你寫的代碼,無論是Python、Java還是C++,本質上都是一份普通的文本文件,電腦CPU根本看不懂代碼。
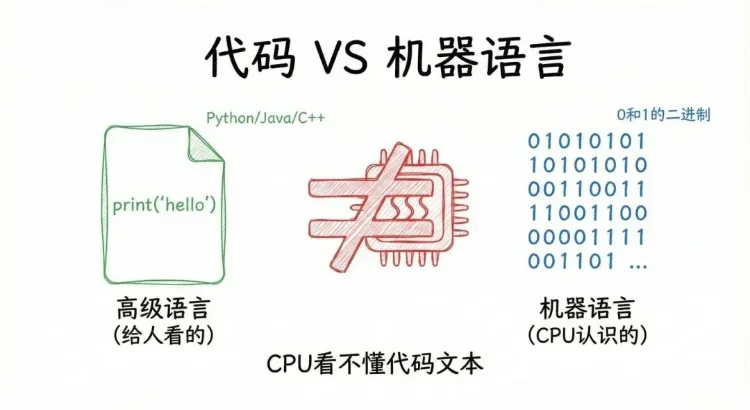
我們寫的代碼是“高級語言”,比如print(“hello”),本質是給人看的、符合人類邏輯的指令;但CPU只認一種“語言”——機器語言,也就是由0和1組成的二進制代碼。
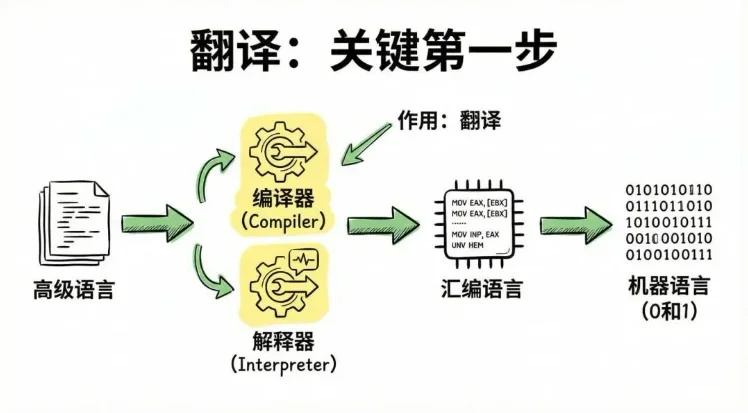
所以代碼能跑起來,第一步就是把高級語言翻譯成機器語言,這是最關鍵的一步。這個“翻譯”工作,靠兩種核心工具,編譯器和解釋器,對應不同的編程語言。編譯器或者 解釋器它們的作用只有一個:翻譯。 它們會把我們寫的高級語言,翻譯成 CPU 能看懂的**“彙編語言”,然後再進一步翻譯成0和1組成的二進制代碼。
本文只說編譯器,像C、C++這類語言會用到它。編譯到運行的工作主要分4步。
第一步:你寫完代碼後,編譯器做的第一件事,不是立刻翻譯,而是先進行預編譯,預編譯階段幹三件核心的事情。
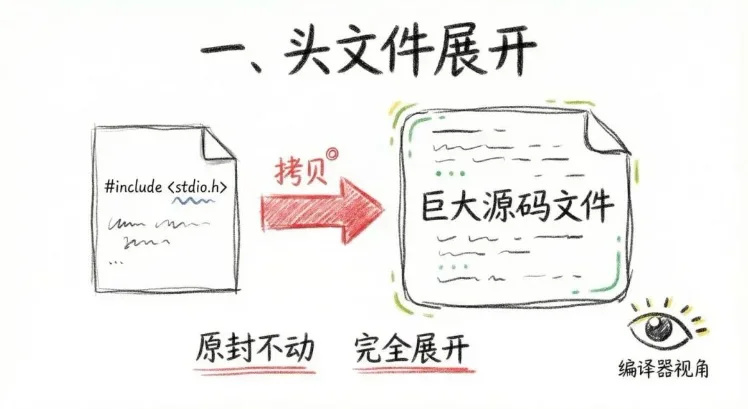
一、頭文件展開。當你寫 #include 的時候,預編譯器並不是“記住你用了它”,而是直接把頭文件裏的內容,原封不動地拷貝進你的代碼裏。從編譯器的視角看,根本不存在什麼“頭文件”,它看到的,只是一份已經被完全展開的巨大源碼文件。
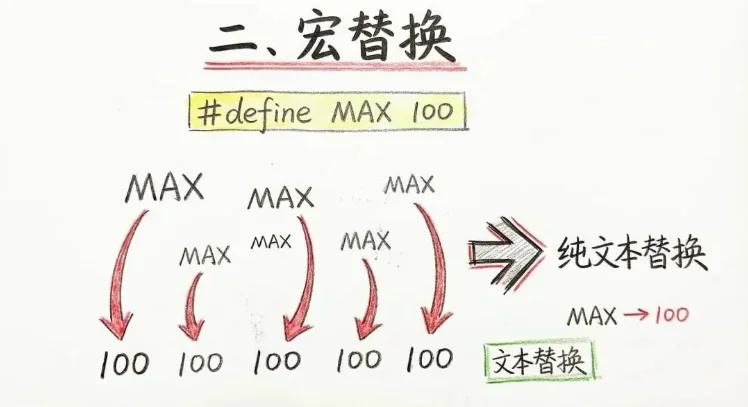
二,宏替換。#define 本質上就是純文本替換。比如你寫:#define MAX 100,預編譯之後,代碼裏所有的 MAX,都會被直接替換成 100。
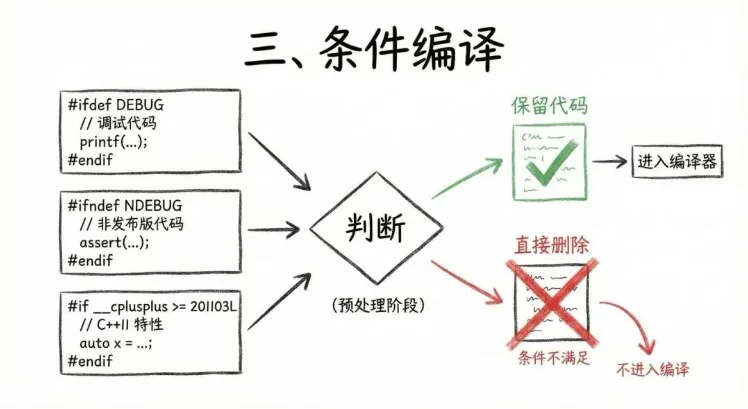
三,條件編譯。#ifdef、#ifndef、#if 這些語句,會在預編譯階段被直接判斷。條件不滿足的代碼,直接被刪除,根本不會進入後續的編譯流程。
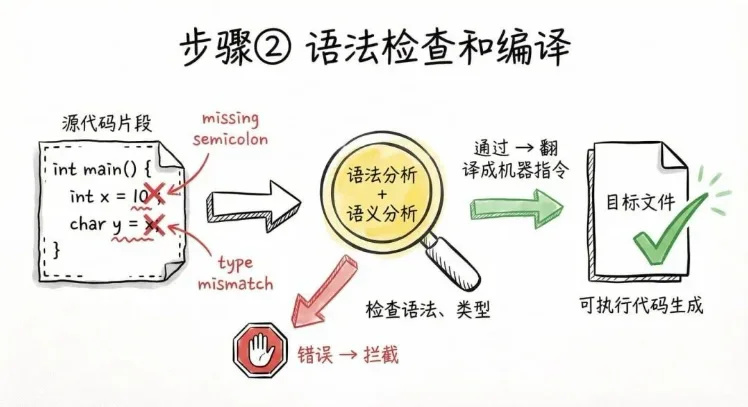
第二步,語法檢查和編譯。語法對不對?類型合不合理?有沒有明顯的錯誤?這一步我們叫:語法分析和語義分析。如果你少寫了分號、變量類型不匹配,編譯器就在這一步直接把你攔下來。檢查通過之後,編譯器纔會真正開始翻譯。這一步結束後,你得到的通常還不是最終程序,而是:目標文件。目標文件裏,已經是接近 CPU 能執行的機器指令了,但還差最後一步。
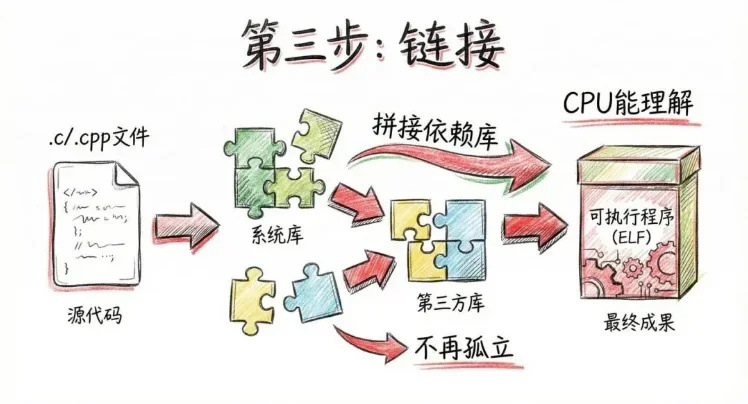
接着來到第三步,鏈接。鏈接這一步,很多人平時不太注意,但它非常關鍵。因爲你寫的程序,幾乎從來不是“孤立”的。你用到了用了系統庫、用了第三方庫。這些代碼並不在你寫的那個 .c 或 .cpp 文件裏。鏈接要做的事情就是:把你寫的代碼,和所有依賴的庫代碼,拼接到一起。鏈接完成之後,纔會生成一個真正意義上的:可執行程序。比如 Linux 下的 ELF 文件。到這裏,代碼已經不再是代碼了,而是一份 CPU 能理解、操作系統能加載的二進制程序。
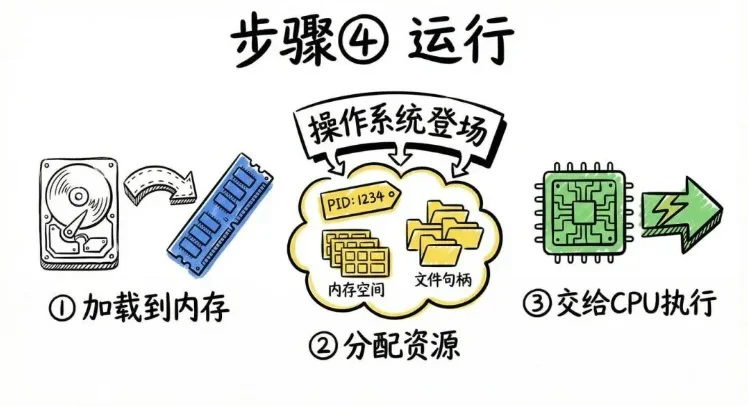
接下來是第四步,運行。當你在命令行裏敲下程序名,或者雙擊一個 exe 文件時,操作系統開始登場了。操作系統會做幾件事:一,把程序從磁盤加載到內存。因爲 CPU 只能從內存裏取指令執行,不能直接跑硬盤上的程序。二,給程序分配資源。比如進程 ID、內存空間、文件句柄、棧和堆。三,把 CPU 的執行權交給程序的入口地址。從這一刻開始,CPU 才真正開始一條一條執行你的指令。
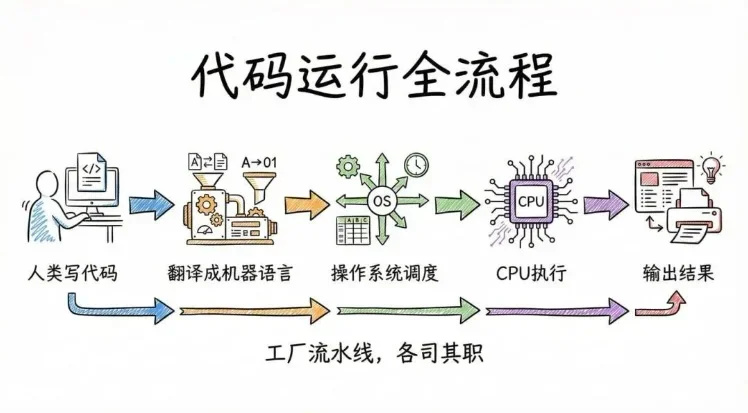
總結一下,代碼跑起來的核心就是:人類寫的高級語言代碼,通過編譯器/解釋器翻譯成CPU能懂的機器語言,再由操作系統調度資源,交給CPU執行,最終把結果輸出。整個過程就像一個工廠流水線,每個環節各司其職,才能讓幾行文本代碼變成電腦上運行的軟件。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














