系列前文:
引子
如果你看过本系列的前两篇,你应该还记得:
我们的"老式电视机"(FSM,有限状态机)只会一件事:换频道。简单、粗暴,但也傻得令人心疼。一个被遥控器绑架的电视,永远不知道什么叫"意外"。
接着是"管家"(Behavior Tree,行为树)。笨蛋管家比电视高级一点,他手里有一份带分支的待办清单。优先级明确了,步骤清晰了,他终于不会在路口左右横跳了。
但问题是……
新问题:清单有了,但先干哪个?
想象一下:你给管家下了三条指令
"如果冰箱空了,去超市买菜"
"如果水槽有碗,把碗洗了"
"如果有人在敲门,去开门"
这三件事同时发生了。冰箱空了、水槽有碗、有人在敲门。
管家站在门口,手里拿着洗碗布,背上背着购物袋,满脸困惑。他的待办清单列明了每件事都要做,但面对同时涌来的任务,他不知道该先做哪件。
于是他只能随机切换。去开门 -> 想起要买菜 -> 冲到门口 -> 又想起碗没洗完 -> 冲回厨房 -> 门铃又响了 -> 又冲回去……管家还是那个笨蛋。

管家的困境,正是FSM和BT结构上的限制。
FSM微波炉只有"加热""解冻""烧烤"三档。你把菜放进去只能选一个按钮,微波炉不管菜凉了还是糊了。
BT菜谱能让你按步骤来,先切菜、再热油、再翻炒。但如果客人突然说不吃辣了,菜谱不会告诉你怎么办。
菜谱告诉他每道菜都要做,但没告诉他先上哪道。 厨房里三个灶都在喊"快处理我",而他只有两只手。
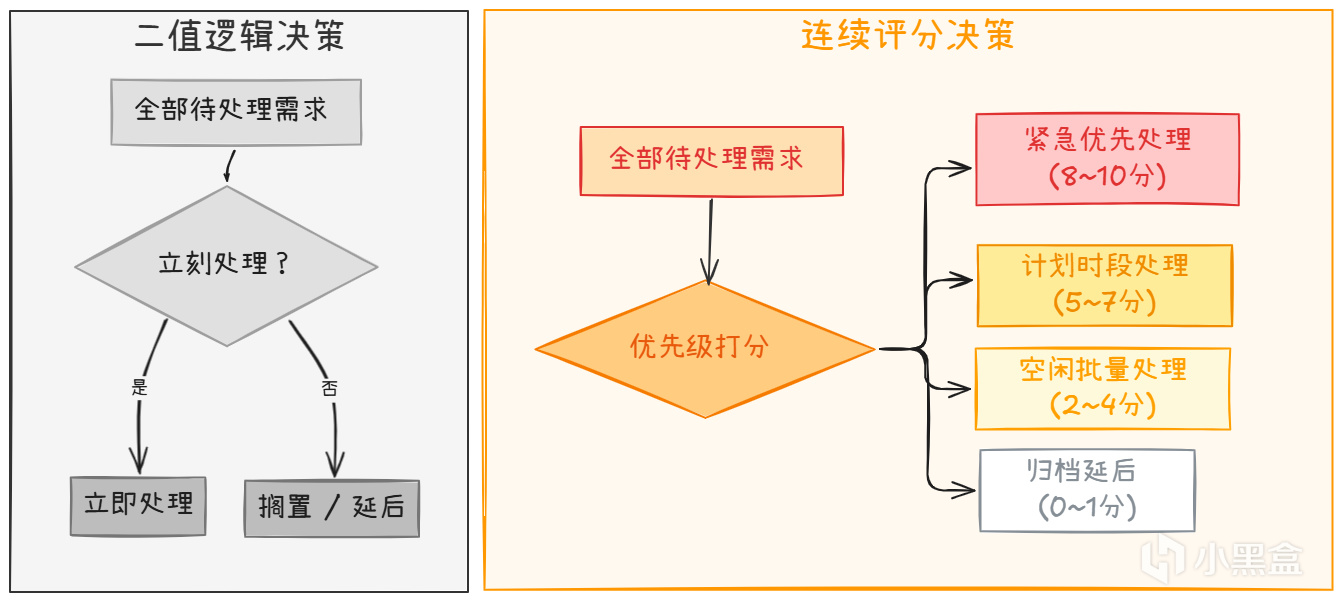
从"该不该"到"有多值得"
关键的一步转变在于提问方式:不要问"该不该做",要问"现在有多值得做"。
冰箱空了 -> 买菜得分 0.95(非常值得)
水槽有碗 -> 洗碗得分 0.80(也值得)
整理书架 -> 得分 0.30(等等再做也行)
这就是 Utility AI(效用AI) 的做法:给每个决策打分,选最高分。
但打分这件事本身没那么简单。
"给我一组参数,我就能撬动整个世界。" 想法很美好,但现实很骨感。
效用值和输入参数之间很少是简单的正比关系,这个世界是非线性的。
第一章:当"是/否"不够用了
FSM/BT的底层:二值逻辑
FSM和BT共享同一个基础:布尔逻辑。
条件要么是 true,要么是 false。敌人距离 < 10 米?是 -> 攻击。否 -> 巡逻。
就像是一盏灯泡:要么亮,要么灭。干净利落,毫不含糊。 传统FSM/BT架构下的AI,其判断是绝对的。
一点补充:严格来说,BT的Decorator节点(如Utility Condition)可以引入连续值判断,让BT具备"有多符合条件"的能力——但这属于BT的扩展用法,不是基础架构的固有特性。标准的BT Condition节点仍然是布尔判断。第七章会详细讨论这种混合模式。
现实世界不是二值的
现实世界并非非黑即白。想象一个场景:
你是一个弓箭手,你的箭囊里还剩最后一支箭。前方有三个目标
目标A:一个普通士兵,距离5米(一箭秒杀)
目标B:一个将军,距离20米(三箭才能杀,但奖金丰厚)
目标C:一只正在逃跑的信鸽(一箭就能射下来,但不确定值不值得)
FSM的逻辑会写成这样:
if (有箭 and 有敌人) -> 攻击最近的敌人
于是你永远朝着最近的士兵射箭,哪怕将军就在旁边。因为你没有"评估目标价值"这个功能。
二值逻辑的问题在于: 世界是连续的、模糊的、需要权衡的,但你的AI只能选择"是"或"否"。
就像你的微信工作群,每个群都在说"快处理我",但你没办法同时回复所有人 ( ;∀;)。你需要一个优先级评分系统。
这种优先级缺失的问题,在早期游戏中表现得尤为明显。
反例:FSM做出来的"弱智AI"
如果你玩过2000年代初期的游戏,你一定见过这种AI:
敌人站在原地,你绕到他背后,他不会转身,因为他只有"发现玩家 -> 攻击"这一条路径
守卫会在哨塔之间来回走,哪怕你在他面前把同伴杀了——他不在"巡逻"状态之外的状态
敌人的攻击模式是固定的三连招,打完就站着不动
这些"弱智时刻"的根源只有一个:设计者把所有可能性用if-else写死了,但游戏里可能出现的情况远比预设的多得多。 (´-ω-`) 谁还没写过几个死if-else呢…
正如资深游戏AI专家Dave Mark在《Behavioral Mathematics for Game AI》中所传达的核心思想那样:
FSM并非万能——行为不是离散的,而是连续的。它需要更灵活的建模方式。
这恰如其分地概括了为什么我们需要Utility AI。
""好,现在我知道怎么打分了。给每个选项打分,选最高的。但是这个分数该怎么算?"
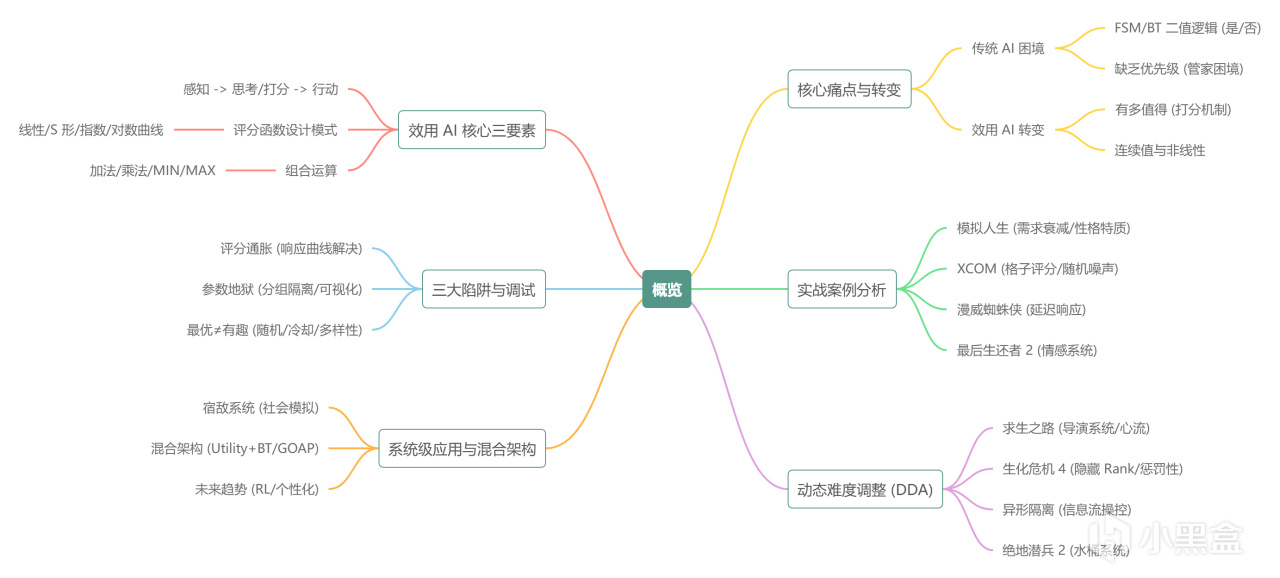
第二章:Utility AI核心三要素
好了,上硬菜。
Utility AI的核心就是三个东西:
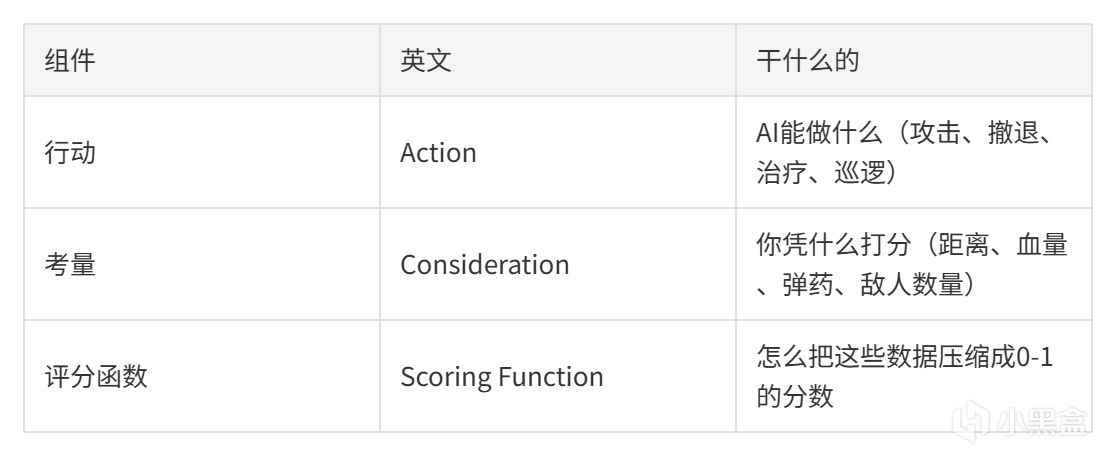
2.1 核心流程:Sense -> Think/Score -> Act

这不就是早上起床的你吗 ( ˘ω˘ )
Sense:闹钟响了,窗外下雨,被窝温度35°C
Score:起床得分0.20,再睡5分钟得分0.95,请病假得分0.80
Act:再睡5分钟(每天都是最高分)
2.2 经典案例1:《模拟人生》——Needs-Based AI
《模拟人生》把需求量化为数值,再用分值驱动行为,这套设计后来被大量模拟经营游戏借鉴。
每个Sim(小人)有八大需求:
饥饿、精力、社交、娱乐、膀胱……
每个需求被量化成一个0-100的数值
当Sim决定做什么时,系统会遍历所有可能的行为(吃饭、睡觉、找人聊天、玩游戏),对每个行为算一个"满足度分数":
吃饭得分 = (饥饿值 - 50) * 0.8 + 随机抖动
睡觉得分 = (精力值 - 30) * 0.7 + 随机抖动
得分最高的行为胜出。
但这里有一个细节问题:如果Sim的饥饿分和社交分都很高怎么办?它会变成一个"在冰箱和电话之间反复横跳"的负智人。
为了解决这个问题,《模拟人生》引入了 Bucketing System(分桶系统),这是一种类似 Dual-Utility Reasoning(双效用推理)的设计思路。
其核心机制是:将所有动机按当前效用值连续排序,分数最高的动机被归入一个桶。Sim只会在当前桶内的行为中寻找可执行的操作,低分桶完全不被考虑。
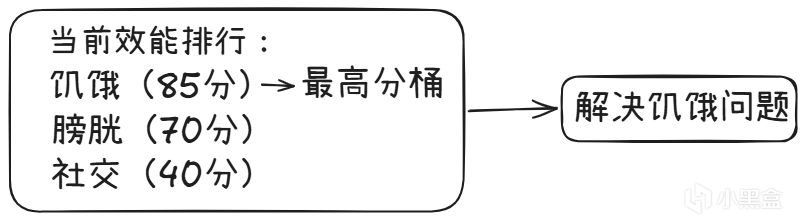
如果最高分桶中没有可执行的操作,Sim才会看下一个分数段的桶。这就是连续分组,而非固定层级——桶的组成随情况动态变化。
它用排序加分桶做决策漏斗,比FSM灵活得多。
一个真正的打工人会先把所有活按紧急程度排序,手里一万个任务也只有一个「最紧急的」搞定了再看下一个。
桶的组成随时变化,哪个需求最急就处理哪个。
深挖一下:Robert Zubek的需求衰减曲线
如果你觉得上面的需求系统只是"饿了就吃饭"这么简单,那你就低估了Maxis的设计功力。
根据Robert Zubek在《Game Programming Gems 8》中的分析(Zubek曾参与《模拟人生3》原型开发,是Needs-Based AI理论的重要总结者),《模拟人生》的需求系统背后有更精细的数学设计。以下数值为示意性示例,用于说明设计原理,并非Maxis官方工程参数:
需求衰减曲线(Decay Curve):每个需求不是线性下降的,而是有自己的衰减速率。
膀胱需求:衰减速率 0.8/小时(攒得快,憋不住)
饥饿需求:衰减速率 0.3/小时(慢饿)
社交需求:衰减速率 0.2/小时(可以独处一段时间)
Character Trait(性格特质)乘子:Sim的性格特质会作为乘子影响需求和行为的评分。
"爱干净"特质 -> 清洁需求衰减速率 × 1.5(脏得更快)
"懒散"特质 -> 所有需求的衰减速率 × 0.8(啥都不着急)
"社交达人"特质 -> 社交行为评分 × 1.3(更喜欢聊天)
同一套需求系统,配上不同的衰减速率和特质乘子,能产生截然不同的行为模式。 一个"爱干净的社交达人"Sim和一个"懒散的独行侠"Sim,虽然底层是同一个Utility引擎,但表现出来的行为却判若两Sim。
在宿舍时,你和你的室友肚子饿了都会去找吃的,但室友可能先把碗洗了再吃("爱干净"特质乘子高),而你直接点外卖("懒散"特质让做饭行为的评分很低)。
2.3 《XCOM: Enemy Unknown》——战术Utility评分
Firaxis的《XCOM》展示了Utility AI在回合制战术场景中的另一种用法。在这款回合制战术游戏中,每个敌方单位每回合需要决定:打谁?用什么武器?要不要用技能?
这不是一个可以预判的决策——因为战场局势每秒都在变。
XCOM的做法是:给每个潜在目标算一个"威胁评分"。
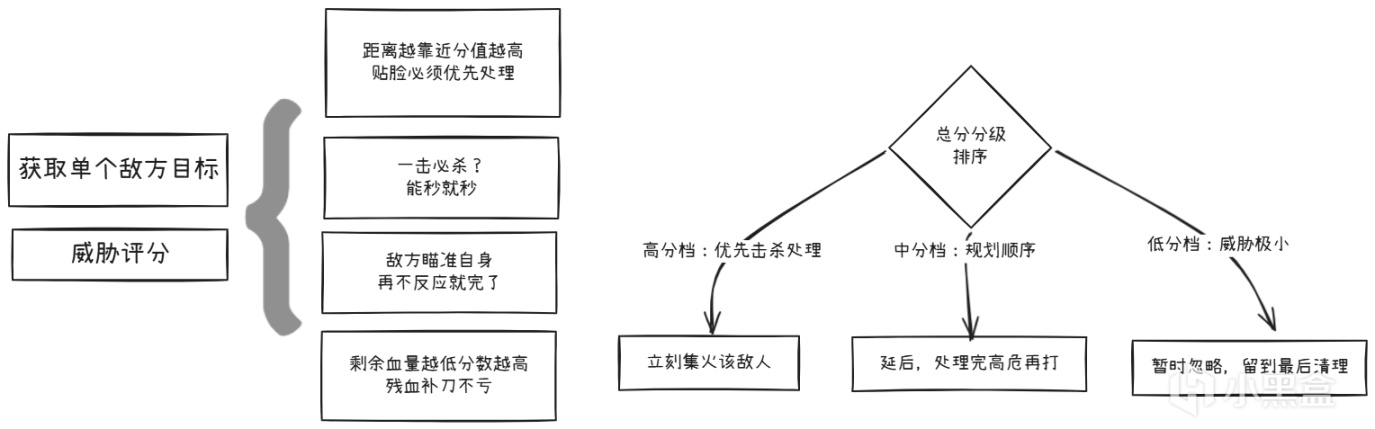
然后AI对每个可能的行动(射击A、射击B、投雷、撤退)都算一个utility分数,选最高的。
但如果AI每次都选"最优解",玩家就会发现敌人的行为模式,然后反过来利用。
所以XCOM在评分里加入了随机噪声(以下为行业常见的噪声注入模式,非官方精确数值):
最终得分 = 计算得分 * (0.8 + 随机(0, 0.4))
这保证了AI不会100%可预测,偶尔会做出"不是最优但更有人味"的决策。
这招可以叫作"脱罪随机数"(plausible deniability)。如果AI做出了一个看似愚蠢的决策,系统可以解释为"它算过,只是噪声太大了"。"我改了一个小参数……奇怪,怎么全都崩了?" ( ;∀;) ノ
深挖一下:Alex Cheng GDC 2013的Tile Scoring System
Alex Cheng在GDC 2013的AI峰会联合Panel——"AI Postmortems: Assassin's Creed III, XCOM: Enemy Unknown, and Warframe"上做了XCOM部分的分享,其中透露了XCOM更底层的设计细节。
Tile Scoring System(格子评分系统):
XCOM的战场被划分为网格状战术格(tile)。AI不仅要决定"打谁",还要决定"走到哪"。每个格子也有自己的utility分数:
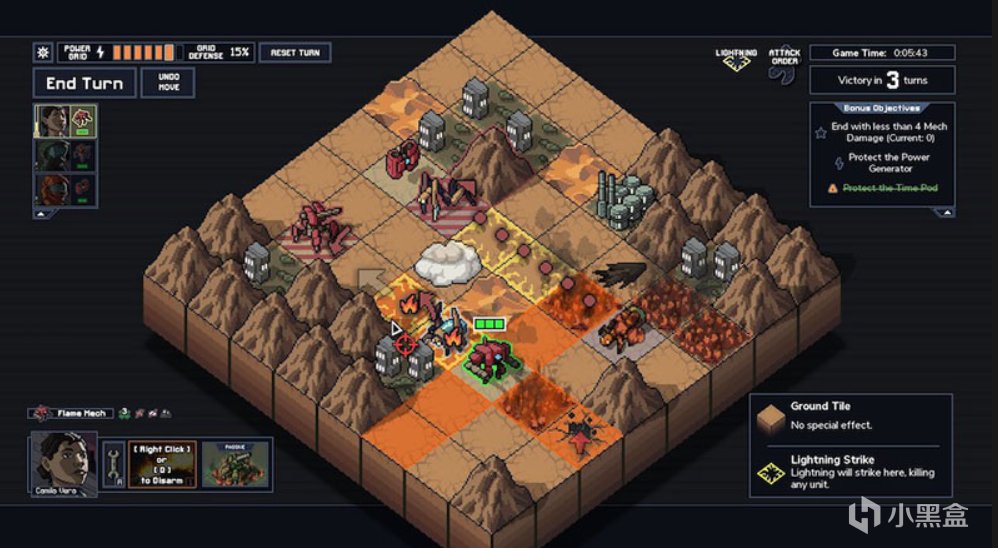
为了直观性,这里使用了《陷阵之志》
格子评分考量因素:
掩体评分:全掩体 +0.4、半掩体 +0.2、无掩体 -0.1
高度评分:高地 +0.3(射击加成)、低地 -0.1
侧翼暴露:暴露在敌人火力下 -0.5
与当前目标的距离:射程内 +0.3、射程外 -0.2
视野覆盖数:能看到N个敌人 -> +N×0.1
AI会为每个可行走格子算分,选最高的。但这还不够——因为AI需要规划"多步行动"。
Hidden Movement机制:
XCOM的AI还有一个"隐藏移动"阶段。在玩家看不到的回合,AI会做多步模拟:
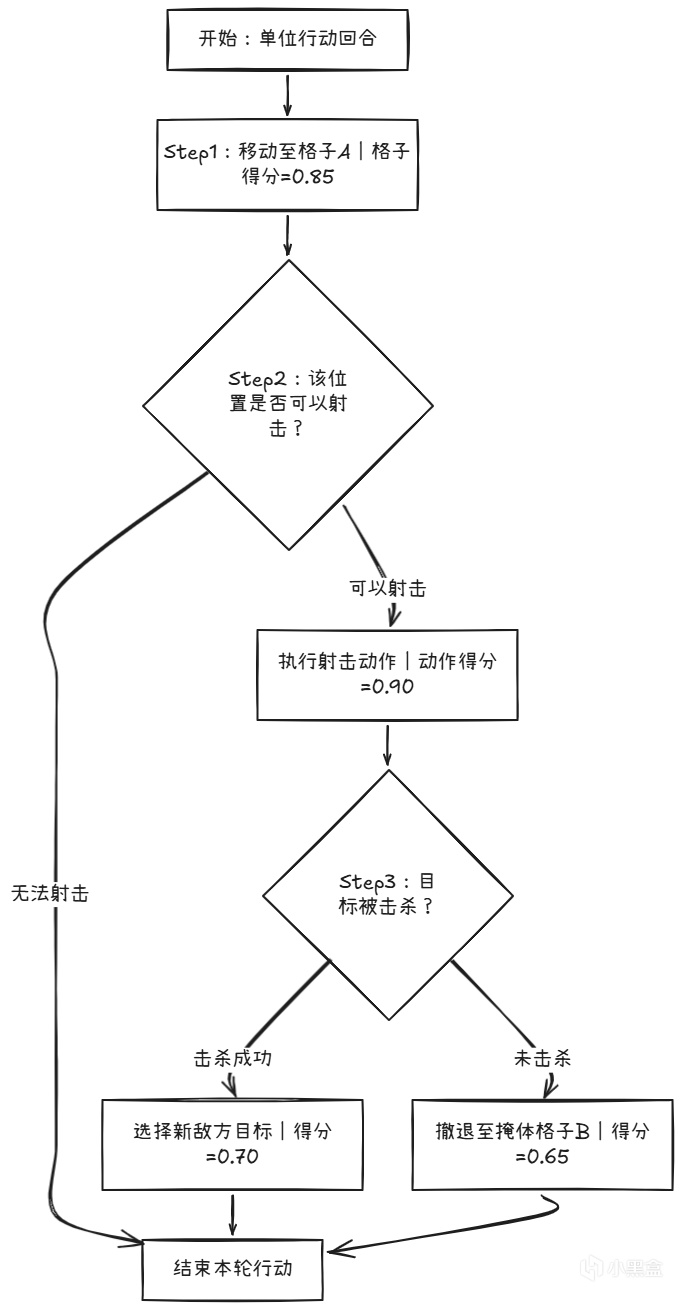
这个"模拟-执行"循环让XCOM的AI看起来有战术眼光,而不仅仅是"谁近打谁"。 XCOM的AI下棋能看三步。你看到的是一个敌人走到你面前,实际上它已经预计了数种不同的开火方案。
2.4 经典案例3:《漫威蜘蛛侠》——敌人实时评分
Insomniac Games在《漫威蜘蛛侠》中把Utility AI用在了敌人决策上(见GDC 2019 "Marvel's Spider-Man AI Postmortem")。每个敌人在战斗中持续对蜘蛛侠做评分:
实用性评分:我手里的武器能不能打到蜘蛛侠?(火箭筒得分高,手枪得分低)
紧急性评分:蜘蛛侠离我多远?他是不是正在打我?
位置评分:我在高处还是低处?有没有障碍物?
当蜘蛛侠跳到你头顶时,所有地面敌人的"攻击得分"会骤降(蜘蛛侠太快了,瞄不准),而高空敌人的"攻击得分"会飙升(终于能打到你了)。
玩家感受到的是:敌人不会傻站着被打,他们会根据局势实时调整策略。
不过Insomniac的设计师很快意识到一个反直觉的问题:AI越聪明,玩家越挫败。
所以他们给Utility AI加了一个"延迟响应":即使敌人判断出了最优策略,也要等一小段时间才执行。
Adam Noonchester的GDC演讲提到了一个"momentary enemy idle timer"机制,具体延迟时间按游戏节奏动态调整。 这让蜘蛛侠有了喘息空间,也让玩家的操作更有意义。
毕竟游戏要的是好玩,而不是难玩。
2.5 评分函数设计模式:爱玩矢量的大爷
前面我们一直在说"算分",但评分函数本身有很多讲究。 同样的输入数据,用不同的曲线处理,会得到天差地别的结果。
下面来看看评分函数的几种常见写法。
线性曲线(Linear)
最简单的评分曲线:输入和输出成正比。
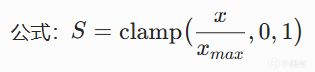
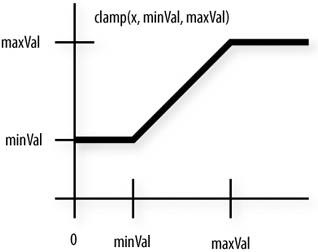
例子:血量百分比 -> 治疗紧迫度。血量50% -> 得分0.50,血量30% -> 得分0.30。
适用场景:当输入和输出关系是"越怎样就越怎样"时。比如距离越近,攻击得分越高。
问题:线性曲线没有"拐点",AI的决策边界很模糊。比如一个敌人从15米走到10米,得分从0.3到0.7,中间的每一米变化都是均匀的。这在某些场景下不够"戏剧性"。
S形曲线(Sigmoid)
在中间区域陡峭,在两端平缓。
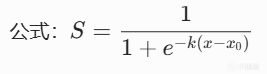
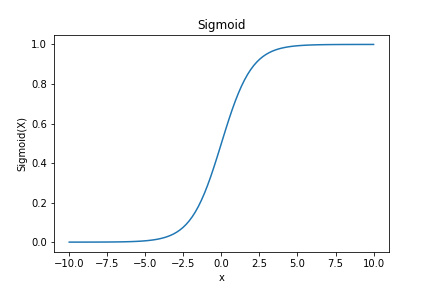
其中k控制陡峭度,中点是曲线拐点。
例子:血量在30%附近时,治疗紧迫度"突然飙升"。血量从40%降到35%,治疗分从0.3跳到0.7,因为30%是"危险线"。
适用场景:当你有"阈值感觉"时,即在某个临界点附近,AI的态度应该"急剧转变"。
游戏案例:在战术游戏中,撤退决策常用S形曲线。当己方血量 > 50%时,撤退分很低;但一旦低于30%,撤退分急剧上升。这模拟了"临阵脱逃的30%红线",士兵在安全时绝不撤退,濒死时拼命逃跑。
指数曲线(Exponential)
低端平缓,高端陡峭,呈现滚雪球效应。
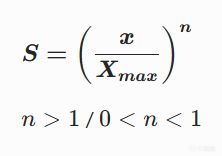
当 n > 1 时,曲线向下弯曲(高分更难达到);当 0 < n < 1 时,曲线向上弯曲(更容易达到高分)。
例子:弹药稀缺度。还有90%子弹 -> 补弹得分0.01;还有10%子弹 -> 补弹得分0.85。因为最后10%的子弹比前90%都"值钱"。
适用场景:当资源匮乏时,稀缺度的感知非线性上升。
注意 :严格数学上这是幂函数(Power Function),但游戏行业常将 (x)^n 称为指数曲线(Exponential Curve)。真正的指数曲线公式为 a^x 。
Unity 其实严格区分了两者 : PowerEase f(t) = t^p (幂函数)ExponentialEase → f(t) = 2^(10(t-1)) (真指数函数)
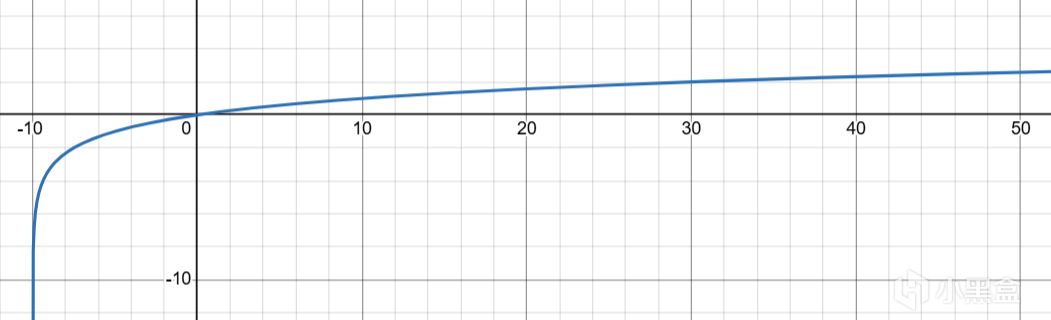
对数曲线(Logarithmic)
低端陡峭,高端平缓,呈现边际递减效应。
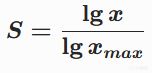
此公式可实现0→1的对数归一化,实践中同样有效。
例子:在《模拟人生》中,社交行为对社交需求的满足。从0到20分钟社交,满足度飙升(你终于有个人说话了);从60到80分钟,满足度几乎不涨(你已经聊累了)。
适用场景:当"有比没有好得多,但多了也没什么用"时。
选择评分曲线就是在选调料:线性是盐(百搭但普通),S形是辣椒(只在关键时刻爆发),指数是糖(越到后面越甜),对数是醋(第一口酸爽,后面就没感觉了)。 一名好的厨师知道什么时候放什么调料。
2.6 考量因素组合的艺术
单条曲线只是基础。真正的挑战在于如何把多个考量因素组合成一个最终分数。
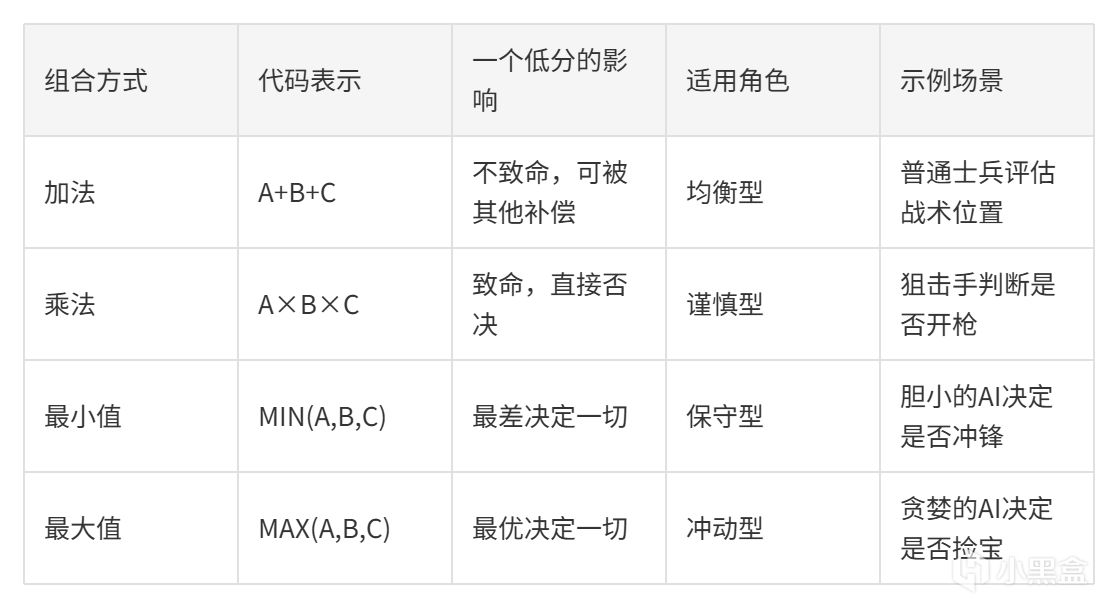
加法组合(Additive)
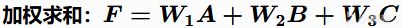
优点:直观、好调参、一个考量得分为0不会让整个决策"死亡"。 缺点:分数容易膨胀,需要精确的权重配比。
例子:XCOM的格子评分就是加法组合,掩体得分 + 高度得分 + 视野覆盖得分。即使某个格子没有掩体(得分为0),它仍然可能因为高地优势而总分很高。
乘法组合(Multiplicative)
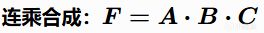
优点:任何一个考量为0,整个决策"一票否决"。 缺点:容易导致分数向低分区压缩(所有得分挤在底部),调参更复杂。
例子:弓箭手判断"是否射箭" = 目标可见度 × 命中概率 × 目标价值。如果目标不可见(得分为0),其他两个考量再高也没用。这就是"一票否决"的威力。
最小值组合(MIN)
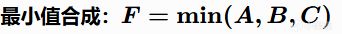
优点:最保守的策略,AI只关注最坏的情况。 缺点:可能过于谨慎,忽略整体优势。
例子:一个胆小的AI判断"是否冲锋" = MIN(血量充足性, 弹药充足性, 掩体距离)。
只要有一项很低,它就不会冲锋,哪怕其他条件都很好。
如果让最挑剔的食客评价来评价一桌菜,只要有一道菜不合口味,整桌都是"零分"。
最大值组合(MAX)
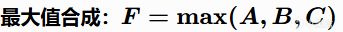
优点:最冒险的策略,AI只关注最好的一面。 缺点:容易做出鲁莽决策。
例子:贪婪的AI判断"是否去捡宝箱" = MAX(好奇心, 对宝藏的渴望, 当前装备的缺乏)。只要有任何一个理由很强烈,它就冲过去了,尽管周围全是敌人。
优劣对比一览
2.7 旁路对比:F.E.A.R.的GOAP
GOAP(Goal-Oriented Action Planning)不是Utility AI,但两者共享评分思想。
GOAP的Planner使用A*搜索在动作空间中找出一条从当前状态到目标状态的最短路径,输出的是行动序列而非单次选择。
关于GOAP的详细原理和F.E.A.R.的实现(两个底层状态 + Planner搜索),已在《FSM篇》和《行为树篇》中详细讲过,此处不再展开。
GOAP vs Utility AI:
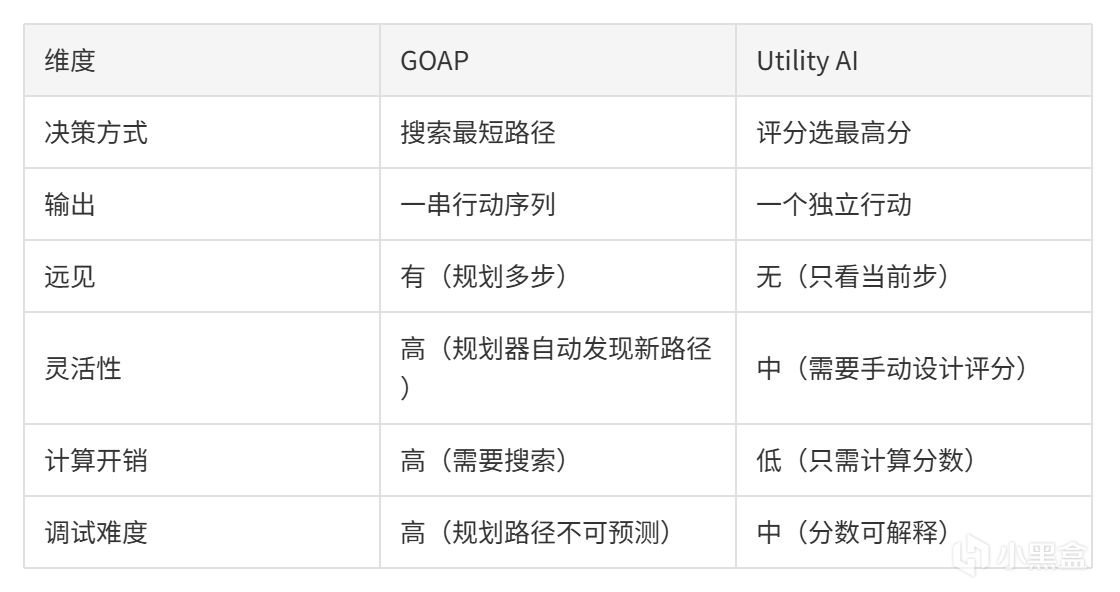
有人说GOAP是"规划+评分"的混合——Planner用评分来决定搜索方向,但最终输出的是规划而不是单次选择。这个观点在第7章我们会再讨论。
言而总之,Utility AI是选择题,只需做出选择即可。GOAP是简答题,你既要选答案还要写出解题步骤。
"打分容易调参难。下一章我们来看看这些参数是怎么让人头疼的。"
第三章:Utility AI的三大坑
你以为评分就是给选项打分就行了?
评分系统上线了,每道菜都有评分,一切看起来很完美。直到遇到三个棘手问题。
3.1 坑1:评分通胀
评分函数设好后,一个诡异的现象出现了:所有任务的得分都在0.9-1.0之间。
冰箱空了 -> 0.95 水槽有碗 -> 0.93 有人在敲门 -> 0.91 窗外有鸟 -> 0.89
评分系统陷入了僵局,生死不明,那就是死了。
所有餐厅都打了5分,那这评分还有什么意义?点开App时每家都是"优秀",反而不知道该去哪家了。 评分通胀让评分系统崩溃了。
这就是 "评分通胀"(Utility Inflation)。 当你的评分函数设计不合理时,所有行动都会被压缩在分数空间的顶部,导致"最高分胜出"机制失效。
为什么会出现评分通胀?
大多数评分函数使用"乘法组合":
最终分 = 考量A × 考量B × 考量C
如果每个考量都在0.8-1.0之间,三个一乘,所有分都"挤在"0.5-1.0的区间。这就等于没区分度。
在两家评分都接近满分的餐厅之间反复横跳,最后饿死了。分都差不多,就等于没分。 你以为你有的选吗?

当我面对选择困难时belike
怎么治?
Dave Mark 在《Behavioral Mathematics for Game AI》里推荐了一个方法:用"响应曲线"(Response Curves)替代线性评分。
线性:分差均匀,容易通胀
S形曲线:低端和高端被压缩,中间放大区分度(推荐用于解决通胀)
指数型:拉大高分和低分的差距
还有一个技巧:用减法替代乘法。
最终分 = 距离分 × 血量分 × 弹药分
最终分 = (距离分 + 血量分 + 弹药分) - (1 - 距离分) × (1 - 血量分) × (1 - 弹药分)
减法的好处是:每个低分考量都会在最终分上留下一个"缺口",分数天然不会挤在顶部。
3.2 坑2:改一个崩一片
评分系统跑了几天,开始出问题了。
问题1:冰箱空了 -> 买菜得分 0.95 -> 系统天天去买菜 -> 家里菜堆成山了
调参数:把"冰箱空"的权重从0.8降到0.5。
然后灾难来了。
问题2:因为调了买菜权重,所有和"食物"相关的决策都变了。洗碗的分也变了(吃饭产生碗筷),出门的分也变了(买菜顺便散步),甚至看电视的分都变了(吃饭的时候看电视)。
一个参数改下去,十个系统跟着变。
这种情况被开发者称为"参数地狱"。
参数A -> 影响评分B -> 影响决策C -> 影响系统D -> 影响...
到底哪里出了问题??
为什么会有参数地狱?
因为Utility AI的评分函数本质是高维参数空间。 修改了"饥饿权重"后,其影响的不只是吃饭决策。它会通过"需求满足度"连锁影响社交意愿、探索意愿、工作效率。
做饭时改了一道菜的盐量,整桌菜的味道都可能受影响。 客人吃了咸的菜再喝汤,会觉得汤有点淡。后厨的调料比例是一个相互依赖的系统,牵一发而动全身。
虽然客人不一定会先吃菜再喝汤就是了。
实际上,参数地狱在游戏开发界是个众所周知的噩梦。
有团队为调一个Utility AI的评分系数投入过数周时间。当你看到游戏里的AI偶尔犯傻,那多半是参数没调好。
BioWare在《龙腾世纪:审判》中怎么解决的?
根据Hanlon & Watts在《Game AI Pro 3》第31章中的详细描述,BioWare采用了多层策略:
差异化评分曲线:每个考量有自己的独立响应曲线。"饥饿"用指数曲线,"疲劳"用S形曲线,"社交"用对数曲线。不共用参数模板。
参数分组隔离:通过"behavior snippet"数据结构封装评分和执行逻辑,战斗参数、社交参数、环境参数分属不同组。改战斗参数不会影响社交评分。
视觉化调试工具:实时显示每个行动的评分分解(《Game AI Pro 3》第31章中描述的debug-viewable scoring breakdown table):"为什么攻击得分是0.85?因为距离分0.90 × 血量分0.95 = 0.855"。
迭代测试流程:每次参数修改后,通过调试表比对行为变化是否符合预期(此外,Sebastian Hanlon在GDC 2016上做了"Getting Inquisitive About the AI of Dragon Age Inquisition"演讲,展示了更多调试工具链细节)。
核心思路就是分开管理、可视化、自动化测试。每个工具干自己的活,别搅在一起。
3.3 坑3:最优决策不等于有趣决策
这是Utility AI最大的困境。
假设你有一个Boss AI,它的决策逻辑是:
攻击玩家(如果玩家在射程内 + 自己有血量 > 50%)-> 得分0.90
召唤小兵(如果小兵数量 < 3)-> 得分0.85
释放大招(如果冷却已好 + 玩家血量 < 30%)-> 得分0.70
Boss每次都会选择"攻击玩家",因为得分最高。
但如果Boss每次都只攻击,玩家的体验就会很无聊。 一只只会平A、既不召唤小兵也不放大招的Boss毫无惊喜可言。
最优决策往往是最无聊的决策。

火车难题最优结局
这就成了一个矛盾:"AI太聪明反而不聪明"。有时去追求最大化Utility,结果却最小化了乐趣。
怎么平衡?
几个常见策略:
添加随机噪声(XCOM的做法):在最终分上加10-20%的随机偏移,让次优解偶尔胜出
冷却器机制(Cooldown):当一个行动连续胜出N次后,降低它的分数(逼AI"休息")
多样性奖励:如果一个行动长时间没被选中,给它加分(鼓励AI展示更多行为)
Exhaustion机制:一个行动被执行后,短时间内评分归零("刚喊过救命,现在不用再喊了")
主包很喜欢吃食堂的麻辣烫,尽管知道麻辣烫最好吃(最优解),但总不能一年吃365天麻辣烫吧?偶尔也要整点小汉堡换换口味。这就是"多样性奖励"。
3.4 全新案例:TLoU2的"情感系统"如何帮AI避免最优≠有趣
Naughty Dog在《The Last of Us Part II》中做了一个很有意思的设计:给AI加情感维度。
详见GDC演讲"Melee AI in The Last of Us Part II"及"Emotional Systemic Facial of Last of Us Part II"
每一个人类敌人都有情感状态:恐惧、愤怒、悲伤。这些情感不是装饰,它们作为额外考量因素直接影响Utility评分。
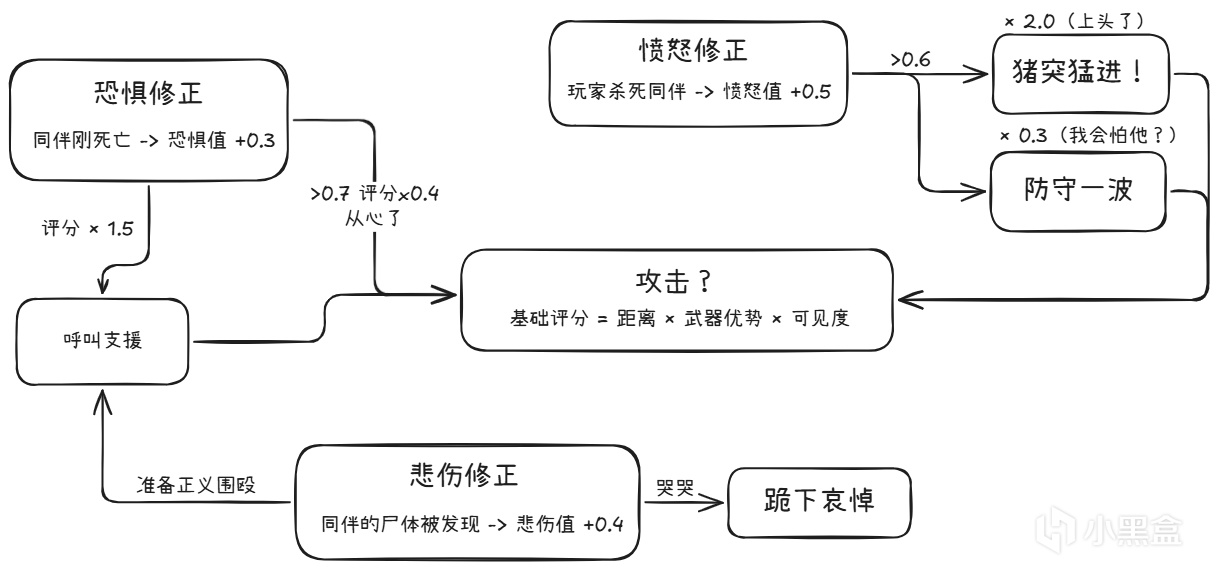
TLoU2还做了一个有意思的设计:敌人会喊出同伴的名字。当你杀了"Elena"之后,另一个敌人会在搜索时说"Elena? Elena, where are you?"
这个功能不是预先录好的,它通过程序化对话系统实时生成。
技术实现路径大致是:
每个敌人有一个"关系网络"(知道哪些人是同伴)
同伴死亡事件触发 -> 情感系统更新恐惧/愤怒值
根据情感值决定对话内容 -> "愤怒 -> 复仇宣言"、"恐惧 -> 呼喊确认生死"
对话内容覆盖基础Utility评分(喊话期间AI的"搜索"评分高于"攻击"评分)
情感维度让AI不再只做数学优化,行为变得不可预测。当一个敌人因为愤怒而鲁莽冲锋时,它做出了一个"非最优"但"有故事感"的决策。玩家会觉得:这个AI在为同伴报仇。

摆手不是拒绝,而是无需多言
即使是个理性的人,当看到朋友被人欺负时,尽管知道打架不好,肾上腺素也会让其上头。 情绪来了的时候,人顾不上算最优解。TLoU2的AI就是这种人。
3.5 调试工具链:为什么Utility AI需要可视化
Utility AI的评分不只是"几个数字算来算去"。真正去调的时候就会发现,没有可视化调试器,调参就是盲猜。
可视化调试器的重要性
你在开发一个游戏,敌人AI突然抽风了——明明没有敌人它却在"警惕"状态。 你打开代码,翻到评分函数,对着十几个参数发呆。
到底是"距离分"算错了,还是"威胁评估"权重太高,还是"随机噪声"这次运气不好?三个答案都可能是对的,但你没有数据,你只能靠猜。 改一个参数,重新编译,跑一遍,看效果。循环10次,终于好了。但你可能改错了参数,只是碰巧效果对了。
这就是没有调试器的日常。
BioWare的DAI调试工具长什么样?
根据Hanlon的分享,BioWare为《龙腾世纪:审判》的Utility AI构建了一个完整的可视化调试面板。
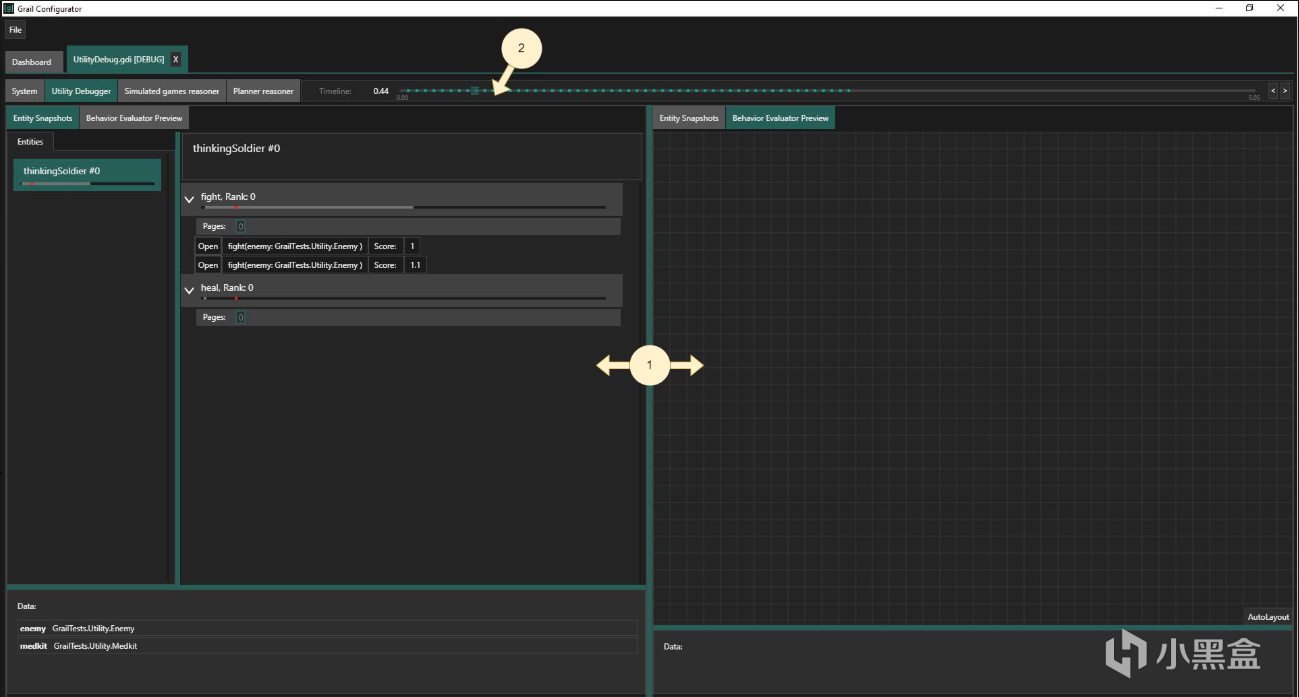
这个面板让设计师能实时看到每个决策的"数学解剖"。
如果AI总是选择不合理的行动 -> 直接看每个考量的分数分解
如果某个考量始终贡献很低 -> 可能权重太小或者曲线设计不合理
如果随机噪声主导了决策 -> 噪声幅度太大了
开发Utility AI的第一条规则:没有可视化调试器,就不要做Utility AI。
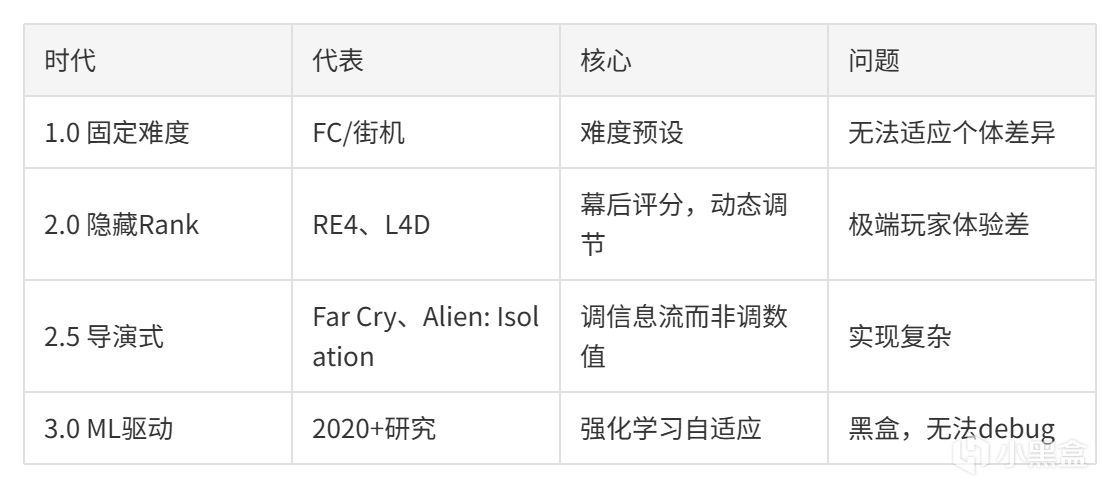
第四章:Left 4 Dead 的 Utility DDA
如果你只玩过一个有DDA(动态难度调整)的游戏,那大概率是《Left 4 Dead》(求生之路)。 Valve的这款2008年僵尸射击游戏,至今仍是DDA领域被频繁引用的案例。
L4D的DDA系统:Director(导演)是一个Utility AI和心流理论的结合。
它的出发点是一个问题:"你觉得玩家什么时候玩得最开心?"
大部分AI设计者在想"怎么让AI做更好的决策",但L4D的设计师更关心"玩家什么时候最开心"。
这就是Director的出发点。
4.1 心流理论:DDA的心理学基础
在讲L4D之前,必须先说一个人:Mihaly Csikszentmihalyi(米哈里·契克森米哈赖)。
1990年,他提出了心流理论(Flow Theory):
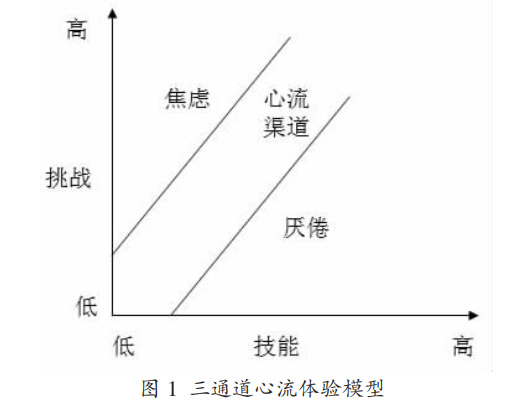
如果挑战太高、能力太低 -> 玩家焦虑(想摔手柄)
如果挑战太低、能力太高 -> 玩家无聊(想换游戏)
心流通道:挑战和能力匹配 -> 玩家沉浸,忘记时间
L4D的Director首次将心流理论系统化地整合进DDA架构。更早的游戏如1990年代的赛车游戏已有基于玩家表现的动态难度实践,但L4D首次将其提升到了系统化、可解释的架构层面。
4.2 L4D Director 四大系统
Mike Booth在2009年的AIIDE(人工智能与交互数字娱乐国际会议)上做了《The AI Systems of Left 4 Dead》的演讲(同年在GDC 2009上还做了《From Counter-Strike to Left 4 Dead: Creating Replayable Cooperative Experiences》分享)。Director由四个核心系统组成:
4.2.1 Flow Distance(流程距离)
Director用"流程距离"来衡量玩家在关卡中的进度。 根据Mike Booth的GDC演讲描述,Flow Distance更准确地说是玩家到关底的最短路径上的关键事件序列,是一个空间加事件的复合度量。
具体来说:
起点:距离0,新手村,Director派最弱的僵尸
中途:距离50%,Director开始热身
终点前:距离90%,Director准备上上强度
具体的事件序列大致如下:
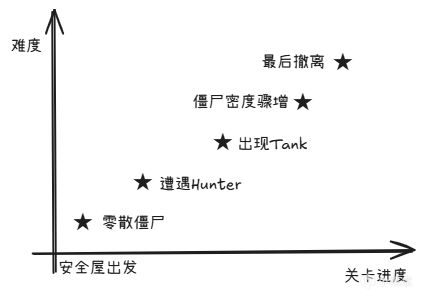
本质上就是"温水煮青蛙"。你不会一下子觉得难,但回头看时已经超过了退款时间。
4.2.2 Active Area Set(活动区域集)
Director把关卡分成一个个"活动区域"(AAS)。它知道玩家在哪个区域里,知道附近有哪些刷怪点、哪些掩体、哪些高地。
就如电影导演知道舞台上有哪些道具:"现在演员站在舞台左边,我就从右边放烟幕弹。"
AAS的具体工作方式:
关卡设计时预标注:每个区域的刷怪点、安全点、补给点
运行时追踪:玩家当前在哪个AAS中
动态选择:只在玩家附近的AAS中生成事件(避免"在玩家背后刷怪"的作弊感)
区域切换:玩家从一个AAS进入另一个时,Director重新评估节奏
4.2.3 Survivor Intensity(幸存者紧张度)
这是Director的监测器。它将持续追踪:
玩家当前血量
最近受伤频率
倒地次数
被特殊感染者攻击次数
队伍整体血量百分比
最近60秒内的"危机事件"数量
紧张度的计算方式(根据GDC演讲和社区逆向分析,大致模型如下):

仅作参考,并非精确数值
如果紧张度太高 -> Director降难度(少刷特感、多刷药包) 如果紧张度太低 -> Director升难度(刷个Tank过来,给玩家提提神)
阈值触发逻辑(以下为社区分析推测的近似阈值,非官方确认值):
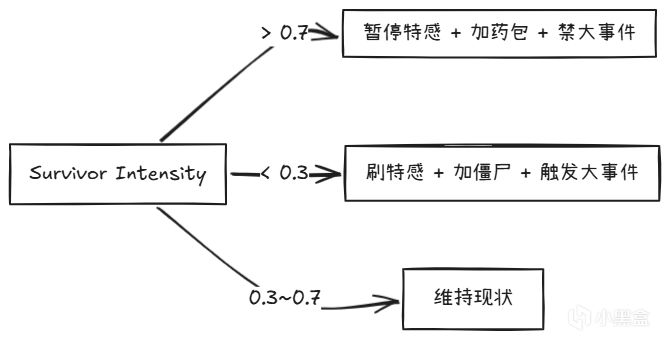
类似于餐厅里的大堂经理,看客人狼吞虎咽就放慢上菜节奏(降速),看客人久不落筷就加快上菜节奏(提速)。
4.2.4 Adaptive Dramatic Pacing(自适应戏剧节奏)
这是Director的"叙事感"组件。它不只是调难度,它还在编排:调高潮、低谷、转折。
Director会给每个"戏剧节拍"打分:
上一次高潮过去多久了?太久 -> 该来一波大的了(得分高)
玩家刚打完Boss,残血 -> 不让僵尸出现,给恢复时间(得分低)
玩家刚进一个新区域 -> 刷几个僵尸"欢迎"(得分中)
Director是一个持续的"戏剧节奏评分器",不是if-else的状态机。这是Utility AI在DDA中的典型应用。
Director是餐厅的大堂经理。他不会在客人刚坐下吃开胃菜时就上主菜,也不会在客人吃饱了才上甜品。 他会观察每桌的进食节奏,吃得快的催后厨快点上,在聊天的慢慢来。 这位经理会安排整个餐厅的上菜节奏。
4.3 Boss Card Shuffle:L4D的卡牌洗牌机制
L4D的Boss生成机制用了卡牌洗牌的逻辑。
Director手里有一副"Boss卡牌"(以下概率分布基于玩家社区统计和GDC演讲中的描述,非精确官方数据):

主包帮你们开了认知滤镜(╹╹ )
当Director决定要搞一波大的时,它不是随机选一张卡。
它选择洗牌。
洗牌逻辑的核心:
如果玩家刚打完Tank -> Tank的牌从牌组中移出(短时间内不会再次出现)
如果Hunter连续出现两次 -> Hunter的优先级下降("多样性奖励"的典型)
如果玩家对Witch反应特别慢(被秒了)-> Witch概率下降
这是一个离散型的Utility系统:每个Boss类型根据历史数据实时调整"被选中概率"。
这个系统太成功了,后来被不少游戏借鉴,包括《战争机器》的Horde Mode、《Back 4 Blood》、甚至《Helldivers 2》的Patrol系统。
4.4 物品动态转换:给玩家送温暖
L4D还有一个低调但极其聪明的DDA设计:物品动态转换。
Director持续追踪玩家队伍的"贫穷度":
弹尽粮绝?下一个房间刷弹药
全员残血?转角处必有药包
有人倒地?附近补血点
Director做得很隐蔽,不会在玩家残血时突然在天上掉药包。它会在前面的房间里"恰好"放一个药包,看起来像是"本来就有的"。
这样玩家就会觉得"是我自己找到了资源",而不是"系统可怜我才给我"。
一名服务员看到客人被辣到,她不会直接说"您不能吃辣吧"。 她会"恰好"端来一杯柠檬水,轻轻放在客人手边。(这边更推荐牛奶或豆乳哦)
4.5 番外篇:Chet Faliszek谈Valve为什么没公开Director
Valve藏了一个惊天秘密,他们做了DDA,但最初没告诉任何人。
2023年,在L4D发售15周年之际,编剧兼制作人Chet Faliszek接受Game Developer专访时聊到了一个有趣的往事:
L4D最初发布时,Valve完全没公开DDA系统的存在。Director的一切都在幕后运行,玩家根本不知道有这个东西。
但在游戏发售后,玩家在论坛上疯狂讨论:
"你有没有发现,后面刷出来的僵尸好像跟你的表现有关?"
"我觉得有隐藏系统在控制难度——太神奇了"
"我残血的时候总能在角落里找到药包,这不是巧合!"
社区自发地开始"挖掘"Director的秘密,形成了大量讨论帖、攻略视频、数据分析。
Chet在访谈中笑着说:"看到玩家自己发现Director的运作方式,这是最有意思的部分。" 虽然访谈中没有明确说Valve"刻意隐瞒",但社区确实是在游戏发售后通过逆向工程和实践逐步摸清了Director的工作原理。
这段故事告诉我们:有时候最好的设计,是玩家都还没意识到自己在被设计。
第五章:DDA的多样面孔——从隐藏Rank到信息流操控
L4D的Director至少Valve后来承认了它的存在。有些游戏从不承认——它们做了DDA,但永远不告诉你。直到十年后,数据挖掘者才翻出来。
这一章看DDA的三种面孔: 惩罚性DDA(你强我就更难)、导演式DDA(我帮你安排节奏)和解耦式DDA(我不直接调难度,我调信息流)。
5.1 隐藏Rank流派:你强我更难
生化危机4(2005)+ God Hand(2006):三上真司的DDA双响炮
三上真司的《生化危机4》是游戏史上最被低估的DDA案例之一。
这个系统完全隐藏,游戏手册里没有,开发者访谈里没有,玩家论坛上争论了十年。直到数据挖掘者在2020年拆包才确认。
RE4隐藏Rank怎么工作的?
每个玩家有一个看不见的 Rank 值(社区分析认为系统通过Action Points动态调整,数值范围因数据挖掘版本而异),全程实时变化(以下数值基于社区数据挖掘分析,不同资料来源可能存在差异):
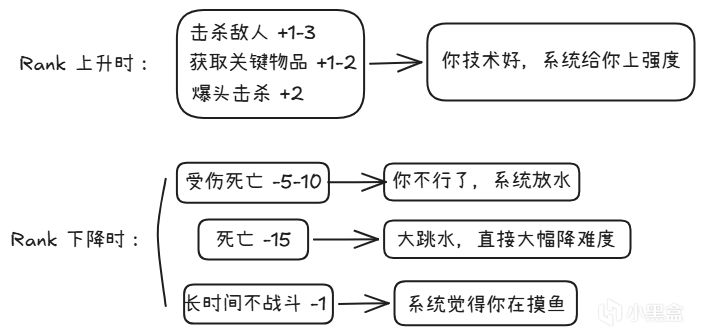
Rank影响什么?
敌人攻击性:Rank高 -> 敌人更主动、更激进;Rank低 -> 敌人更"迟钝"
敌人血量:Rank高 -> 村民能吃更多枪;Rank低 -> 两枪就倒
反应时间:Rank高 -> 敌人闪避更快;Rank低 -> 敌人站桩挨打
弹药掉落率:Rank高 -> 弹药掉落少(你技术好,不需要太多子弹);Rank低 -> 弹药掉落多(给你补个弹)
如果你是个高手,系统会"奖励"你更难的游戏——敌人更硬、更快。
如果你是个菜鸟,系统会"保护"你——敌人变软、弹药变多。
但问题在于,高手的Rank越高,游戏越难;菜鸟的Rank越低,游戏越简单。这并不算平衡难度,而是在拉大贫富差距。
考试的时候,学霸越学越觉得题简单,学渣越学越觉得题难。然后系统给学霸加附加题,给学渣减题目。差距只会越来越大。
"原来我玩游戏觉得越来越难,不是因为游戏真的难,而是游戏觉得我太强了。 "RE4度量的是你的技术,所以它给你的回报是更强的敌人。但这是玩家想要的回报吗?
而三上真司的另一款神作《God Hand》(2006)走了另一个极端。它的隐藏DDA系统叫 "难度等级"(Difficulty Level, DL):
DL 1(最简单):敌人站着不动让你打
DL 2(中等):正常的攻防节奏 DL 3(较难):敌人进攻积极
DL Die(最难):敌人疯狂进攻,几乎不给喘息时间
每次攻击命中敌人 -> DL +1 每次被敌人命中 -> DL -1 使用特定招式 -> DL 大幅上升
你打得越好,系统越不让你好过。
这被称为"惩罚性DDA":系统不是帮助你,而是挑战你。 你表现出色,系统提高难度,看看你到底能走多远。
面对拳击教练时,你打中他一拳,他不会说"好棒哦,给你一朵小红花"。 他会更狠地还手,因为你在变强。
RE4 Remake(2023):保留了一部分自适应的味道
2023年的《生化危机4 重制版》保留了隐藏Rank系统,但做了一些调整(据Mod社区的逆向分析及玩家反馈):
Rank调整幅度更温和(不会让玩家明显感觉到难度波动)
加入了"安全网":如果玩家连续多次死亡,Rank会有一个"保底下限"
弹药掉落还是自适应,但极端情况被锁死
Capcom的设计师显然意识到了原版的"贫富差距"问题,但他们不想完全抛弃这个系统。因为它确实让更多人能通关。这是一个"让所有人都能玩完故事"的设计思想。
是故意的(骄傲)
Robin Hunicke的HAMLET(2004)
2004年,Robin Hunicke(后来成为《Journey》的制作人)在AAAI上发表了关于DDA的经典论文,提出了两个关键概念:
Proactive DDA(主动式DDA)
系统在玩家还没意识到自己需要帮助之前就调整难度。
玩家血量还有70% -> 系统检测到玩家最近的命中率下降 -> 提前降低敌人生成速度
玩家还没死亡 -> 系统"未雨绸缪"地给装备调整
优点:无缝衔接,玩家完全感觉不到 缺点:误判率高(玩家只是在喝水,系统就以为他不行了)
Reactive DDA(反应式DDA)
系统在玩家遇到困难后才调整难度。
玩家连续死亡3次 -> 降低敌人血量
玩家卡关30分钟 -> 刷出更多弹药
优点:准(数据充足,不会误判) 缺点:慢(玩家已经被虐了才来帮忙)
HAMLET认为:最好的DDA是"主动+反应"的混合。用主动式维持心流,用反应式兜底防死局。
新拿了驾照的朋友开车带你去旅游,主动式是他看到前面有坑就提前减速;反应式是你喊"慢点慢点"了他才刹车。
5.2 Alien: Isolation双层AI:信息流操控
Creative Director Alistair Hope在GDC 2015上做了"Building Fear in Alien: Isolation"的演讲,Lead Designer Gary Napper也在多个采访中详细解释了AI架构。其中描述的AI架构至今仍是游戏AI课程中的经典案例。
双层解耦架构
《异形:隔离》的AI由两个独立的系统组成
它们解耦(decoupled)运行:
第一层:Director AI(导演AI)
知道玩家的精确位置
负责监控整体局势
它的职责是不是直接操控异形,而是给异形提供"线索"
第二层:Alien AI(异形AI)
不知道玩家的精确位置
只能通过游戏世界中的线索来推断玩家位置
移动逻辑:搜索 -> 听到声音 -> 靠近 -> 搜索 -> 循环
为什么解耦是核心创新?
如果异形直接知道你的位置,游戏就变成了"异形永远跟着你跑"。
玩家没有喘息空间,游戏体验就是持续的压迫感,没有节奏变化。
如果异形完全不知道你的位置,游戏就变成了"异形在瞎逛"。
没有紧张感,玩家会觉得AI傻。
解耦的解决方案:异形不知道你的位置,但导演AI知道。导演AI不是直接告诉异形"你在柜子里",而是在你的位置附近"放置"线索。
比如在附近的通风口放出声音、在你的路径上留下痕迹。
这样一来,异形的行为看起来是自然的搜索行为,而不是"作弊式追踪"。
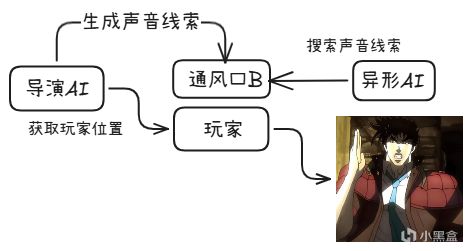
最好的DDA不是调数值,是调信息流。
《异形:隔离》的DDA和RE4、God Hand完全不同。
RE4调的是敌人的血量、攻击性等数值参数。 L4D Director调的是僵尸的生成频率、资源投放等游戏参数。
但Alien: Isolation调的是信息流。
也就是"异形知道多少关于玩家位置的信息"。
当玩家太安逸(躲在一个柜子里太久)-> 导演AI给异形更多线索,缩小搜索区域
当玩家太紧张(刚被异形追过)-> 导演AI暂时不给异形线索,让异形"迷路"
当游戏节奏太慢 -> 导演AI让异形巡逻得更积极
当游戏节奏太快 -> 导演AI让异形"分心"去看别的地方
它调整的不是"谁更强",是"谁知道什么"。
这比调数值更隐蔽,也更难被玩家察觉。玩家会觉得"异形是靠自己的搜索能力找到我的"。
RE4像是给你的考试加分减分,L4D像是调整试卷难度,Alien: Isolation像是老师在你旁边路过,看了一眼你的试卷,然后你慌了。老师什么都没做,只是调整了信息的流动。
最高明的DDA,不是改变世界,而是改变世界被感知的方式。它调整信息如何流动,让参与者"恰好"知道什么时候该做什么。
5.3 Helldivers 2 Patrol System:当你清完所有哨站……
Arrowhead Game Studios在2024年的爆款《Helldivers 2》中展示了一个反直觉的DDA设计。
Bucket System(水桶系统)
Helldivers 2的刷怪系统不是简单的"附近有玩家就刷怪"。它使用了一个被称为"Bucket"的系统:
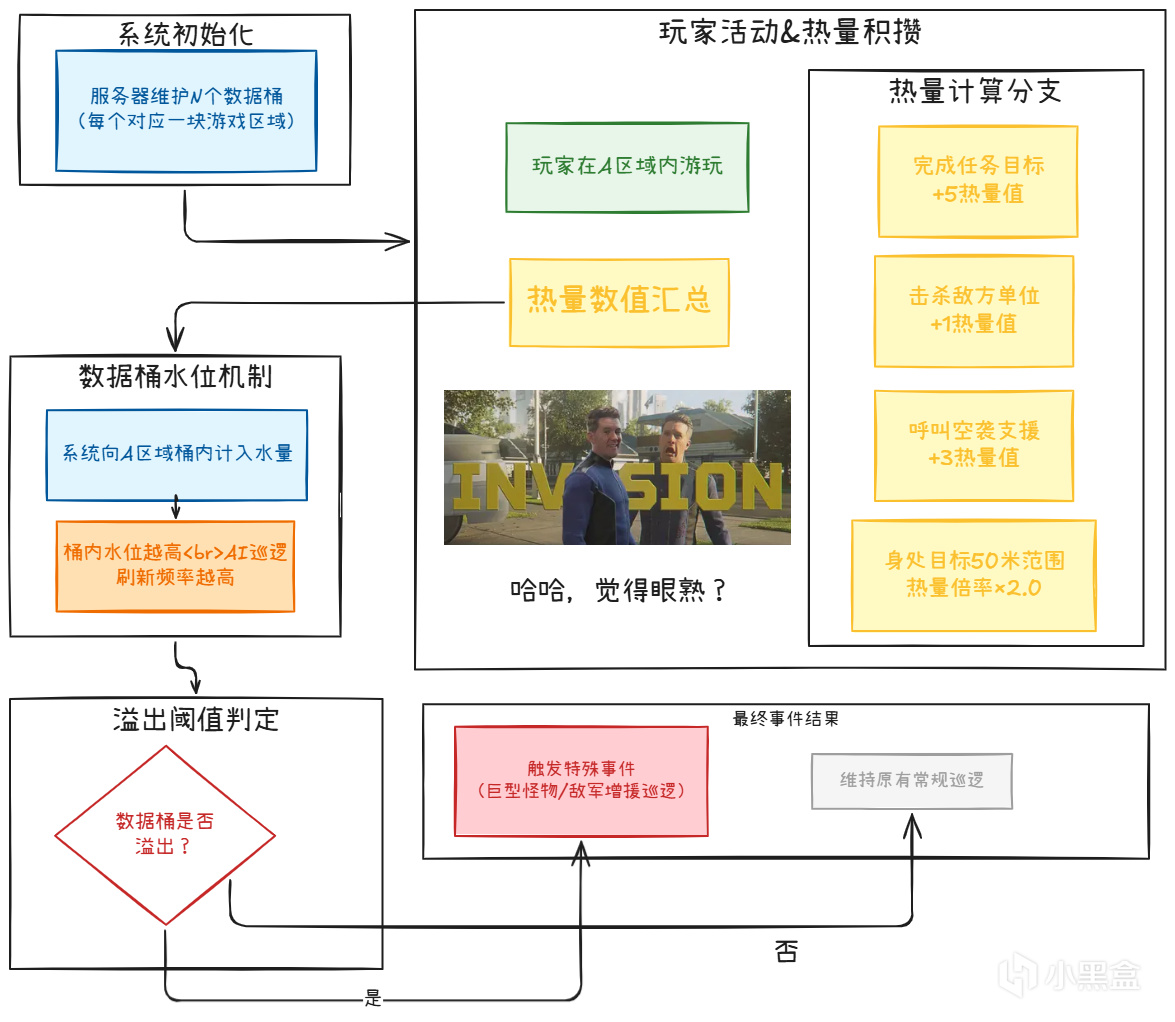
加入绝地潜兵!
Heat Generation(热量生成)
这是Helldivers 2反直觉设计的核心。
任务目标50米内热量最高:你没看错,越靠近任务目标,刷怪越猛。这意味着你不可能"偷偷摸摸做完任务然后溜走"。游戏逼着你硬刚。
哨站清除与刷怪率的关系(基于社区数据分析,不同补丁版本可能存在差异):
清除0%哨站:基准线(刷怪速度 100%)
清除部分哨站:刷怪速度小幅累进上升
清除所有哨站:刷怪速度约提升 17.5%(最终刷怪率约 117.5%)
反直觉的设计:清完所有哨站后,刷怪速度反而加快17.5%(相较于基准线)。
为什么这么设计?因为:
清完所有哨站意味着玩家已经展示了"征服力" -> 系统提高挑战
清完哨站后玩家的主要目标是撤离 -> 系统刷怪阻止撤离(制造最终高潮)
清完哨站后玩家通常会松懈 -> 系统趁你松懈给你惊喜
"评分、评分、评分。打分的世界里,还有没有比分数更重要的东西?"
第六章:超越评分:Utility遇见系统设计
到目前为止,我们都是将Utility AI作为决策引擎来讲:给行动打分,选最高分。它还可以做更大的事——当整个系统的基础。
这一章看三个案例。
6.1 Nemesis System(宿敌系统):Utility AI下的社会模拟
Monolith Productions的《中土世界:暗影魔多》(2014)的Nemesis System在设计上做得比较彻底。
Chris Hoge在GDC 2018上做了"Helping Players Hate (or Love) Their Nemesis"的演讲,解析了Player Interaction Score(PIS)等核心机制。
表面:程序化层级关系
Nemesis System最广为人知的是:兽人军团有自己的一套社会结构。

原谅我,这真的不好画
当你杀死一个副官时,它的保镖可能会晋升为新的副官,或者另一个副官趁机吞并它的地盘。这个层级会持续变化,是一套动态的社会模拟。
支撑这些行为的,是Utility评分。
每个兽人角色有多个评分维度:
攻击力评分 = 武器熟练度 × 等级乘子 + 性格偏移
防御力评分 = 护甲质量 × 等级乘子 + 性格偏移
忠诚度评分 = 对上级的服从度 × 性格特质
野心评分 = 求晋升的欲望 × 当前地位 + 性格偏移
威胁评分 = 对玩家的威胁程度(距离 × 等级 × 装备)
注:这里的"性格偏移"是基于角色种子生成的固定值,不是每帧变化的真随机,避免行为抖动。
这些评分驱动了兽人社会的所有决策:
角色记忆与动态叙事的自然产生
Nemesis System的另一个核心是角色记忆。每个兽人记住和玩家的交互历史:
兽人"Goroth the Stabber"的记忆:
遭遇玩家3次
第1次:被玩家砍掉左臂(但没死)
第2次:被玩家用火烧(但逃跑了)
第3次:成功偷袭玩家(让玩家死了一次)
当前状态:
对玩家的恐惧评分:0.7(被打怕了)
对玩家的愤怒评分:0.9(但仇恨更深)
每次见到玩家说:特定对话("你还记得我的左臂吗?")
当这个兽人再次遇到玩家时,它的Utility评分会调用这些记忆维度:
攻击评分 = 攻击力 × 对玩家愤怒评分 × (1 - 对玩家恐惧评分)
如果恐惧大于愤怒,它可能会逃跑或求饶。如果愤怒大于恐惧,它会加倍疯狂地攻击。

当你砍了Goroth的左臂,三个月后它成了大佬,带着全身铁甲回来找你报仇。Nemesis System让Utility AI从决策引擎扩展到社会模拟。评分负责底层计算,上层跑出角色之间的动态关系。
6.2 TLoU2的狗追踪与记忆系统:情感能力的再升级
我们在第三章提到了TLoU2的情感系统。但那个系统还有一个更有意思的应用:狗追踪系统。
狗的追踪机制
TLoU2中的军犬(德国牧羊犬)有一个专门的追踪AI:
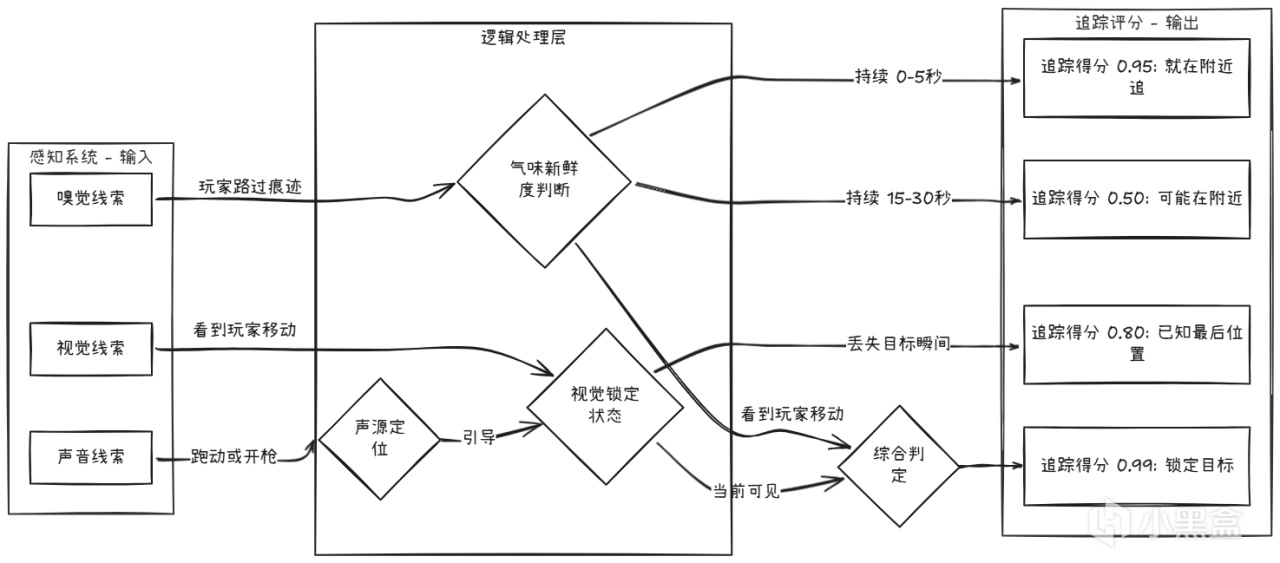
记忆系统:已知最后位置
狗的记忆系统不仅仅用于追踪,它也用于搜索模式。
当狗失去玩家踪迹时,它会在最后已知位置做圆周搜索:
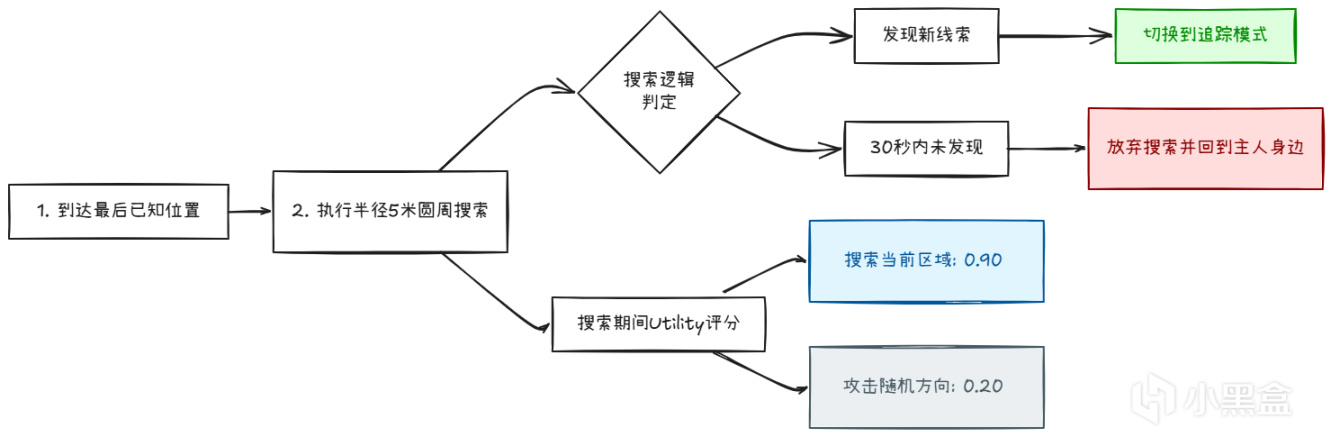
系统叠加:杀了狗,主人会愤怒
这里有一个更进阶的设计:当玩家杀了狗之后,狗的主人(一个人类敌人)会愤怒。
注:以下数值为示意性,实际参数因具体实现而异。
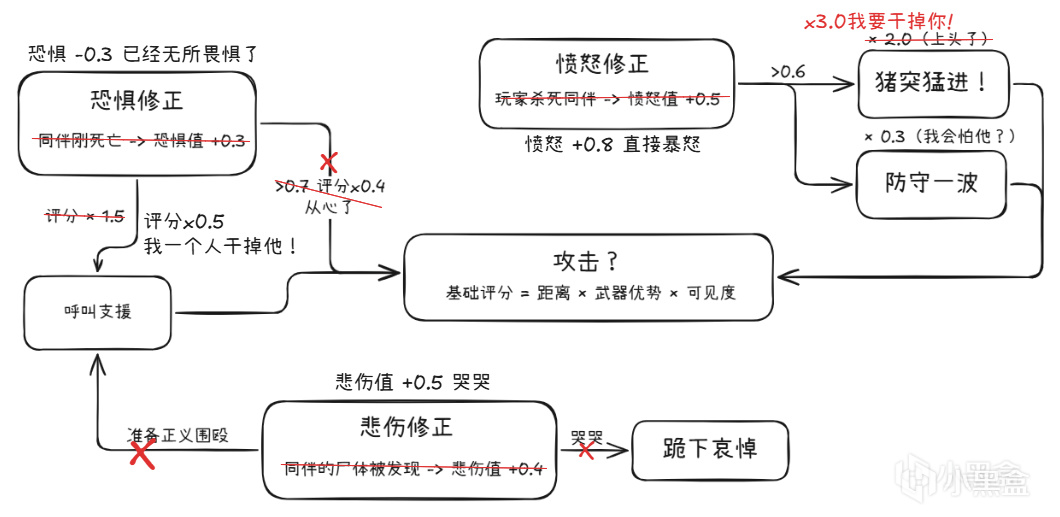
Utility考量因素不限于距离/血量,还有感情和记忆。
当你杀了狗,你在Utility AI的计算中,不再只是一个敌对目标。 你是一个杀了狗的仇人。这个标签带来了完全不同的评分矩阵。
TLoU2的狗不只是一个探测器,它和游戏角色之间有情感连接。你杀了它,它的主人会恨你。这种恨没法用if-else写出来,它是评分系统的结果。
6.3 Utility作为设计方法
回顾这一章的三个案例,可以注意到一点:
Utility AI不仅是一种算法,更是一种设计思路。
这三个案例都关注AI如何回应游戏里发生的事,而不是只决定"下一步做什么"。
传统Utility AI:距离 × 血量 × 武器 = 是否攻击
系统级Utility AI:(距离 × 血量 × 武器) + 情感记忆 × 社会关系 = 是否攻击 + 怎么攻击 + 攻击后的影响
当Utility AI从决策函数变成系统核心,它的作用就从算法扩展到了设计层面,是一种让游戏世界的反应更丰富的方法。
除了评分本身,还要考虑评分是怎么算出来的。
"不同场景适合不同的做法,关键是选对方法。"
第七章:混合架构的时代
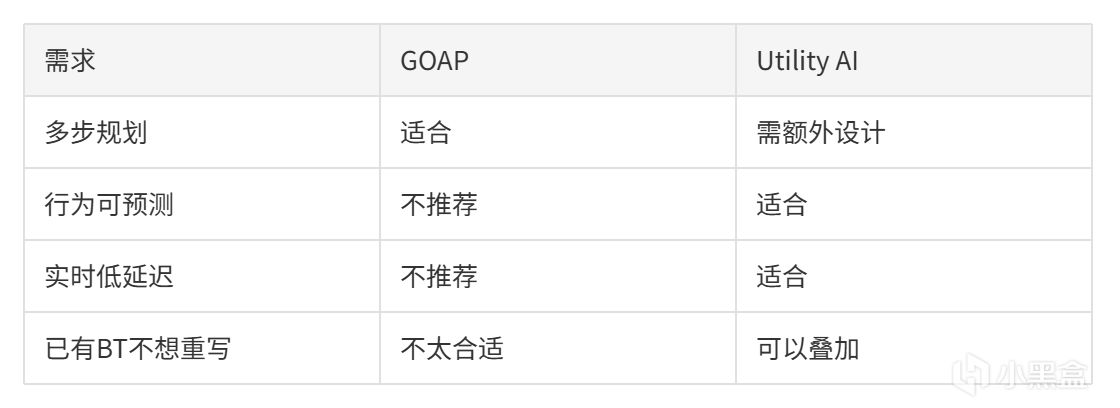
前面介绍了的几种架构,各有各的短板。在实际开发中通常组合使用。
7.1 Utility + BT:最常见的分工
Utility AI决定"做什么",BT负责"怎么做"。

7.2 BT + Utility Condition
保留原有BT,把布尔判断换成Utility评分:
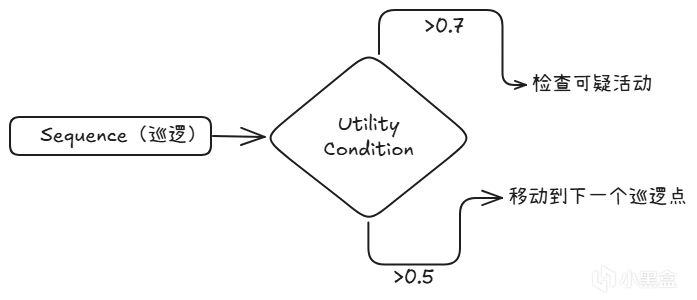
B. Merrill在《Game AI Pro》第10章详细介绍了这种方法。
7.3 HTN + Utility
HTN生成多个候选行动规划,Utility评分选出最优方案执行。
HTN让AI能规划多步,Utility让它能权衡策略。
7.4 GOBT:决策和执行一体化
BT节点的条件由Utility AI实时计算,决策和执行绑在一起。

概念定义见 Hong et al., JMIS 2023。
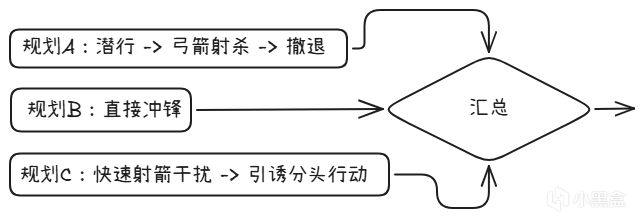
7.5 GOAP:规划+评分
F.E.A.R.用的GOAP只有两个状态:Goto(移动到正确位置)+ Animate(做正确的事)。核心是Planner通过组合动作的precondition和effect自动生成战术。
Planner不需要开发者写死"闪光弹+侧翼包抄",它通过precondition/effect匹配自己算出来了。
GOAP和Utility的思路相近(多选项权衡),但机制不同:
目标选择 → Utility的核心
路径搜索(A*) → 规划器的核心
第八章:DDA的现在与未来
DDA进化历程
RL驱动的DDA
传统DDA的规则是人写的条件判断,RL让AI自己学什么时候升难度、什么时候降难度。
状态空间:命中率、死亡次数、通关时间
动作空间:难度调节量(-5 ~ +5)
奖励函数:心流状态+1,连续死亡5次-5,10分钟无压力-3
2024年一篇MOBA游戏的RL-DDA论文显示玩家留存有所提升。但问题是黑盒:难度在变,但原因不透明。QA发现异常行为时无法追溯。
未来方向
个性化DDA:根据玩家历史自动学习"理想挑战曲线"。爱好《猫版马里奥》给高挑战,偏爱休闲游戏的则放宽限制。
情感感知DDA:通过摄像头或生物传感器检测情绪,不只是看操作数据。检测到焦虑就降难度,检测到无聊就升难度。
协同DDA:多人游戏中在集体和个人体验间找平衡。PVE按队伍平均调整,PVP用伪匹配微调参数。使命召唤的SBMM系统曾引发争议——如果玩家发现被系统暗中调低伤害,信任就崩塌了。
趋势:从调数值到调信息流
RE4:调数值(敌人血量)
L4D:调参数(刷怪频率)
Far Cry:调事件(巡逻路线)
Alien: Isolation:调信息流(线索分布)
HD2:调系统(Bucket水位)
注:HD2的Bucket系统来自社区反向工程,开发商未官方确认。
DDA的发展方向是间接调节,让玩家察觉不到难度变化。
第九章:技术总结与实用指北
架构对比:从状态机到Utility AI
整个游戏AI系列走过了三条路径
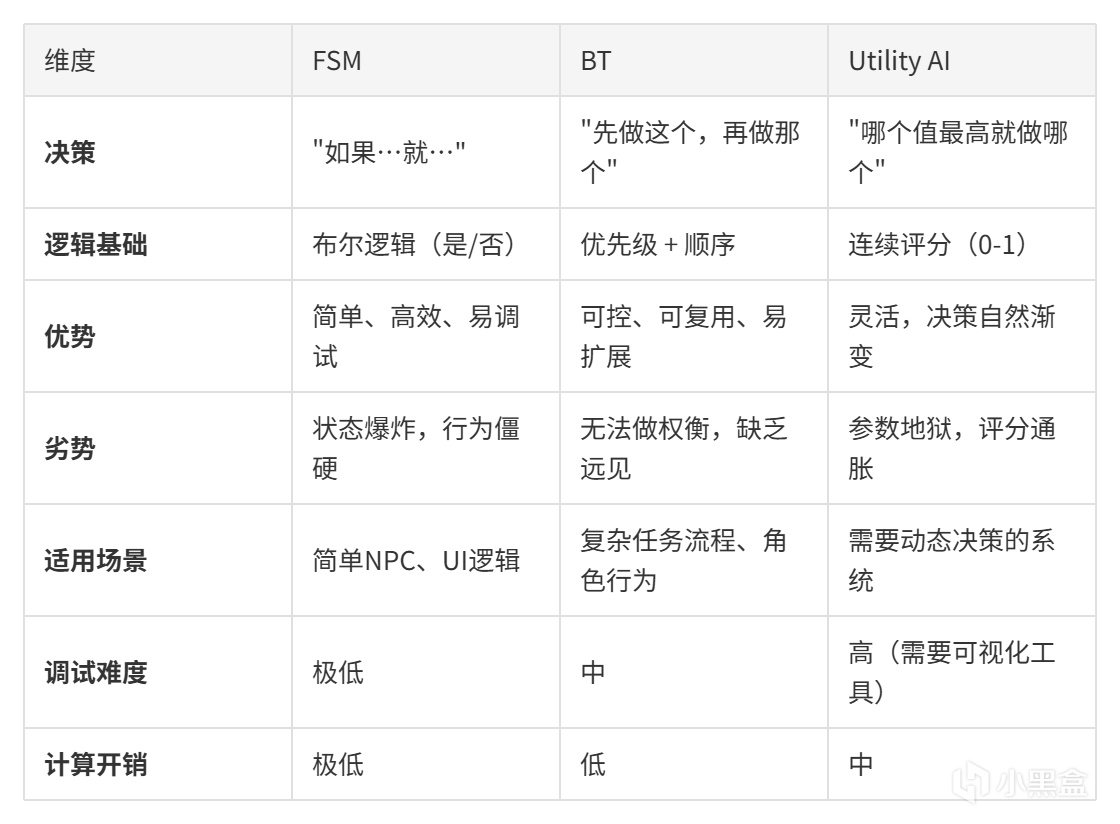
全景对比:六种AI架构一表通
系列中提到的不止三大「主角」,这里把所有架构放在一起看:
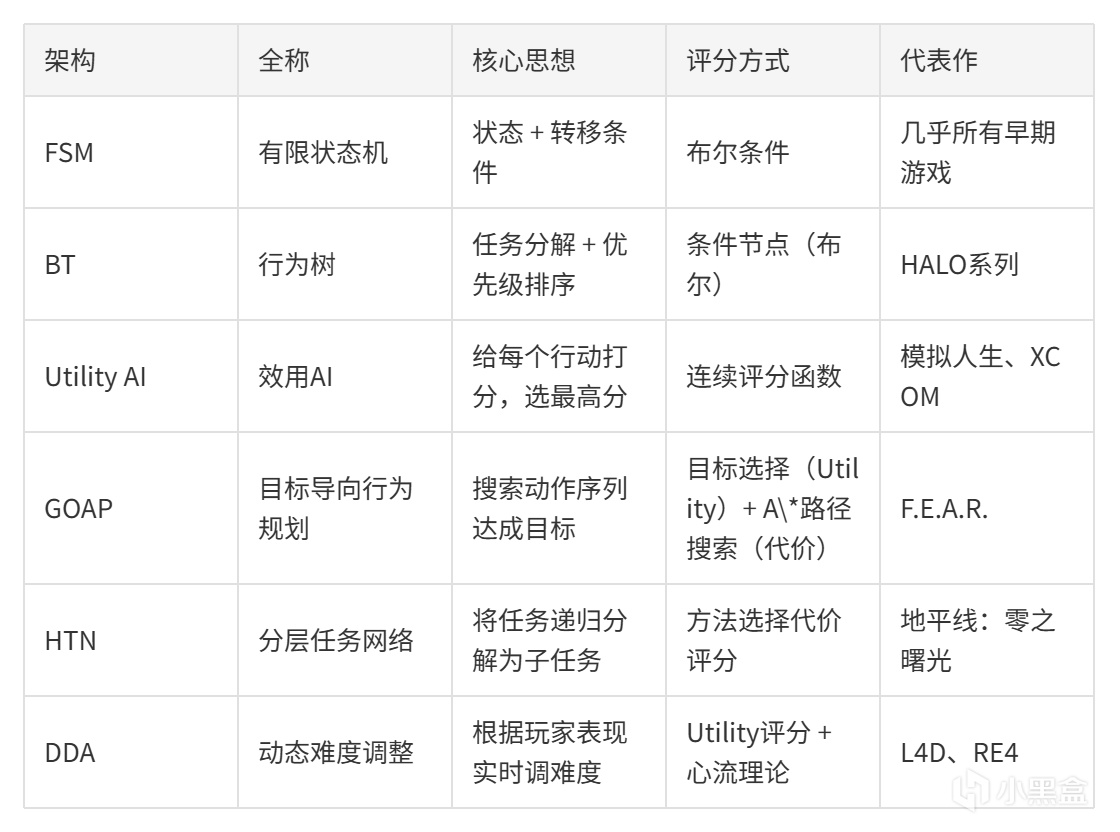
这些架构是互补关系。实际项目中通常混合使用:Utility AI做决策,BT做执行,HTN做规划。
下一个游戏该怎么选
1. 从FSM起步,预留升级接口
小项目(比如一个平台的敌人AI)用FSM即可。尽量不要开始就上Utility AI,那是不必要的复杂度。设计时把状态和条件解耦,未来升级到BT时会省很多事。
2. 需要任务流程时用BT
角色要执行一系列有先后顺序的动作(巡逻→搜索→攻击→撤退)时,BT的树状结构天然适合「先做这个,再做那个」。 推荐叠加Utility Condition(见第七章),让BT节点从布尔判断升级为评分筛选。
3. 需要做权衡时用Utility AI
AI需要在「攻击哪个目标」「撤退还是继续」之间做动态选择?用Utility AI。 注意避开三大坑(第三章):评分通胀用S形曲线解决,参数地狱用分组隔离,最优≠有趣用随机噪声加多样性奖励。
4. 需要规划多步时用GOAP或HTN
AI不只选下一步,而要规划一串动作(如「扔闪光弹→翻越掩体→侧翼包抄」)。 GOAP适用于战术场景,HTN适用于长程规划。开放世界要注意计算开销。
5. DDA最后再加
动态难度调整是锦上添花,不是地基。先确保游戏本身的AI够好,再考虑DDA。最简单的DDA用if-else就能实现(「如果玩家连续死亡3次,降敌人血量」),最复杂的(如L4D的Director)需要完整的Utility AI系统支撑。
下期预告:机器学习入侵游戏AI
经典游戏AI的内容到这里告一段落。游戏AI还有更多方向。
下一期将进入一个不同的领域:
强化学习如何让AI「自学」玩游戏(AlphaGo、OpenAI Five)
行为克隆:让AI学会模仿玩家,而不是被if-else编程
ML-DDA:用强化学习替代人工设计的难度曲线
当游戏AI遇上大语言模型:NPC不再是木头,而是活生生的角色
参考文献
Mark, D. (2009). Behavioral Mathematics for Game AI. Course Technology PTR.
Booth, M. (2009). "The AI Systems of Left 4 Dead." AIIDE-09 (AI and Interactive Digital Entertainment Conference). Valve.
Hunicke, R. (2004). "AI for Dynamic Difficulty Adjustment in Games." AAAI Workshop on Challenges in Game AI.
Hanlon, S. & Watts, C. (BioWare). "Dragon Age: Inquisition's Utility Scoring Architecture." In Game AI Pro 3: Collected Wisdom of Game AI Professionals, Chapter 31. CRC Press.
Berteling, J. (2018). "Beyond Killzone: Creating New AI Systems for Horizon Zero Dawn." Game Developers Conference 2018. Guerrilla Games.
Merrill, B. (2013). "Building Utility Decisions into Your Existing Behavior Tree." In Game AI Pro: Collected Wisdom of Game AI Professionals, Chapter 10. CRC Press.
Csikszentmihalyi, M. (1990). Flow: The Psychology of Optimal Experience. Harper & Row.
Faliszek, C. (2023). Interview on Left 4 Dead's Director and Development History. Game Developer (15th anniversary feature).
Capcom. (2005). Resident Evil 4 Hidden Rank System. (Confirmed via data mining, ~2020; see e.g., "Resident Evil 4's Hidden Difficulty System" analysis videos and community wiki documentation).
Clover Studio. (2006). God Hand Difficulty Level (DL) System. (See community documentation and "Dynamic game difficulty balancing" on *********).
Noonchester, A. [Adam]. (2019). "'Marvel's Spider-Man' AI Postmortem." Game Developers Conference 2019. Insomniac Games.
Hope, A. & Napper, G. (Creative Assembly). (2015). "Building Fear in Alien: Isolation." Game Developers Conference 2015.
Hoge, C. (2018). "Helping Players Hate (or Love) Their Nemesis." Game Developers Conference 2018. Monolith Productions.
Naughty Dog. (2020). "Melee AI in The Last of Us Part II." GDC Vault.
Cheng, A. (2013). XCOM: Enemy Unknown AI session. AI Postmortems: Assassin's Creed III, XCOM: Enemy Unknown, and Warframe (joint panel). Game Developers Conference 2013. Firaxis Games.
Orkin, J. (2006). "Three States and a Plan: The AI of F.E.A.R." Game Developers Conference 2006. Monolith Productions.
Helldivers 2 Patrol System. (Community analysis, 2024). Various player analyses and data mining efforts.
Zubek, R. (2010). "Needs-Based AI." In Game Programming Gems 8, Chapter 9. Course Technology PTR.
本文是游戏AI科普系列的第三篇。前两篇见【状态机篇】和 【行为树篇】。第四篇——"机器学习入侵"——敬请期待。
本文纯属技术科普,所有游戏案例均来自公开资料、GDC演讲和学术论文。如有疏漏,欢迎指正。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com












