你写的代码,无论是Python、Java还是C++,本质上都是一份普通的文本文件,电脑CPU根本看不懂代码。
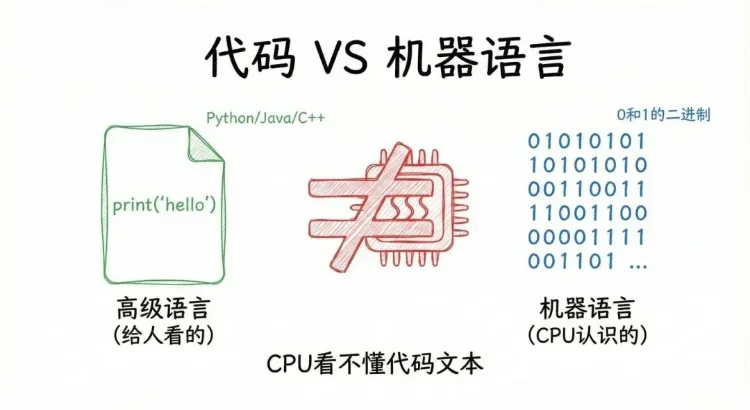
我们写的代码是“高级语言”,比如print(“hello”),本质是给人看的、符合人类逻辑的指令;但CPU只认一种“语言”——机器语言,也就是由0和1组成的二进制代码。
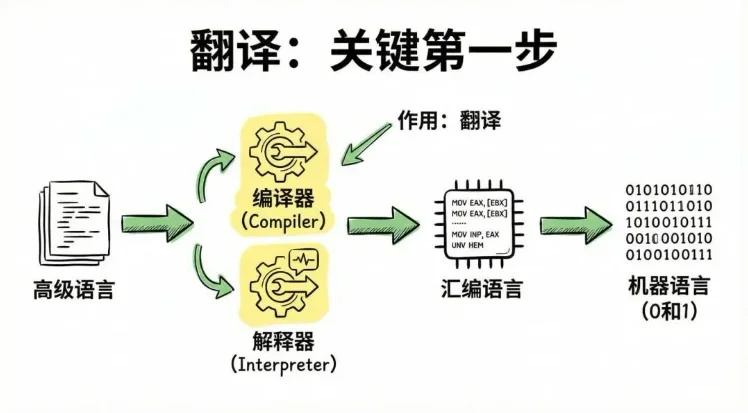
所以代码能跑起来,第一步就是把高级语言翻译成机器语言,这是最关键的一步。这个“翻译”工作,靠两种核心工具,编译器和解释器,对应不同的编程语言。编译器或者 解释器它们的作用只有一个:翻译。 它们会把我们写的高级语言,翻译成 CPU 能看懂的**“汇编语言”,然后再进一步翻译成0和1组成的二进制代码。
本文只说编译器,像C、C++这类语言会用到它。编译到运行的工作主要分4步。
第一步:你写完代码后,编译器做的第一件事,不是立刻翻译,而是先进行预编译,预编译阶段干三件核心的事情。
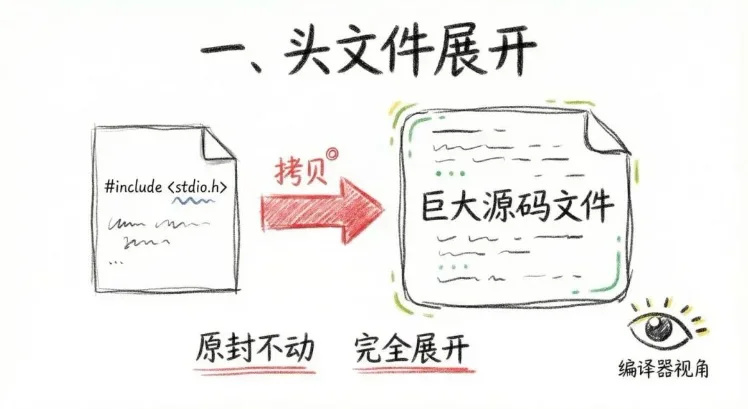
一、头文件展开。当你写 #include 的时候,预编译器并不是“记住你用了它”,而是直接把头文件里的内容,原封不动地拷贝进你的代码里。从编译器的视角看,根本不存在什么“头文件”,它看到的,只是一份已经被完全展开的巨大源码文件。
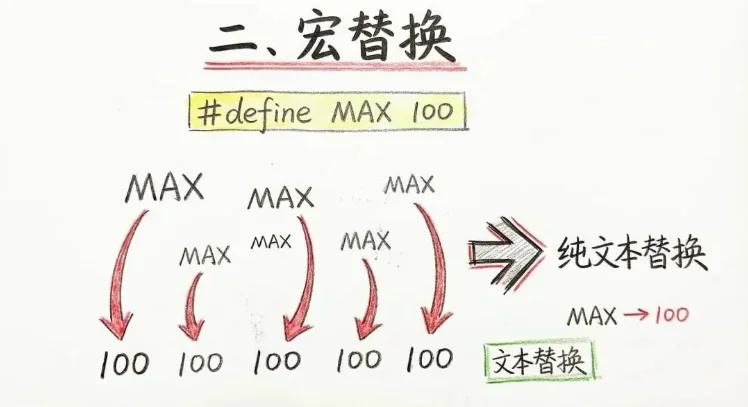
二,宏替换。#define 本质上就是纯文本替换。比如你写:#define MAX 100,预编译之后,代码里所有的 MAX,都会被直接替换成 100。
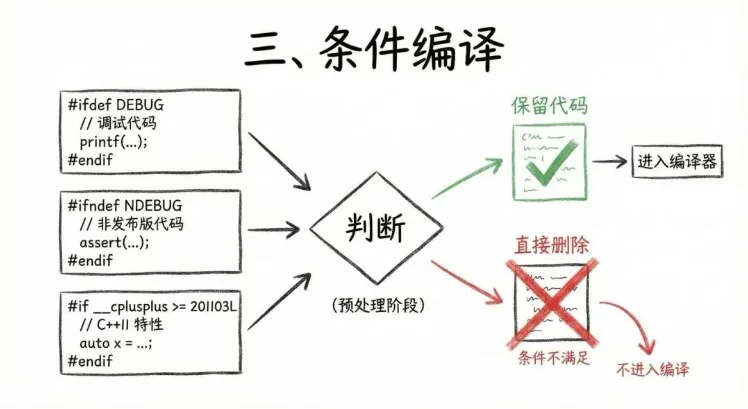
三,条件编译。#ifdef、#ifndef、#if 这些语句,会在预编译阶段被直接判断。条件不满足的代码,直接被删除,根本不会进入后续的编译流程。
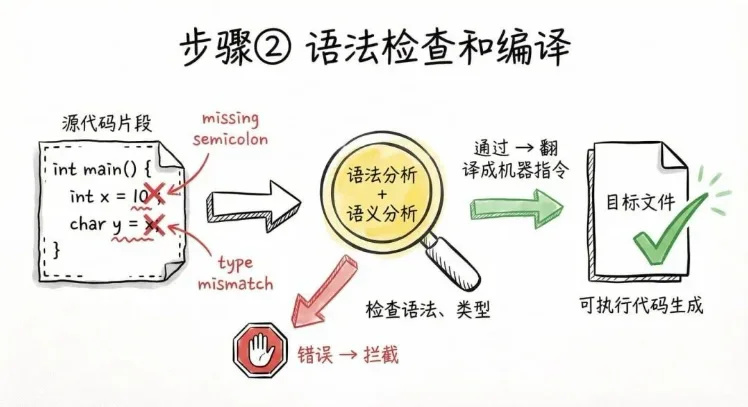
第二步,语法检查和编译。语法对不对?类型合不合理?有没有明显的错误?这一步我们叫:语法分析和语义分析。如果你少写了分号、变量类型不匹配,编译器就在这一步直接把你拦下来。检查通过之后,编译器才会真正开始翻译。这一步结束后,你得到的通常还不是最终程序,而是:目标文件。目标文件里,已经是接近 CPU 能执行的机器指令了,但还差最后一步。
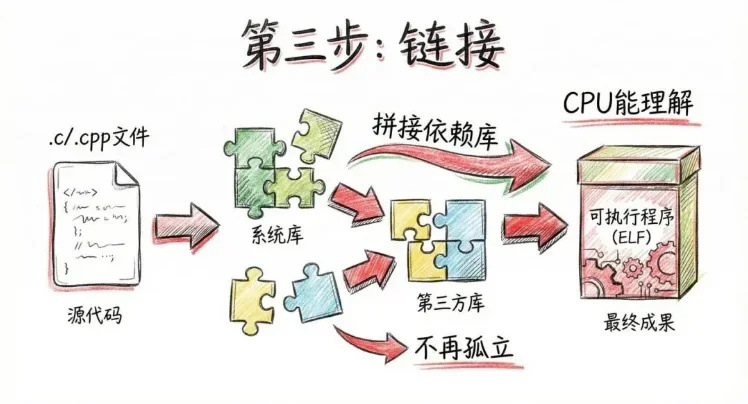
接着来到第三步,链接。链接这一步,很多人平时不太注意,但它非常关键。因为你写的程序,几乎从来不是“孤立”的。你用到了用了系统库、用了第三方库。这些代码并不在你写的那个 .c 或 .cpp 文件里。链接要做的事情就是:把你写的代码,和所有依赖的库代码,拼接到一起。链接完成之后,才会生成一个真正意义上的:可执行程序。比如 Linux 下的 ELF 文件。到这里,代码已经不再是代码了,而是一份 CPU 能理解、操作系统能加载的二进制程序。
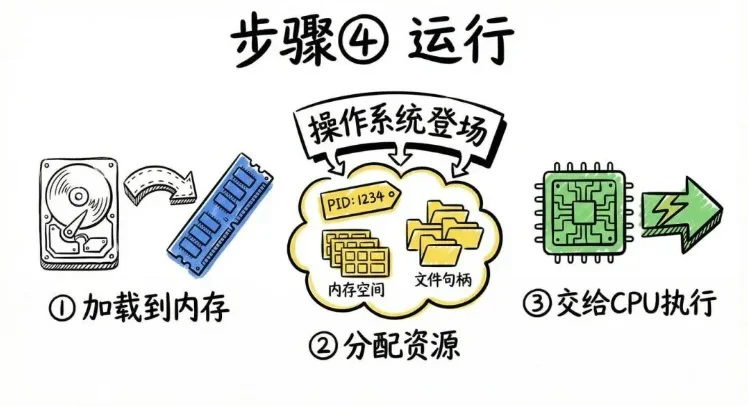
接下来是第四步,运行。当你在命令行里敲下程序名,或者双击一个 exe 文件时,操作系统开始登场了。操作系统会做几件事:一,把程序从磁盘加载到内存。因为 CPU 只能从内存里取指令执行,不能直接跑硬盘上的程序。二,给程序分配资源。比如进程 ID、内存空间、文件句柄、栈和堆。三,把 CPU 的执行权交给程序的入口地址。从这一刻开始,CPU 才真正开始一条一条执行你的指令。
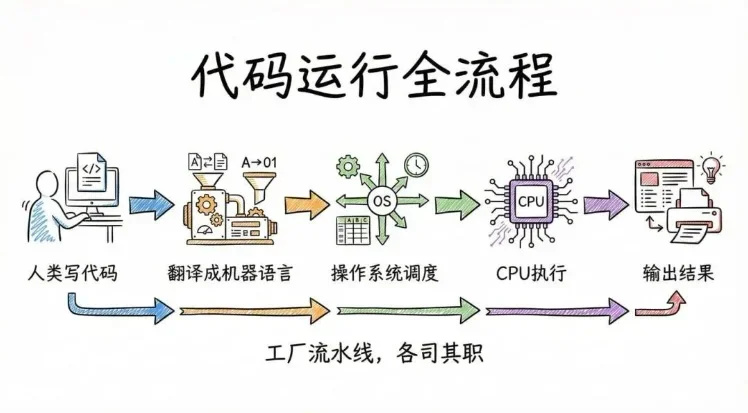
总结一下,代码跑起来的核心就是:人类写的高级语言代码,通过编译器/解释器翻译成CPU能懂的机器语言,再由操作系统调度资源,交给CPU执行,最终把结果输出。整个过程就像一个工厂流水线,每个环节各司其职,才能让几行文本代码变成电脑上运行的软件。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














