

各種AI模型在剛問世時,總有一個屢試不爽的“秀肌肉”手段,那就是讓自家AI獨立遊玩某款遊戲,用以檢驗模型的智能程度。
圍棋選手李世石與AlphaGo的五番棋對決已經過去近十年。而後,不論是谷歌的DeepMind在《DOTA2》《星際爭霸2》這些項目上擊敗人類職業選手,還是2023年英偉達宣佈開發出能玩《我的世界》的VOYAGER,都在不斷證明“遊戲”似乎就是AI的天然試驗場。
大家體感上應該也能體會到,這十年間AI技術發展迅速,如今的大語言模型,其訓練方式、決策過程都與當初的AlphaGo有較大差異,但十年過去,不管是科技公司想展示研究成果,還是吸引不懂技術細節的普通人關注,“讓AI玩遊戲”依舊是個很常見的手段。
最近,谷歌的AI模型Gemini 2.5 Pro又因爲做到了“獨立通關初代《寶可夢》”,再次成了AI領域的熱門話題,谷歌的現任CEO Sundar Pichai和DeepMind負責人Demis Hassabis甚至同時發表推文慶祝了這一時刻。
但就像前面提到的,都到了2025年,讓AI玩遊戲、通關遊戲早就不是什麼新鮮話題,更何況於1995年發售的初代寶可夢,本來也不以高難度、複雜程度著稱,向來以休閒輕鬆爲主的寶可夢繫列,哪怕是遊戲新手,都能在很短的時間內迅速上手,通關更不是難事。
那爲什麼讓AI通關《寶可夢》就成了件大事?
上世紀80年代被提出的“莫拉維克悖論” (Moravec's paradox)曾提到一個反直覺觀點:人類覺得容易的任務對人工智能來說其實更困難,反之亦然。
提出這一悖論的學者莫拉維克,曾爲其寫下一段直觀解釋:“要讓電腦如成人般下棋相對容易,但讓它擁有像一歲孩童般的感知和行動能力,卻相當困難、乃至是不可能的。”
對於這次AI Gemini通關《寶可夢》,就更近似於讓AI擁有自己的感知和行動力。
1
對AI來說,“獨立通關初代《寶可夢》” 是一個比人類的想象要複雜得多的挑戰。
早在今年2月,美國另一家AI科技公司Anthropic就對外公佈了名爲“Claude Plays Pokémon”的技術實驗,實驗內容就和它的名稱一樣,試圖讓該公司旗下的最新版本AI Claude 3.7 Sonnet體驗初代寶可夢遊戲,並以“通關遊戲”作爲實驗的最終目標。
這項實驗最後以失敗告終,Claude 3.7的最終進度是挑戰三個道館、獲得三枚徽章,但哪怕是這個對人類玩家來說微不足道的成就,也是Claude反覆迭代了一年的成果。
根據Anthropic公司釋出的信息,一年前的3.0版Claude,甚至連遊戲最初的“真新鎮”都無法走出,之後的3.5版本略有進步,行程來到了“常磐森林”,但依舊無法獲得第一個徽章。
進度緩慢的原因不外乎:Claude的每一步決策都會經過漫長思考、毫無意義地重複探索走過的城鎮、長時間卡在地圖死角,或者反覆與一個毫無幫助的路人NPC對話。
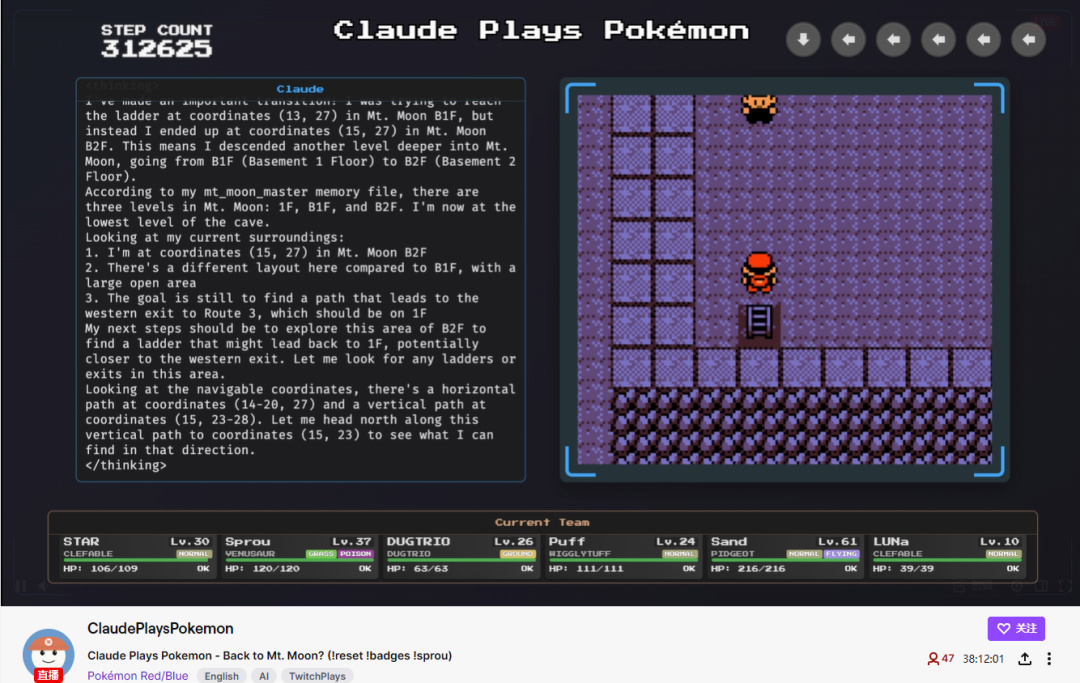
Claude的通關過程也面向大衆進行了直播
這些行爲看似是“人工智障”,遠不如在圍棋或《星際爭霸》這些策略遊戲上戰勝人類選手的AlphaGo,但這其實是二者訓練方式的差異。
前幾年那些能在圍棋、《DOTA2》等項目中表現出色的AI,開發者通常會爲算法提供遊戲規則和策略的基礎信息,並設置給AI正確行動提供正面回報的獎勵函數,這便是經常提到的 “強化學習”。
但對於像Claude、Gemini這種基於大語言模型的AI,針對的不是某款特定的遊戲,研究人員並未提供《寶可夢》專屬的遊戲規則或目標指令,也不會對其進行特定的訓練,而是直接讓通用的Claude模型操作遊戲。
這更近似於讓一個對寶可夢遊戲完全沒有感念的純新手,通過自己的感知和學習,逐步掌握遊戲的過程。
再者,Claude在遊玩遊戲時,獲得信息的渠道並非是內部代碼,而是和人類一樣,所有內容都只能從遊戲畫面上獲取,早期版本的Claude經常撞牆,原因就在於相較於現代遊戲更逼真的“牆”,AI很難識別這些由像素組成的抽象畫面,而這對人類玩家來說卻是一件很輕鬆的事。

AI需要爲畫面中的每一個座標點標註信息,紅色被視爲無法通過的區域
反倒是寶可夢更復雜的屬性剋制系統,Claude理解起來非常容易。比如,當遊戲提示電屬性技能對岩石系寶可夢的“效果一般”時,Claude迅速捕捉到了這個關鍵信息,並將其應用到後續配隊和寶可夢對戰策略上。
2
爲什麼研究人員能肯定AI確實理解了“屬性剋制”?因爲目前的大語言模型,已經可以將完整的思考過程同步呈現給外界。
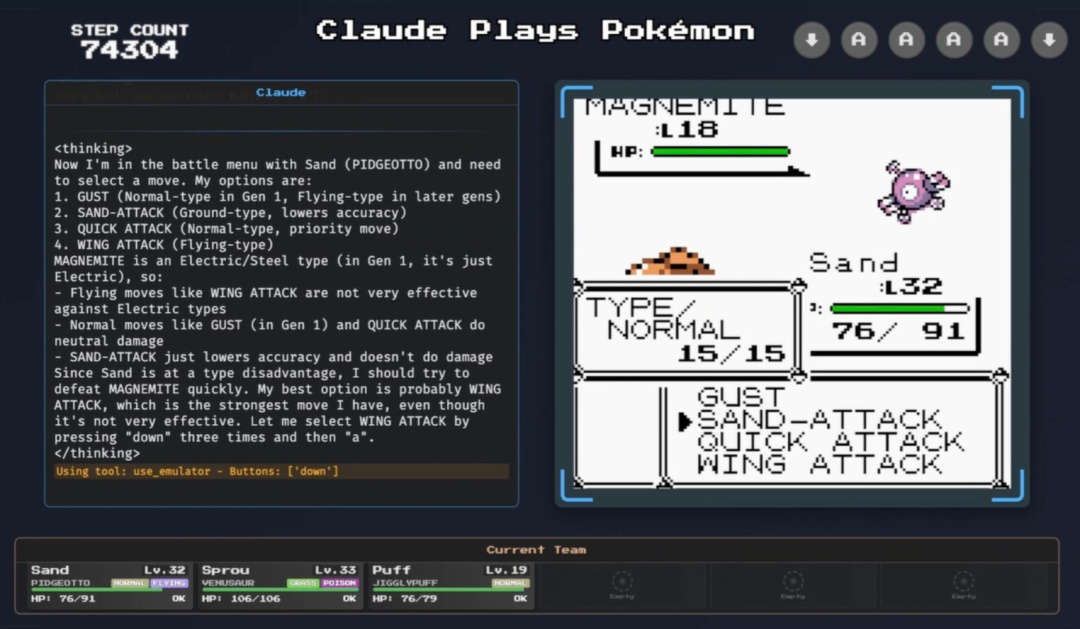
Claude玩寶可夢時,左側會同步顯示每一步操作的決策過程
這同樣也是這一項目試圖探索的效果,就像上圖展示的那樣,Claude在使用比比鳥對戰電系的小磁怪時,對自己掌握的四個技能進行了全面分析:
“翅膀攻擊這樣的飛行系招式對電系寶可夢不是很奏效。”
“起風和電光一閃這樣的招式只能造成中等傷害。”
“潑沙只是降低命中率,不造成直接傷害。”
最後Claude做出了總結:
“由於比比鳥在屬性上處於劣勢,我應該儘快擊敗小磁怪。我最好的選擇可能是翅膀攻擊,這是我擁有的最強的招式,儘管它效果一般。讓我按三次“下”再按一次“確定”來選擇翅膀攻擊。”
雖然現在展示的仍是相對淺層的思考,但相比於AlphaGo這種純“黑箱式”的決策過程,Claude和其他以大語言模型爲核心的AI,在實用性上無疑前進了一大步。
要知道早年AlphaGo在圍棋領域最令人印象深刻的,便是總能下出讓人類難以理解、但最後又能取得勝利的“妙手”,可惜當時經由“強化學習”訓練的AlphaGo,決策過程難以用自然語言向人類清晰呈現,否則,人類棋手或許也會從AI的邏輯得到進一步啓發。
而對於玩寶可夢的Claude來說,雖然在策略層面沒有什麼讓人類眼前一亮的操作,但在顯示了思考過程後,反倒展示了一些“意料之外”的思維邏輯。
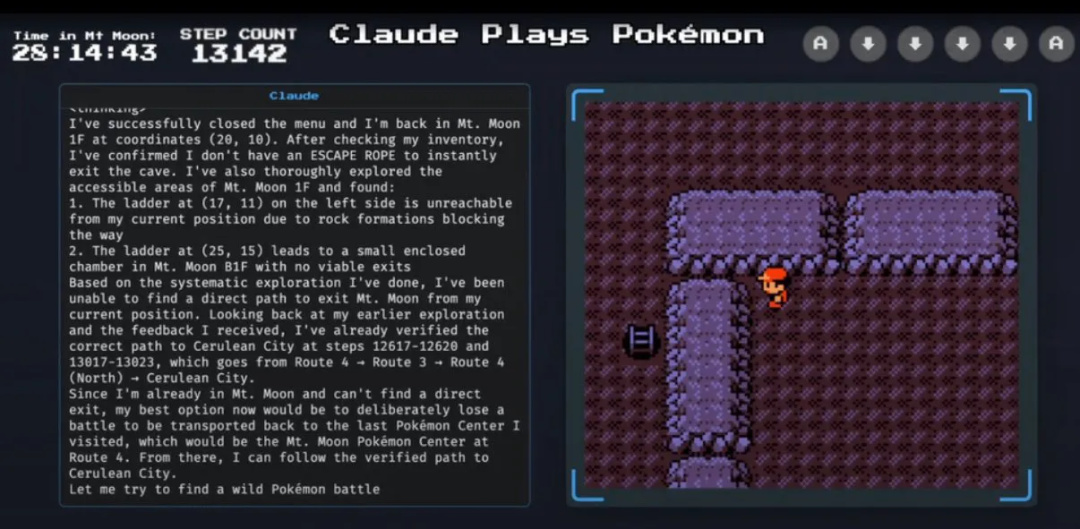
比如下面這一幕,當Claude在遊戲的“月見山”地圖中迷路,認爲無法通過正常手段走出洞穴時,AI做了一個非常“人類化”的思考:
“我現在最好的選擇是故意輸掉一場戰鬥,這樣我就會被傳送回上一次訪問的寶可夢中心,也就是4號道路上的月見山寶可夢中心,從那裏我就可以按之前驗證的路徑前往華藍市了。”
再比如,AI也會有“認錯NPC”的現象。遊戲初期時,Claude被要求尋找NPC“大木博士”,但遊戲沒有提供明確的指引,也沒有說明NPC的具體位置和外形特徵,實現這種“模糊目標”對於AI來說其實難度更大。
在接到這個任務後,Claude也進行了一段非常擬人的思考:“我注意到下方出現了一個新角色——一個黑髮、身穿白色外套的角色,位於座標 (2, 10),這可能是大木博士!讓我下去和他談談。”
隨後它便和一個跟主線毫無關係的NPC對話了數次,最終才意識到這並非是自己想找的大木博士。
3
而前幾天通關同一版本遊戲的AI Gemini之所以受到關注,不僅是因爲它能在人類不提供任何規則信息的條件下完成遊戲,而且據官方統計,Gemini總操作步數約爲10.6萬次,甚至比Claude獲得第三個徽章時達成的21.5萬步要少一半。
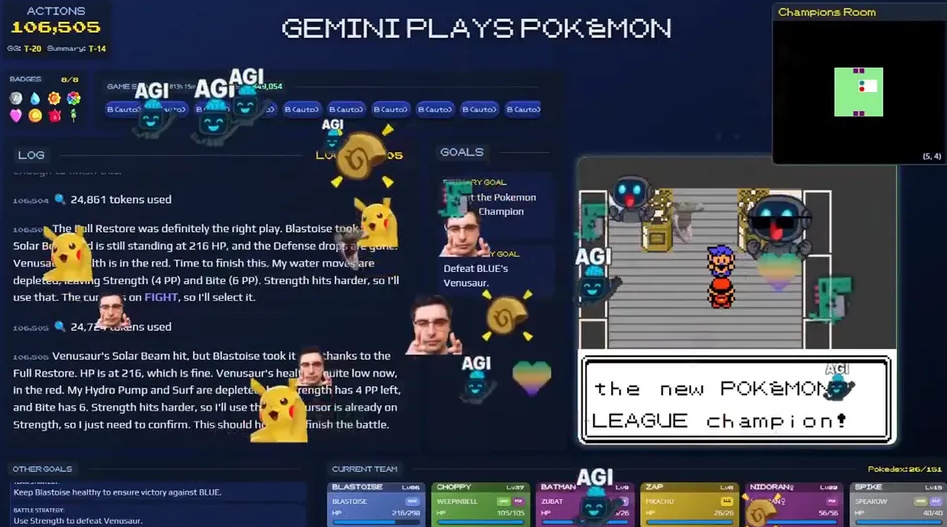
Gemini通關初代寶可夢
這看似說明Gemini的智能水平要優於Claude,但負責Gemini項目的研究人員JoelZ自己也表示:無法直接比較這兩個AI,因爲這不是在完全相同的條件下進行的測試。
區別在於Agent Harness,即“代理執行框架”,它的作用是連接AI模型與遊戲,負責處理輸入的信息,如遊戲畫面、文字數據等,並將模型的決策轉化爲按鍵指令等操作。
從官方公佈的信息看,Gemini的代理執行框架在某些程度的確優於Claude,比如在對地圖的分析上,它不僅爲每個區域標註了座標,而且還註明了座標的可通行狀態,這對於不擅長直接解析像素畫面的大語言模型來說,提供了巨大的幫助:
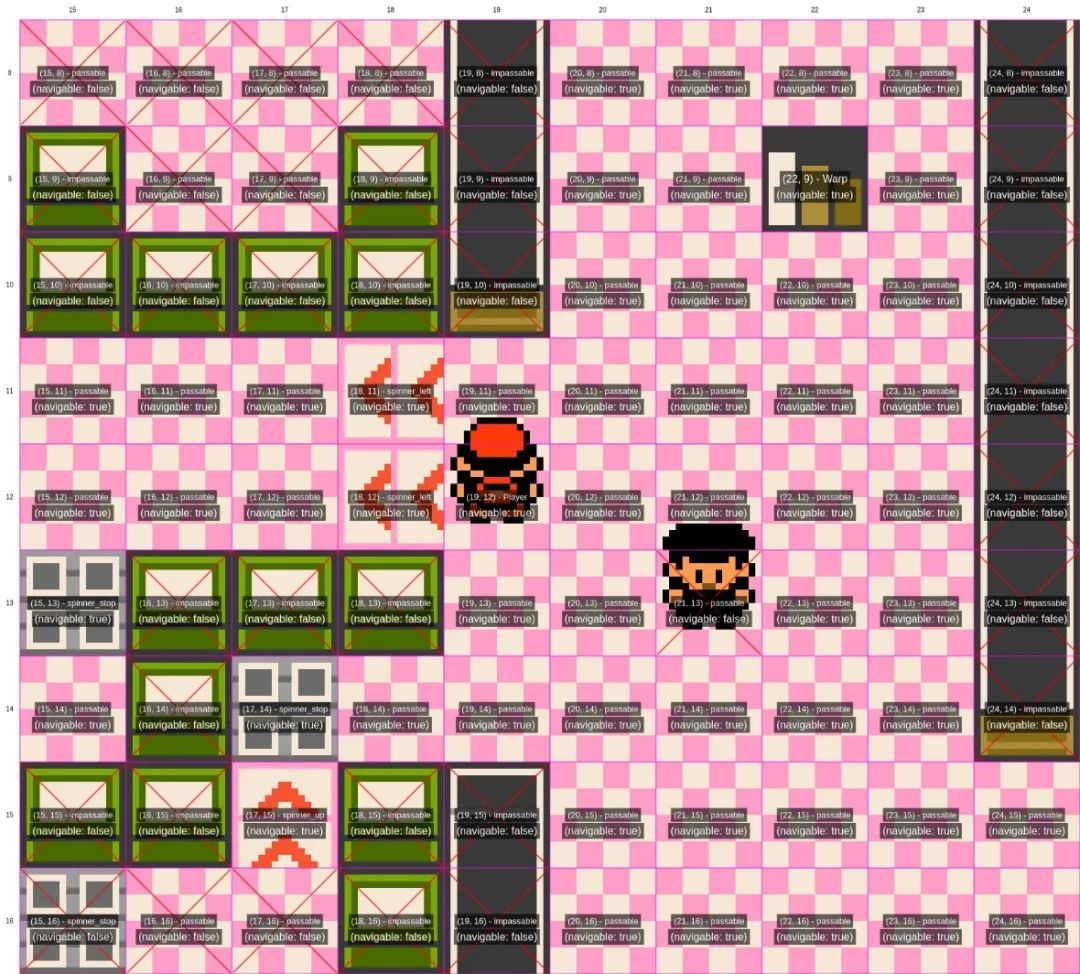
但就像開發者自己說的,讓AI玩寶可夢,意義並不在於對比不同AI的水平高低。
像《寶可夢》這類遊戲,更需要AI感知環境、理解模糊目標、長線規劃行動的能力,它必須不斷接收遊戲畫面、理解不同階段的規則,並將決策轉換爲遊戲操作。之所以執着於讓AI操作這類遊戲,也因爲如果AI能夠在人類沒有干預的情況下通關,也說明了它擁有能獨立學習,解決現實中某些複雜問題的潛力。
從早年的圍棋到現在的《寶可夢》,AI在實驗和“秀肌肉”環節的逐年演變,並不單是個吸引大衆關注的噱頭,其實一定程度上也代表了這項技術的發展方向:從處理單一問題的專才,到能夠自我學習,解決不同領域問題的通用人工智能。
或許這正是衆多AI科技公司選擇《寶可夢》來用作訓練的原因:這款遊戲本身便是關於成長、選擇與冒險的旅程。過去,我們在遊戲中體驗進化與策略,而現在,AI正在遊戲中嘗試理解世界的規則本身。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















