前言:賽博cos緣起
hello大家好呀,有不少盒友關注薯薯肯定是因爲【百變果果】系列呢:

原圖在主頁【百變果果】系列
所謂賽博cos,就是把自己的全身照餵給AI,讓它幫忙給我們換裝,從而實現低成本cos,讓我們風格百變。
其實薯薯一開始也只是抱着試試的心態來弄,畢竟平時上班,還要更新經濟金融的帖子,實在沒什麼精力真的去弄cos,更新頻率低不說,cos服也都好貴,買了很多cos服又不能穿一次就丟掉,還很佔地方。
但最後沒想到大家這麼喜歡這個系列,不知不覺都已經cos了二十多個角色,而且想必大家也能發現,經歷這些時間的摸索,薯薯調教AI的能力也日漸提升:

左邊兩張是最早期的,右邊兩張是近期的
所以薯薯打算出一期攻略,來教教大家如何低成本出cos,讓大家都能輕鬆獲得屬於自己的百變女友,或者讓自己的女友風格百變。
以下是薯薯自己摸索出來的經驗,可能不是最優解,大家如果有更好的方法歡迎友好討論分享~
前期準備(一):豆包+gpt pro
在嘗試用gpt pro之前,我只用豆包來着,是真正意義上的零成本(當然豆包以後也要收費了),後來在盒友的提醒下,開了gpt pro,於是大家也能發現最近幾期cos圖的質量更上一層樓。

爲什麼是豆包+gpt pro的組合?
豆包的優點:基礎產圖能力比較均衡,也基本能聽懂人話(但不多),自帶一定美顏效果,且可以一次性產10張圖(這點非常關鍵,能節約大量時間,單個豆包單日生成圖片次數上限爲60次,60*10=600張圖,絕對可以滿足日常需求了);
豆包的缺點:衣服和頭髮的質感略有欠缺,對於微細節的調整能力較差(可能是底層算法精細度不夠,對於一些衣服和髮型細節調整的需求理解不了),而且如果把一張豆包生成的圖,再次餵給豆包進行微調,衣服和頭髮的質感就會不受控制的變化,AI味就會更濃,所以堅持一直用豆包,血壓會飆升。
此時需要gpt pro出場,其優點剛好能夠補足豆包的缺點:衣服和頭髮的質感會比豆包更好一些,而且對於一些細節的處理更到位,也更能聽懂人話。把豆包產出來的不完美初圖再餵給gpt,也不會出現像豆包一樣更失真的情況。
但gpt的缺點在於,我總感覺它美顏能力一般,如果直接用gpt產初圖,總是很醜;另外gpt確實只能一次產一張圖,如果讓它產多張圖,它會擅自給你拼到一起,像素就會變低,所以gpt的產圖效率不如豆包,更適合微調。
所以綜合二者優劣,我們的工作流程是:先用豆包調教出初圖,然後再餵給gpt精修,這樣可以結合二者長處,讓我們的效率最大化。
後面我們會舉例來教大家怎麼用這套工作流程。
前期準備(二):一張女生(或者xnn)全身照
這個事情怎麼講呢,首先要麼大家自己是女生,或者自己是xnn,或者有一個願意配合的女朋友(不可以隨便從網上拿圖就喂ai噢,這樣不好)。
關於這張照片也有幾個tips需要注意,首先女主角一定要穿衣服(不然喂ai可能不通過),最好穿比較凸顯身材的衣服(內衣,小背心短褲,或者包臀裙應該都可以)。
另外如果要cos胸比自己大的角色,一定要記得在原圖中就給自己墊起來,不然的話,讓豆包幫忙把你的胸調大,容易變得非常不自然(因爲它總是要把你的胸給露出來,而不是蓋在衣服裏面,而且看起來很假),gpt更不用說了,合規更嚴格。
再有,最好在原圖裏直接穿上絲襪,穿褲襪、大腿襪、吊帶襪都行。結合我這段時間的經驗,AI脫絲襪的本事比穿絲襪強,而且生成腳趾的能力也比預期要強,特別是gpt,感覺它似乎不怎麼會給光腿光腳的女生穿絲襪,這方面反而是豆包還強一些。
如果你本來就穿了黑絲,再讓它幫忙調教成灰絲、白絲會更容易一些,質感也更真實一些。
具體案例:以結城明日奈cos爲例
假設我們想cos亞絲娜的這張常服壁紙,也是薯薯最喜歡的一套亞絲娜日常穿搭:

下圖左側是豆包生成的初圖,右側是二次餵給gpt精修後的成圖:

大家可以明顯看到,豆包的圖和原版相比,已經還原出了基本框架,但細節明顯不足,包括對麻花辮的處理很有問題,而gpt修過的圖則更還原出了原圖的精髓:包括麻花辮在後腦紮上的低位髮髻,以及長髮飄逸吹散的細節,還有輕微歪頭的動作。
接下來是具體步驟:
我們餵給豆包的提示詞框架一般長這樣:
給圖中女生換上如下穿搭和髮型,生成10張:
髮型細節:
……
衣服細節:
……
姿勢細節:
……
那麼現在問題是,提示詞到底怎麼寫?我們不可能自己寫,那樣太累了,我們可以用一個非常取巧的辦法,就是把我們想cos的原圖餵給豆包,讓它替我們描述:
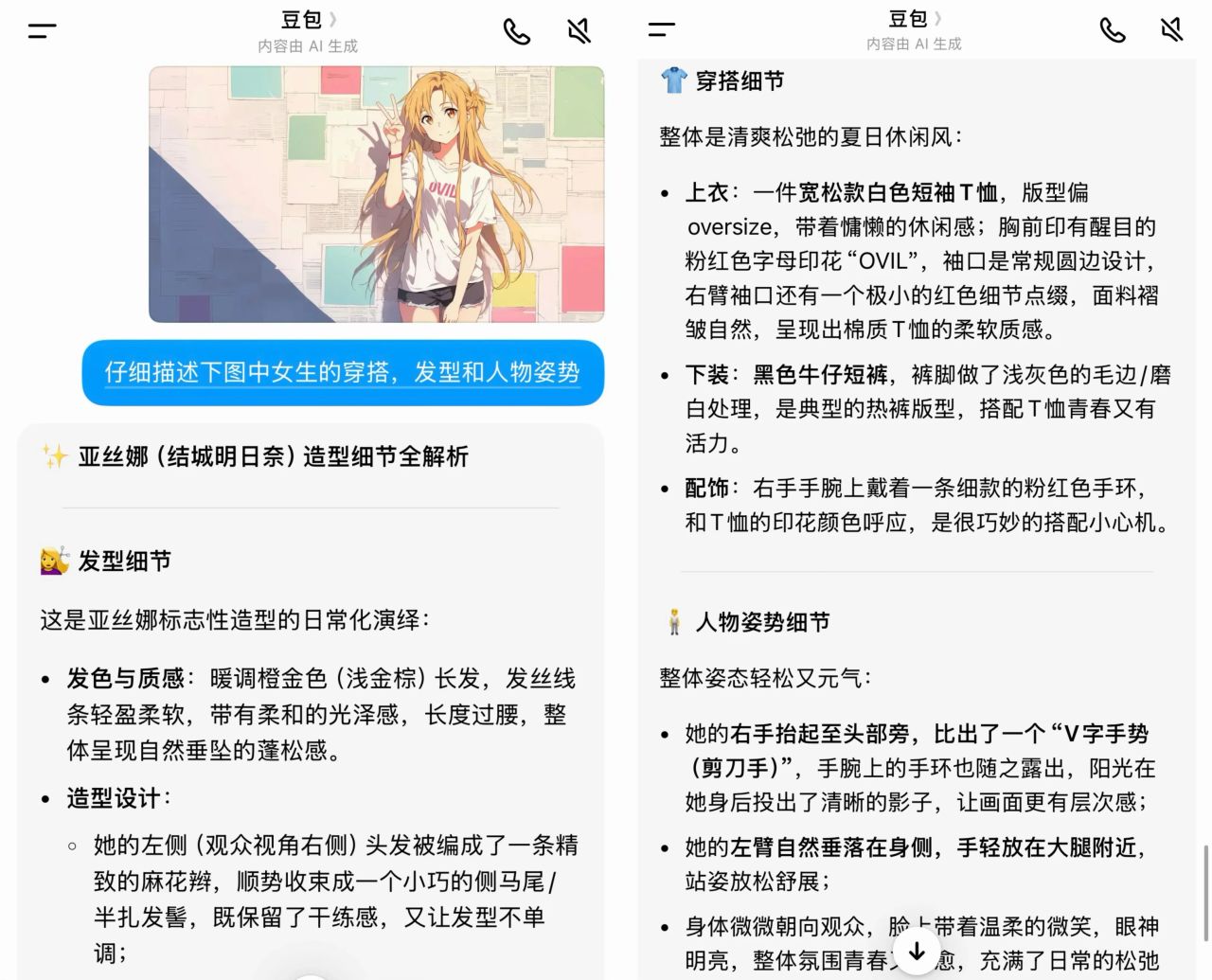
這樣我們就獲得了提示詞了,可以直接粘到我們的提示詞框架裏,附上我們的原照片,然後讓豆包生成換裝:
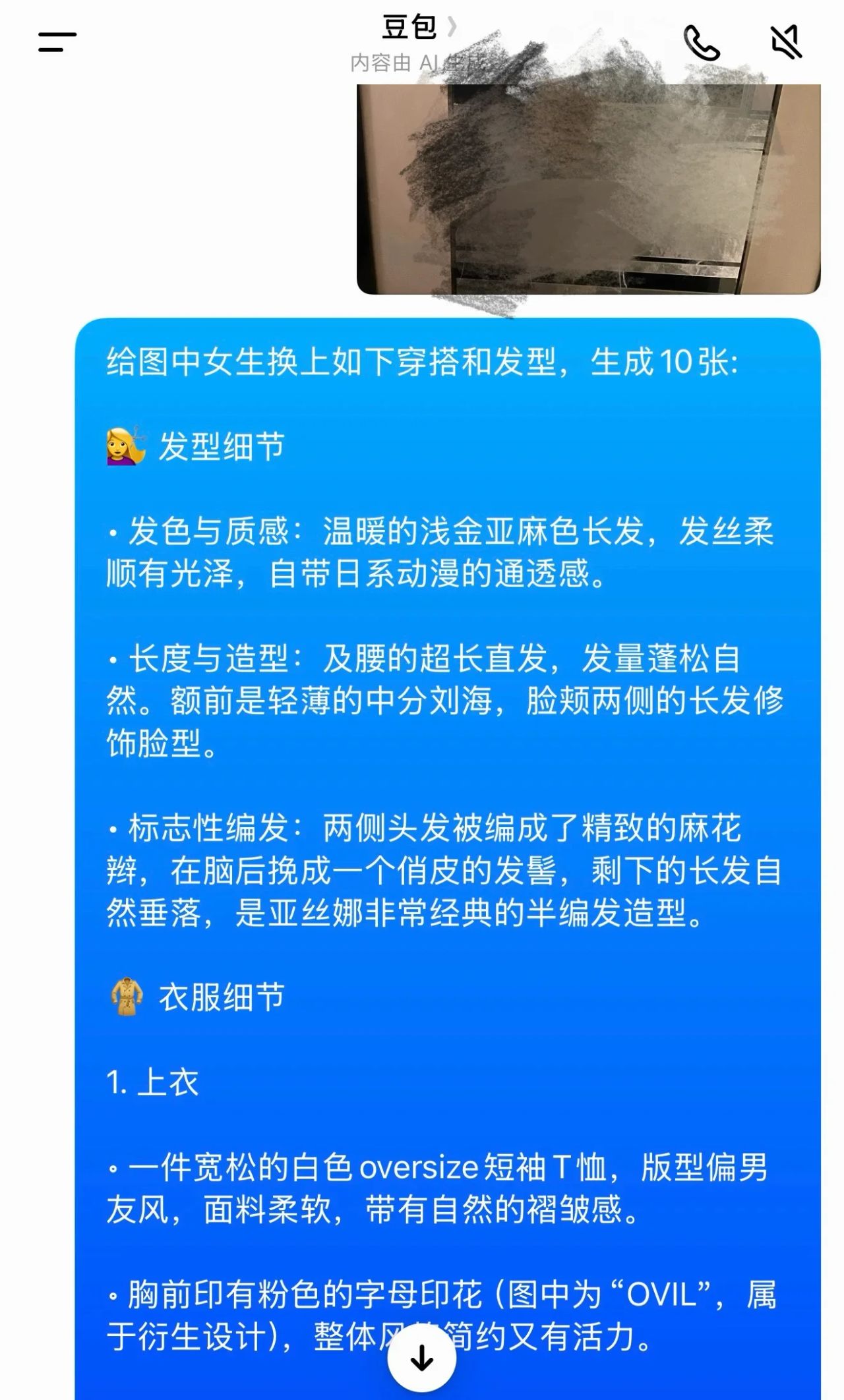
第一次生成後,我們先大致看看效果,有沒有偏差很明顯的地方,如果有的話,看看哪裏不對,再返回去微調下提示詞,如此往復,直到選出幾張我們覺得還ok的初圖,比如我當時選的這張:

這張的問題是,亞總的頭型是,兩縷細麻花辮在後腦較低的位置紮成一個小發髻,但我們發現豆包明顯處理不了這個細節,雖然在側後方還原出了髮髻,但麻花辮還是垂在了胸前,同時對於及腰髮絲的飄逸感也很難拿捏。
這就是我們前面提到的豆包的劣勢,能還原出大致框架,但細節上的偏差導致無法出圖。所以接下來我們需要再餵給gpt,讓它幫我們對細節進行精修。
我也可以用一個取巧的方法,就是直接讓gpt來複刻原圖細節,也省去我們打字的功夫了:
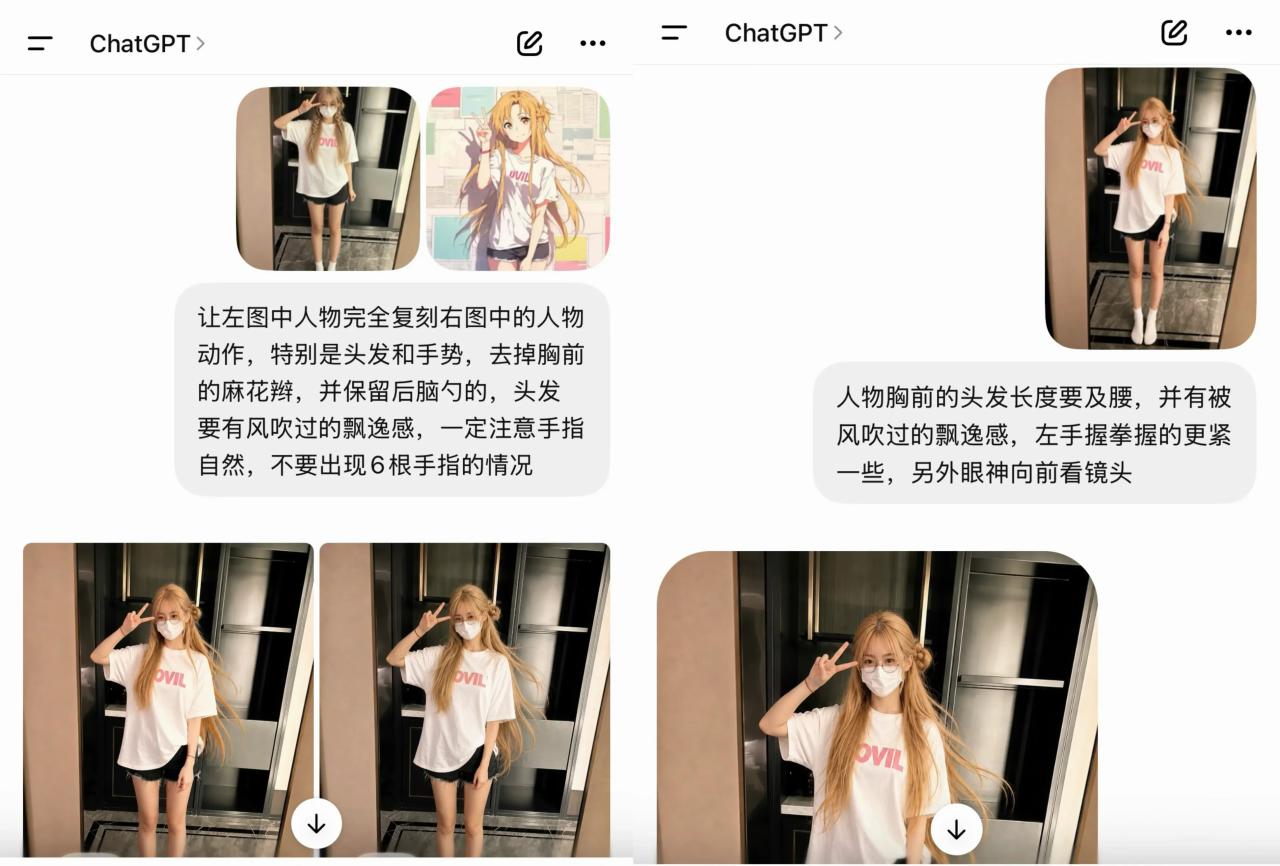
但是呢,豆包也會出現無法生成的情況:

這種情況一般是,我們對各種細節的描述太多了,超出了豆包單次的算力上限,或者有一些它無法理解的詞語(比如我每次寫絲襪的D數,100D之類的,它就必卡殼),所以我們需要對提示詞做些刪改,然後再繼續生成。
同時gpt也有類似的情況,主要是合規問題,比如一旦出現“裙子更短一點”這種描述,就會被拒絕:

總之,微調之後,就得到我們最後的成品圖了。怎麼樣,是不是算很還原了:

最後還有一個小tips,就是光影的調整,在格蕾絲那一期初次嘗試,效果也還不錯:

這個大家可以直接去問gpt,怎麼調節光影好,薯薯用的是這段話:
低照度高對比光影,頂部暖光打出明顯明暗層次,整體偏電影感和高級暗調氛圍。
那麼以上就是本期攻略的全部內容啦,最後附上薯薯主頁歡迎關注:
https://api.xiaoheihe.cn/v3/bbs/app/api/web/share?h_camp=link&h_src=YXBwX3NoYXJl&link_id=766e7191c1f5
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















