AI时代最根本的是什么?是算力。
随着AI模型、训练数据规模的不断膨胀,对于算力的渴求也是空前高涨,没有尽头。
强大的AI算力可以来自CPU,可以来自GPU,可以来自FPGA,可以来自ASIC,各有各的优势,其中的王者毋庸置疑就是GPU加速器。
如今的AI GPU加速器市场,呈现着明显的“一家独大、两家追赶”的态势:NVIDIA有着无可比拟的市场地位,尤其是软件生态遥遥领先;AMD、Intel都有各自的独特方案,也都有了不俗的成果。
NVIDIA的大家都比较熟了,Intel的才刚刚起步,今天我们重点聊聊AMD Instinct系列加速器,看看它能不能真正挑战NVIDIA。
毕竟,任何市场领域一家独大,都不是什么好事儿,都需要你来我往的竞争,才是对用户利益、对行业发展最为有利的。

AMD Instinct很多人可能不太熟悉,但其实历史也很优秀了,可以追溯到2017年。
不过那时候,它还叫Radeon Instinct,基础架构也是和Radeon游戏显卡通用的,包括Polaris、GCN、Vega,一直到2020年的RDNA都用过。
这么做的好处是开发成本低、推进速度快,但缺点也很明显,就是在计算方面缺乏针对性和高效率。
2020年诞生的Instinct MI100,成为这条产品线的一个转折点,因为它首次采用了专门设计的CNDA计算架构,和RDNA图形架构彻底分道扬镳,同时去掉了名字中的Radeon字样,踏上了新的征程。

2021年的Instinct MI200系列又达到了全新的高度,这是AMD第一款ExaScale百亿亿次计算性能级别的加速器产品,号称在同类产品中拥有世界上最快的HPC性能、AI性能。
它升级到了第二代CDNA 2架构,首创MCM多芯整合封装,拥有Infinity Fabric高速互连通道、矩阵核心、128GB HBM2e高带宽内存等等,性能异常强大,浮点性能约48万亿次每秒。
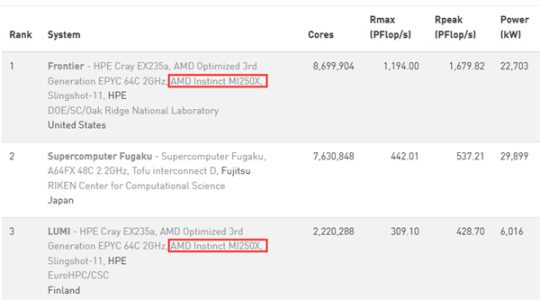
该系列包括MI250X、MI250、MI210三款型号,在诸多高性能计算、机器学习、人工智能、超级计算机中都有普遍应用。
尤其是顶级满血的MI250X战绩彪炳,目前公开性能世界第一、已经三连冠的超算“Frontier”,就是基于它打造的,最大性能高达119.4亿亿次浮点每秒,是第二名的多达2.7倍,峰值性能更是168亿亿次浮点每秒,是第二名的3倍还多!
第三名的“LUMI”同样是采用了MI250X,最大性能30.9亿亿次浮点每秒,峰值性能42.9亿亿次浮点每秒,相当于第二名的七八成。
值得一提的是,韩国电信运营商Kt还使用AMD Instinct平台运行了该国第一个大语言模型,支持110亿参数。


最新一代的Instinct MI300系列再次实现跨越,并开辟了全新的方向,有了两款不同的产品。
其中,MI300A是全球首款面向HPC、AI的APU加速器,基于AMD的成熟经验,开创了CPU、GPU合体加速的先河。
它采用了先进的Chiplet芯粒设计,一共有多达13颗小芯片,其中计算部分9颗,都是5nm工艺制造,基底和扩展部分4颗,都是6nm工艺制造,集成多达1460亿个晶体管。
CPU部分为Zen 4架构,三组CCD共24个核心,GPU为最新的CDNA3架构,还有128GB大容量的HBM3高带宽内存,可以为CPU、GPU所共享。
MI300A使用了标准的Socket独立封装,因此不再需要单独的CPU处理器,自己就能组建一整套加速平台,大大简化系统设计。


MI300X则是纯GPU加速器,相当于把MI300A里的CPU模块也替换成GPU,同时将HBM3内存容量增加到史无前例的192GB,带宽达到惊人的5.2TB/s。
整体集成的晶体管数量,也达到了同样史无前例的1530亿个。
作为对比,NVIDIA最新的H100加速器也只有800亿个晶体管,只有MI300X的一半多点,不在一个层级上。


为方便客户部署,AMD全新设计了Instinct平台,基于行业标准的OCP计算标准,单系统可集成最多八块OAM形态的MI300X,HBM3内存总容量达1.5TB。
Instinct MI300系列也已经开始投入商用,比如美国劳伦斯利弗莫尔实验室的新一代超级计算机EI Capitan,已开始安装MI300A加速器,搭档第四代AMD EPYC处理器。
它将在明年上线,预计性能超过200亿亿次浮点计算每秒,也就是可以超越当今第一的Frontier。
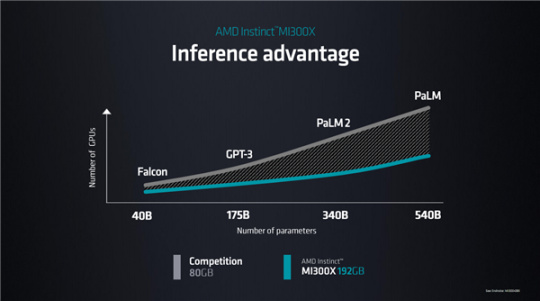
MI300X的强劲性能和超高能效,使之可以轻松应对当今AI对强算力的需求,搞定各种几百上千亿参数的大语言模型,Falcon、GPT-3、PaLM 2、PaLM等等都不在话下。
甚至,MI300X单卡就能运行800亿参数的大语言模型,尤其是得益于超大容量的HBM3内存,大模型可以完全在HBM3内存中运行,无需动用系统内存,从而省去数据传输与拷贝,大大降低延迟、提升性能。
相比于 NVIDIA 80GB HBM内存加速器,运行同样参数规模模型,MI300X所需要的GPU数量也更少,自然成本更低。
更关键的是,NVIDIA H100/A100加速器过于火爆,价格一路飙升,比如应用最多的H100目前已经要到4.5万美元一块,相当于30多万人民币,新一代的A100也需要十几万。
甚至,就算你舍得花钱,也不一定买到。负责代工的台积电也承认,H100/A100的紧缺状况还要持续大约一年半之久。
相比之下,AMD的一贯优良传统恰恰就是高性价比,正好可以给客户提供更丰富的选择空间,而不是吊在一棵树上。

当然了,作为AI加速器,不但需要硬件设计强大,更需要足够高效的开发平台、足够优化的软件和应用适配,才能彻底释放潜力。
NVIDIA在这方面无疑做得相当透彻,这也是其赢得开发者和市场的一大关键。
AMD ROCm开发平台同样历史悠久,只是在技术特性、生态适配上一直有待进一步拓展,而今在AI的驱动下正在努力追赶。
比如新一代ROCm 5.x版本,针对HPC、AI做了全方位优化,支持各种流行的AI模型、框架和算法,诸如PyTorch、TensorFlow、ONNX、OpenXLA、Triton、DeepSpeed……方便开发者根据自己的实际需要选择,灵活满足不同场景。
值得一提的是,现在部署MI210,AMD还会提供软件层面的搭建支持,让客户的安装、使用更加简单、省心。

说到这里顺带一提,除了高性能计算GPU方面,AMD还正在不断释放消费级游戏GPU的AI潜力,比如大火的文生图应用Stable Diffusion,已经可以在Windows系统下跑在AMD Radeon显卡上。
如今,你可以在Automatic1111(Xformer)下使用微软的Microsoft Olive(一个可用于转换、优化、量化和自动调整模型以通过DirectML等ONNX运行时执行提供程序获得最佳推理性能的Python工具),来启用Stable Diffusion,从而在Windows系统上通过Microsoft DirectML,获得显著的加速。
AMD也一直在与微软合作优化AMD硬件上的Olive路径,通过微软DirectML API,以及用于DirectML的AMD用户模式驱动程序的ML层加速,从而允许用户访问AMD GPU的AI功能和性能。
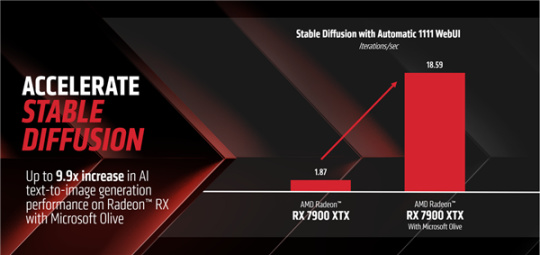
按照AMD实测的数据,RX 7900 XTX在默认PyTorch路径上运行,每秒可提供1.87次迭代,而换到Microsoft Olive的优化模型上运行,每秒可提供18.59次迭代,也就是性能提升多达9.9倍!
相信像这样的生态适配和合作,未来势必也会越来越多地体现在AMD Instinct上。
最后,AMD Instinct还有一个任何对手都无法匹及的优势,那就可以是背靠完整的AI产品矩阵,提供一整套一站式解决方案。
尤其是高性能的EPYC处理器,经过几年的迭代,计算性能已经遥遥领先,新一代EPYC 9004系列已经升级到Zen 4架构、96核心192线程、12通道DDR5内存、160条PCIe 5.0总线,还衍生出了Zen 4c高能效核心、3D V-Cache 1GB+缓存等不同版本。
事实上,当今的众多高性能计算平台尤其是超级计算机,都部署了AMD EPYC、AMD Instinct这一对黄金组合,效果拔群,在各种科学与学术研究中贡献力量。

总的来说,在这个AI蓬勃发展的时代,对于强大算力的需求只会越发高涨,其中蕴含着前所未有的机遇。
NVIDIA的强大和领先毋庸置疑,软硬件结合更是做得十分到位,但一花独放不是春、百花齐放春满园,我们同时也非常希望AMD、Intel能把握住这个风口,拿出同样优秀的方案,让开发者和用户受益。
AMD更是尤为值得期待。Instinct系列加速器发展多年,屡屡实现创新突破,性能上绝对不是问题,能在超算的世界里脱颖而出就是明证,只要在开发和生态上多下一番功夫,势必更受欢迎。
同时,AMD还有着全套解决方案的支撑,特别是强大的EPYC处理器现在让Intel都不得不仰视,可以和Instinct珠联璧合,再加上一贯以来的高性价比,前途必然是相当光明的。

更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















