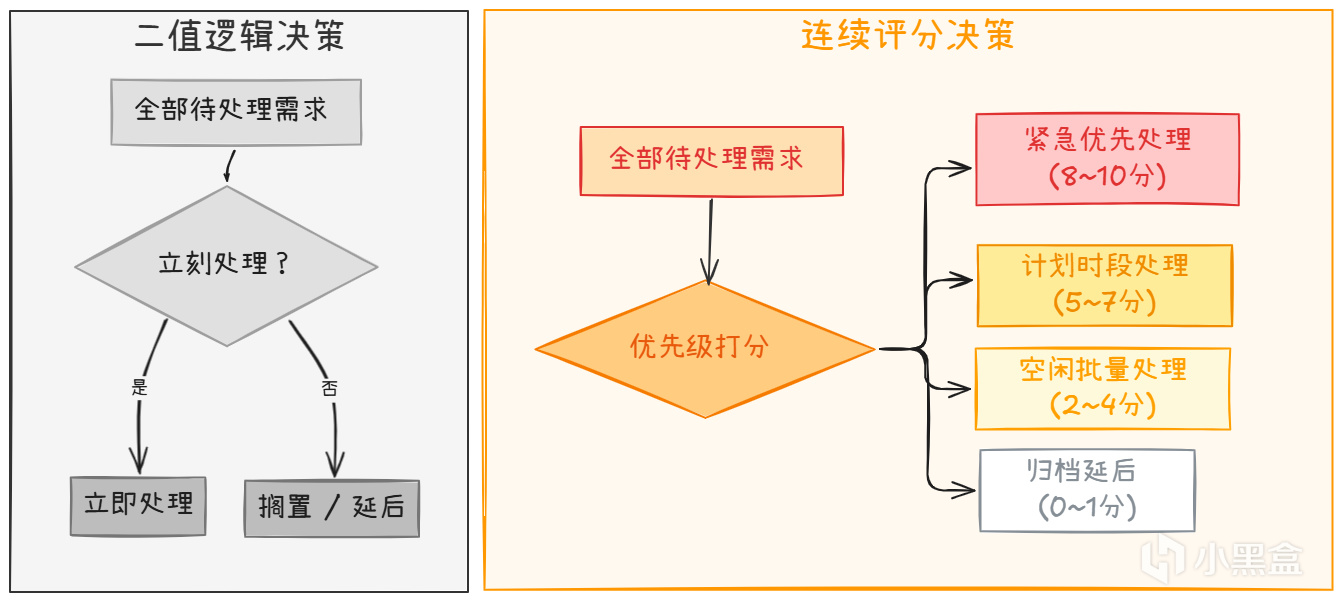
從"該不該"到"有多值得"
關鍵的一步轉變在於提問方式:不要問"該不該做",要問"現在有多值得做"。
冰箱空了 -> 買菜得分 0.95(非常值得)
水槽有碗 -> 洗碗得分 0.80(也值得)
整理書架 -> 得分 0.30(等等再做也行)
這就是 Utility AI(效用AI) 的做法:給每個決策打分,選最高分。
但打分這件事本身沒那麼簡單。
"給我一組參數,我就能撬動整個世界。" 想法很美好,但現實很骨感。
效用值和輸入參數之間很少是簡單的正比關係,這個世界是非線性的。
第一章:當"是/否"不夠用了
FSM/BT的底層:二值邏輯
FSM和BT共享同一個基礎:布爾邏輯。
條件要麼是 true,要麼是 false。敵人距離 < 10 米?是 -> 攻擊。否 -> 巡邏。
就像是一盞燈泡:要麼亮,要麼滅。乾淨利落,毫不含糊。 傳統FSM/BT架構下的AI,其判斷是絕對的。
一點補充:嚴格來說,BT的Decorator節點(如Utility Condition)可以引入連續值判斷,讓BT具備"有多符合條件"的能力——但這屬於BT的擴展用法,不是基礎架構的固有特性。標準的BT Condition節點仍然是布爾判斷。第七章會詳細討論這種混合模式。
現實世界不是二值的
現實世界並非非黑即白。想象一個場景:
你是一個弓箭手,你的箭囊裏還剩最後一支箭。前方有三個目標
目標A:一個普通士兵,距離5米(一箭秒殺)
目標B:一個將軍,距離20米(三箭才能殺,但獎金豐厚)
目標C:一隻正在逃跑的信鴿(一箭就能射下來,但不確定值不值得)
FSM的邏輯會寫成這樣:
if (有箭 and 有敵人) -> 攻擊最近的敵人
於是你永遠朝着最近的士兵射箭,哪怕將軍就在旁邊。因爲你沒有"評估目標價值"這個功能。
二值邏輯的問題在於: 世界是連續的、模糊的、需要權衡的,但你的AI只能選擇"是"或"否"。
就像你的微信工作羣,每個羣都在說"快處理我",但你沒辦法同時回覆所有人 ( ;∀;)。你需要一個優先級評分系統。
這種優先級缺失的問題,在早期遊戲中表現得尤爲明顯。
反例:FSM做出來的"弱智AI"
如果你玩過2000年代初期的遊戲,你一定見過這種AI:
敵人站在原地,你繞到他背後,他不會轉身,因爲他只有"發現玩家 -> 攻擊"這一條路徑
守衛會在哨塔之間來回走,哪怕你在他面前把同伴殺了——他不在"巡邏"狀態之外的狀態
敵人的攻擊模式是固定的三連招,打完就站着不動
這些"弱智時刻"的根源只有一個:設計者把所有可能性用if-else寫死了,但遊戲裏可能出現的情況遠比預設的多得多。 (´-ω-`) 誰還沒寫過幾個死if-else呢…
正如資深遊戲AI專家Dave Mark在《Behavioral Mathematics for Game AI》中所傳達的核心思想那樣:
FSM並非萬能——行爲不是離散的,而是連續的。它需要更靈活的建模方式。
這恰如其分地概括了爲什麼我們需要Utility AI。
""好,現在我知道怎麼打分了。給每個選項打分,選最高的。但是這個分數該怎麼算?"
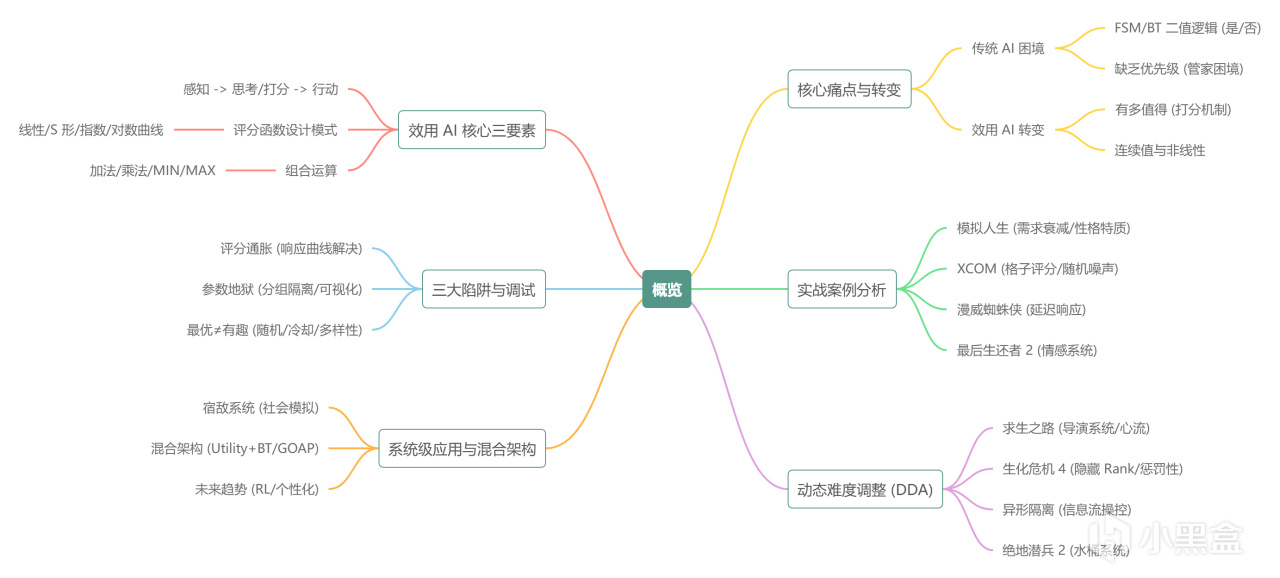
第二章:Utility AI核心三要素
好了,上硬菜。
Utility AI的核心就是三個東西:
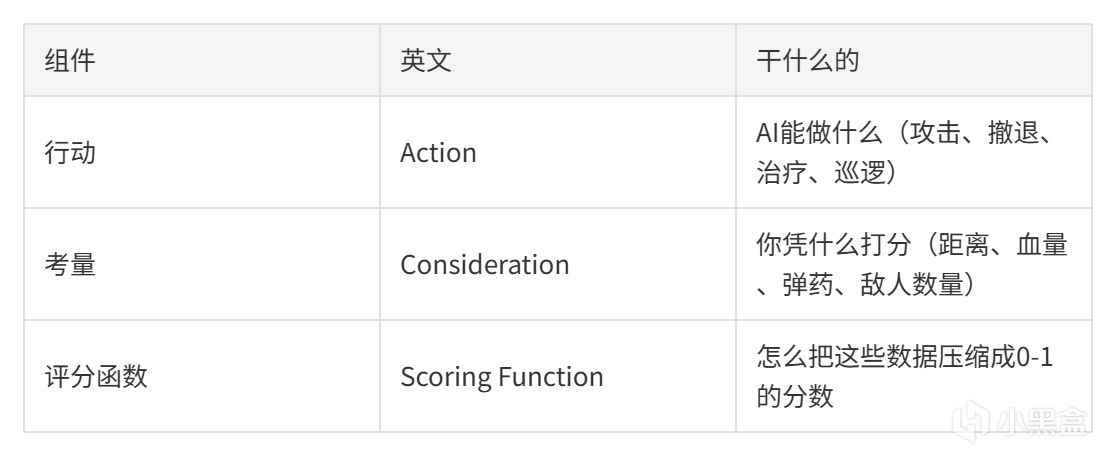
2.1 核心流程:Sense -> Think/Score -> Act

這不就是早上起牀的你嗎 ( ˘ω˘ )
Sense:鬧鐘響了,窗外下雨,被窩溫度35°C
Score:起牀得分0.20,再睡5分鐘得分0.95,請病假得分0.80
Act:再睡5分鐘(每天都是最高分)
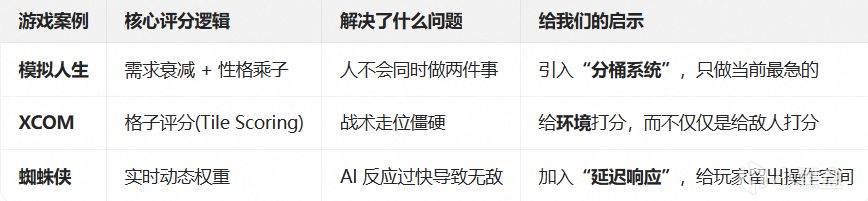
2.2 經典案例1:《模擬人生》——Needs-Based AI
《模擬人生》把需求量化爲數值,再用分值驅動行爲,這套設計後來被大量模擬經營遊戲借鑑。
每個Sim(小人)有八大需求:
飢餓、精力、社交、娛樂、膀胱……
每個需求被量化成一個0-100的數值
當Sim決定做什麼時,系統會遍歷所有可能的行爲(喫飯、睡覺、找人聊天、玩遊戲),對每個行爲算一個"滿足度分數":
喫飯得分 = (飢餓值 - 50) * 0.8 + 隨機抖動
睡覺得分 = (精力值 - 30) * 0.7 + 隨機抖動
得分最高的行爲勝出。
但這裏有一個細節問題:如果Sim的飢餓分和社交分都很高怎麼辦?它會變成一個"在冰箱和電話之間反覆橫跳"的負智人。
爲了解決這個問題,《模擬人生》引入了 Bucketing System(分桶系統),這是一種類似 Dual-Utility Reasoning(雙效用推理)的設計思路。
其核心機制是:將所有動機按當前效用值連續排序,分數最高的動機被歸入一個桶。Sim只會在當前桶內的行爲中尋找可執行的操作,低分桶完全不被考慮。
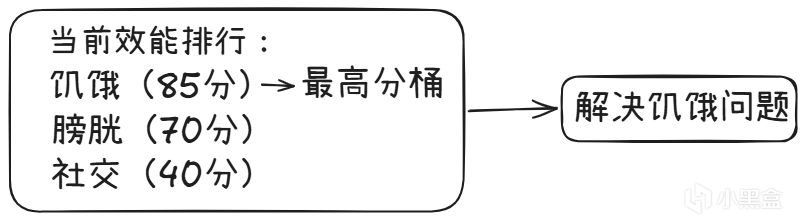
如果最高分桶中沒有可執行的操作,Sim纔會看下一個分數段的桶。這就是連續分組,而非固定層級——桶的組成隨情況動態變化。
它用排序加分桶做決策漏斗,比FSM靈活得多。
一個真正的打工人會先把所有活按緊急程度排序,手裏一萬個任務也只有一個「最緊急的」搞定了再看下一個。
桶的組成隨時變化,哪個需求最急就處理哪個。
深挖一下:Robert Zubek的需求衰減曲線
如果你覺得上面的需求系統只是"餓了就喫飯"這麼簡單,那你就低估了Maxis的設計功力。
根據Robert Zubek在《Game Programming Gems 8》中的分析(Zubek曾參與《模擬人生3》原型開發,是Needs-Based AI理論的重要總結者),《模擬人生》的需求系統背後有更精細的數學設計。以下數值爲示意性示例,用於說明設計原理,並非Maxis官方工程參數:
需求衰減曲線(Decay Curve):每個需求不是線性下降的,而是有自己的衰減速率。
膀胱需求:衰減速率 0.8/小時(攢得快,憋不住)
飢餓需求:衰減速率 0.3/小時(慢餓)
社交需求:衰減速率 0.2/小時(可以獨處一段時間)
Character Trait(性格特質)乘子:Sim的性格特質會作爲乘子影響需求和行爲的評分。
"愛乾淨"特質 -> 清潔需求衰減速率 × 1.5(髒得更快)
"懶散"特質 -> 所有需求的衰減速率 × 0.8(啥都不着急)
"社交達人"特質 -> 社交行爲評分 × 1.3(更喜歡聊天)
同一套需求系統,配上不同的衰減速率和特質乘子,能產生截然不同的行爲模式。 一個"愛乾淨的社交達人"Sim和一個"懶散的獨行俠"Sim,雖然底層是同一個Utility引擎,但表現出來的行爲卻判若兩Sim。
在宿舍時,你和你的室友肚子餓了都會去找喫的,但室友可能先把碗洗了再喫("愛乾淨"特質乘子高),而你直接點外賣("懶散"特質讓做飯行爲的評分很低)。
2.3 《XCOM: Enemy Unknown》——戰術Utility評分
Firaxis的《XCOM》展示了Utility AI在回合制戰術場景中的另一種用法。在這款回合制戰術遊戲中,每個敵方單位每回合需要決定:打誰?用什麼武器?要不要用技能?
這不是一個可以預判的決策——因爲戰場局勢每秒都在變。
XCOM的做法是:給每個潛在目標算一個"威脅評分"。
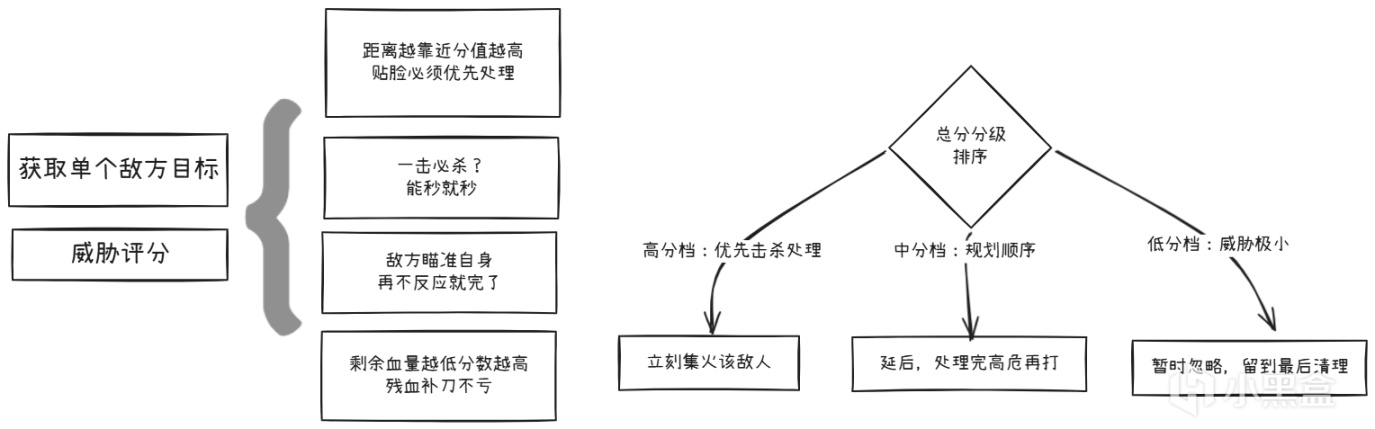
然後AI對每個可能的行動(射擊A、射擊B、投雷、撤退)都算一個utility分數,選最高的。
但如果AI每次都選"最優解",玩家就會發現敵人的行爲模式,然後反過來利用。
所以XCOM在評分里加入了隨機噪聲(以下爲行業常見的噪聲注入模式,非官方精確數值):
最終得分 = 計算得分 * (0.8 + 隨機(0, 0.4))
這保證了AI不會100%可預測,偶爾會做出"不是最優但更有人味"的決策。
這招可以叫作"脫罪隨機數"(plausible deniability)。如果AI做出了一個看似愚蠢的決策,系統可以解釋爲"它算過,只是噪聲太大了"。"我改了一個小參數……奇怪,怎麼全都崩了?" ( ;∀;) ノ
深挖一下:Alex Cheng GDC 2013的Tile Scoring System
Alex Cheng在GDC 2013的AI峯會聯合Panel——"AI Postmortems: Assassin's Creed III, XCOM: Enemy Unknown, and Warframe"上做了XCOM部分的分享,其中透露了XCOM更底層的設計細節。
Tile Scoring System(格子評分系統):
XCOM的戰場被劃分爲網格狀戰術格(tile)。AI不僅要決定"打誰",還要決定"走到哪"。每個格子也有自己的utility分數:
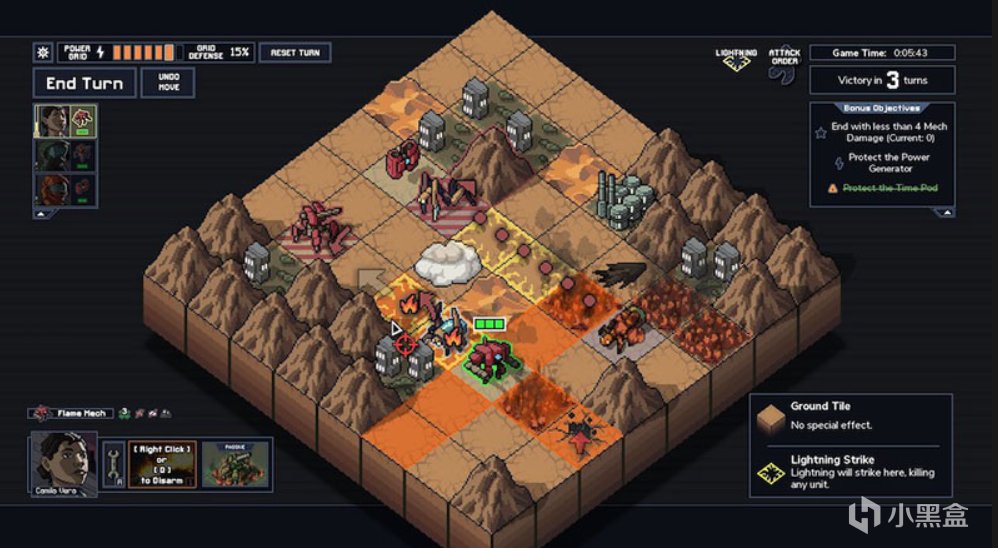
爲了直觀性,這裏使用了《陷陣之志》
格子評分考量因素:
掩體評分:全掩體 +0.4、半掩體 +0.2、無掩體 -0.1
高度評分:高地 +0.3(射擊加成)、低地 -0.1
側翼暴露:暴露在敵人火力下 -0.5
與當前目標的距離:射程內 +0.3、射程外 -0.2
視野覆蓋數:能看到N個敵人 -> +N×0.1
AI會爲每個可行走格子算分,選最高的。但這還不夠——因爲AI需要規劃"多步行動"。
Hidden Movement機制:
XCOM的AI還有一個"隱藏移動"階段。在玩家看不到的回合,AI會做多步模擬:
這個"模擬-執行"循環讓XCOM的AI看起來有戰術眼光,而不僅僅是"誰近打誰"。 XCOM的AI下棋能看三步。你看到的是一個敵人走到你面前,實際上它已經預計了數種不同的開火方案。
2.4 經典案例3:《漫威蜘蛛俠》——敵人實時評分
Insomniac Games在《漫威蜘蛛俠》中把Utility AI用在了敵人決策上(見GDC 2019 "Marvel's Spider-Man AI Postmortem")。每個敵人在戰鬥中持續對蜘蛛俠做評分:
實用性評分:我手裏的武器能不能打到蜘蛛俠?(火箭筒得分高,手槍得分低)
緊急性評分:蜘蛛俠離我多遠?他是不是正在打我?
位置評分:我在高處還是低處?有沒有障礙物?
當蜘蛛俠跳到你頭頂時,所有地面敵人的"攻擊得分"會驟降(蜘蛛俠太快了,瞄不準),而高空敵人的"攻擊得分"會飆升(終於能打到你了)。
玩家感受到的是:敵人不會傻站着被打,他們會根據局勢實時調整策略。
不過Insomniac的設計師很快意識到一個反直覺的問題:AI越聰明,玩家越挫敗。
所以他們給Utility AI加了一個"延遲響應":即使敵人判斷出了最優策略,也要等一小段時間才執行。
Adam Noonchester的GDC演講提到了一個"momentary enemy idle timer"機制,具體延遲時間按遊戲節奏動態調整。 這讓蜘蛛俠有了喘息空間,也讓玩家的操作更有意義。
畢竟遊戲要的是好玩,而不是難玩。
2.5 評分函數設計模式:愛玩矢量的大爺
前面我們一直在說"算分",但評分函數本身有很多講究。 同樣的輸入數據,用不同的曲線處理,會得到天差地別的結果。
下面來看看評分函數的幾種常見寫法。
線性曲線(Linear)
最簡單的評分曲線:輸入和輸出成正比。
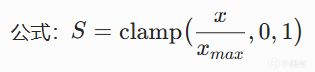
例子:血量百分比 -> 治療緊迫度。血量50% -> 得分0.50,血量30% -> 得分0.30。
適用場景:當輸入和輸出關係是"越怎樣就越怎樣"時。比如距離越近,攻擊得分越高。
問題:線性曲線沒有"拐點",AI的決策邊界很模糊。比如一個敵人從15米走到10米,得分從0.3到0.7,中間的每一米變化都是均勻的。這在某些場景下不夠"戲劇性"。
S形曲線(Sigmoid)
在中間區域陡峭,在兩端平緩。
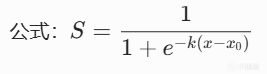
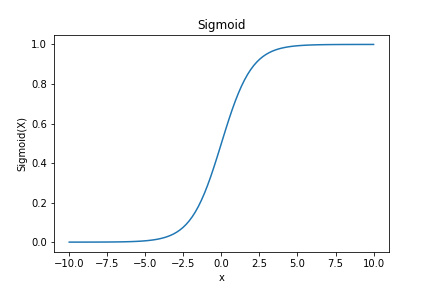
其中k控制陡峭度,中點是曲線拐點。
例子:血量在30%附近時,治療緊迫度"突然飆升"。血量從40%降到35%,治療分從0.3跳到0.7,因爲30%是"危險線"。
適用場景:當你有"閾值感覺"時,即在某個臨界點附近,AI的態度應該"急劇轉變"。
遊戲案例:在戰術遊戲中,撤退決策常用S形曲線。當己方血量 > 50%時,撤退分很低;但一旦低於30%,撤退分急劇上升。這模擬了"臨陣脫逃的30%紅線",士兵在安全時絕不撤退,瀕死時拼命逃跑。
指數曲線(Exponential)
低端平緩,高端陡峭,呈現滾雪球效應。
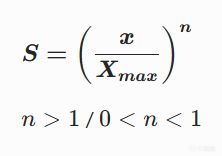
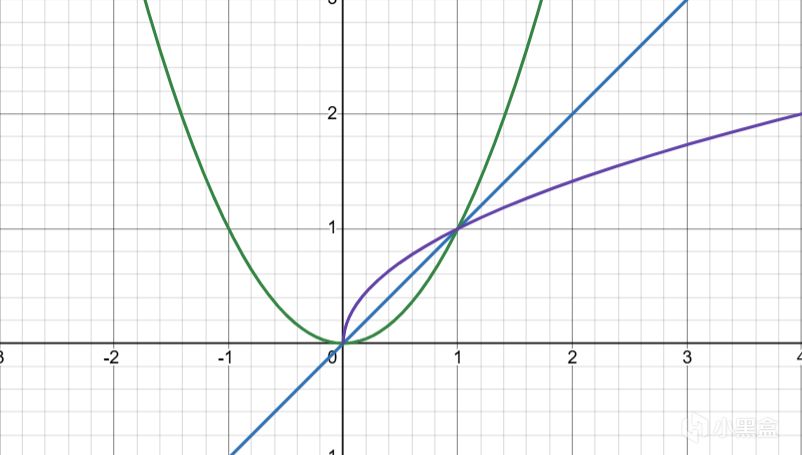
當 n > 1 時,曲線向下彎曲(高分更難達到);當 0 < n < 1 時,曲線向上彎曲(更容易達到高分)。
例子:彈藥稀缺度。還有90%子彈 -> 補彈得分0.01;還有10%子彈 -> 補彈得分0.85。因爲最後10%的子彈比前90%都"值錢"。
適用場景:當資源匱乏時,稀缺度的感知非線性上升。
注意 :嚴格數學上這是冪函數(Power Function),但遊戲行業常將 (x)^n 稱爲指數曲線(Exponential Curve)。真正的指數曲線公式爲 a^x 。
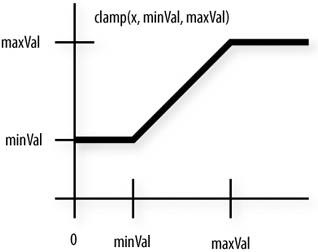
Unity 其實嚴格區分了兩者 : PowerEase f(t) = t^p (冪函數)ExponentialEase → f(t) = 2^(10(t-1)) (真指數函數)
對數曲線(Logarithmic)
低端陡峭,高端平緩,呈現邊際遞減效應。
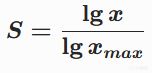
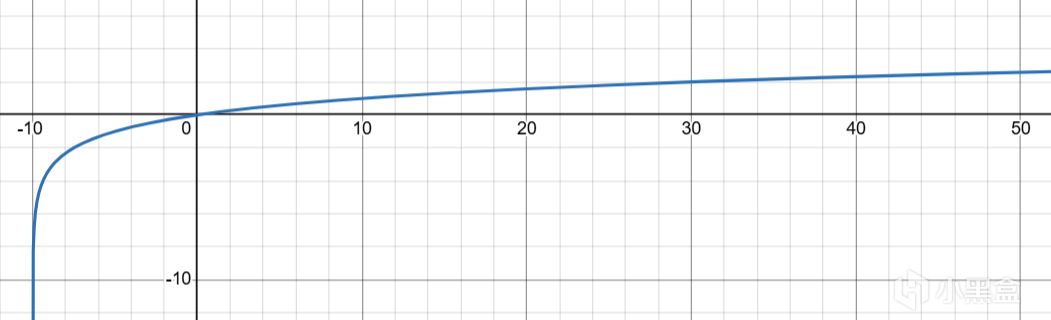
此公式可實現0→1的對數歸一化,實踐中同樣有效。
例子:在《模擬人生》中,社交行爲對社交需求的滿足。從0到20分鐘社交,滿足度飆升(你終於有個人說話了);從60到80分鐘,滿足度幾乎不漲(你已經聊累了)。
適用場景:當"有比沒有好得多,但多了也沒什麼用"時。
選擇評分曲線就是在選調料:線性是鹽(百搭但普通),S形是辣椒(只在關鍵時刻爆發),指數是糖(越到後面越甜),對數是醋(第一口酸爽,後面就沒感覺了)。 一名好的廚師知道什麼時候放什麼調料。
2.6 考量因素組合的藝術
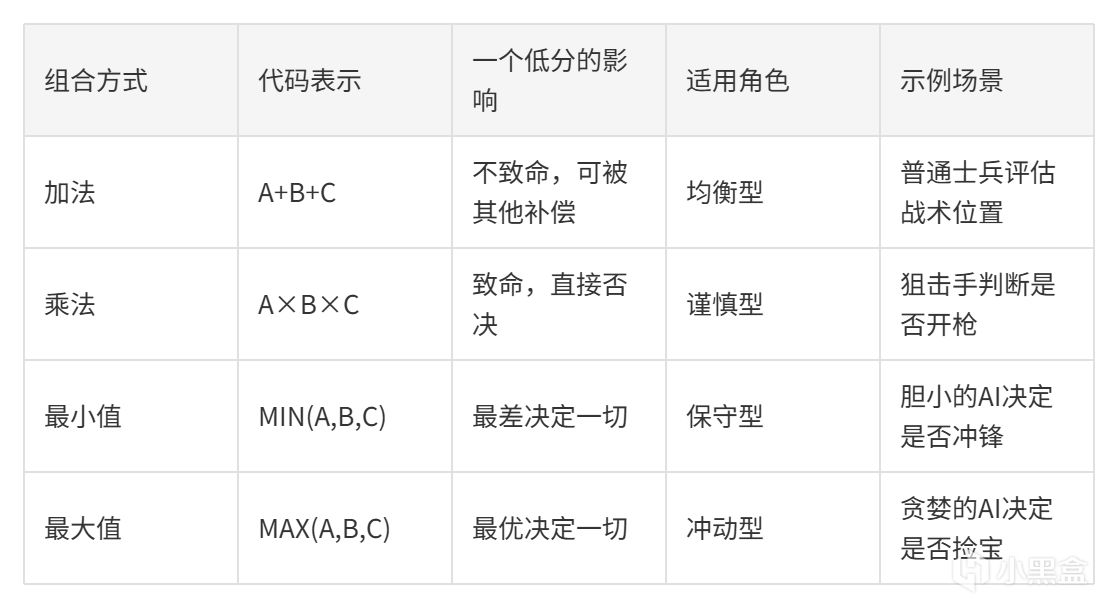
單條曲線只是基礎。真正的挑戰在於如何把多個考量因素組合成一個最終分數。
加法組合(Additive)
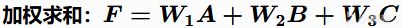
優點:直觀、好調參、一個考量得分爲0不會讓整個決策"死亡"。 缺點:分數容易膨脹,需要精確的權重配比。
例子:XCOM的格子評分就是加法組合,掩體得分 + 高度得分 + 視野覆蓋得分。即使某個格子沒有掩體(得分爲0),它仍然可能因爲高地優勢而總分很高。
乘法組合(Multiplicative)
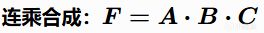
優點:任何一個考量爲0,整個決策"一票否決"。 缺點:容易導致分數向低分區壓縮(所有得分擠在底部),調參更復雜。
例子:弓箭手判斷"是否射箭" = 目標可見度 × 命中概率 × 目標價值。如果目標不可見(得分爲0),其他兩個考量再高也沒用。這就是"一票否決"的威力。
最小值組合(MIN)
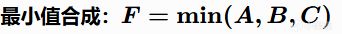
優點:最保守的策略,AI只關注最壞的情況。 缺點:可能過於謹慎,忽略整體優勢。
例子:一個膽小的AI判斷"是否衝鋒" = MIN(血量充足性, 彈藥充足性, 掩體距離)。
只要有一項很低,它就不會衝鋒,哪怕其他條件都很好。
如果讓最挑剔的食客評價來評價一桌菜,只要有一道菜不合口味,整桌都是"零分"。
最大值組合(MAX)
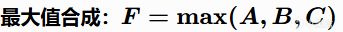
優點:最冒險的策略,AI只關注最好的一面。 缺點:容易做出魯莽決策。
例子:貪婪的AI判斷"是否去撿寶箱" = MAX(好奇心, 對寶藏的渴望, 當前裝備的缺乏)。只要有任何一個理由很強烈,它就衝過去了,儘管周圍全是敵人。
優劣對比一覽
2.7 旁路對比:F.E.A.R.的GOAP
GOAP(Goal-Oriented Action Planning)不是Utility AI,但兩者共享評分思想。
GOAP的Planner使用A*搜索在動作空間中找出一條從當前狀態到目標狀態的最短路徑,輸出的是行動序列而非單次選擇。
關於GOAP的詳細原理和F.E.A.R.的實現(兩個底層狀態 + Planner搜索),已在《FSM篇》和《行爲樹篇》中詳細講過,此處不再展開。
GOAP vs Utility AI:
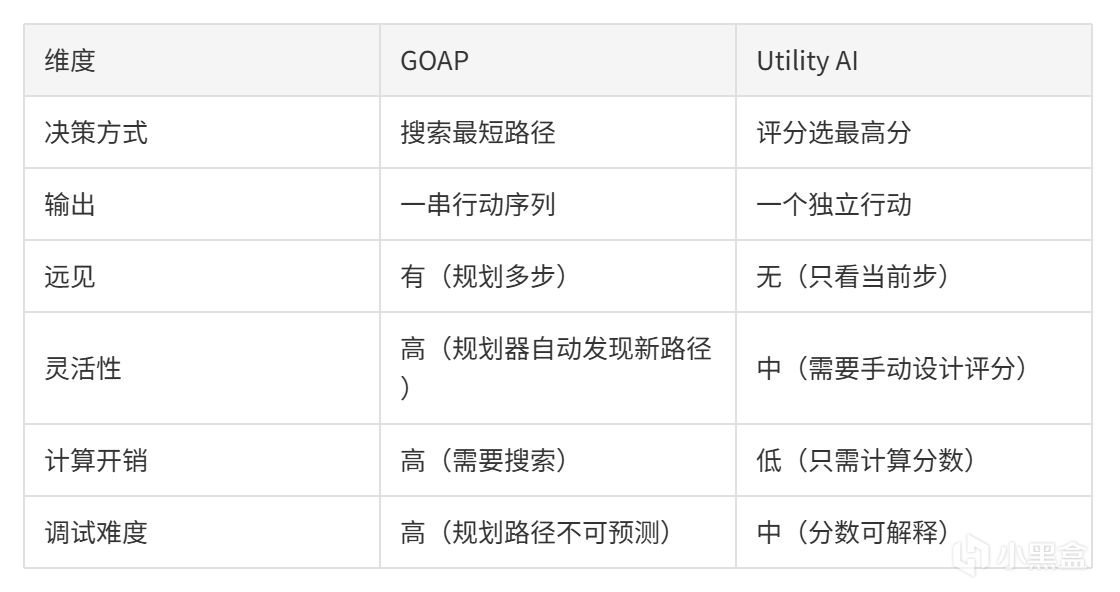
有人說GOAP是"規劃+評分"的混合——Planner用評分來決定搜索方向,但最終輸出的是規劃而不是單次選擇。這個觀點在第7章我們會再討論。
言而總之,Utility AI是選擇題,只需做出選擇即可。GOAP是簡答題,你既要選答案還要寫出解題步驟。
"打分容易調參難。下一章我們來看看這些參數是怎麼讓人頭疼的。"
第三章:Utility AI的三大坑
你以爲評分就是給選項打分就行了?
評分系統上線了,每道菜都有評分,一切看起來很完美。直到遇到三個棘手問題。
3.1 坑1:評分通脹
評分函數設好後,一個詭異的現象出現了:所有任務的得分都在0.9-1.0之間。
冰箱空了 -> 0.95 水槽有碗 -> 0.93 有人在敲門 -> 0.91 窗外有鳥 -> 0.89
評分系統陷入了僵局,生死不明,那就是死了。
所有餐廳都打了5分,那這評分還有什麼意義?點開App時每家都是"優秀",反而不知道該去哪家了。 評分通脹讓評分系統崩潰了。
這就是 "評分通脹"(Utility Inflation)。 當你的評分函數設計不合理時,所有行動都會被壓縮在分數空間的頂部,導致"最高分勝出"機制失效。
爲什麼會出現評分通脹?
大多數評分函數使用"乘法組合":
最終分 = 考量A × 考量B × 考量C
如果每個考量都在0.8-1.0之間,三個一乘,所有分都"擠在"0.5-1.0的區間。這就等於沒區分度。
在兩家評分都接近滿分的餐廳之間反覆橫跳,最後餓死了。分都差不多,就等於沒分。 你以爲你有的選嗎?

當我面對選擇困難時belike
怎麼治?
Dave Mark 在《Behavioral Mathematics for Game AI》裏推薦了一個方法:用"響應曲線"(Response Curves)替代線性評分。
線性:分差均勻,容易通脹
S形曲線:低端和高端被壓縮,中間放大區分度(推薦用於解決通脹)
指數型:拉大高分和低分的差距
還有一個技巧:用減法替代乘法。
最終分 = 距離分 × 血量分 × 彈藥分
最終分 = (距離分 + 血量分 + 彈藥分) - (1 - 距離分) × (1 - 血量分) × (1 - 彈藥分)
減法的好處是:每個低分考量都會在最終分上留下一個"缺口",分數天然不會擠在頂部。
3.2 坑2:改一個崩一片
評分系統跑了幾天,開始出問題了。
問題1:冰箱空了 -> 買菜得分 0.95 -> 系統天天去買菜 -> 家裏菜堆成山了
調參數:把"冰箱空"的權重從0.8降到0.5。
然後災難來了。
問題2:因爲調了買菜權重,所有和"食物"相關的決策都變了。洗碗的分也變了(喫飯產生碗筷),出門的分也變了(買菜順便散步),甚至看電視的分都變了(喫飯的時候看電視)。
一個參數改下去,十個系統跟着變。
這種情況被開發者稱爲"參數地獄"。
參數A -> 影響評分B -> 影響決策C -> 影響系統D -> 影響...
到底哪裏出了問題??
爲什麼會有參數地獄?
因爲Utility AI的評分函數本質是高維參數空間。 修改了"飢餓權重"後,其影響的不只是喫飯決策。它會通過"需求滿足度"連鎖影響社交意願、探索意願、工作效率。
做飯時改了一道菜的鹽量,整桌菜的味道都可能受影響。 客人喫了鹹的菜再喝湯,會覺得湯有點淡。後廚的調料比例是一個相互依賴的系統,牽一髮而動全身。
雖然客人不一定會先喫菜再喝湯就是了。
實際上,參數地獄在遊戲開發界是個衆所周知的噩夢。
有團隊爲調一個Utility AI的評分系數投入過數週時間。當你看到遊戲裏的AI偶爾犯傻,那多半是參數沒調好。
BioWare在《龍騰世紀:審判》中怎麼解決的?
根據Hanlon & Watts在《Game AI Pro 3》第31章中的詳細描述,BioWare採用了多層策略:
差異化評分曲線:每個考量有自己的獨立響應曲線。"飢餓"用指數曲線,"疲勞"用S形曲線,"社交"用對數曲線。不共用參數模板。
參數分組隔離:通過"behavior snippet"數據結構封裝評分和執行邏輯,戰鬥參數、社交參數、環境參數分屬不同組。改戰鬥參數不會影響社交評分。
視覺化調試工具:實時顯示每個行動的評分分解(《Game AI Pro 3》第31章中描述的debug-viewable scoring breakdown table):"爲什麼攻擊得分是0.85?因爲距離分0.90 × 血量分0.95 = 0.855"。
迭代測試流程:每次參數修改後,通過調試表比對行爲變化是否符合預期(此外,Sebastian Hanlon在GDC 2016上做了"Getting Inquisitive About the AI of Dragon Age Inquisition"演講,展示了更多調試工具鏈細節)。
核心思路就是分開管理、可視化、自動化測試。每個工具幹自己的活,別攪在一起。
3.3 坑3:最優決策不等於有趣決策
這是Utility AI最大的困境。
假設你有一個Boss AI,它的決策邏輯是:
攻擊玩家(如果玩家在射程內 + 自己有血量 > 50%)-> 得分0.90
召喚小兵(如果小兵數量 < 3)-> 得分0.85
釋放大招(如果冷卻已好 + 玩家血量 < 30%)-> 得分0.70
Boss每次都會選擇"攻擊玩家",因爲得分最高。
但如果Boss每次都只攻擊,玩家的體驗就會很無聊。 一隻只會平A、既不召喚小兵也不放大招的Boss毫無驚喜可言。
最優決策往往是最無聊的決策。

火車難題最優結局
這就成了一個矛盾:"AI太聰明反而不聰明"。有時去追求最大化Utility,結果卻最小化了樂趣。
怎麼平衡?
幾個常見策略:
添加隨機噪聲(XCOM的做法):在最終分上加10-20%的隨機偏移,讓次優解偶爾勝出
冷卻器機制(Cooldown):當一個行動連續勝出N次後,降低它的分數(逼AI"休息")
多樣性獎勵:如果一個行動長時間沒被選中,給它加分(鼓勵AI展示更多行爲)
Exhaustion機制:一個行動被執行後,短時間內評分歸零("剛喊過救命,現在不用再喊了")
主包很喜歡喫食堂的麻辣燙,儘管知道麻辣燙最好喫(最優解),但總不能一年喫365天麻辣燙吧?偶爾也要整點小漢堡換換口味。這就是"多樣性獎勵"。
3.4 全新案例:TLoU2的"情感系統"如何幫AI避免最優≠有趣
Naughty Dog在《The Last of Us Part II》中做了一個很有意思的設計:給AI加情感維度。
詳見GDC演講"Melee AI in The Last of Us Part II"及"Emotional Systemic Facial of Last of Us Part II"
每一個人類敵人都有情感狀態:恐懼、憤怒、悲傷。這些情感不是裝飾,它們作爲額外考量因素直接影響Utility評分。
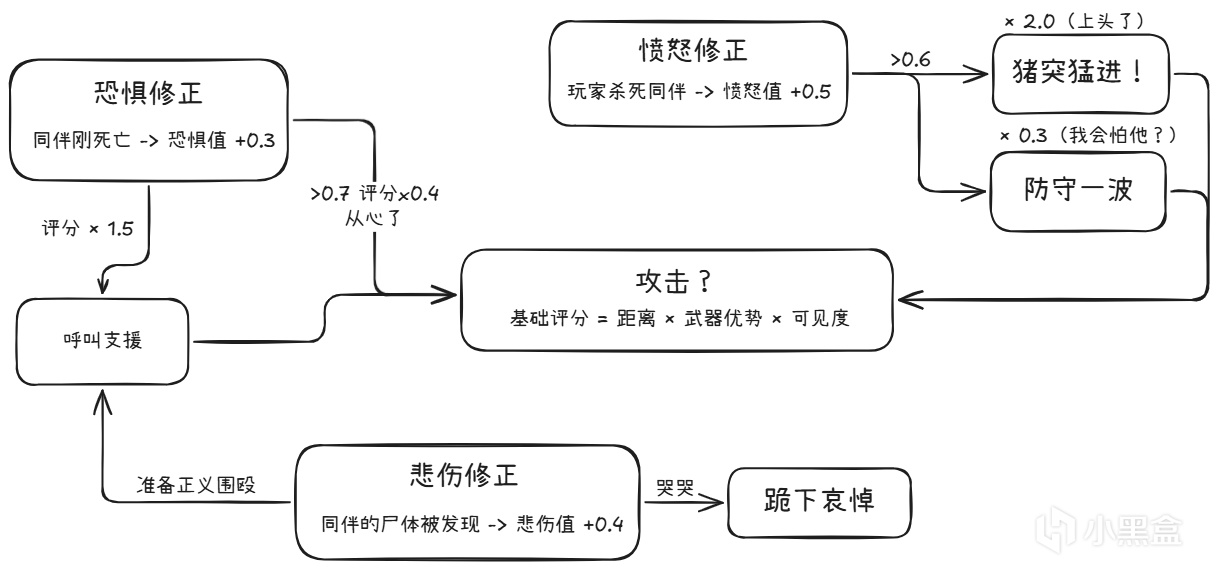
TLoU2還做了一個有意思的設計:敵人會喊出同伴的名字。當你殺了"Elena"之後,另一個敵人會在搜索時說"Elena? Elena, where are you?"
這個功能不是預先錄好的,它通過程序化對話系統實時生成。
技術實現路徑大致是:
每個敵人有一個"關係網絡"(知道哪些人是同伴)
同伴死亡事件觸發 -> 情感系統更新恐懼/憤怒值
根據情感值決定對話內容 -> "憤怒 -> 復仇宣言"、"恐懼 -> 呼喊確認生死"
對話內容覆蓋基礎Utility評分(喊話期間AI的"搜索"評分高於"攻擊"評分)
情感維度讓AI不再只做數學優化,行爲變得不可預測。當一個敵人因爲憤怒而魯莽衝鋒時,它做出了一個"非最優"但"有故事感"的決策。玩家會覺得:這個AI在爲同伴報仇。

擺手不是拒絕,而是無需多言
即使是個理性的人,當看到朋友被人欺負時,儘管知道打架不好,腎上腺素也會讓其上頭。 情緒來了的時候,人顧不上算最優解。TLoU2的AI就是這種人。
3.5 調試工具鏈:爲什麼Utility AI需要可視化
Utility AI的評分不只是"幾個數字算來算去"。真正去調的時候就會發現,沒有可視化調試器,調參就是盲猜。
可視化調試器的重要性
你在開發一個遊戲,敵人AI突然抽風了——明明沒有敵人它卻在"警惕"狀態。 你打開代碼,翻到評分函數,對着十幾個參數發呆。
到底是"距離分"算錯了,還是"威脅評估"權重太高,還是"隨機噪聲"這次運氣不好?三個答案都可能是對的,但你沒有數據,你只能靠猜。 改一個參數,重新編譯,跑一遍,看效果。循環10次,終於好了。但你可能改錯了參數,只是碰巧效果對了。
這就是沒有調試器的日常。
BioWare的DAI調試工具長什麼樣?
根據Hanlon的分享,BioWare爲《龍騰世紀:審判》的Utility AI構建了一個完整的可視化調試面板。
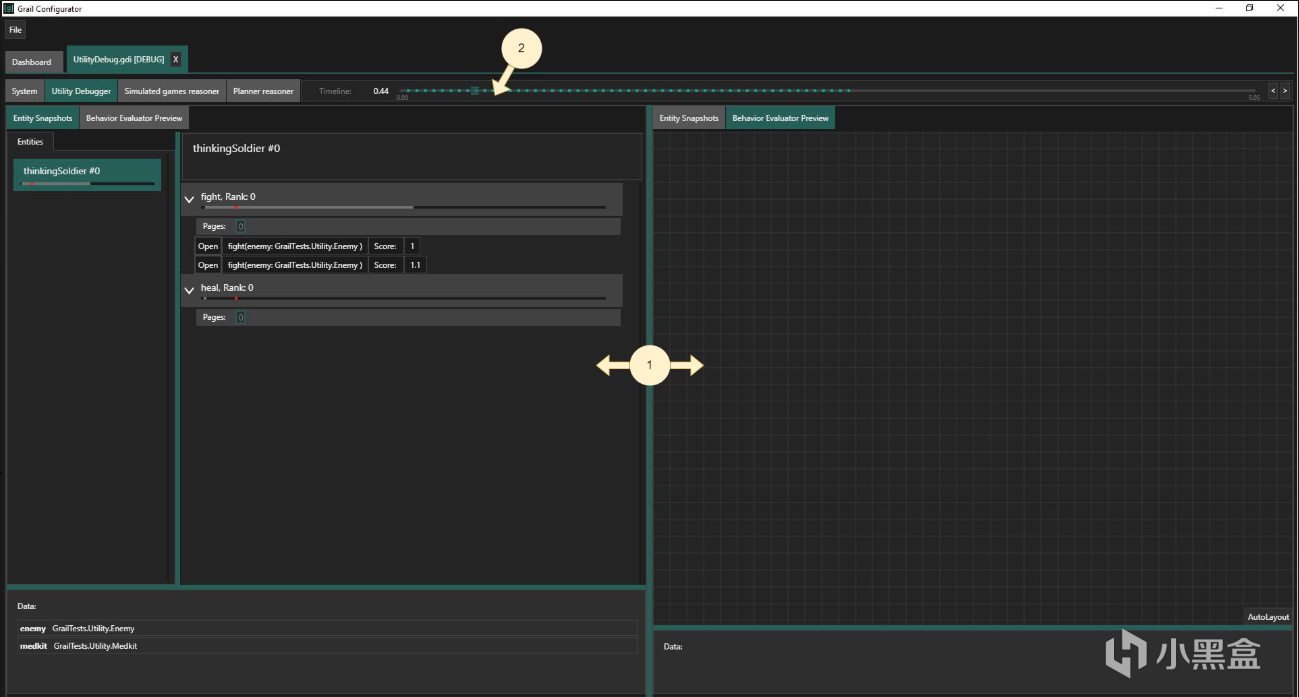
這個面板讓設計師能實時看到每個決策的"數學解剖"。
如果AI總是選擇不合理的行動 -> 直接看每個考量的分數分解
如果某個考量始終貢獻很低 -> 可能權重太小或者曲線設計不合理
如果隨機噪聲主導了決策 -> 噪聲幅度太大了
開發Utility AI的第一條規則:沒有可視化調試器,就不要做Utility AI。
第四章:Left 4 Dead 的 Utility DDA
如果你只玩過一個有DDA(動態難度調整)的遊戲,那大概率是《Left 4 Dead》(求生之路)。 Valve的這款2008年殭屍射擊遊戲,至今仍是DDA領域被頻繁引用的案例。
L4D的DDA系統:Director(導演)是一個Utility AI和心流理論的結合。
它的出發點是一個問題:"你覺得玩傢什麼時候玩得最開心?"
大部分AI設計者在想"怎麼讓AI做更好的決策",但L4D的設計師更關心"玩傢什麼時候最開心"。
這就是Director的出發點。
4.1 心流理論:DDA的心理學基礎
在講L4D之前,必須先說一個人:Mihaly Csikszentmihalyi(米哈里·契克森米哈賴)。
1990年,他提出了心流理論(Flow Theory):
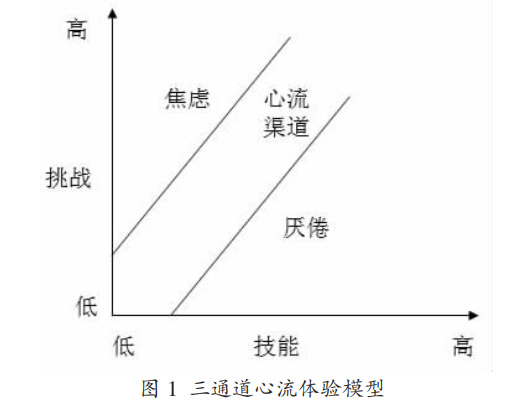
如果挑戰太高、能力太低 -> 玩家焦慮(想摔手柄)
如果挑戰太低、能力太高 -> 玩家無聊(想換遊戲)
心流通道:挑戰和能力匹配 -> 玩家沉浸,忘記時間
L4D的Director首次將心流理論系統化地整合進DDA架構。更早的遊戲如1990年代的賽車遊戲已有基於玩家表現的動態難度實踐,但L4D首次將其提升到了系統化、可解釋的架構層面。
4.2 L4D Director 四大系統
Mike Booth在2009年的AIIDE(人工智能與交互數字娛樂國際會議)上做了《The AI Systems of Left 4 Dead》的演講(同年在GDC 2009上還做了《From Counter-Strike to Left 4 Dead: Creating Replayable Cooperative Experiences》分享)。Director由四個核心系統組成:
4.2.1 Flow Distance(流程距離)
Director用"流程距離"來衡量玩家在關卡中的進度。 根據Mike Booth的GDC演講描述,Flow Distance更準確地說是玩家到關底的最短路徑上的關鍵事件序列,是一個空間加事件的複合度量。
具體來說:
起點:距離0,新手村,Director派最弱的殭屍
中途:距離50%,Director開始熱身
終點前:距離90%,Director準備上上強度
具體的事件序列大致如下:
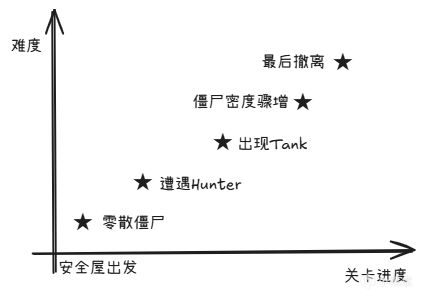
本質上就是"溫水煮青蛙"。你不會一下子覺得難,但回頭看時已經超過了退款時間。
4.2.2 Active Area Set(活動區域集)
Director把關卡分成一個個"活動區域"(AAS)。它知道玩家在哪個區域裏,知道附近有哪些刷怪點、哪些掩體、哪些高地。
就如電影導演知道舞臺上有哪些道具:"現在演員站在舞臺左邊,我就從右邊放煙幕彈。"
AAS的具體工作方式:
關卡設計時預標註:每個區域的刷怪點、安全點、補給點
運行時追蹤:玩家當前在哪個AAS中
動態選擇:只在玩家附近的AAS中生成事件(避免"在玩家背後刷怪"的作弊感)
區域切換:玩家從一個AAS進入另一個時,Director重新評估節奏
4.2.3 Survivor Intensity(倖存者緊張度)
這是Director的監測器。它將持續追蹤:
玩家當前血量
最近受傷頻率
倒地次數
被特殊感染者攻擊次數
隊伍整體血量百分比
最近60秒內的"危機事件"數量
緊張度的計算方式(根據GDC演講和社區逆向分析,大致模型如下):

僅作參考,並非精確數值
如果緊張度太高 -> Director降難度(少刷特感、多刷藥包) 如果緊張度太低 -> Director升難度(刷個Tank過來,給玩家提提神)
閾值觸發邏輯(以下爲社區分析推測的近似閾值,非官方確認值):
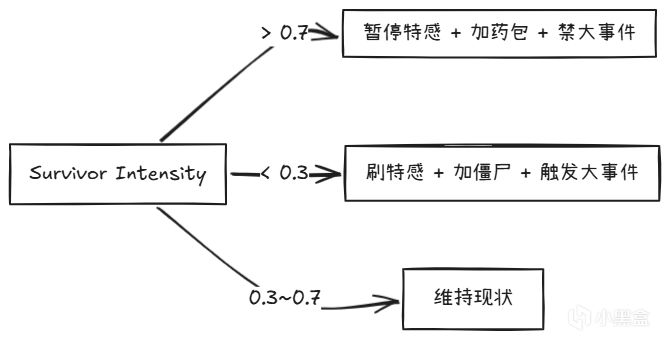
類似於餐廳裏的大堂經理,看客人狼吞虎嚥就放慢上菜節奏(降速),看客人久不落筷就加快上菜節奏(提速)。
4.2.4 Adaptive Dramatic Pacing(自適應戲劇節奏)
這是Director的"敘事感"組件。它不只是調難度,它還在編排:調高潮、低谷、轉折。
Director會給每個"戲劇節拍"打分:
上一次高潮過去多久了?太久 -> 該來一波大的了(得分高)
玩家剛打完Boss,殘血 -> 不讓殭屍出現,給恢復時間(得分低)
玩家剛進一個新區域 -> 刷幾個殭屍"歡迎"(得分中)
Director是一個持續的"戲劇節奏評分器",不是if-else的狀態機。這是Utility AI在DDA中的典型應用。
Director是餐廳的大堂經理。他不會在客人剛坐下喫開胃菜時就上主菜,也不會在客人喫飽了才上甜品。 他會觀察每桌的進食節奏,喫得快的催後廚快點上,在聊天的慢慢來。 這位經理會安排整個餐廳的上菜節奏。
4.3 Boss Card Shuffle:L4D的卡牌洗牌機制
L4D的Boss生成機制用了卡牌洗牌的邏輯。
Director手裏有一副"Boss卡牌"(以下概率分佈基於玩家社區統計和GDC演講中的描述,非精確官方數據):

主包幫你們開了認知濾鏡(╹╹ )
當Director決定要搞一波大的時,它不是隨機選一張卡。
它選擇洗牌。
洗牌邏輯的核心:
如果玩家剛打完Tank -> Tank的牌從牌組中移出(短時間內不會再次出現)
如果Hunter連續出現兩次 -> Hunter的優先級下降("多樣性獎勵"的典型)
如果玩家對Witch反應特別慢(被秒了)-> Witch概率下降
這是一個離散型的Utility系統:每個Boss類型根據歷史數據實時調整"被選中概率"。
這個系統太成功了,後來被不少遊戲借鑑,包括《戰爭機器》的Horde Mode、《Back 4 Blood》、甚至《Helldivers 2》的Patrol系統。
4.4 物品動態轉換:給玩家送溫暖
L4D還有一個低調但極其聰明的DDA設計:物品動態轉換。
Director持續追蹤玩家隊伍的"貧窮度":
彈盡糧絕?下一個房間刷彈藥
全員殘血?轉角處必有藥包
有人倒地?附近補血點
Director做得很隱蔽,不會在玩家殘血時突然在天上掉藥包。它會在前面的房間裏"恰好"放一個藥包,看起來像是"本來就有的"。
這樣玩家就會覺得"是我自己找到了資源",而不是"系統可憐我纔給我"。
一名服務員看到客人被辣到,她不會直接說"您不能喫辣吧"。 她會"恰好"端來一杯檸檬水,輕輕放在客人手邊。(這邊更推薦牛奶或豆乳哦)
4.5 番外篇:Chet Faliszek談Valve爲什麼沒公開Director
Valve藏了一個驚天祕密,他們做了DDA,但最初沒告訴任何人。
2023年,在L4D發售15週年之際,編劇兼製作人Chet Faliszek接受Game Developer專訪時聊到了一個有趣的往事:
L4D最初發布時,Valve完全沒公開DDA系統的存在。Director的一切都在幕後運行,玩家根本不知道有這個東西。
但在遊戲發售後,玩家在論壇上瘋狂討論:
"你有沒有發現,後面刷出來的殭屍好像跟你的表現有關?"
"我覺得有隱藏系統在控制難度——太神奇了"
"我殘血的時候總能在角落裏找到藥包,這不是巧合!"
社區自發地開始"挖掘"Director的祕密,形成了大量討論帖、攻略視頻、數據分析。
Chet在訪談中笑着說:"看到玩家自己發現Director的運作方式,這是最有意思的部分。" 雖然訪談中沒有明確說Valve"刻意隱瞞",但社區確實是在遊戲發售後通過逆向工程和實踐逐步摸清了Director的工作原理。
這段故事告訴我們:有時候最好的設計,是玩家都還沒意識到自己在被設計。
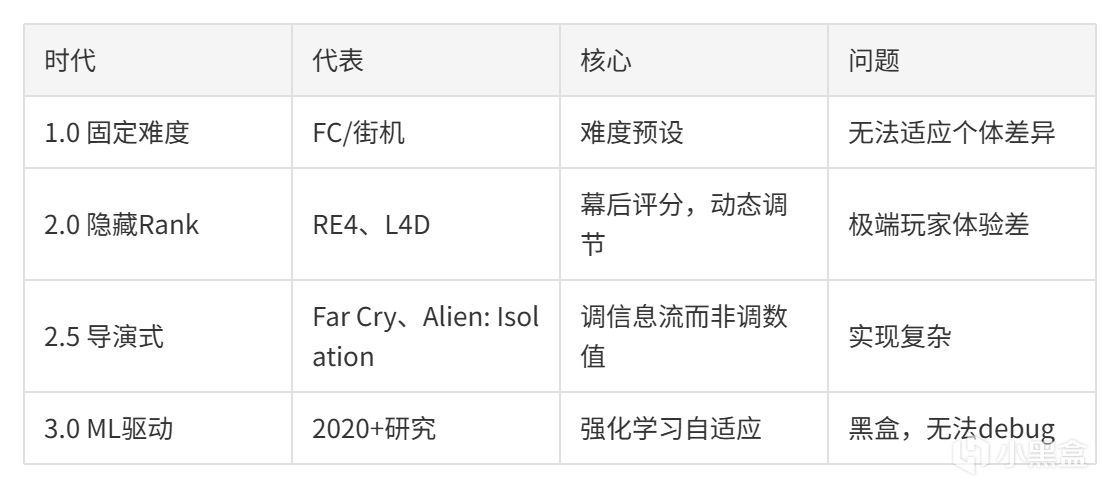
第五章:DDA的多樣面孔——從隱藏Rank到信息流操控
L4D的Director至少Valve後來承認了它的存在。有些遊戲從不承認——它們做了DDA,但永遠不告訴你。直到十年後,數據挖掘者才翻出來。
這一章看DDA的三種面孔: 懲罰性DDA(你強我就更難)、導演式DDA(我幫你安排節奏)和解耦式DDA(我不直接調難度,我調信息流)。
5.1 隱藏Rank流派:你強我更難
生化危機4(2005)+ God Hand(2006):三上真司的DDA雙響炮
三上真司的《生化危機4》是遊戲史上最被低估的DDA案例之一。
這個系統完全隱藏,遊戲手冊裏沒有,開發者訪談裏沒有,玩家論壇上爭論了十年。直到數據挖掘者在2020年拆包才確認。
RE4隱藏Rank怎麼工作的?
每個玩家有一個看不見的 Rank 值(社區分析認爲系統通過Action Points動態調整,數值範圍因數據挖掘版本而異),全程實時變化(以下數值基於社區數據挖掘分析,不同資料來源可能存在差異):
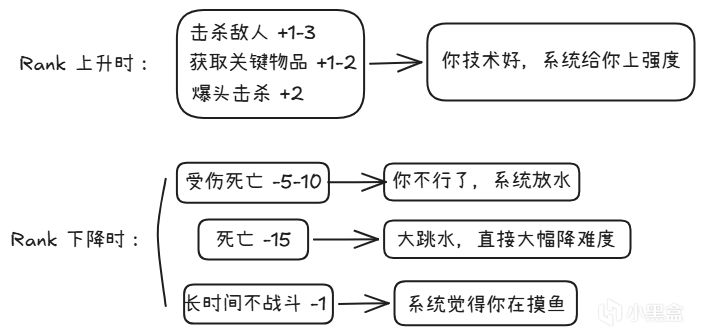
Rank影響什麼?
敵人攻擊性:Rank高 -> 敵人更主動、更激進;Rank低 -> 敵人更"遲鈍"
敵人血量:Rank高 -> 村民能喫更多槍;Rank低 -> 兩槍就倒
反應時間:Rank高 -> 敵人閃避更快;Rank低 -> 敵人站樁捱打
彈藥掉落率:Rank高 -> 彈藥掉落少(你技術好,不需要太多子彈);Rank低 -> 彈藥掉落多(給你補個彈)
如果你是個高手,系統會"獎勵"你更難的遊戲——敵人更硬、更快。
如果你是個菜鳥,系統會"保護"你——敵人變軟、彈藥變多。
但問題在於,高手的Rank越高,遊戲越難;菜鳥的Rank越低,遊戲越簡單。這並不算平衡難度,而是在拉大貧富差距。
考試的時候,學霸越學越覺得題簡單,學渣越學越覺得題難。然後系統給學霸加附加題,給學渣減題目。差距只會越來越大。
"原來我玩遊戲覺得越來越難,不是因爲遊戲真的難,而是遊戲覺得我太強了。 "RE4度量的是你的技術,所以它給你的回報是更強的敵人。但這是玩家想要的回報嗎?
而三上真司的另一款神作《God Hand》(2006)走了另一個極端。它的隱藏DDA系統叫 "難度等級"(Difficulty Level, DL):
DL 1(最簡單):敵人站着不動讓你打
DL 2(中等):正常的攻防節奏 DL 3(較難):敵人進攻積極
DL Die(最難):敵人瘋狂進攻,幾乎不給喘息時間
每次攻擊命中敵人 -> DL +1 每次被敵人命中 -> DL -1 使用特定招式 -> DL 大幅上升
你打得越好,系統越不讓你好過。
這被稱爲"懲罰性DDA":系統不是幫助你,而是挑戰你。 你表現出色,系統提高難度,看看你到底能走多遠。
面對拳擊教練時,你打中他一拳,他不會說"好棒哦,給你一朵小紅花"。 他會更狠地還手,因爲你在變強。
RE4 Remake(2023):保留了一部分自適應的味道
2023年的《生化危機4 重製版》保留了隱藏Rank系統,但做了一些調整(據Mod社區的逆向分析及玩家反饋):
Rank調整幅度更溫和(不會讓玩家明顯感覺到難度波動)
加入了"安全網":如果玩家連續多次死亡,Rank會有一個"保底下限"
彈藥掉落還是自適應,但極端情況被鎖死
Capcom的設計師顯然意識到了原版的"貧富差距"問題,但他們不想完全拋棄這個系統。因爲它確實讓更多人能通關。這是一個"讓所有人都能玩完故事"的設計思想。
是故意的(驕傲)
Robin Hunicke的HAMLET(2004)
2004年,Robin Hunicke(後來成爲《Journey》的製作人)在AAAI上發表了關於DDA的經典論文,提出了兩個關鍵概念:
Proactive DDA(主動式DDA)
系統在玩家還沒意識到自己需要幫助之前就調整難度。
玩家血量還有70% -> 系統檢測到玩家最近的命中率下降 -> 提前降低敵人生成速度
玩家還沒死亡 -> 系統"未雨綢繆"地給裝備調整
優點:無縫銜接,玩家完全感覺不到 缺點:誤判率高(玩家只是在喝水,系統就以爲他不行了)
Reactive DDA(反應式DDA)
系統在玩家遇到困難後才調整難度。
玩家連續死亡3次 -> 降低敵人血量
玩家卡關30分鐘 -> 刷出更多彈藥
優點:準(數據充足,不會誤判) 缺點:慢(玩家已經被虐了纔來幫忙)
HAMLET認爲:最好的DDA是"主動+反應"的混合。用主動式維持心流,用反應式兜底防死局。
新拿了駕照的朋友開車帶你去旅遊,主動式是他看到前面有坑就提前減速;反應式是你喊"慢點慢點"了他才剎車。
5.2 Alien: Isolation雙層AI:信息流操控
Creative Director Alistair Hope在GDC 2015上做了"Building Fear in Alien: Isolation"的演講,Lead Designer Gary Napper也在多個採訪中詳細解釋了AI架構。其中描述的AI架構至今仍是遊戲AI課程中的經典案例。
雙層解耦架構
《異形:隔離》的AI由兩個獨立的系統組成
它們解耦(decoupled)運行:
第一層:Director AI(導演AI)
知道玩家的精確位置
負責監控整體局勢
它的職責是不是直接操控異形,而是給異形提供"線索"
第二層:Alien AI(異形AI)
不知道玩家的精確位置
只能通過遊戲世界中的線索來推斷玩家位置
移動邏輯:搜索 -> 聽到聲音 -> 靠近 -> 搜索 -> 循環
爲什麼解耦是核心創新?
如果異形直接知道你的位置,遊戲就變成了"異形永遠跟着你跑"。
玩家沒有喘息空間,遊戲體驗就是持續的壓迫感,沒有節奏變化。
如果異形完全不知道你的位置,遊戲就變成了"異形在瞎逛"。
沒有緊張感,玩家會覺得AI傻。
解耦的解決方案:異形不知道你的位置,但導演AI知道。導演AI不是直接告訴異形"你在櫃子裏",而是在你的位置附近"放置"線索。
比如在附近的通風口放出聲音、在你的路徑上留下痕跡。
這樣一來,異形的行爲看起來是自然的搜索行爲,而不是"作弊式追蹤"。
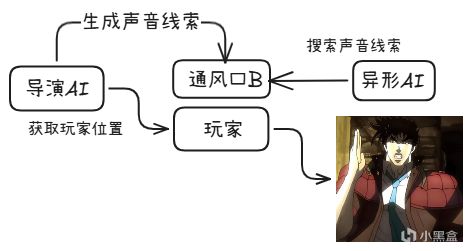
最好的DDA不是調數值,是調信息流。
《異形:隔離》的DDA和RE4、God Hand完全不同。
RE4調的是敵人的血量、攻擊性等數值參數。 L4D Director調的是殭屍的生成頻率、資源投放等遊戲參數。
但Alien: Isolation調的是信息流。
也就是"異形知道多少關於玩家位置的信息"。
當玩家太安逸(躲在一個櫃子裏太久)-> 導演AI給異形更多線索,縮小搜索區域
當玩家太緊張(剛被異形追過)-> 導演AI暫時不給異形線索,讓異形"迷路"
當遊戲節奏太慢 -> 導演AI讓異形巡邏得更積極
當遊戲節奏太快 -> 導演AI讓異形"分心"去看別的地方
它調整的不是"誰更強",是"誰知道什麼"。
這比調數值更隱蔽,也更難被玩家察覺。玩家會覺得"異形是靠自己的搜索能力找到我的"。
RE4像是給你的考試加分減分,L4D像是調整試卷難度,Alien: Isolation像是老師在你旁邊路過,看了一眼你的試卷,然後你慌了。老師什麼都沒做,只是調整了信息的流動。
最高明的DDA,不是改變世界,而是改變世界被感知的方式。它調整信息如何流動,讓參與者"恰好"知道什麼時候該做什麼。
5.3 Helldivers 2 Patrol System:當你清完所有哨站……
Arrowhead Game Studios在2024年的爆款《Helldivers 2》中展示了一個反直覺的DDA設計。
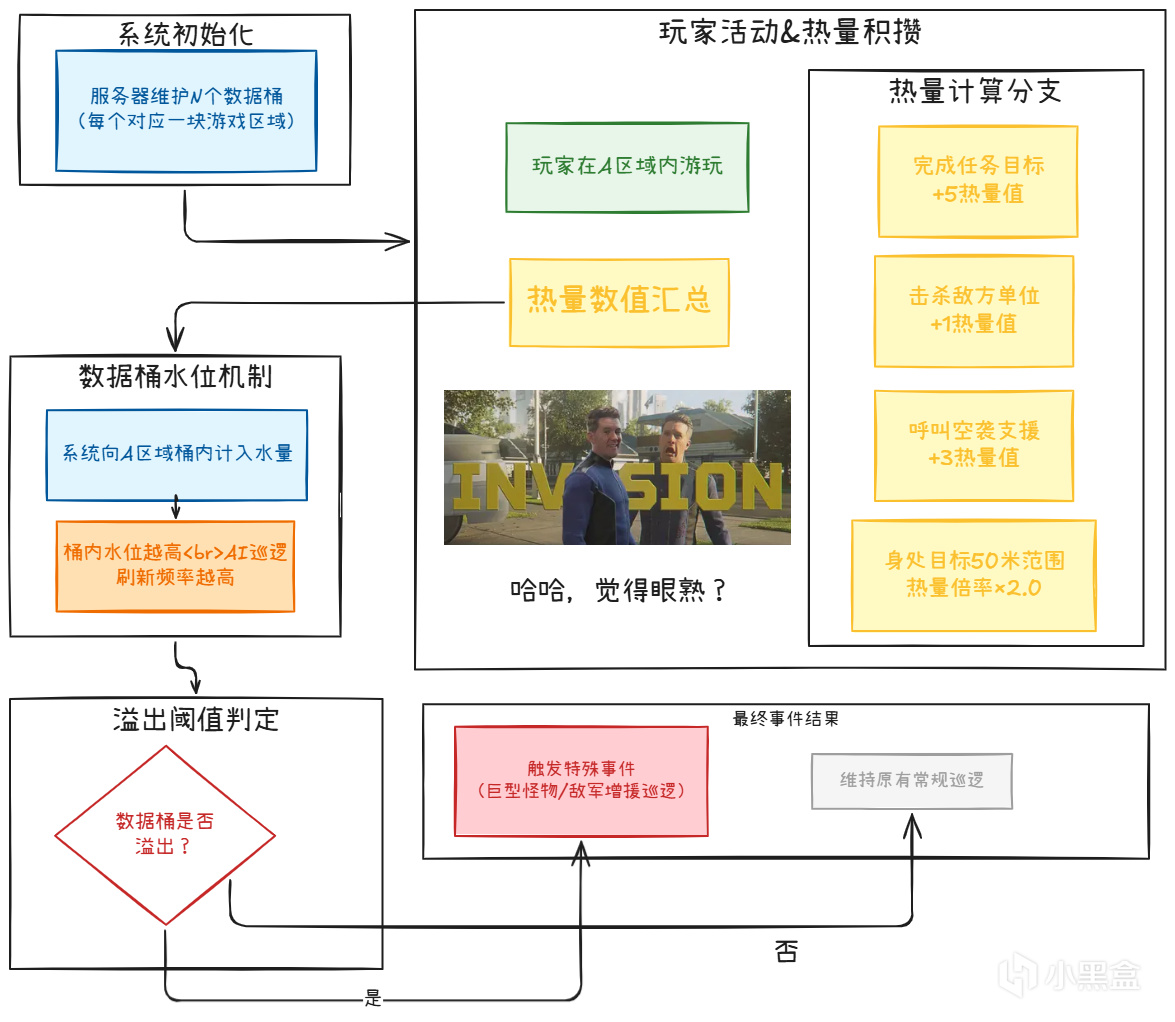
Bucket System(水桶系統)
Helldivers 2的刷怪系統不是簡單的"附近有玩家就刷怪"。它使用了一個被稱爲"Bucket"的系統:
加入絕地潛兵!
Heat Generation(熱量生成)
這是Helldivers 2反直覺設計的核心。
任務目標50米內熱量最高:你沒看錯,越靠近任務目標,刷怪越猛。這意味着你不可能"偷偷摸摸做完任務然後溜走"。遊戲逼着你硬剛。
哨站清除與刷怪率的關係(基於社區數據分析,不同補丁版本可能存在差異):
清除0%哨站:基準線(刷怪速度 100%)
清除部分哨站:刷怪速度小幅累進上升
清除所有哨站:刷怪速度約提升 17.5%(最終刷怪率約 117.5%)
反直覺的設計:清完所有哨站後,刷怪速度反而加快17.5%(相較於基準線)。
爲什麼這麼設計?因爲:
清完所有哨站意味着玩家已經展示了"征服力" -> 系統提高挑戰
清完哨站後玩家的主要目標是撤離 -> 系統刷怪阻止撤離(製造最終高潮)
清完哨站後玩家通常會鬆懈 -> 系統趁你鬆懈給你驚喜
"評分、評分、評分。打分的世界裏,還有沒有比分數更重要的東西?"
第六章:超越評分:Utility遇見系統設計
到目前爲止,我們都是將Utility AI作爲決策引擎來講:給行動打分,選最高分。它還可以做更大的事——當整個系統的基礎。
這一章看三個案例。
6.1 Nemesis System(宿敵系統):Utility AI下的社會模擬
Monolith Productions的《中土世界:暗影魔多》(2014)的Nemesis System在設計上做得比較徹底。
Chris Hoge在GDC 2018上做了"Helping Players Hate (or Love) Their Nemesis"的演講,解析了Player Interaction Score(PIS)等核心機制。
表面:程序化層級關係
Nemesis System最廣爲人知的是:獸人軍團有自己的一套社會結構。

原諒我,這真的不好畫
當你殺死一個副官時,它的保鏢可能會晉升爲新的副官,或者另一個副官趁機吞併它的地盤。這個層級會持續變化,是一套動態的社會模擬。
支撐這些行爲的,是Utility評分。
每個獸人角色有多個評分維度:
攻擊力評分 = 武器熟練度 × 等級乘子 + 性格偏移
防禦力評分 = 護甲質量 × 等級乘子 + 性格偏移
忠誠度評分 = 對上級的服從度 × 性格特質
野心評分 = 求晉升的慾望 × 當前地位 + 性格偏移
威脅評分 = 對玩家的威脅程度(距離 × 等級 × 裝備)
注:這裏的"性格偏移"是基於角色種子生成的固定值,不是每幀變化的真隨機,避免行爲抖動。
這些評分驅動了獸人社會的所有決策:
角色記憶與動態敘事的自然產生
Nemesis System的另一個核心是角色記憶。每個獸人記住和玩家的交互歷史:
獸人"Goroth the Stabber"的記憶:
遭遇玩家3次
第1次:被玩家砍掉左臂(但沒死)
第2次:被玩家用火燒(但逃跑了)
第3次:成功偷襲玩家(讓玩家死了一次)
當前狀態:
對玩家的恐懼評分:0.7(被打怕了)
對玩家的憤怒評分:0.9(但仇恨更深)
每次見到玩家說:特定對話("你還記得我的左臂嗎?")
當這個獸人再次遇到玩家時,它的Utility評分會調用這些記憶維度:
攻擊評分 = 攻擊力 × 對玩家憤怒評分 × (1 - 對玩家恐懼評分)
如果恐懼大於憤怒,它可能會逃跑或求饒。如果憤怒大於恐懼,它會加倍瘋狂地攻擊。

當你砍了Goroth的左臂,三個月後它成了大佬,帶着全身鐵甲回來找你報仇。Nemesis System讓Utility AI從決策引擎擴展到社會模擬。評分負責底層計算,上層跑出角色之間的動態關係。
6.2 TLoU2的狗追蹤與記憶系統:情感能力的再升級
我們在第三章提到了TLoU2的情感系統。但那個系統還有一個更有意思的應用:狗追蹤系統。
狗的追蹤機制
TLoU2中的軍犬(德國牧羊犬)有一個專門的追蹤AI:
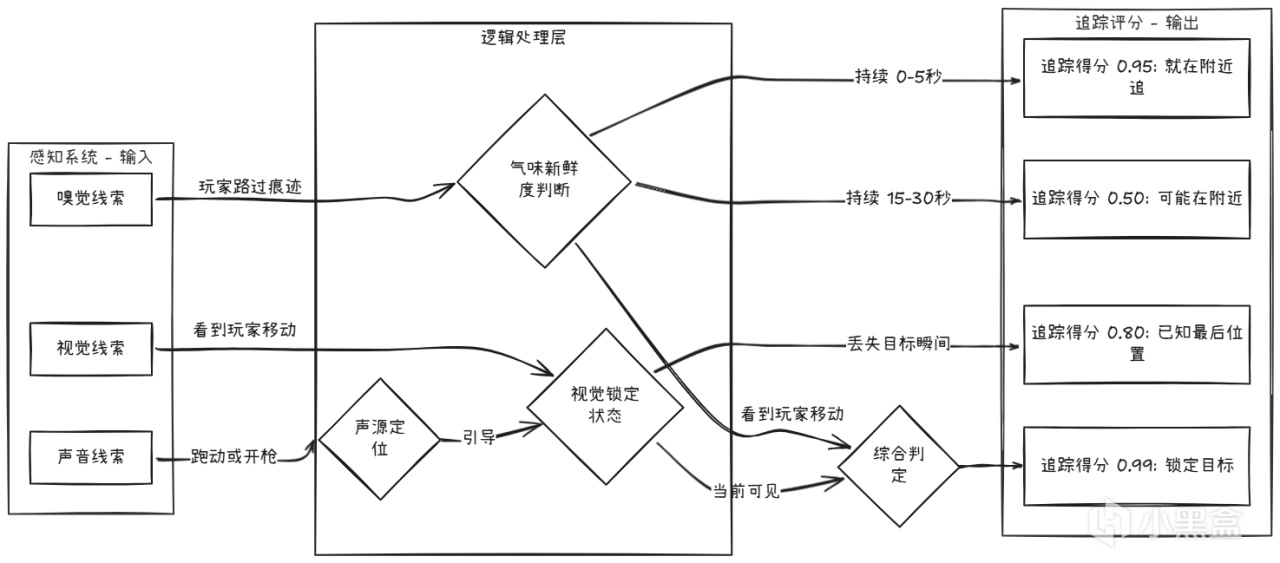
記憶系統:已知最後位置
狗的記憶系統不僅僅用於追蹤,它也用於搜索模式。
當狗失去玩家蹤跡時,它會在最後已知位置做圓周搜索:
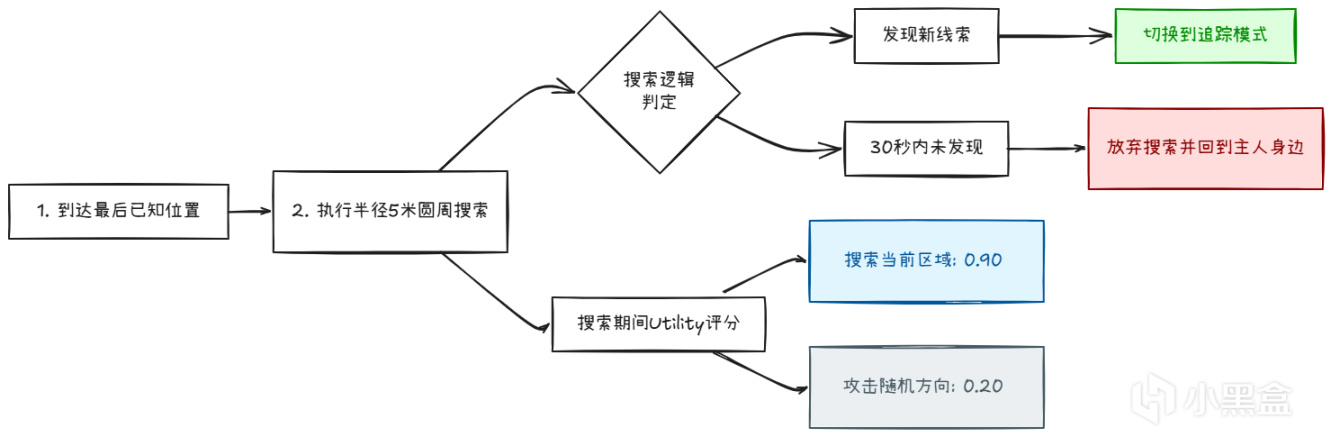
系統疊加:殺了狗,主人會憤怒
這裏有一個更進階的設計:當玩家殺了狗之後,狗的主人(一個人類敵人)會憤怒。
注:以下數值爲示意性,實際參數因具體實現而異。
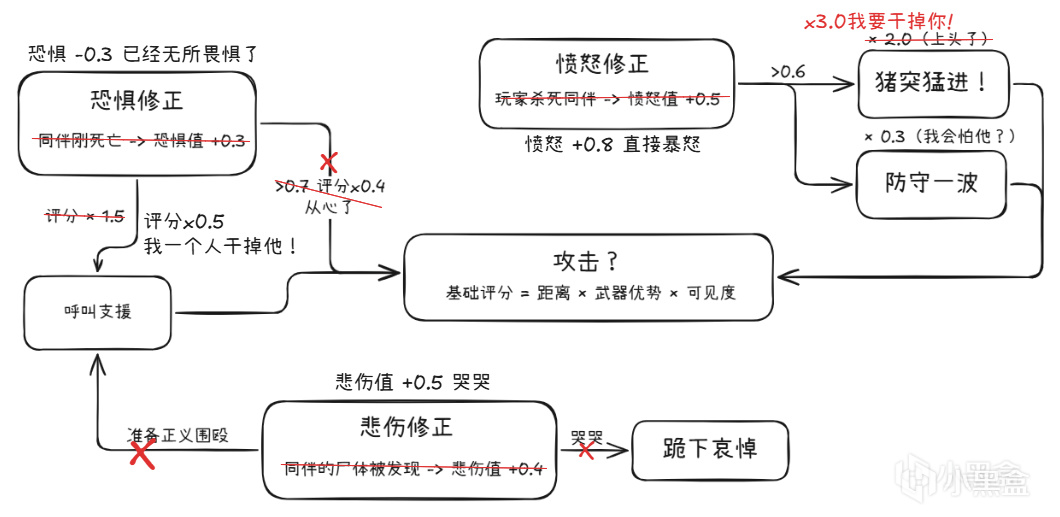
Utility考量因素不限於距離/血量,還有感情和記憶。
當你殺了狗,你在Utility AI的計算中,不再只是一個敵對目標。 你是一個殺了狗的仇人。這個標籤帶來了完全不同的評分矩陣。
TLoU2的狗不只是一個探測器,它和遊戲角色之間有情感連接。你殺了它,它的主人會恨你。這種恨沒法用if-else寫出來,它是評分系統的結果。
6.3 Utility作爲設計方法
回顧這一章的三個案例,可以注意到一點:
Utility AI不僅是一種算法,更是一種設計思路。
這三個案例都關注AI如何回應遊戲裏發生的事,而不是隻決定"下一步做什麼"。
傳統Utility AI:距離 × 血量 × 武器 = 是否攻擊
系統級Utility AI:(距離 × 血量 × 武器) + 情感記憶 × 社會關係 = 是否攻擊 + 怎麼攻擊 + 攻擊後的影響
當Utility AI從決策函數變成系統核心,它的作用就從算法擴展到了設計層面,是一種讓遊戲世界的反應更豐富的方法。
除了評分本身,還要考慮評分是怎麼算出來的。
"不同場景適合不同的做法,關鍵是選對方法。"
第七章:混合架構的時代
前面介紹了的幾種架構,各有各的短板。在實際開發中通常組合使用。
7.1 Utility + BT:最常見的分工
Utility AI決定"做什麼",BT負責"怎麼做"。

7.2 BT + Utility Condition
保留原有BT,把布爾判斷換成Utility評分:
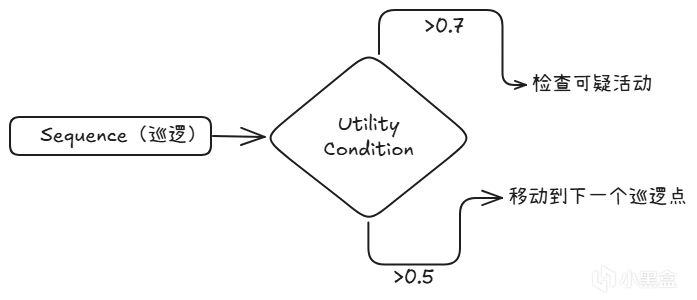
B. Merrill在《Game AI Pro》第10章詳細介紹了這種方法。
7.3 HTN + Utility
HTN生成多個候選行動規劃,Utility評分選出最優方案執行。
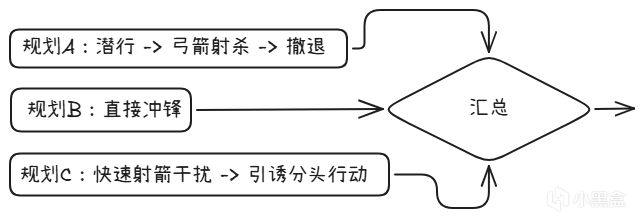
HTN讓AI能規劃多步,Utility讓它能權衡策略。
7.4 GOBT:決策和執行一體化
BT節點的條件由Utility AI實時計算,決策和執行綁在一起。

概念定義見 Hong et al., JMIS 2023。
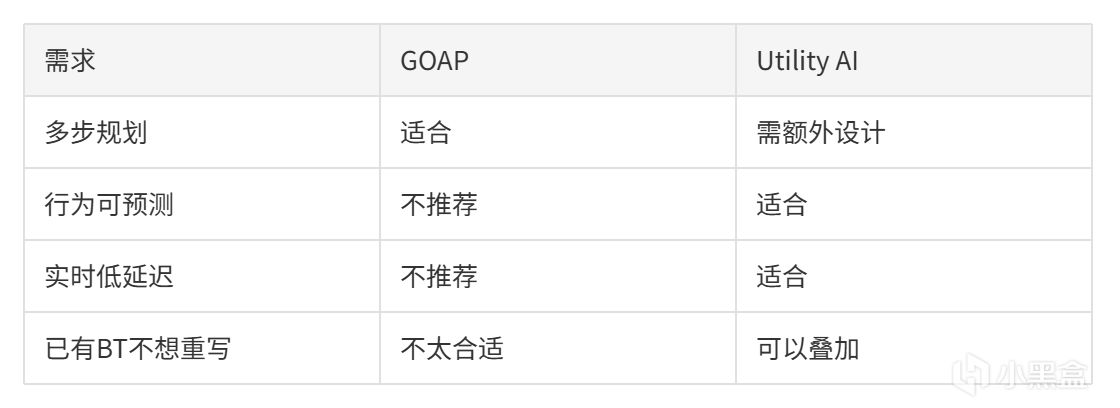
7.5 GOAP:規劃+評分
F.E.A.R.用的GOAP只有兩個狀態:Goto(移動到正確位置)+ Animate(做正確的事)。核心是Planner通過組合動作的precondition和effect自動生成戰術。
Planner不需要開發者寫死"閃光彈+側翼包抄",它通過precondition/effect匹配自己算出來了。
GOAP和Utility的思路相近(多選項權衡),但機制不同:
目標選擇 → Utility的核心
路徑搜索(A*) → 規劃器的核心
第八章:DDA的現在與未來
DDA進化歷程
RL驅動的DDA
傳統DDA的規則是人寫的條件判斷,RL讓AI自己學什麼時候升難度、什麼時候降難度。
狀態空間:命中率、死亡次數、通關時間
動作空間:難度調節量(-5 ~ +5)
獎勵函數:心流狀態+1,連續死亡5次-5,10分鐘無壓力-3
2024年一篇MOBA遊戲的RL-DDA論文顯示玩家留存有所提升。但問題是黑盒:難度在變,但原因不透明。QA發現異常行爲時無法追溯。
未來方向
個性化DDA:根據玩家歷史自動學習"理想挑戰曲線"。愛好《貓版馬里奧》給高挑戰,偏愛休閒遊戲的則放寬限制。
情感感知DDA:通過攝像頭或生物傳感器檢測情緒,不只是看操作數據。檢測到焦慮就降難度,檢測到無聊就升難度。
協同DDA:多人遊戲中在集體和個人體驗間找平衡。PVE按隊伍平均調整,PVP用僞匹配微調參數。使命召喚的SBMM系統曾引發爭議——如果玩家發現被系統暗中調低傷害,信任就崩塌了。
趨勢:從調數值到調信息流
RE4:調數值(敵人血量)
L4D:調參數(刷怪頻率)
Far Cry:調事件(巡邏路線)
Alien: Isolation:調信息流(線索分佈)
HD2:調系統(Bucket水位)
注:HD2的Bucket系統來自社區反向工程,開發商未官方確認。
DDA的發展方向是間接調節,讓玩家察覺不到難度變化。
第九章:技術總結與實用指北
架構對比:從狀態機到Utility AI
整個遊戲AI系列走過了三條路徑
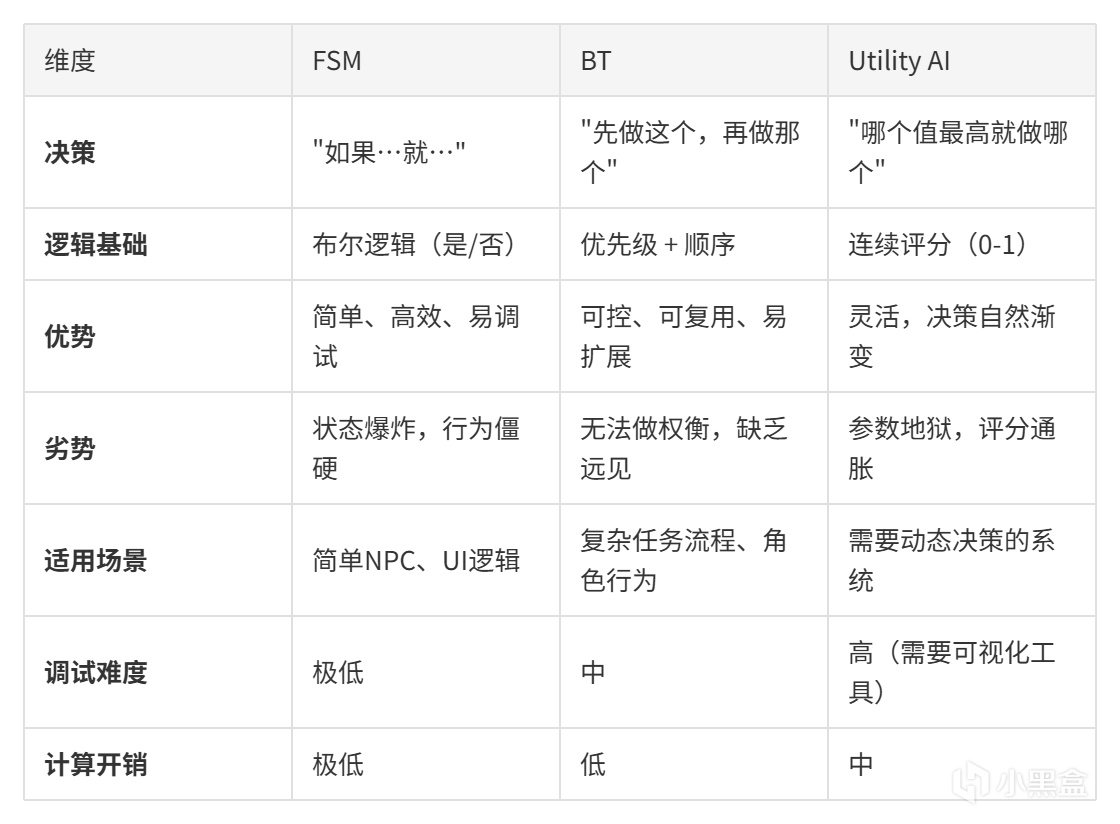
全景對比:六種AI架構一表通
系列中提到的不止三大「主角」,這裏把所有架構放在一起看:
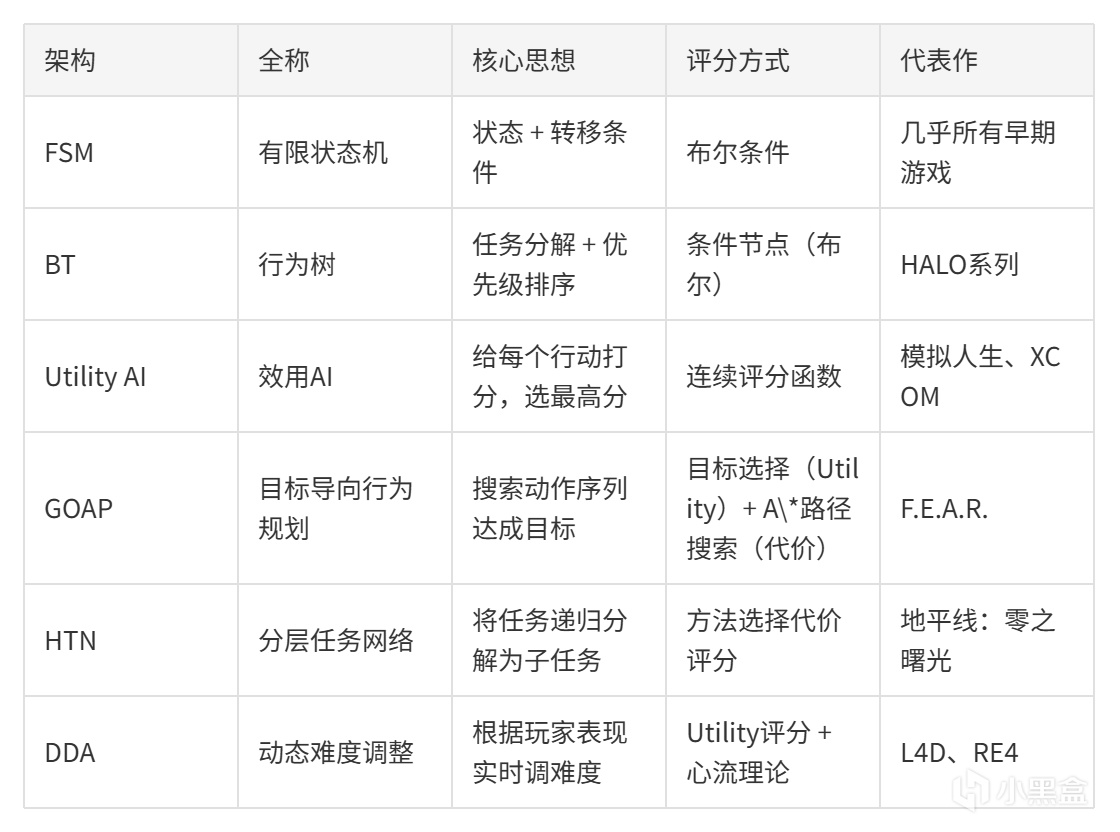
這些架構是互補關係。實際項目中通常混合使用:Utility AI做決策,BT做執行,HTN做規劃。
下一個遊戲該怎麼選
1. 從FSM起步,預留升級接口
小項目(比如一個平臺的敵人AI)用FSM即可。儘量不要開始就上Utility AI,那是不必要的複雜度。設計時把狀態和條件解耦,未來升級到BT時會省很多事。
2. 需要任務流程時用BT
角色要執行一系列有先後順序的動作(巡邏→搜索→攻擊→撤退)時,BT的樹狀結構天然適合「先做這個,再做那個」。 推薦疊加Utility Condition(見第七章),讓BT節點從布爾判斷升級爲評分篩選。
3. 需要做權衡時用Utility AI
AI需要在「攻擊哪個目標」「撤退還是繼續」之間做動態選擇?用Utility AI。 注意避開三大坑(第三章):評分通脹用S形曲線解決,參數地獄用分組隔離,最優≠有趣用隨機噪聲加多樣性獎勵。
4. 需要規劃多步時用GOAP或HTN
AI不只選下一步,而要規劃一串動作(如「扔閃光彈→翻越掩體→側翼包抄」)。 GOAP適用於戰術場景,HTN適用於長程規劃。開放世界要注意計算開銷。
5. DDA最後再加
動態難度調整是錦上添花,不是地基。先確保遊戲本身的AI夠好,再考慮DDA。最簡單的DDA用if-else就能實現(「如果玩家連續死亡3次,降敵人血量」),最複雜的(如L4D的Director)需要完整的Utility AI系統支撐。
下期預告:機器學習入侵遊戲AI
經典遊戲AI的內容到這裏告一段落。遊戲AI還有更多方向。
下一期將進入一個不同的領域:
強化學習如何讓AI「自學」玩遊戲(AlphaGo、OpenAI Five)
行爲克隆:讓AI學會模仿玩家,而不是被if-else編程
ML-DDA:用強化學習替代人工設計的難度曲線
當遊戲AI遇上大語言模型:NPC不再是木頭,而是活生生的角色
參考文獻
Mark, D. (2009). Behavioral Mathematics for Game AI. Course Technology PTR.
Booth, M. (2009). "The AI Systems of Left 4 Dead." AIIDE-09 (AI and Interactive Digital Entertainment Conference). Valve.
Hunicke, R. (2004). "AI for Dynamic Difficulty Adjustment in Games." AAAI Workshop on Challenges in Game AI.
Hanlon, S. & Watts, C. (BioWare). "Dragon Age: Inquisition's Utility Scoring Architecture." In Game AI Pro 3: Collected Wisdom of Game AI Professionals, Chapter 31. CRC Press.
Berteling, J. (2018). "Beyond Killzone: Creating New AI Systems for Horizon Zero Dawn." Game Developers Conference 2018. Guerrilla Games.
Merrill, B. (2013). "Building Utility Decisions into Your Existing Behavior Tree." In Game AI Pro: Collected Wisdom of Game AI Professionals, Chapter 10. CRC Press.
Csikszentmihalyi, M. (1990). Flow: The Psychology of Optimal Experience. Harper & Row.
Faliszek, C. (2023). Interview on Left 4 Dead's Director and Development History. Game Developer (15th anniversary feature).
Capcom. (2005). Resident Evil 4 Hidden Rank System. (Confirmed via data mining, ~2020; see e.g., "Resident Evil 4's Hidden Difficulty System" analysis videos and community wiki documentation).
Clover Studio. (2006). God Hand Difficulty Level (DL) System. (See community documentation and "Dynamic game difficulty balancing" on *********).
Noonchester, A. [Adam]. (2019). "'Marvel's Spider-Man' AI Postmortem." Game Developers Conference 2019. Insomniac Games.
Hope, A. & Napper, G. (Creative Assembly). (2015). "Building Fear in Alien: Isolation." Game Developers Conference 2015.
Hoge, C. (2018). "Helping Players Hate (or Love) Their Nemesis." Game Developers Conference 2018. Monolith Productions.
Naughty Dog. (2020). "Melee AI in The Last of Us Part II." GDC Vault.
Cheng, A. (2013). XCOM: Enemy Unknown AI session. AI Postmortems: Assassin's Creed III, XCOM: Enemy Unknown, and Warframe (joint panel). Game Developers Conference 2013. Firaxis Games.
Orkin, J. (2006). "Three States and a Plan: The AI of F.E.A.R." Game Developers Conference 2006. Monolith Productions.
Helldivers 2 Patrol System. (Community analysis, 2024). Various player analyses and data mining efforts.
Zubek, R. (2010). "Needs-Based AI." In Game Programming Gems 8, Chapter 9. Course Technology PTR.
本文是遊戲AI科普系列的第三篇。前兩篇見【狀態機篇】和 【行爲樹篇】。第四篇——"機器學習入侵"——敬請期待。
本文純屬技術科普,所有遊戲案例均來自公開資料、GDC演講和學術論文。如有疏漏,歡迎指正。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













