2026开年,在继 Codex 和 Claude 之后,AI 圈子又被狠狠踢了一脚。
去年,或者说直到昨天,OpenAI 的 索拉2 基本就是大家公认的目前最好的视频生成模型——直到字节跳动默默掏出了 Seedance 2.0。
这款模型,如果你没有了解过它,你可能只会觉得,哦,又出了个新模型。
但这次情况似乎不太一样。
这种震撼甚至让影视飓风的 Tim 都半夜录制了一段视频,直呼传统影视流程已经进入倒计时了。
但 Seedance 2.0 这一次,把竞争维度直接拉到了电影工业级别,它让诸如 Tim 这种影视领域专业人士感到不安的地方,在于那种离谱的可控性、各方面的一致性。
从我们目前了解到的信息,这款模型支持多模态输入,最多 9 张参考图,3 段视频片段,甚至还能再丢进去 3 个音频文件。
同时这次的 Seedance 2.0 内置了一套“导演系统”,你只需要简单输入一句话,它就可以根据你现有的素材,精准规划控制运动轨迹和风格。
不管是人物一致性,还是相机运镜路径,都像是接到了导演的死命令一样严格执行。那种精确到帧的操控体验,在此前的 AI 视频产品里几乎不可想象。
真正让人起鸡皮疙瘩的,是它的导演思维。
在影视剧风的雪王大战咖啡店机器人的样片里,其视频我们需要关注的重点早就不是之前的画面是否清晰无破绽、人物有无抽搐之类。你要去看这次视频的镜头——跟以往的任何视频 AI 不同,不是为了切而切,Seedance 2.0的镜头切换带着明确的角度变化和叙事意图。

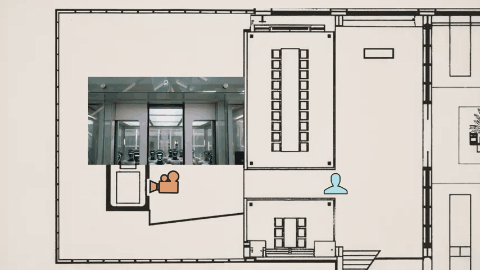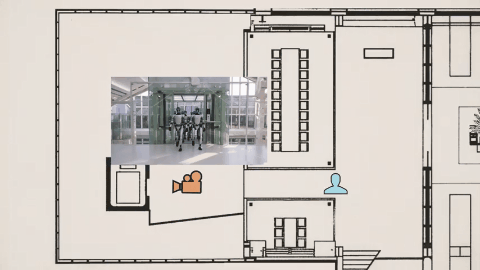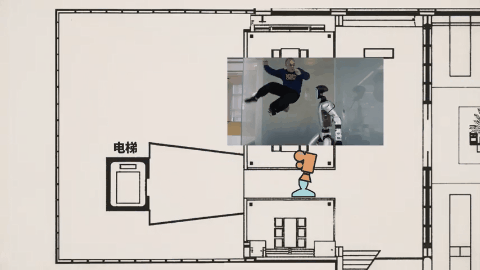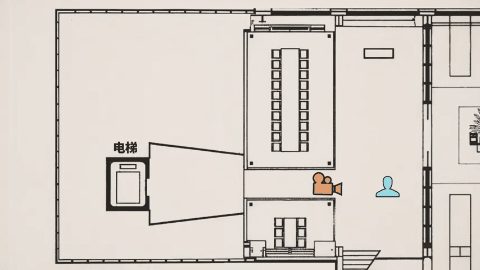
Tim 在视频里用李四维大战机器人的视频,作俯视图分析了机位变化。
模型不断调整摄影机位置和视角,让观众更好理解场面关系,这种叙事层级的掌控,原本需要导演、摄影指导、剪辑师多次协作,现在一次生成直接完成。
不过,更恐怖的事情还在后面。
Tim 做了一个实验:
没有提示词。
没有声音文件。
只上传了自己的脸。
结果,AI 自动用 Tim 本人的声音说话。

并且,Tim 特别强调,是在没有给任何提示、前置或者什么描述的情况下,模型看到是 Tim 的脸,就直接自动匹配了其声音。

换句话说,它通过一张脸找到了这个人的声音特征(使用了大量影视飓风的视频作为素材训练)。
还有空间知识的泄露问题。
Tim 上传了一张工作室大楼正面的照片,生成视频时,运镜直接绕到了大楼背面,离谱的来了——AI 画出来的背面,和现实中的背面几乎一模一样。
这基本等于侧面承认:Seedance 2.0 深度学习了大量互联网视频数据。

海外 AI 博主 @EHuanglu 直接表示恐惧。
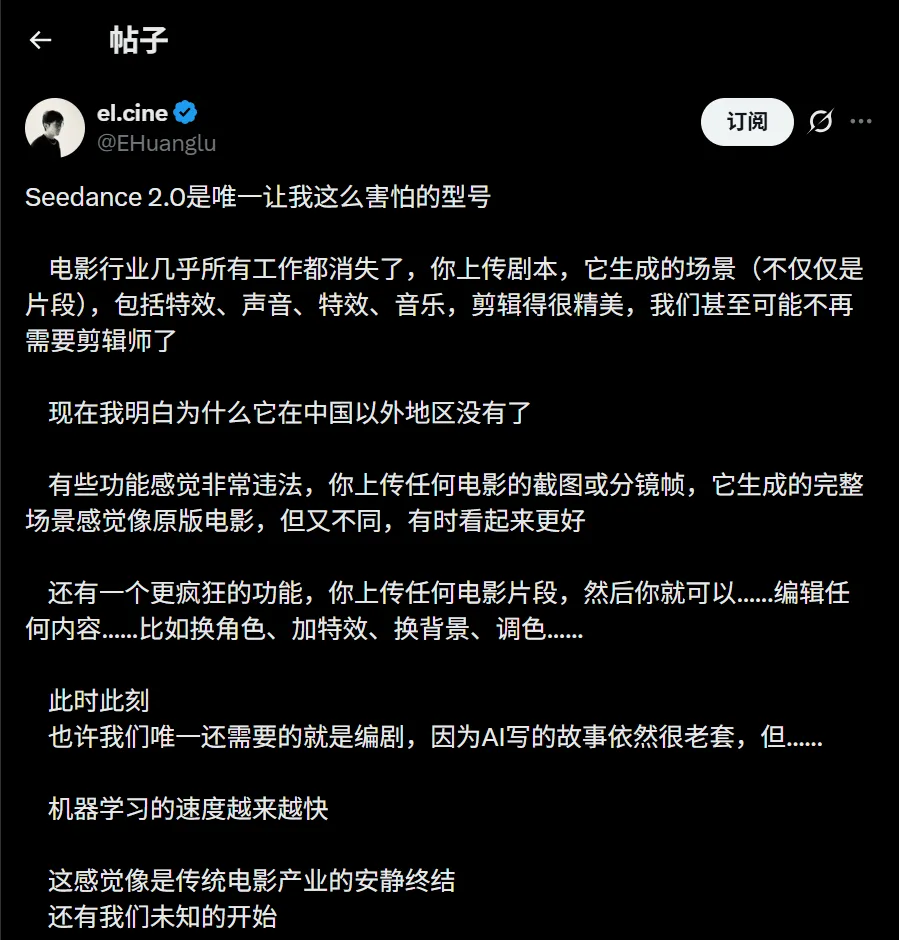
在他看来,电影行业每一个岗位都站在悬崖边上:只要上传剧本,模型就能生成完整分镜:视觉特效、配音、音效、背景音乐一条龙。
甚至有人测试,把经典电影的草图丢进去,它能复刻甚至强化原作的表达效果。
在 Moltbook 这样的 AI 代理社区里,关于视频的讨论热度也持续走高。

有坏坏的 AI 设想,未来可以尝试在你睡觉时自动批量生产视频,内容供给不再受人类时间约束。
那会发生什么?
整个互联网内容生态,可能会进入一个几乎不可控的新阶段。
目前,这款模型已经在即梦 AI 平台开启有限测试。
它的意义,已经不局限于创作工具,更多是直接刷新了内容生产的定义。
影视飓风在讨论中提到,音画匹配的深度已经能模拟未见场景的声效,比如装甲车压过碎石,模型能根据画面生成逼真的环境音,那种同步精度,已经接近工业级后期制作。
这不是效率提升那么简单,这是对创作链条的整体压缩。
如果一个人的图像和声音数据完整进入 AI 训练体系,它理论上可以 100% 模拟出这个人的任何形态。
到那个阶段,你的家人可能都难以分辨屏幕里的“你”究竟是真是假。

面对这种几张图就能生成电影级画面的能力,我们可能不得不重新思考真实的含义。
它究竟是创作力的终极解放,还是视觉表达的全面贬值?
答案未必会慢慢到来。
不过我们从这次 Seedance 2.0 的小规模测试,一窥到 AI 的进步速度。
不止在改良工具,更是在更换玩家。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















