半个多月前,谷歌搞了一波突然袭击,毫无预兆地发布了新一代AI模型Gemma,并宣称这是全球性能最强大的轻量级开源系列模型。

根据Google介绍,开源模型Gemma使用了和Gemini同源的技术,总共有20亿参数和70亿参数两种规模,每个规模又分预训练和指令微调两个版本。
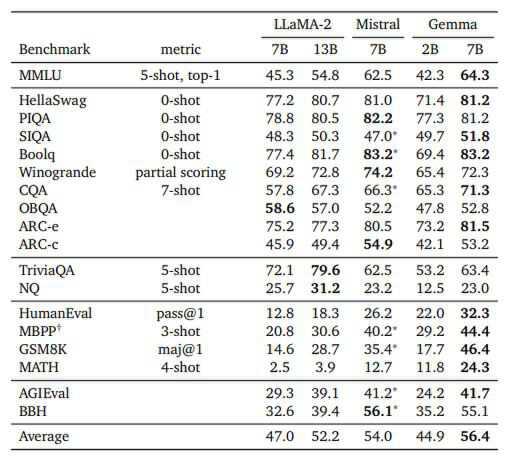
在Gemma官方页面上,Google给出了Gemma在语言理解、推理、数学等各项标准测试中的得分,其中70亿参数模型击败了主流开源模型Llama-2和Mistral,直接登顶Hugging Face开源大模型排行榜,成为目前全球最火热的开源大模型之一。
与Gemini的全家桶路线不同,Gemma这次主打轻量高性能,拥有2b、2b全量版、7b、7b全量版4种版本。
其中最基础的2b模型即便是在没有独显的笔记本电脑上都能尝试运行,而规模更大的7b、7b全量版分别需要8GB和16GB显存。
经过实测,虽然Gemma的使用体验不如ChatGPT-4等成熟的闭源大模型,但是本地运行模式还是有其存在的意义的,对于私密性要求较强的用户,也可以在断网的情况下本地加载运行,不用担心相关信息泄露等等。
本次就为大家分享本地部署Gemma的操作流程,并演示如何使用JAN AI来实现UI界面访问Gemma。
一、安装Ollama
Ollama 是一个专为运行、创建和分享大型语言模型而设计的开源项目,为开发者和研究者提供了一个平台,使得他们可以更方便地部署、管理和使用这些大型语言模型。目前Ollama支持支持 macOS、Windows、Linux 和 Docker等多种安装方式,还能通过 API 方式为本地 AI 服务提供便捷途径。
目前Ollama支持的模型如下图所示:
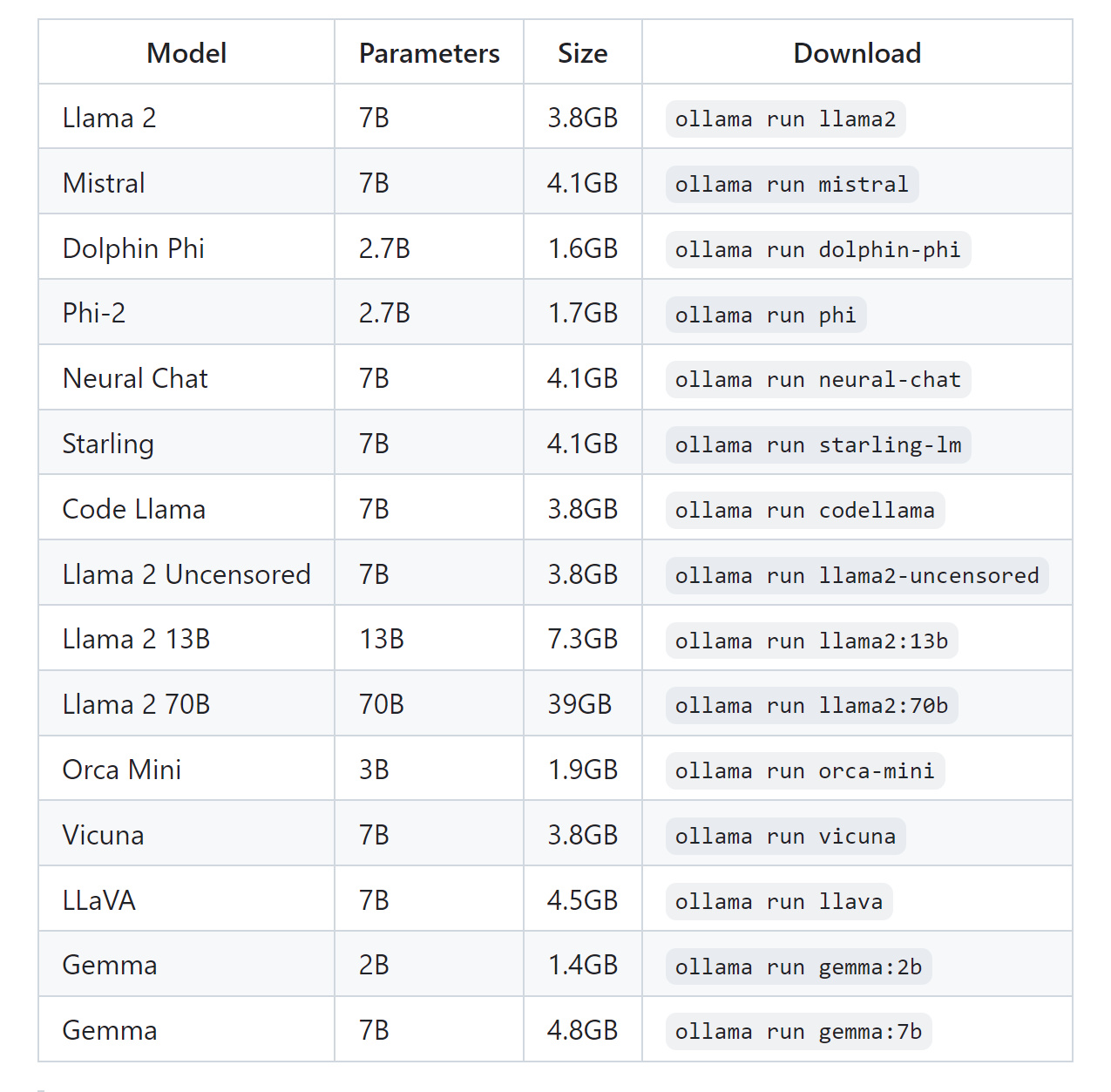
这里我们以Windows系统为例来演示,首先去Ollama的官网或者GitHub页面下载最新的Windows版本安装包:
https://ollama.com/
https://github.com/ollama/ollama
下载安装包后,一路点击“下一步”安装即可。
完成安装后,点击桌面图标运行Ollama,此时桌面右下角Windows系统托盘里有正在运行羊驼图标:

接下来我们进入CMD命令提示符,输入“ollama --version",当看到ollama版本号正确显示时,就已经完成安装了。
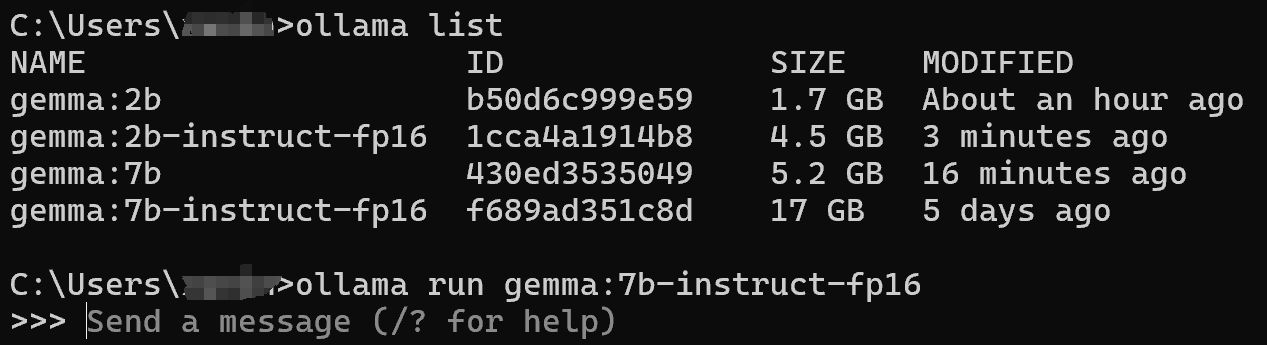
二、拉取并运行Gemma模型
这一步我们直接使用最简单的方法,使用Ollama来拉取Gemma的模型文件。请注意,由于文件服务器在国外,所以我们需要一些魔法上网的技巧,请自行研究。
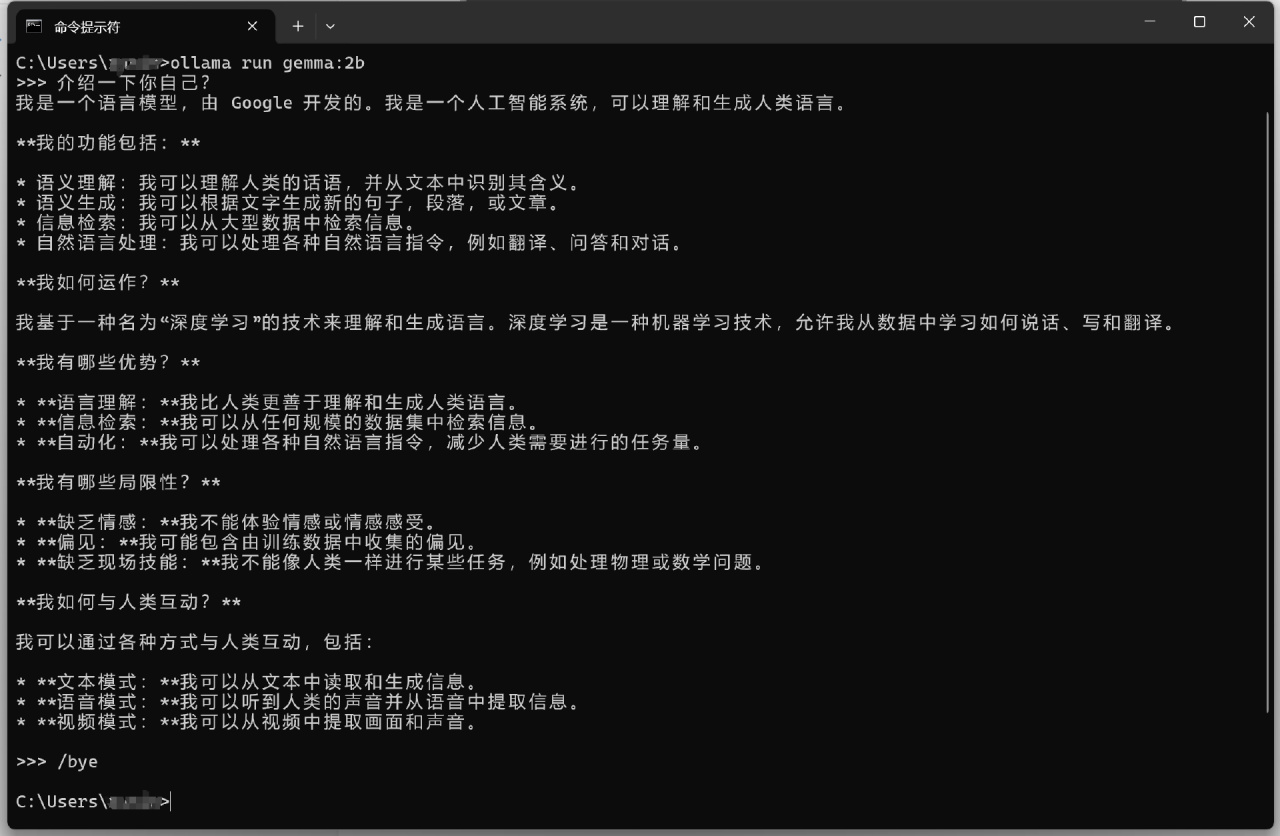
以对电脑配置要求最低的Gemma 2b基础版模型为例,在命令提示符中,我们输入ollama run gemma:2b代码并回车,Ollama会自动从模型库中拉取模型文件并进行运行。当模型加载后,会显示success的标识,此时我们就可以输入汉字与Gemma:2b进行对话了。

如果想要结束对话,我们可以在Gemma的信息输入框中输入/bye即可。
到底为止,Gemma在我们本地已经部署成功了,这里顺带说些其他的事儿。
1.首先Ollama虽然在GitHub页面中只列出了Gemma 2b和7b基础版模型的拉取代码,但实际上我们还是能通过它来拉取全量版模型的,代码分别如下:
ollama run gemma:2b-instruct-fp16
ollama run gemma:7b-instruct-fp16
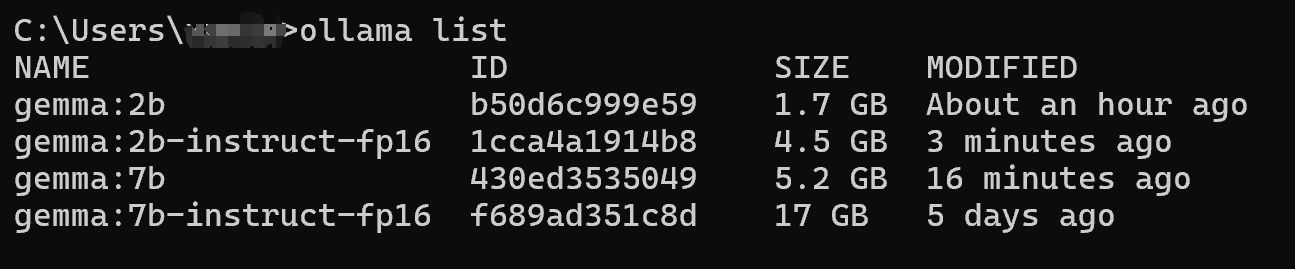
2.想要知道目前Ollama中已经拉取了哪些模型,可以用ollama list来实现:
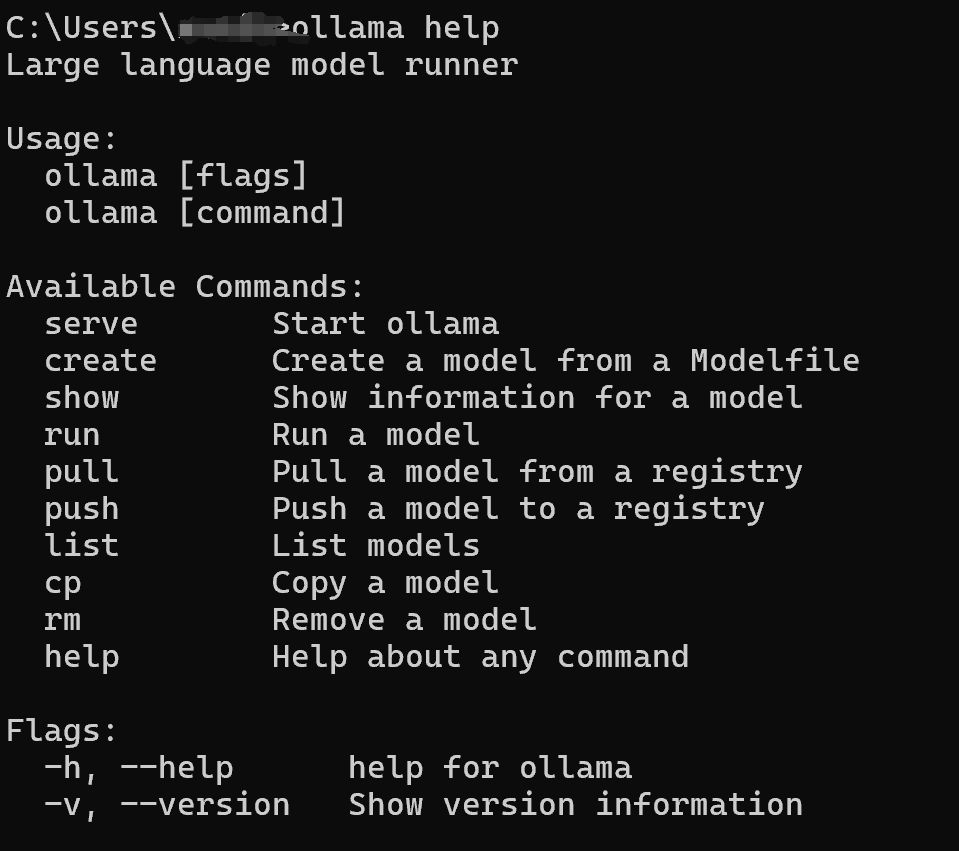
Ollama的其他命令可以参考下图:
三、使用JAN AI美化UI界面
通过Ollama在本地部署Gemma后,我们虽然能在命令提示符中与模型对话,但是这种方式未免也太过麻烦了,所以还是需要有一个类似nextChat之类的软件来美化一下UI界面,同时还可以实现更多功能。
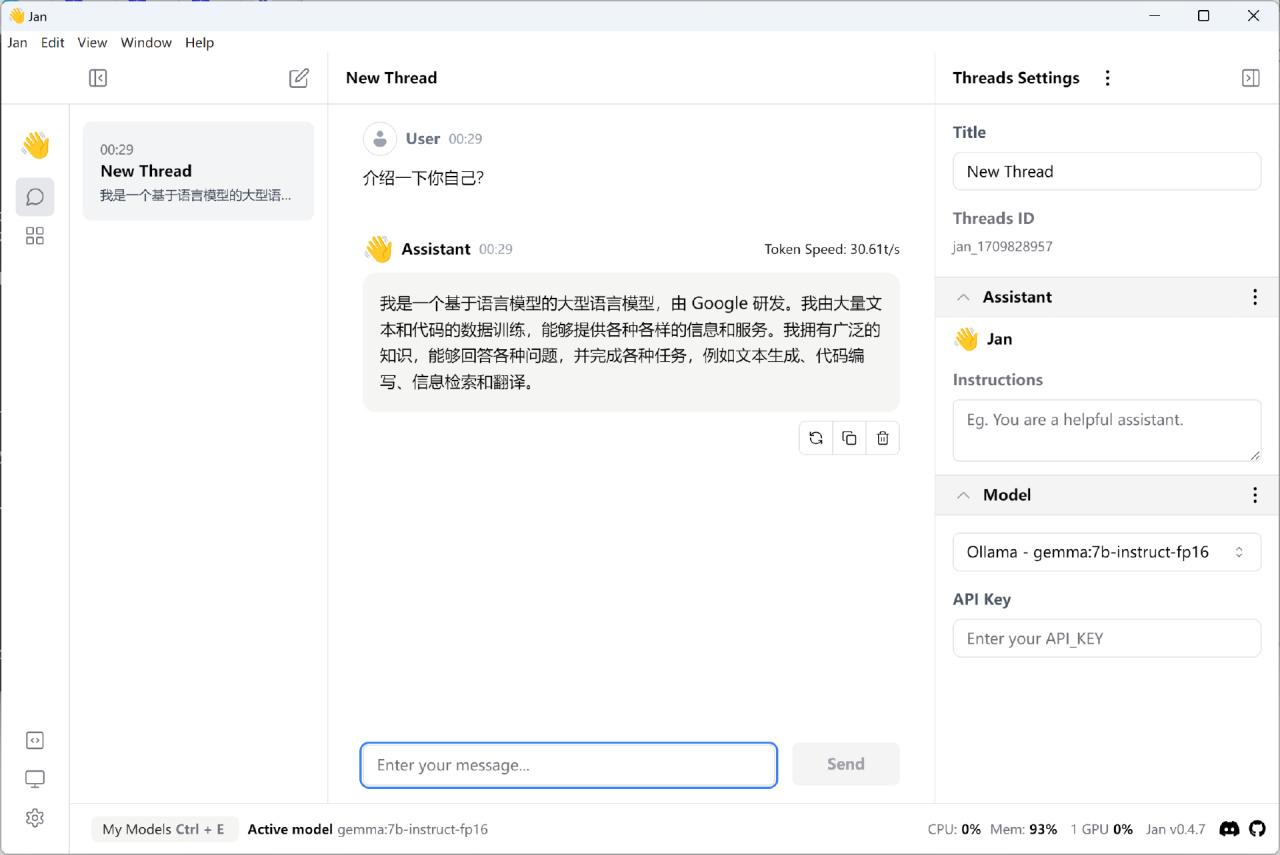
本来Ollama官方推出了open-webui这个开源项目,不过目前该项目尚未推出Windows安装包,在wsl中使用docker安装的方式又有点儿麻烦,所以经过实现,这里还是选择UI非常好看的JAN AI来与Ollama进行链接吧。
首先我们要到JAN的官方网站下载Windows客户端,并直接安装:
https://jan.ai/
在JAN的官网上,有非常详细的操作手册,我们可以在其中找到关于如何链接Ollama的方法。
1.启动 Ollama 服务器
首先我们要通过命令提示符启动 Ollama 服务器,并且加载运行我们要跑的Gemma版本,这里以7b全量版为例:
根据有关 OpenAI 兼容性的 Ollama 文档,Ollama在运行时会提供类似OpenAI的API服务,我们可以使用网址:
http://localhost:11434/v1/chat/completions
连接到 Ollama 服务器。
我们需要去JAN的安装地址,一般是“C:\Users\你的用户名\jan\engines”中找到penai.json 文件,在其中修改为Ollama 服务器的完整网址。
示例如下:
{ "full_url": "http://localhost:11434/v1/chat/completions" }2.模型配置
进入jan安装位置的models 文件夹,创建一个在Ollama中运行的模型同名的文件夹,例如gemma:7b-instruct-fp16。
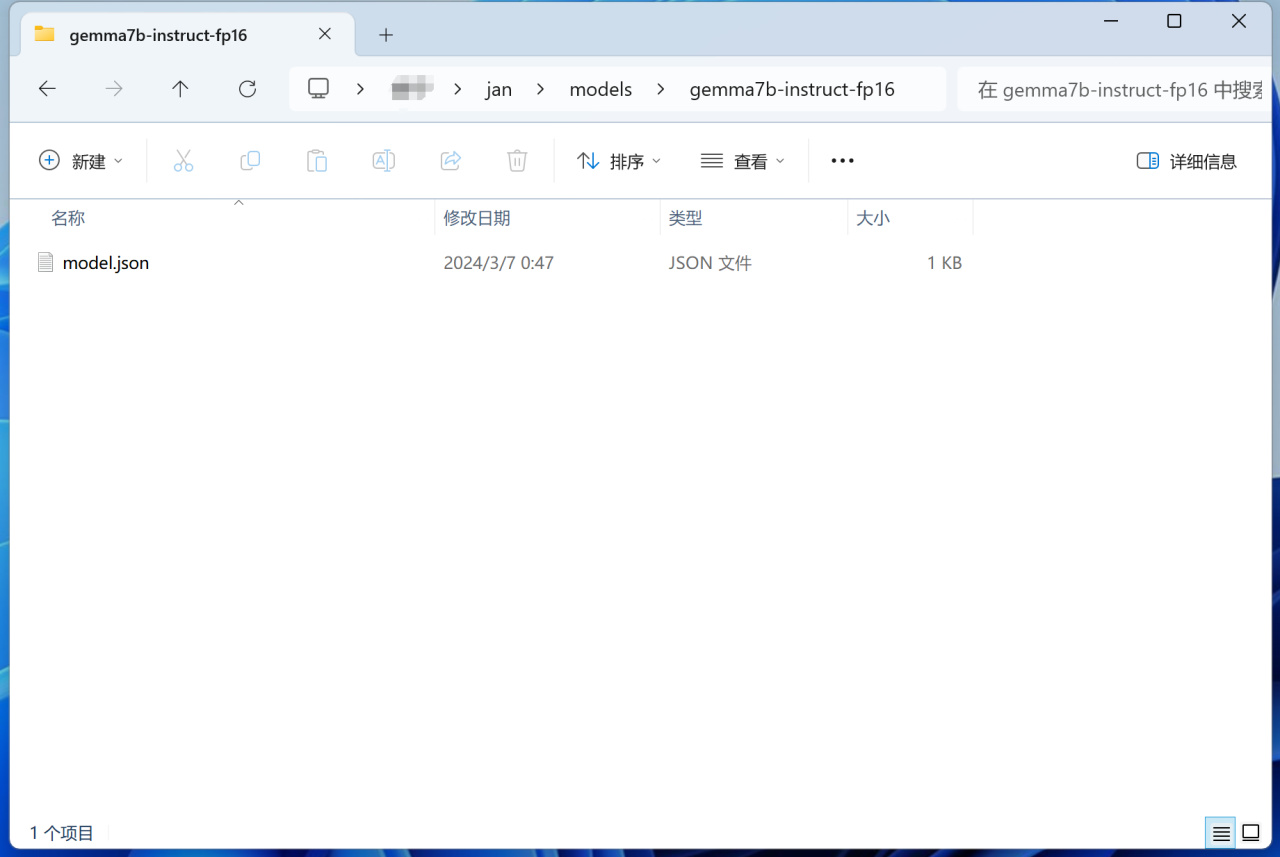
然后在文件夹内创建一个 model.json 文件,在其中将 id 属性设置为 Ollama 模型名称,将格式属性设为 api,将引擎属性设为 openai,将状态属性设为 ready。
示例如下:
{ "sources": [ { "filename": "gemma:7b-instruct-fp16", "url": "https://ollama.com/library/gemma:7b-instruct-fp16" } ], "id": "gemma:7b-instruct-fp16", "object": "model", "name": "Ollama - gemma:7b-instruct-fp16", "version": "1.0", "description": "gemma:7b-instruct-fp16 by ollama", "format": "api", "settings": {}, "parameters": {}, "metadata": { "author": "Meta", "tags": ["General", "Big Context Length"] }, "engine": "openai" }3.启动模型
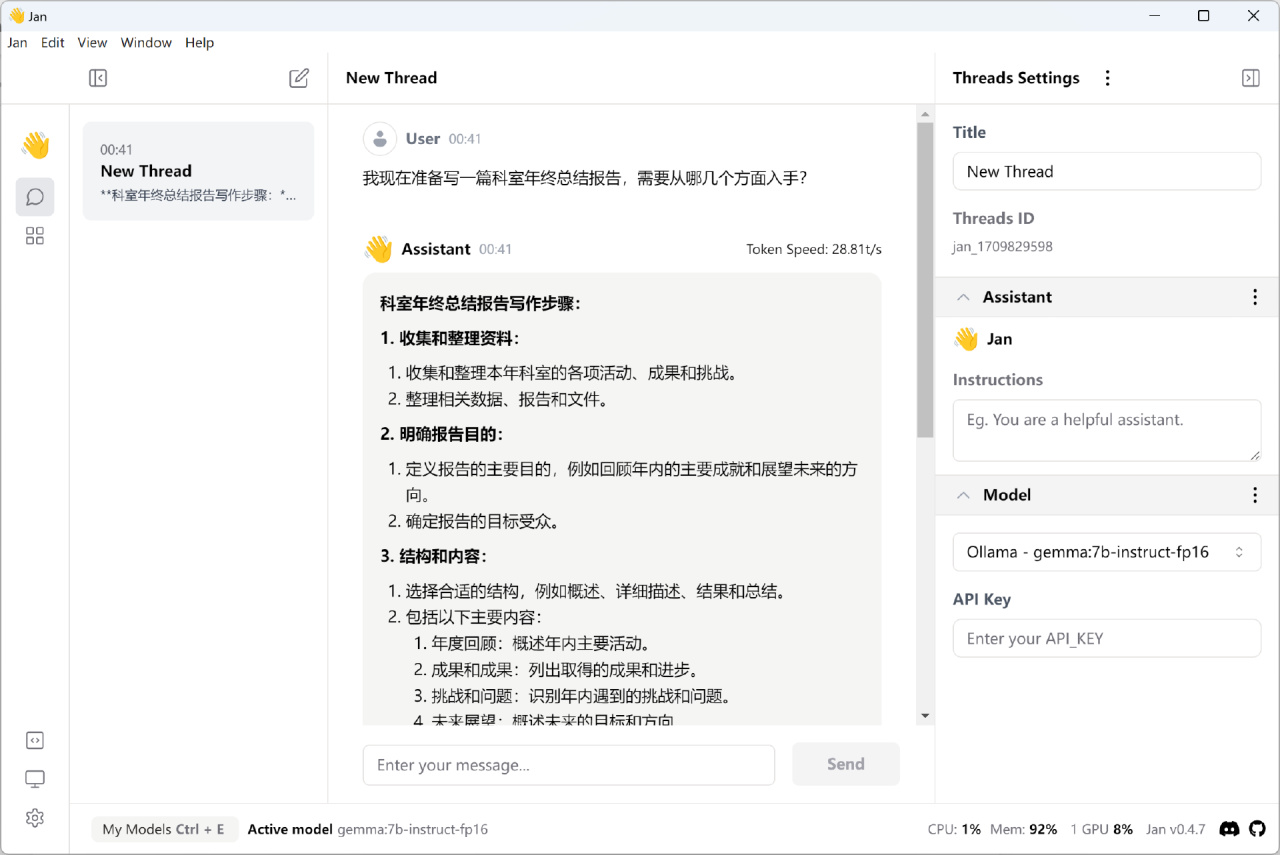
重新启动 Jan ,在模型HUB中找到我们刚才新建的gemma:7b-instruct-fp16,然后点击“USE”即可。
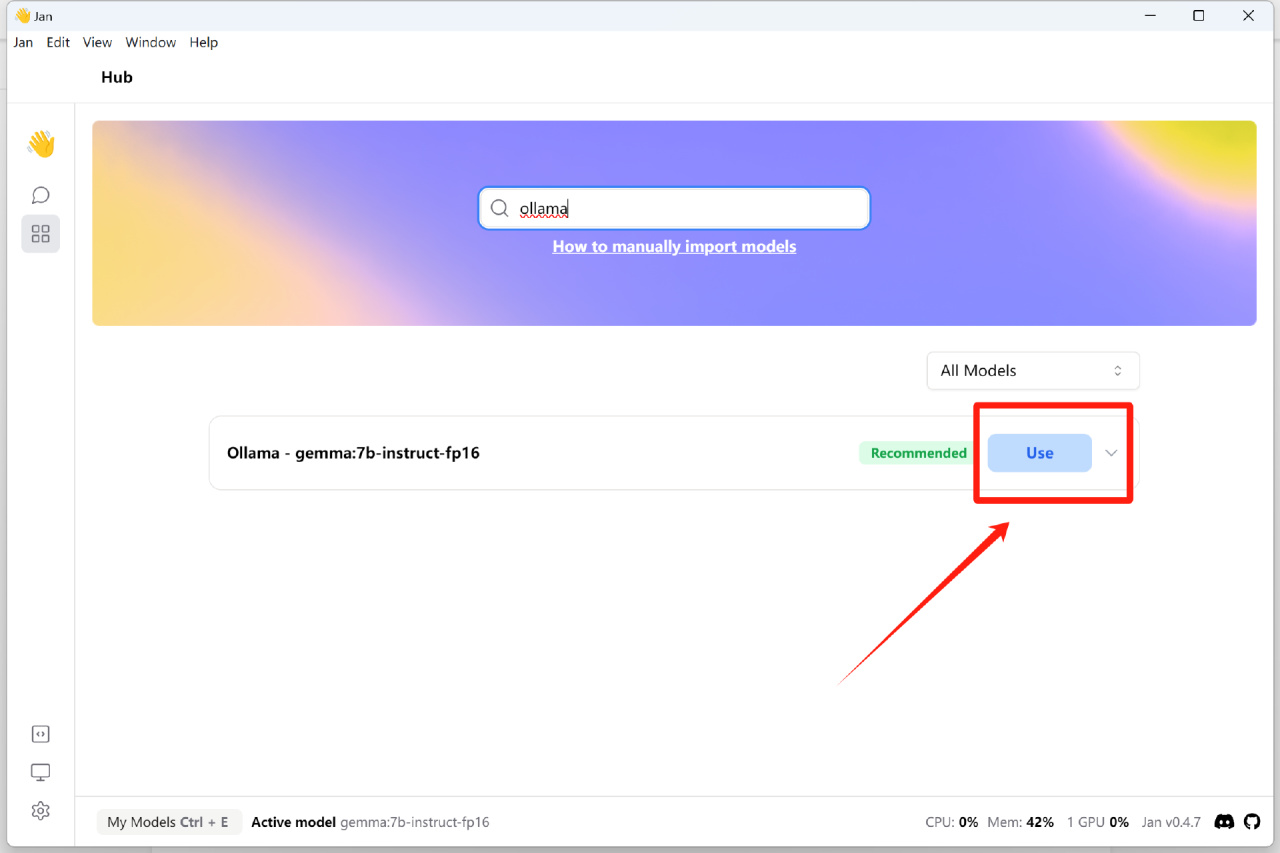
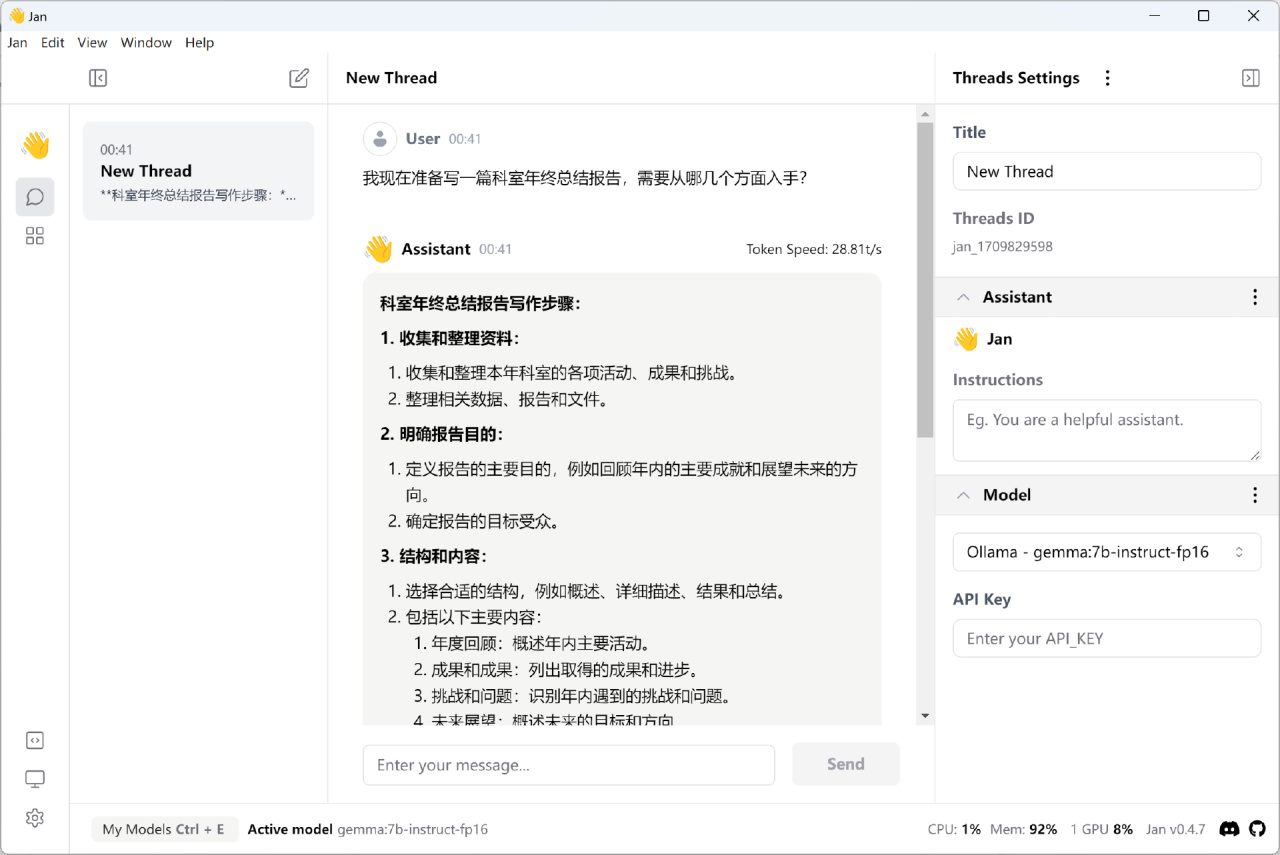
接下来我们就可以和Gemma进行正常对话了,比如问一问它,写年终总结报告要注意点啥事儿:
四、显卡选购小贴士
目前AIGC领域如火如荼,除了如本文所述,在本地部署的AI语言大模型之外,stable diffusion等开源文生图的应用更是广泛,为我们的生活和创造提供了绝佳动力。
由于AIGC应用中,GPU用来推理的效率要比CPU强的太多,所以我们需要一张性能强、显存大的显卡来更好的提高本地AIGC应用的运行效率,这是刚需,真的没法省。
而NVIDIA系列的显卡因为早早布局了CUDA,所以在AI领域无疑拥有近乎无解的统治力,要玩AIGC的话还得选N卡为主,AMD和Intel红蓝两家目前还需要追赶。老黄家的RTX30系N卡由于已经停产,并且在算力方面整体不如RTX40系显卡(毕竟4070Ti就要赶上前期间3090了),所以个人的建议还是买新不买旧,就从RTX40系显卡中捡显存大的型号选购得了。
这里为了方便大家对比,我整理出了当前RTX40系显卡型号的参数列表:
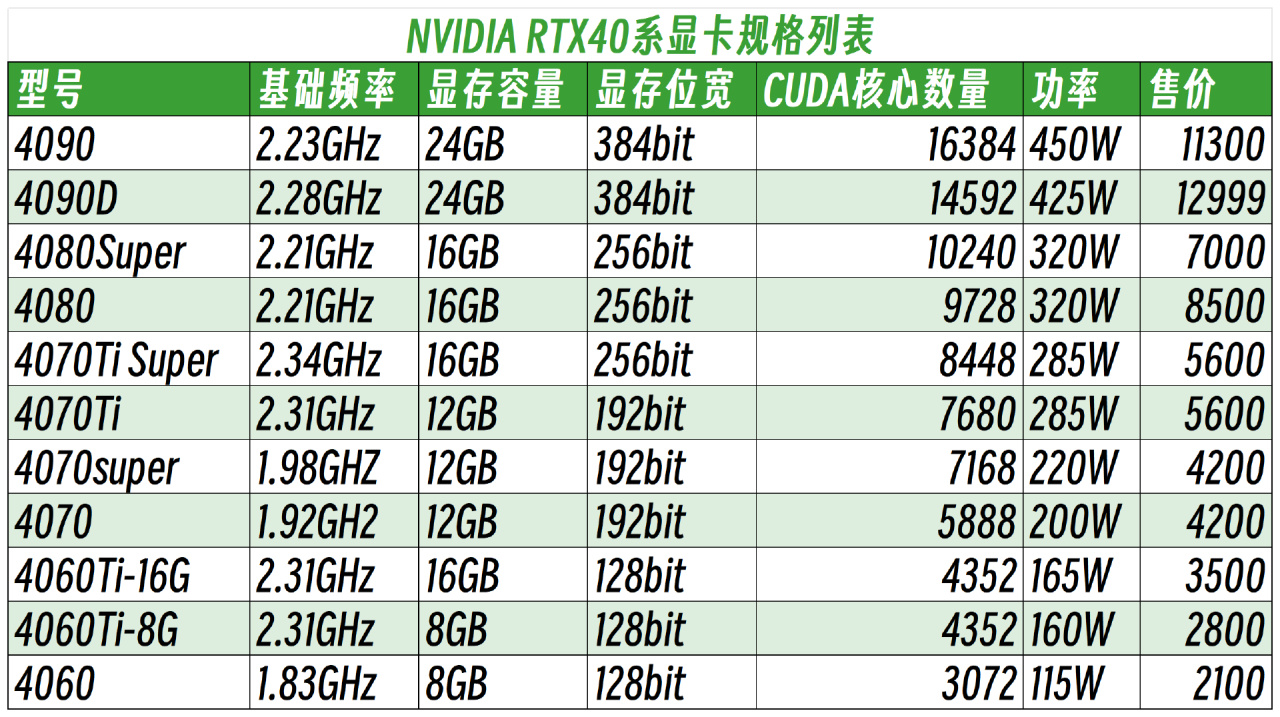
可以看到,富哥的首选肯定是24GB满配显存的RTX4090了,无论是利用AIGC干活儿还是游戏娱乐都是目前消费级显卡中的第一把好手,就是目前阿美断供搞得价格飞涨,让人有点难受。而4090D由于专门阉割了AIGC会用到的CUDA核心和Tensor核心数量,所以虽然市场价更低些,但是反而不如4090值得。
对于大部分玩家而言,退而求其次的选择则是4080Super、4080、4070TiSuper、4060Ti-16G这几张16GB显存的显卡。毕竟算力高低无非是影响AIGC干活儿效率而已,但是显存不够大,那有些本地大模型是真的跑不起来,连门槛都进不了,确实会耽误事儿。
其中4060Ti-16G作为最便宜的16GB显存N卡,还是值得着重看看的。
最后就是关于显卡品牌的选择了,目前华硕、微星、技嘉、七彩虹等一线显卡商中,技嘉因为之前大家都知道的宣发事故,导致这一两年各产品线的价格都相对要更低一些,仅从性价比方面来看其实是真挺香的,预算紧张的话可以一试。
其他的二、三线品牌就不一一列举了,如果不追求一线大厂的话,那大家可以凭着预算随意选购即可。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















