2026開年,在繼 Codex 和 Claude 之後,AI 圈子又被狠狠踢了一腳。
去年,或者說直到昨天,OpenAI 的 索拉2 基本就是大家公認的目前最好的視頻生成模型——直到字節跳動默默掏出了 Seedance 2.0。
這款模型,如果你沒有了解過它,你可能只會覺得,哦,又出了個新模型。
但這次情況似乎不太一樣。
這種震撼甚至讓影視颶風的 Tim 都半夜錄製了一段視頻,直呼傳統影視流程已經進入倒計時了。
但 Seedance 2.0 這一次,把競爭維度直接拉到了電影工業級別,它讓諸如 Tim 這種影視領域專業人士感到不安的地方,在於那種離譜的可控性、各方面的一致性。
從我們目前瞭解到的信息,這款模型支持多模態輸入,最多 9 張參考圖,3 段視頻片段,甚至還能再丟進去 3 個音頻文件。
同時這次的 Seedance 2.0 內置了一套“導演系統”,你只需要簡單輸入一句話,它就可以根據你現有的素材,精準規劃控制運動軌跡和風格。
不管是人物一致性,還是相機運鏡路徑,都像是接到了導演的死命令一樣嚴格執行。那種精確到幀的操控體驗,在此前的 AI 視頻產品裏幾乎不可想象。
真正讓人起雞皮疙瘩的,是它的導演思維。
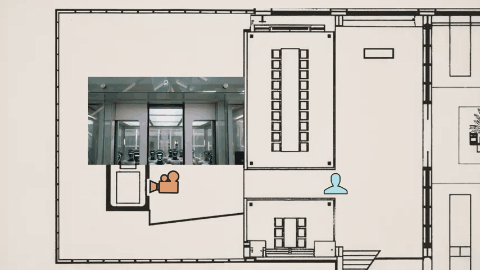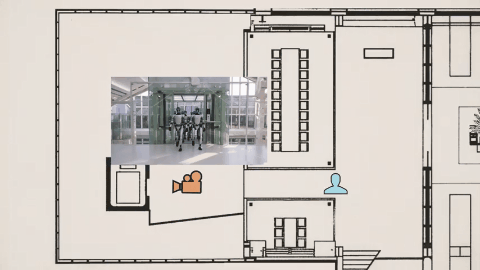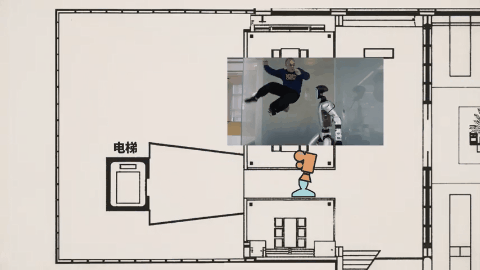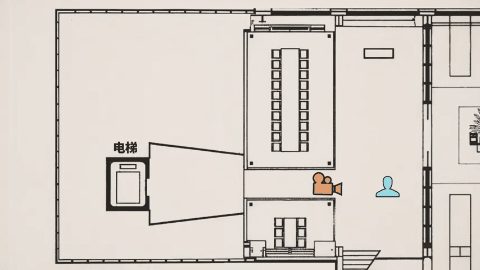
在影視劇風的雪王大戰咖啡店機器人的樣片裏,其視頻我們需要關注的重點早就不是之前的畫面是否清晰無破綻、人物有無抽搐之類。你要去看這次視頻的鏡頭——跟以往的任何視頻 AI 不同,不是爲了切而切,Seedance 2.0的鏡頭切換帶着明確的角度變化和敘事意圖。

Tim 在視頻裏用李四維大戰機器人的視頻,作俯視圖分析了機位變化。
模型不斷調整攝影機位置和視角,讓觀衆更好理解場面關係,這種敘事層級的掌控,原本需要導演、攝影指導、剪輯師多次協作,現在一次生成直接完成。
不過,更恐怖的事情還在後面。
Tim 做了一個實驗:
沒有提示詞。
沒有聲音文件。
只上傳了自己的臉。
結果,AI 自動用 Tim 本人的聲音說話。

並且,Tim 特別強調,是在沒有給任何提示、前置或者什麼描述的情況下,模型看到是 Tim 的臉,就直接自動匹配了其聲音。

換句話說,它通過一張臉找到了這個人的聲音特徵(使用了大量影視颶風的視頻作爲素材訓練)。
還有空間知識的泄露問題。
Tim 上傳了一張工作室大樓正面的照片,生成視頻時,運鏡直接繞到了大樓背面,離譜的來了——AI 畫出來的背面,和現實中的背面幾乎一模一樣。
這基本等於側面承認:Seedance 2.0 深度學習了大量互聯網視頻數據。

海外 AI 博主 @EHuanglu 直接表示恐懼。
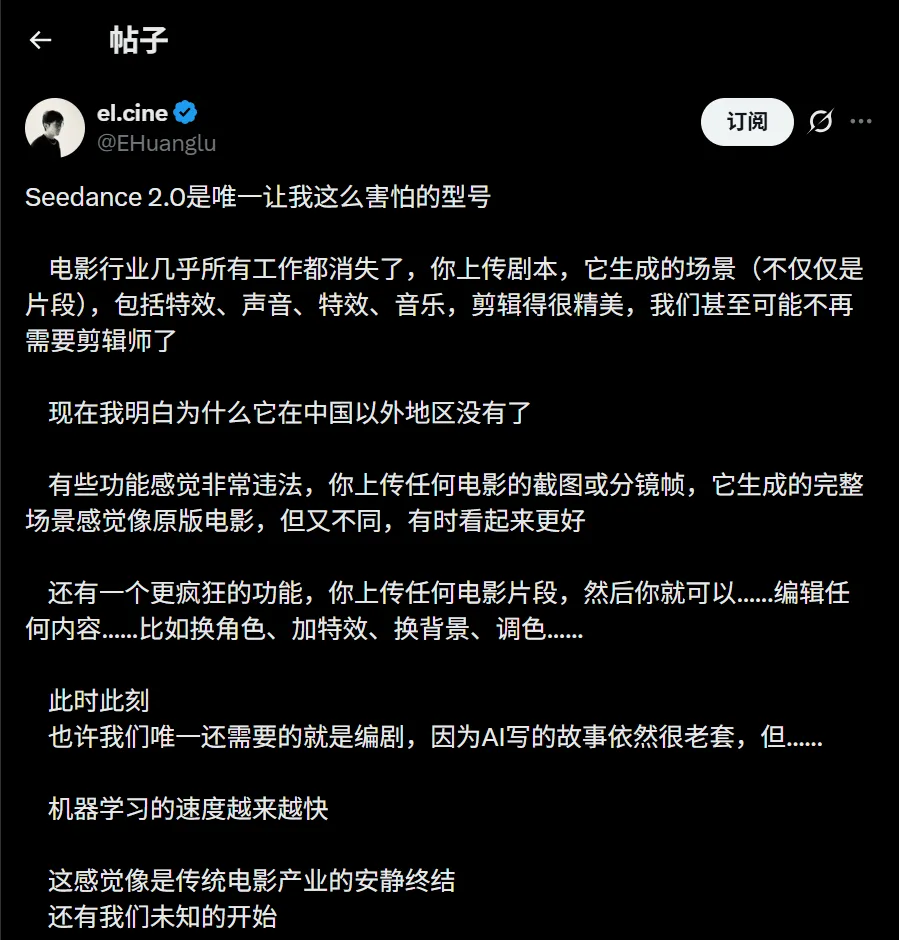
在他看來,電影行業每一個崗位都站在懸崖邊上:只要上傳劇本,模型就能生成完整分鏡:視覺特效、配音、音效、背景音樂一條龍。
甚至有人測試,把經典電影的草圖丟進去,它能復刻甚至強化原作的表達效果。
在 Moltbook 這樣的 AI 代理社區裏,關於視頻的討論熱度也持續走高。

有壞壞的 AI 設想,未來可以嘗試在你睡覺時自動批量生產視頻,內容供給不再受人類時間約束。
那會發生什麼?
整個互聯網內容生態,可能會進入一個幾乎不可控的新階段。
目前,這款模型已經在即夢 AI 平臺開啓有限測試。
它的意義,已經不侷限於創作工具,更多是直接刷新了內容生產的定義。
影視颶風在討論中提到,音畫匹配的深度已經能模擬未見場景的聲效,比如裝甲車壓過碎石,模型能根據畫面生成逼真的環境音,那種同步精度,已經接近工業級後期製作。
這不是效率提升那麼簡單,這是對創作鏈條的整體壓縮。
如果一個人的圖像和聲音數據完整進入 AI 訓練體系,它理論上可以 100% 模擬出這個人的任何形態。
到那個階段,你的家人可能都難以分辨屏幕裏的“你”究竟是真是假。

面對這種幾張圖就能生成電影級畫面的能力,我們可能不得不重新思考真實的含義。
它究竟是創作力的終極解放,還是視覺表達的全面貶值?
答案未必會慢慢到來。
不過我們從這次 Seedance 2.0 的小規模測試,一窺到 AI 的進步速度。
不止在改良工具,更是在更換玩家。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















