
在刚刚过去的春节期间,科技界发生了一件大事。2月16日凌晨,OpenAI带来了它们全新的视频生成模型——Sora。Sora就是视频界的ChatGPT,你只要写下一段文字, Sora这个AI会生成一段视频。比如上面这个视频截图,就是中国春节舞龙,这几个字来生成的。

而上面的这个小狗玩雪的视频,同样也是由Sora这个AI来制作完成的,多么逼真。
从ChatGPT到Sora,众多的AI是目前很火热的技术和话题。除了这些投入重金面向全体大众的应用,由于多种原因,爱好者更喜欢使用本地化部署,搭建自己的AI平台,更加贴合和符合自己的需要,通常是使用自己的电脑来完成,其中显卡是最重要的部分,也是俗称生产力的部分。

个人使用电脑搭建平台使用AI绘画,是现在很流行的。使用本地部署的开源平台,例如 “Stable Diffusion” ,就可以进行 AI 绘画,快速出图,哪怕你是没有任何绘画基础,只需要通过文字描述就可以生产图片。当然,出图是简单的,而出好图,出自己想要的图,需要更多的文字研究,以及模型的训练。这个过程有个形象化的名字俗称“炼丹” 。

要“炼丹”炼丹炉是必要的,主要是要用到显卡。想起 显卡AI功能,很多人下意识的以为必须要用N卡,都说A卡玩游戏,N卡生产力,都说AI要用N卡,被这种信息熏陶,我也一直以为,A卡是没有AI功能的。然而事实其实不是这样的,A卡同样有AI功能。

A卡的AI效果,与同价位的N卡其实是差不多的,这主要指的是速度。然而,由于软件方面的原因,之前这个速度是在Linux系统上的结果,而在Windows系统上,速度会较慢。不过在去年,AMD与微软合作优化了 Microsoft Olive 方式之后,彻底释放了 RDNA3 架构显卡的 AI 性能,超高性价比的 RX7900 家族,在Windows上可以实现同 RTX4080 一样的炼丹效率,加上 7900XT 20GB / 7900XTX 24GB 拥有的超大显存,让用户有了更多的选择。让刚刚拥有了7900XT 极地版的我,也燃起了玩AI绘画的欲望。

白色的蓝宝石的新品旗舰显卡RX 7900XT 20G D6极地版OC。显卡整体是白色框架,三个白色风扇,侧面有金属的蓝宝石英文,以及RDNA 3的字样。这款显卡是采用了最新的RDNA 3架构,搭载全新的人工智能加速器,同时提升了第二代的光线追踪技术和第二代的AMD高速缓存技术。

这款蓝宝石RX 7900XT 20G D6极地版OC 更多的技术细节包括:流处理器5376个,共84 CUs,加速频率2450MHz,游戏频率2075MHz。配备20GB的GDDR6显存,位宽320 bit。它采用了14层PCB,保证电气性能。6根复合式热管,每根热管的设计都进行了优化微调,加厚散热鳍片,实现更好的散热。

显卡使用了3枚散热风扇,风扇是双滚珠轴承风扇,寿命更长。扇叶是著名的飞翼轴流扇叶,可折角的扇叶设计可提供双层向下风压与轴流风扇外环的气压一起作用,可大幅增加风压和气流,运行起来更安静且更凉爽。背面有全尺寸的金属背板,全白色,并有多处通透设计,可以增加散热效果。

于是在这举家欢庆的春节时刻,拖着小病初愈的身体,我也来玩玩这“炼丹”之树,看看效果如何。
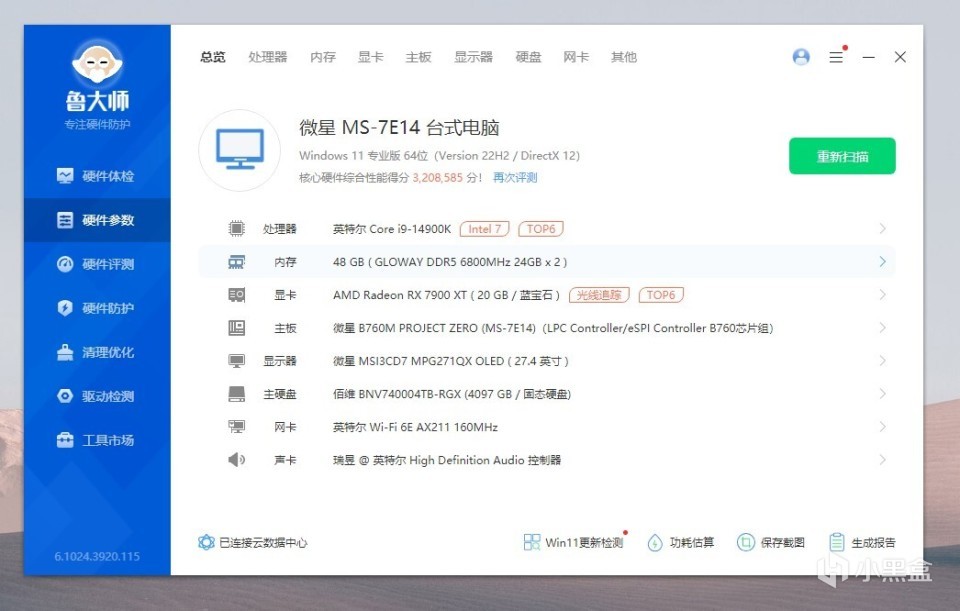
简明描述下电脑配置,CPU是i9-14900K,内存是光威48GB DDR5高频内存(24GBx2),主板是微星的B760M PROJECT ZERO,一款背插主板,显示器是微星的MPG 271QPX QD-OLED,硬盘佰维BNV7400。
“Stable Diffusion” 简称SD,SD炼丹平台的搭建牵扯到许多软件,还有其他因素,是个头疼的地方。好在国内有很多乐于奉献的大神,做好了打包的盒饭,我们只需要下载拿回来吃就可以了,互联网分享精神万岁,感谢“秋葉aaaki” 大神,首先使用的是他做的针对 AMD 显卡的炼丹整合包。
这个是大佬做的启动器,各种设置画面简洁,这个并不是SD的界面。
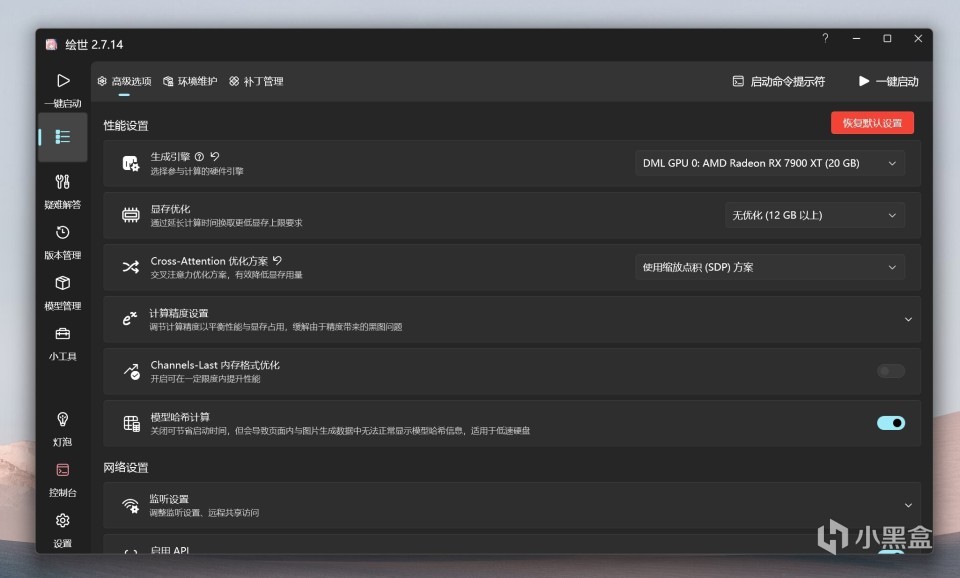
那么在生成引擎里我们选择蓝宝石的这款7900XT极地版显卡,除了显卡,CPU和核显,也是可以绘图的,但是速度就差的太远了。这里有个选项是内存优化,显存容量小的N卡可能需要选择,而A卡通常会显存很大,这里就保持默认不优化就可以了。AI绘画最容易爆显存,所以显存容量大的A卡在这里其实是有它的好处的。
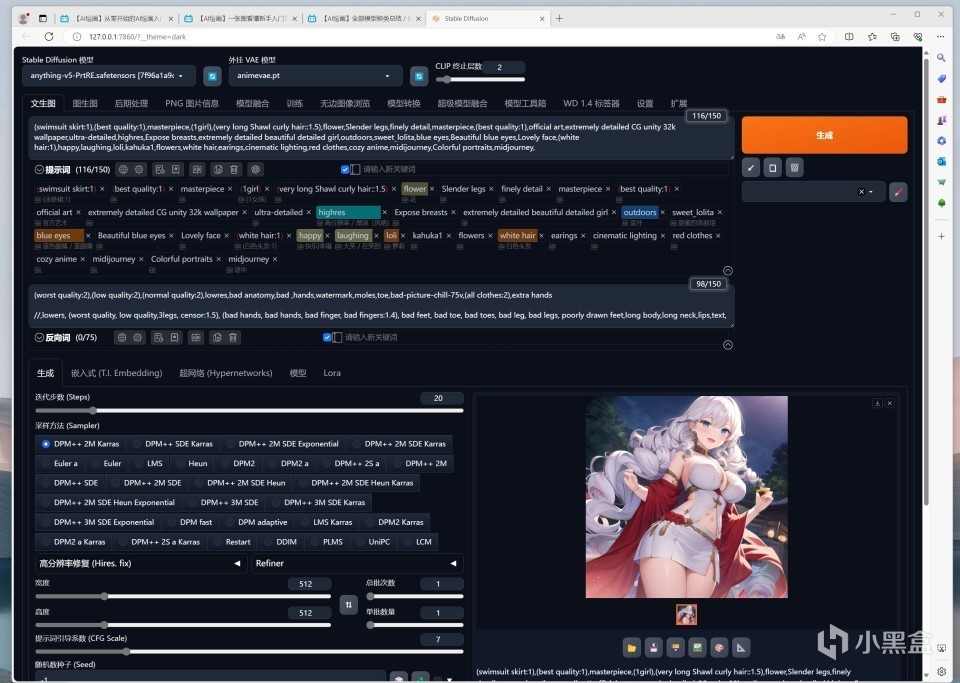
一键启动后,会打开浏览器界面,这里才是SD真正的UI界面,在这里可以有各种设置。包括你希望出图的尺寸,出图的数量,出图的方法、模型等等各种参数。对于我们这个初学者来说,保持默认是个好选择。如果是最常用的文生图的话,所需要做的只是输入提示词。提示词分为正向和反向,正向是绘画的方向、反向是绘画避免的方向。
然后点击生成就可以了,多简单,然后你该干嘛就干嘛,对于我们普通的爱好者来说,足够用了。
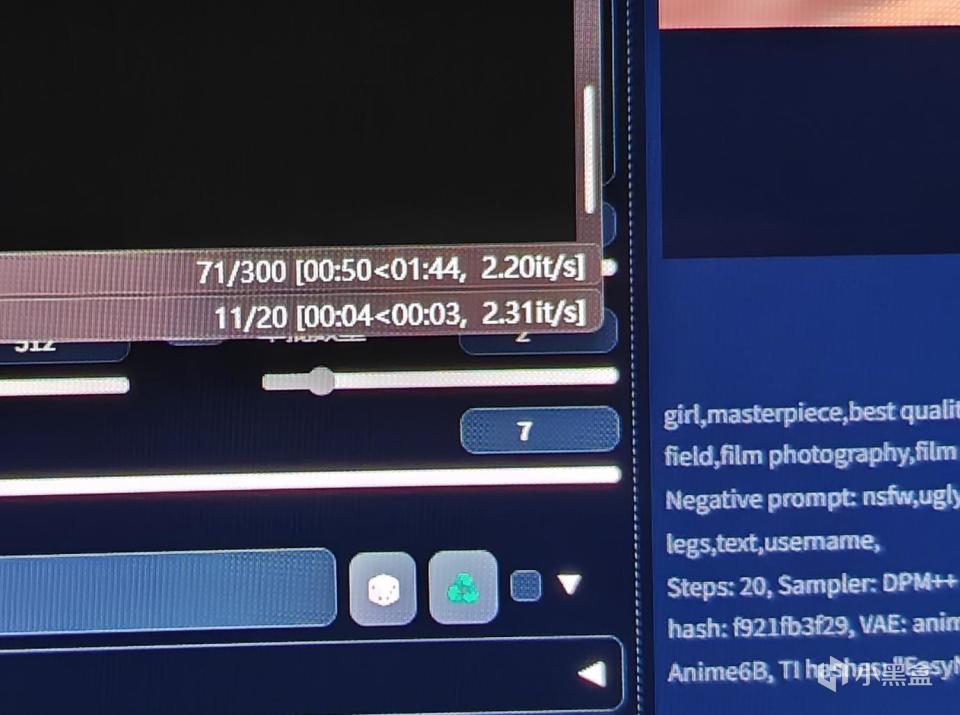
出图的速度,同出图的大小、质量、各种其他参数有关。我们看这里是2.31 it/s,这个单位是每秒迭代次数,次数越多,速度越快。
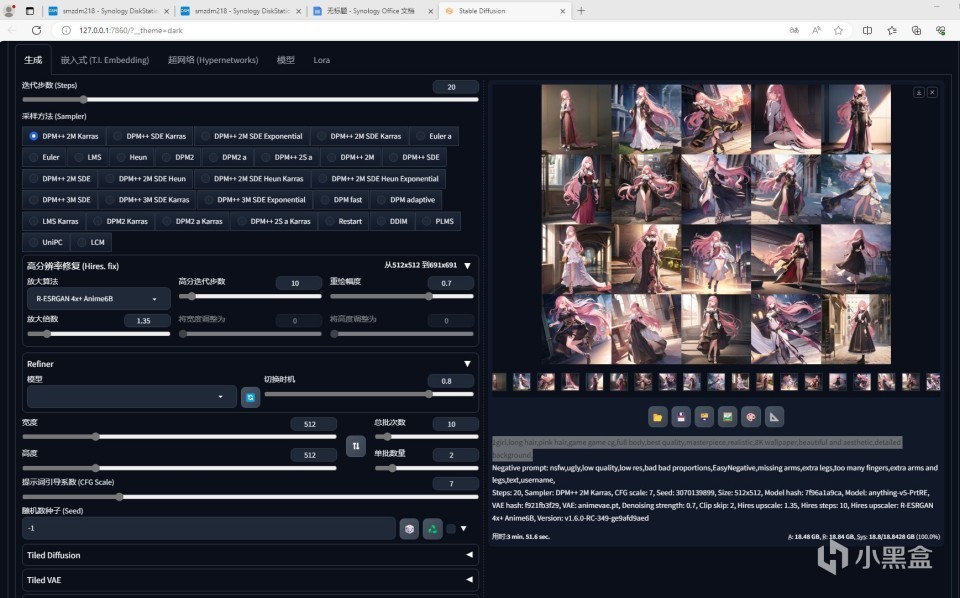
那么在这速度下,一次性出图20张,用时3分钟51.6秒,合算231.6秒。这个方式是采用directML的,并没有利用到olive。
“秋葉aaaki” 大神并没有olive整合包,那么经过本人在网上不断的搜寻资料和研究,终于搞成了olive下的部署,虽然很不完善还有bug,但是起码可以参考下速度了。
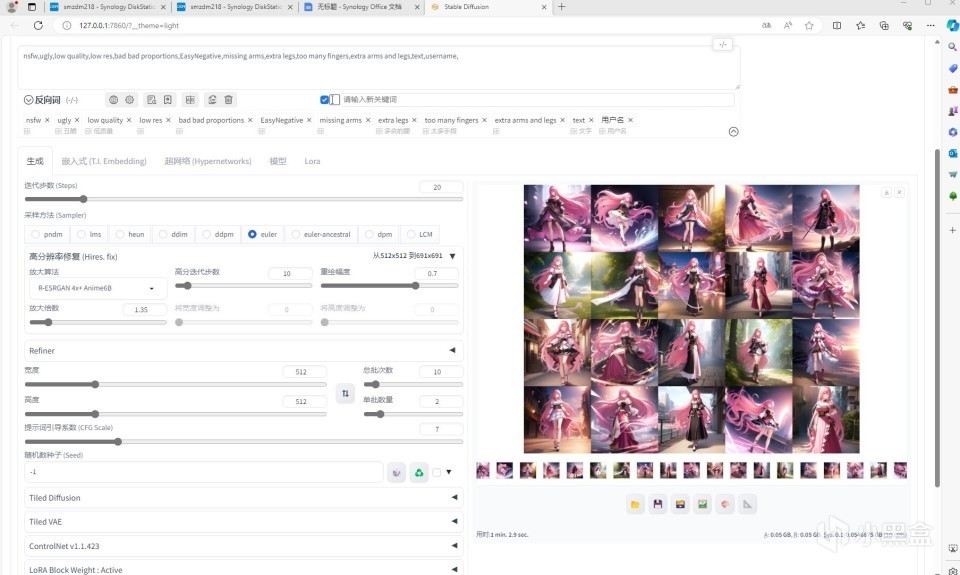
同样是20张图片,用时1分2.9秒,合计62.9秒。
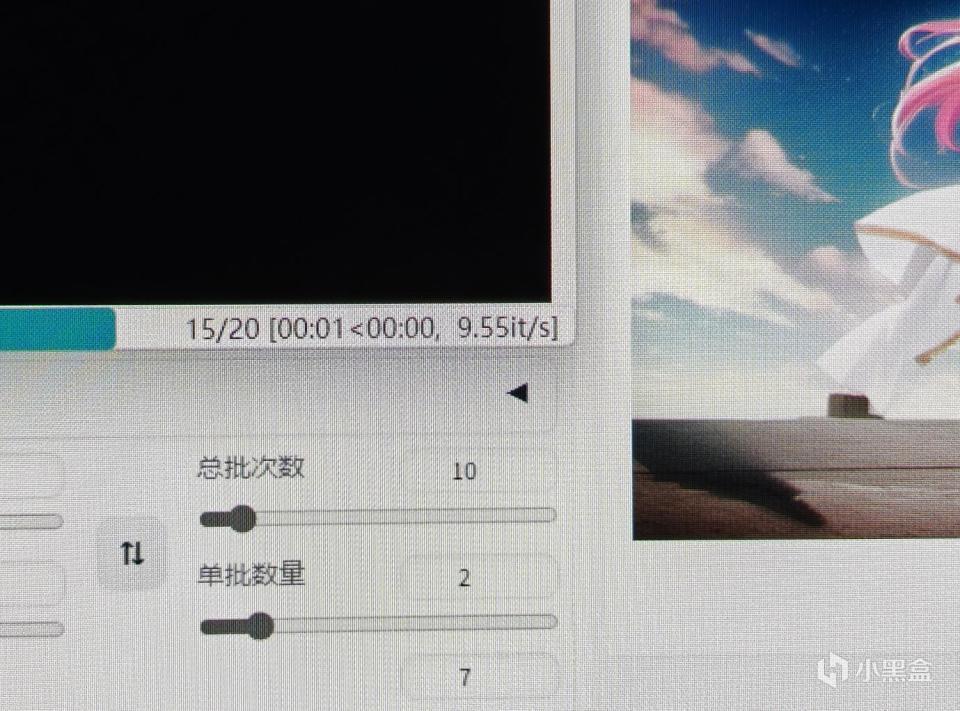
这里出图时的速度是9.55lt/s左右,相对于之前的速度,是4倍多。而总的出图时间,是原来的1/4,可见在最新的AMD与微软合作优化的 Microsoft Olive 方式下,速度大大提高,已经可以快接近linux下的速度了,这对于普通使用Windows的我们来说,的确是个好消息。


上图是2种不同方式的汇总缩略图,可以有个概念。当然,虽然是同样的提示词,2种方式的出图结果和风格还是有点差异的,这个就是需要各种参数细调的部分了,不是我这个刚了解的人所能控制的。

通过上面的实际操作,可以看出,A卡同样具有AI生产力。在 Microsoft Olive 的加持下,AMD RDNA3 架构的7系卡可以释放出它出色的 AI 性能,作为电脑用户,使用A卡同样可以实现AI绘画功能,做到游戏AI两不误。高性价比是永远的追求,而A卡则很大程度上符合这种要求。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















