前言
大家中午好呀,我是浣能🦝,歡迎來到我們機器學習之旅的Day 13!
上次,我們用 Pandas 手寫了“女活男死”的規則,拿到了 76.5% 的準確率。這就像是手工作坊,雖然能用,但遇到複雜情況(比如“有錢的男性”或“窮苦的老人”)就無能爲力了。
我們將引入機器學習霸主 scikit-learn 。從今天起,無論多麼複雜的模型(邏輯迴歸、決策樹、神經網絡),在 sklearn 裏都將簡化爲同一個“萬能公式”。
同時,我們的百寶箱理論知識內容依然在繼續,講完本次線性迴歸的基礎知識,下次課就該介紹邏輯迴歸的內容了。同時,本次例子使用了部分邏輯迴歸函數,相當於提前預告了一下了。
第一部分:百寶箱——線性迴歸(下)
當直線不夠用(欠擬合)或特徵打架(共線性)時怎麼辦?以及模型到底是怎麼算出來的。
1. 進階一:多項式迴歸
問題: 假如數據本身是一條拋物線(比如身高和體重的關係),用直線去擬合就是欠擬合。
解決: “升維”。雖然還是線性迴歸,但我們把x變成 x^2 甚至 x^n。
警惕過擬合: 如果你用的次冪太高(比如15次冪),模型會把所有噪點都連起來,雖然訓練誤差爲0,但預測新數據會完蛋,甚至還會引發“維度災難”!
2. 進階二:多重共線性
現象: 當你的特徵之間高度相關(比如“左腳鞋碼”和“右腳鞋碼”同時作爲特徵預測身高)。
後果: 模型會懵圈,參數估計變得極不穩定。
診斷工具: VIF (方差膨脹因子)。一般來說,如果 VIF > 4,就認爲存在多重共線性,需要處理(比如刪掉其中一個特徵)。
3. 進階三:模型選擇 (AIC 與 BIC)
當你有好幾個模型(比如一個用了3個特徵,一個用了5個特徵),怎麼選?
AIC (赤池信息準則): 越小越好。它在尋找擬合度與參數個數的平衡。
BIC (貝葉斯信息準則): 越小越好。它的懲罰力度比 AIC 更大,傾向於選更簡單的模型。
4. 求解核心:最小二乘法 vs 梯度下降
最後,機器到底是怎麼求出斜率w和截距b的?我們可以使用兩種流派:
1.流派一:最小二乘法
原理: 直接利用以下矩陣運算一步算出最優解:
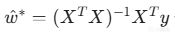
工具: statsmodels 庫擅長這個,輸出結果像R語言一樣詳細。
2.流派二:梯度下降
原理: 想象一個機器人在碗狀的曲面上,沿着梯度的反方向(最陡峭的下坡路)一步步往下走,直到走到碗底(損失函數最小值)。
公式:
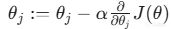
工具: sklearn 和深度學習網絡主要用這個。
第二部分:sklearn三部曲
現在,請記住 sklearn 的核心操作,只有這三步:1. 實例化(Instantiate)->2. 訓練 (Fit) ->3. 預測 (Predict)
這就是所有 sklearn 模型的通用“語法”。
我們今天依舊使用上次的Titanic數據集來進行演示:
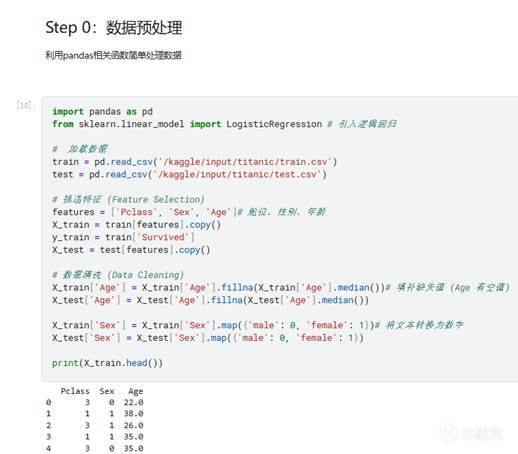
預處理不用多言,利用我們前十二次所學的pandas內容按需處理即可。

這一步比較死板,調用相關模型函數即可,線性迴歸是linear_model.LinearRegression,嶺迴歸linear_model.Ridge ,這裏調用邏輯迴歸函數。

通過fit我們可以得到預測變量與響應變量之間的迴歸模型,還能得到sigmod函數的權重與截距。

最後進行預測即可求出預測結果,我們看到前五個人裏只有最後一個人可以存活。
結語
這就完了?對,這就完了! 這就是 sklearn 的魅力。我們不需要寫幾百行的 if-else 規則,只需要調用 fit(),剩下的數學計算全交給它。
既然模型已經跑通了,現在的核心問題變成了:我怎麼知道這個模型好不好? 直接提交 Kaggle 太麻煩了,能不能在本地就給自己打分?
Day 14,我們將學習模型評估,讓機器在本地進行模擬考!
那這裏是浣熊,我們下次再見
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














