昨天給大家介紹了谷歌、英偉達等多家科技巨頭投資的首款A遊戲引擎Mirage,希望利用生成式AI徹底改變遊戲行業,號稱是一句話實現生成GTA世界,開發者僅需要給引擎輸入自然語言指令,就能實時生成GTA級的開放世界遊戲場景!今天給大家介紹的這個成果來自字節跳動和復旦大學放在arxiv上的最新論文項目,他們發現如果將推箱子、馬里奧和我的世界等類似的遊戲場景用於AI大模型的訓練,可以讓大模型的推理效率變得更高,而且遊戲代碼數據還有很多意想不到的效果!

01 我的世界
想象一下這個場景:
一個彙集了人類頂尖科技、價值連城的先進人工智能,
和一個能夠同時理解圖像和語言的“視覺語言模型”,
直接被應用到《我的世界》的像素世界裏,
AI很有可能會犯和萌新一樣的錯誤,
就是用木鎬或石鎬去採集鑽石,
而字節&復旦的新項目就是希望解決這個問題——
當今許多強大的人工智能“視力”很好,
可以快速分辨出物體場景,
但是卻缺乏我們玩家稱之爲“遊戲常識”的推理能力,
AI可以看清“是什麼”,
卻對“該怎麼做”一頭霧水,
就像是一個擁有神之眼,卻拿着新手木鎬的玩家,
空有屠龍之力,卻總在第一關被史萊姆幹掉。

02 AI訓練
要理解這場革命的意義,我們得先聊聊AI訓練,
本質來說,訓練一個AI就像是在MMORPG中練級,
AI需要經驗值來提升等級,
在AI的世界裏,這些經驗值被稱爲“訓練數據”,
但是並非所有的數據都能提供等量的經驗,
所以爲了讓AI學會複雜的推理能力,
它需要一種極其稀有、品質極高的“神裝級”數據,
AI領域一般稱其爲“視覺語言思維鏈”
(Visual-language Chain-of-Thought, CoT)數據,
簡單來說就是一種融合視覺與語言模態的推理技術,
可以通過模擬人類“分步思考”的過程,
將複雜任務拆解爲可管理的中間步驟,
最終生成邏輯連貫的決策或答案,從而獲得推理能力。
03 肝帝數據
我們可以把CoT數據想象成一本終極遊戲攻略,
它不是那種Boss在xx位置的簡單提醒,
而是一本詳盡到令人髮指的、圖文並茂的保姆級教程,
它會展示一張遊戲截圖,
然後附上一段完整的、一步不落的思考過程,
這種思維鏈只要是大家用過DeepSeek R1推理模型基本上都見過,
但是高質量的CoT思維鏈一直非常稀缺,
因爲傳統的獲取方法實在是太肝了,
需要大量人力進行手動標註,
你可以把它想象成遊戲工作室代肝,
僱傭成千上萬的人,讓他們玩遊戲,
並要求他們把自己每時每刻的每一個想法、
每一個決策步驟都原封不動地寫下來,精確到每一幀畫面,
這也導致很多強大的AI模型被困死邏輯推理的新手村裏,無法升級。
04 遊戲代碼
面對這樣的情況,國內字節跳動和復旦大學的研究者們,
迎來了他們的“尤里卡時刻”——
他們意識到每一個電子遊戲,
本質都是一個完美的、自洽的、可執行的邏輯宇宙,
遊戲的代碼本身,就是一本寫得天衣無縫的“思維鏈攻略本”,
當玩家按下“跳躍”鍵時,
代碼精確地定義了角色的起跳速度、
拋物線軌跡、碰撞檢測以及最終的落地狀態,
這就是一條完美無瑕、內置於遊戲世界的因果鏈,
這個絕妙的想法也直接催生了《Code2Logic》論文項目。

05 訓練細節
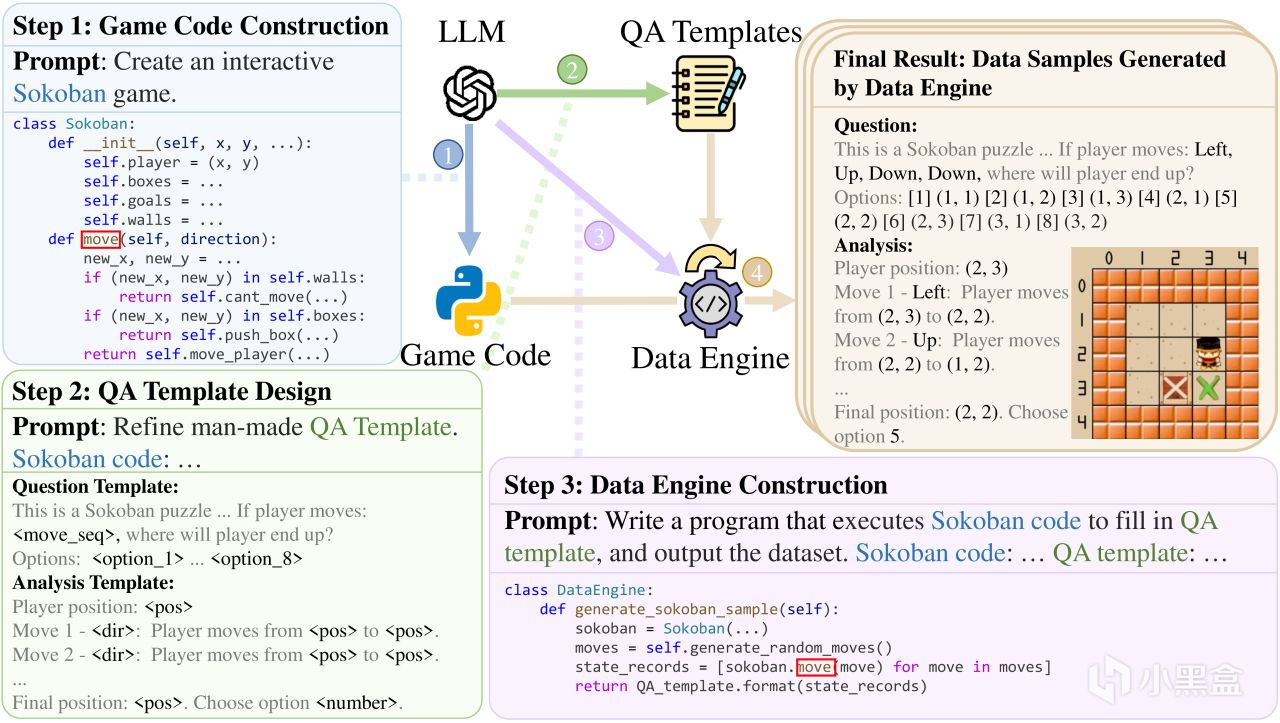
通俗來看,研究者們差不多是分三步來利用遊戲代碼訓練AI模型,
第一步是獲取這個邏輯宇宙的世界規則,
首先研究者用LLM大模型來輔助生成或改編各種遊戲的源代碼,
你可以把LLM想象成一個頂級的遊戲開發者或者《我的世界》裏的創世神,
用代碼構建出一個數字世界,並明確定義了其中的物理法則和交互規則,
比如《推箱子》這個遊戲,LLM可以生成Python代碼,
精確定義玩家的位置、箱子的位置、牆壁的座標,
還有一個核心的移動函數,封裝了所有狀態轉換的邏輯。
第二步世界地圖建好後,LLM會繼續扮演“任務設計師”的角色,
爲即將進入這個世界的AI玩家設計一系列“任務”,
這些任務就是所謂的VQA視覺問答模板,
爲了讓AI得到全方位的鍛鍊,這些任務還被精心設計成了三種由淺入深的任務類型,
對我們玩家來說簡直再熟悉不過了:
第一種是目標感知任務,類似於大家來找茬,考驗AI對靜態畫面的基本理解能力;
第二種是狀態預測任務,類似於狼人殺的預言家,要求AI根據一系列給定的操作,預測遊戲世界的未來狀態;
第三種是策略優化任務,這是最高級的任務,要求AI找到解決問題的最優解,比如推箱子殘局中,最少需要多少步,這類任務不僅要求AI會推理,還要求AI可以進行高效有策略的規劃。
06 構建數據引擎
接下來最後一步,研究者們構建了一個被稱爲“數據引擎”的程序,
可以理解爲遊戲界有史以來最精密的“掛機腳本”,
這個自動化程序同樣在LLM的協助下構建,
可以接管第一步生成好的遊戲代碼和第二步設計好的問答模板,
然後開始大規模地、不知疲倦地“刷數據”,
比如腳本會自動生成無數個全新的遊戲開局,
像是《俄羅斯方塊》裏隨機生成方塊序列,
然後腳本執行隨機的操作序列,
最後利用遊戲代碼那完美無瑕的邏輯,
自動填寫那本“終極攻略本”(也就是CoT數據)。
對比人力勞動手動標註,
這種直接用遊戲數據引擎自動生成的CoT顯然更加完美,而且成本也要更低!

07 GameQA數據集:魂遊般的難度
復旦大學和字節跳動團隊將這個掛機腳本產生的數據,
命名爲GameQA數據集,
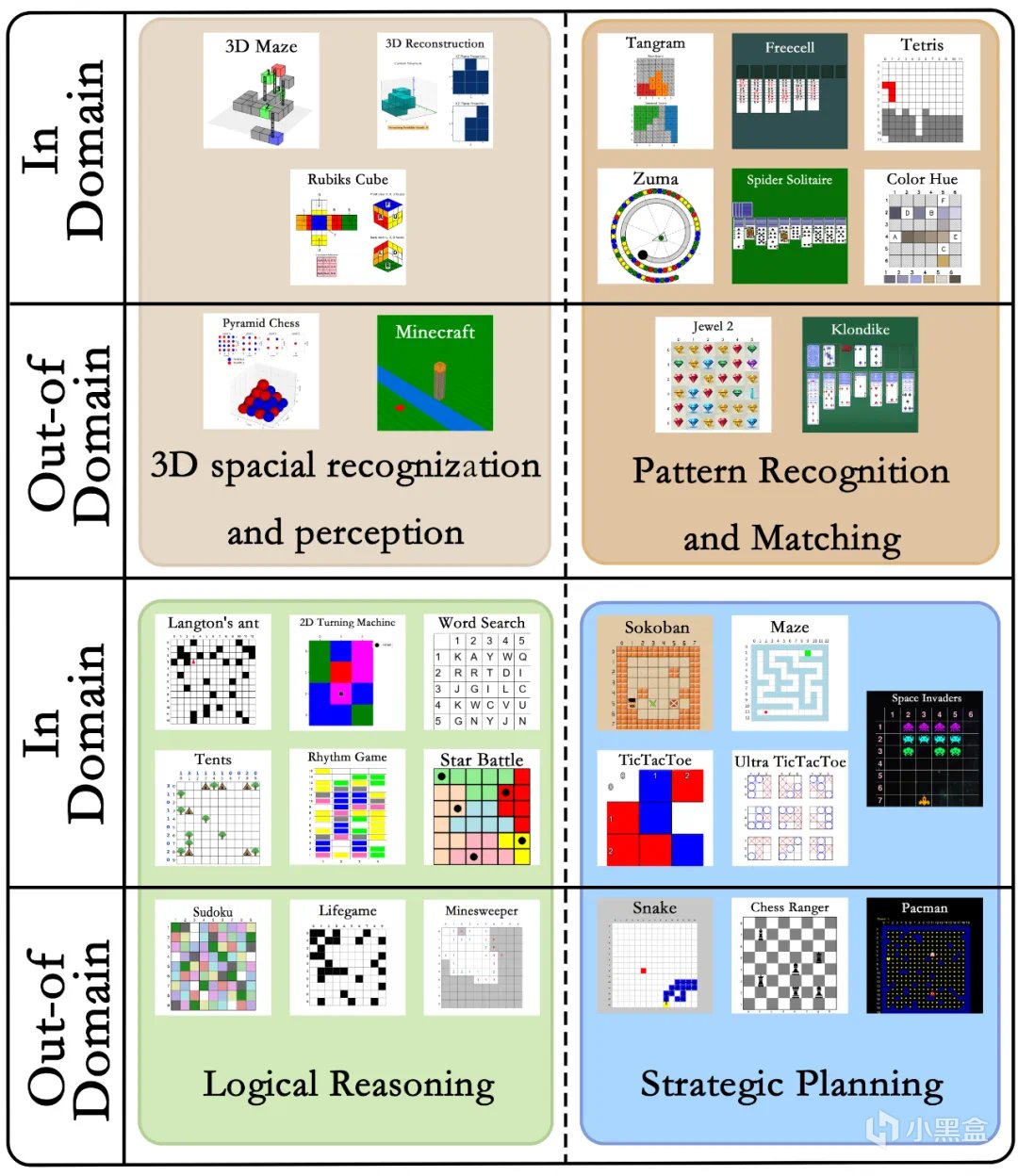
由30款風格迥異的遊戲構成,包含了158個獨特的任務類型,
總共生成了超過14萬個令人絞盡腦汁的問答數據對!
更關鍵的一點是,GameQA的難度極高,
研究者還偶然發現,即便是當前最頂尖的,
所謂“SOTA”(State-of-the-art)的AI模型,
在面對GameQA的挑戰時也紛紛折戟,
這也說明GameQA不是一堆AI能輕易解決的“小兒科”問題,
所以研究者們戲稱這是AI界的《黑暗之魂》,
難度高到令人髮指,
但每一次“受苦”都充滿了學習價值,公平且能真正鍛鍊技術。
08 未來
講到這裏,我儘量用玩家大家都能懂的語言來描述Code2Logic在做的事情,
這次實驗主要採用的是規則相對明確的益智和街機遊戲,
但是如果把這種方法擴展到較爲複雜的模擬經營類遊戲,
可能很難教會AI理解複雜的物流系統、供應鏈管理這些邏輯,
而且現實世界充滿了混亂、模糊、矛盾和非理性,
一個在高度結構化的環境中訓練出來的AI,
是否會因此產生一種“思維定勢”,
難以處理現實世界中那些沒有標準答案的複雜問題。
不過,遊戲世界的美妙之處就在於規則邏輯非常明確,
代碼規定了什麼能做,什麼不能做,一切都有清晰的邊界,
這次研究已經證明了純遊戲數據訓練的有效性,
那麼未來如果將這種高質量的合成數據與傳統的真實世界數據結合起來進行訓練,
又會產生怎樣的效果,在未來這或許也是提升AI能力的一個重要方向,
我推薦大家再往深處思考,本文的方法論其實也可以反哺遊戲本身,
既然AI可以通過理解遊戲代碼來學習推理,
那麼未來的遊戲NPC是否也能通過同樣的方式,
獲得真正智能的、符合遊戲規則的行爲模式?
由於時間關係,本文到這裏也就結束了,
未來有機會我再跟大家聊聊業界內關於遊戲NPC的一些研究成果!
遊戲&AI系列:
AI——是遊戲NPC的未來嗎?
巫師三——AI如何幫助老遊戲畫質重獲新生
你的遊戲存檔——正在改寫人類藥物研發史
無主之地3——臭打遊戲,竟能解決人類大腸便祕煩惱
一句話造GTA——全球首款A遊戲引擎Mirage上線
AI女裝換臉——FaceAPP應用和原理
AI捏臉技術——你想在遊戲中捏誰的臉?
Epic虛幻引擎——“元人類生成器”遊戲開發(附教程)
腦機接口——特斯拉、米哈遊的“魔幻未來技術”
白話科普——Bit到底是如何誕生的?
永劫無間——肌肉金輪,AI如何幫助玩家捏臉?
Adobe之父——發明PDF格式,助喬布斯封神
FPS遊戲之父——誰是最偉大的遊戲程序員?
《巫師3》MOD——製作教程,從零開始!
#gd的ai&遊戲雜談#
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

![[春促好價第一彈]——50款肉鴿遊戲推薦!你都玩過了嗎?](https://imgheybox1.max-c.com/web/bbs/2026/03/23/855853b9a3bd067b630ce6a4997f4abf.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)











