MiniMax 3 今天發佈了,我們來快速過一下。

M3 對自己的定位很明確:
前沿 Coding 能力、1M 上下文、原生多模態,三項合一。
MiniMax 表示這是國內第一個齊備這三個要素的模型,同時也是目前唯一開源的,海外前沿閉源模型已經普遍具備這三項能力,國產模型中同時湊齊的此前確實沒有。
架構方面,M3 最大的變化在注意力機制。
去年 M2 還在使用全注意力機制,MiniMax 當時發過博客解釋,認爲稀疏注意力尚未達到生產就緒狀態。六個月後 M3 採用了自研的 MSA(MiniMax Sparse Attention)。
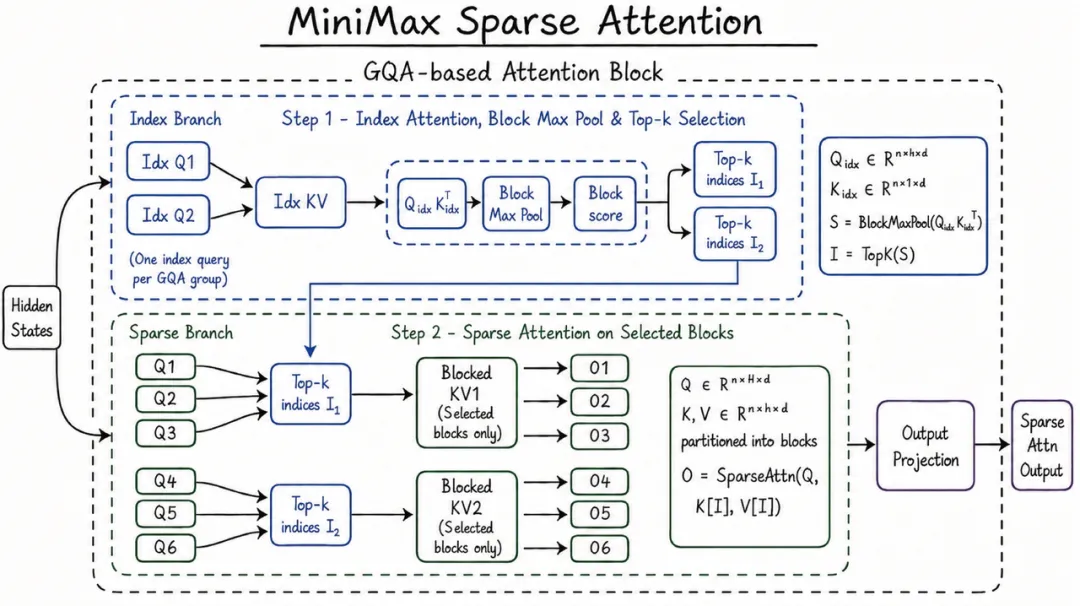
核心設計是雙分支結構,索引分支快速掃描定位關鍵信息,稀疏分支對篩選出的 Token 做精準計算。與 DeepSeek 的 NSA 相比,MSA 只保留了選擇分支,砍掉了壓縮和滑動窗口分支,好處是可以直接複用 FlashAttention 核函數,工程實現成本較低。
100 萬 Token 上下文下,每個 Token 計算量僅爲上代模型的 1/20。預填充階段加速超 9 倍,解碼階段加速超 15 倍。對照實驗中 MSA 的能力與全注意力基本持平。
Coding 和 Agent 是 M3 重點提升的方向。
SWE-Bench Pro 得分 59.0%,超過 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7。Terminal Bench 2.1 得分 66.0%。SVG-Bench 上超過 Opus 4.7,Claw-Eval 拿到最高分,在跑分上,編程和 Agent 任務方面 M3 已進入第一梯隊。
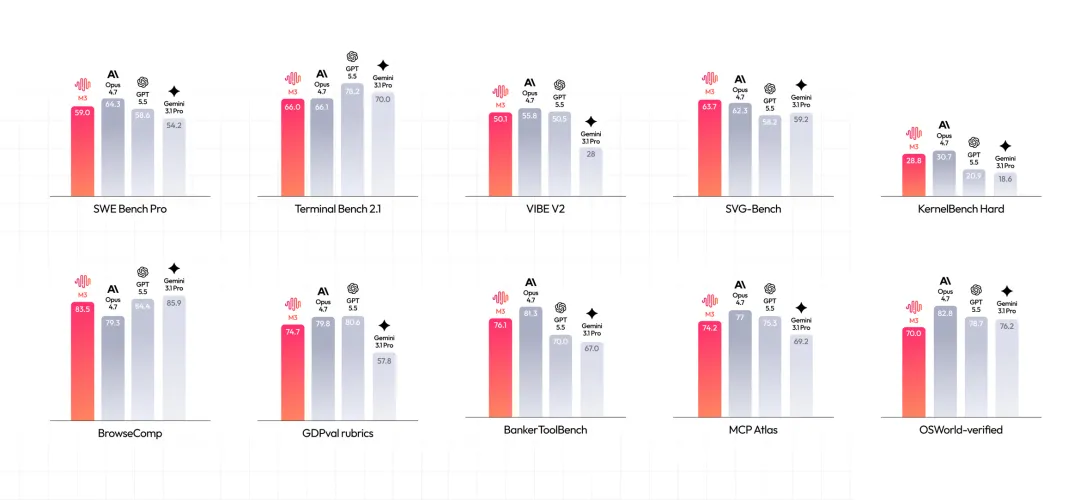
MiniMax 用幾個實際任務做了能力展示。
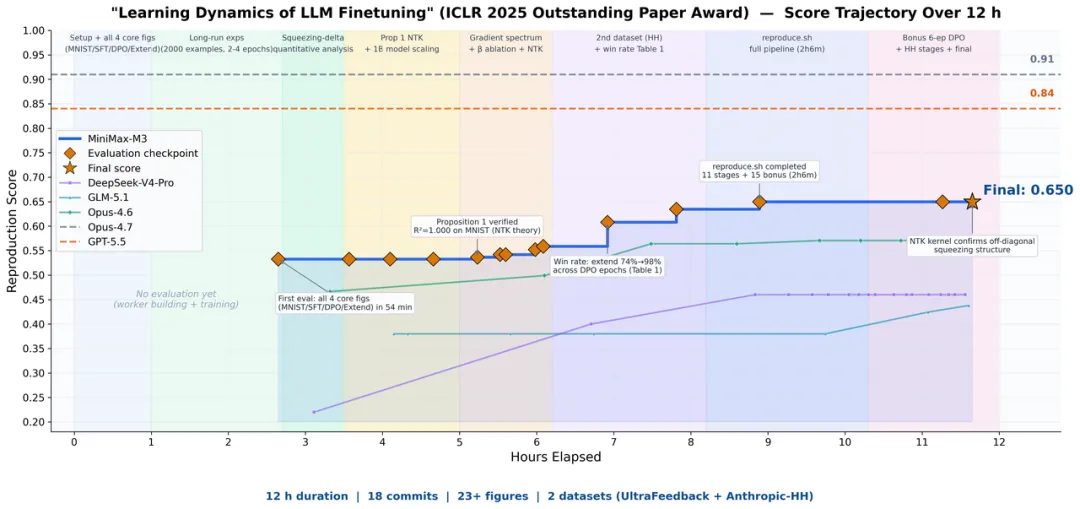
論文獨立復現方面,給 M3 一篇 ICLR 2025 獲獎論文,要求自主復現核心實驗,M3 運行了近 12 小時,產出 18 次 commit 和 23 張圖表,跑通了核心實驗。這個過程對綜合能力要求較高,需要多模態來理解論文圖表,需要長上下文把論文加代碼加日誌一次塞入窗口,還需要編程和 Agent 能力做長線程執行。
在 CUDA 算子優化方面,讓 M3 從零寫一個 Hopper 架構上的 FP8 矩陣乘法 kernel,只提供了任務描述和一份無法運行的骨架代碼。M3 運行了約 24 小時,147 次提交,1959 次工具調用,將硬件峯值利用率從 7.6% 提升到 71.3%,實現了 9.4 倍加速。MiniMax 表示除 Opus 4.7 和 M3 以外,其餘模型大多在前 30 次提交內就停止推進。
多模態方面,M3 從 Step 0 開始進行多模態混合訓練,支持圖片和視頻輸入,還能操作電腦桌面。MiniMax 提到 Interleaved data,即文本和圖像在序列中交替排列的混合數據,對模型性能提升的影響比預期更顯著,重構數據管線後訓練數據規模達到 100 萬億 Token 量級。
接下來 10 天內 MiniMax 將更新技術報告並開源模型權重,感興趣的朋友可以關注一下。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















