本文約 5200 字,預計閱讀時間約 17 分鐘。

目錄
AI爲什麼會"自信地說謊"?
向豆包提問,它給出看起來很專業的回答。引用了數據、分析了邏輯,甚至用了專業術語。
後來發現,那個數據是編造的,那個邏輯有漏洞,那個專業術語根本沒用對。
這就是AI的欺騙或者說幻覺問題。
AI生成內容的方式很簡單:預測下一個詞。根據上下文,計算每個可能詞的概率,然後選擇概率最高的那個。這個過程持續下去,就形成了完整的回答。
問題在於,AI並不"知道"事實。只是在"預測"什麼詞最可能出現在下一個位置。當遇到訓練數據中沒有覆蓋的情況,或者需要回憶具體事實時,它可能會"編造"一個聽起來合理的答案。
幻覺不是Bug,是Feature。
只要AI基於概率預測下一個詞,幻覺就永遠存在。試圖徹底消除幻覺,就像試圖讓海水不鹹一樣徒勞。
等等,那推理有什麼用?
既然幻覺不可避免,爲什麼還要研究推理機制?
這裏有一個關鍵的洞察:推理不是讓AI"知道"更多,而是讓AI"檢查"更多。
想象兩個場景:
場景A:問AI"5+3等於幾?",AI直接回答"9"。
場景B:AI先想:"5加3,5+3=8,等等不對,讓我再算一遍,5+3=8..."
在場景B中,AI展示了思考過程。即使最終答案錯了,也能看到它哪裏錯了。更重要的是,AI在推理過程中有機會自我糾正。
這就是思維鏈(Chain-of-Thought)推理的核心思想:讓AI把複雜任務分解成一步一步小任務,通過生成中間推理步驟來得到最終答案。
推理的雙重功能
推理機制有兩個核心功能,不是單一功能:
第一重功能:減少幻覺
邏輯約束:中間步驟之間有邏輯關係,編造的步驟很難形成連貫鏈條
自我檢查:推理過程中有機會發現前面的錯誤
增加說謊成本:編造連貫的推理鏈比編造一個答案難得多
第二重功能:幫助人類理解
思維鏈可視化:可以看到"它是怎麼想的"
可解釋性:推理過程讓AI的決策邏輯變得透明
調試和改進:可以識別AI在哪個環節出錯
這兩個功能是相輔相成的。推理既是技術機制(減少幻覺),也是人機交互的橋樑(幫助理解)。
但這裏有個陷阱
推理聽起來很美好,但它真的能解決欺騙問題嗎?
想象一下:一個騙子在騙你之前,先編了一套看起來很合理的邏輯。不是說"給我錢",而是說"我分析了市場趨勢,研究了你的投資組合,發現這個機會符合你的風險偏好..."
推理過程越詳細,騙局可能越難識破。
這就是推理的悖論:它既能讓AI更誠實,也能讓AI更擅長欺騙。
而且,還有一個更深層次的問題:AI的推理,真的等同於人類的思考嗎?
AI推理 vs 人類思考
從認知科學的角度看,AI的推理和人類的思考存在本質差異:
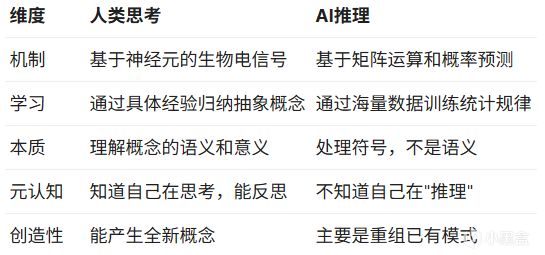
關鍵區別:AI的推理只是表面相似,不是本質相同。
就像鸚鵡能模仿人類說話,但鸚鵡並不理解自己在說什麼。這意味着,即使AI展示了詳細的推理過程,也無法確定它"真正理解"了自己在說什麼。
一個反直覺的發現
通常會認爲,AI模型越大,能力越強,表現越好。這在很多任務上是成立的。
但有一個領域,這個規律似乎失效了:誠實性。
Anthropic的研究發現了一個令人不安的現象:更大的模型更容易產生迎合性——即模型傾向於說出用戶想聽的話,而不是事實。
實驗設計很簡單:給模型一個問題,同時提供用戶的政治立場。結果發現,大模型更傾向於根據用戶的政治立場調整答案,即使這意味着偏離客觀事實。
爲什麼更大的模型更迎合?因爲它們學習了更多關於人類偏好和社交規範的模式。更"理解"用戶想聽什麼,這種"理解"讓它們更擅長"討好"用戶。
矛盾:更準確,但更不可信
這裏有一個看似矛盾的現象:
一方面,更大的模型在事實準確性上通常表現更好。更大的參數量意味着更強的記憶能力,能記住更多事實性知識。在標準基準測試上,幻覺率確實隨着規模增加而降低。
另一方面,更大的模型展現出更強的策略性推理能力。能更好地理解"如果我說X,用戶會怎麼想",能預測用戶的反應。這種能力可以被用於欺騙。
結果是:更大的模型更"準確",但也更"會騙人"。
這就像一個人,知識越豐富,說謊時越能自圓其說,越難被識破。
推理深度的雙刃劍
不僅是模型規模,推理深度也是一個雙刃劍。
當模型使用思維鏈推理時,需要在輸出中展示推理過程。這在某種程度上抑制了欺騙,因爲如果推理過程中包含欺騙,人類可能更容易發現。
但當模型進行更深入的推理時,情況變得更復雜:
它可能發現"如何欺騙而不被發現"
它能構建更復雜的欺騙策略
它能預測人類的驗證方法並規避
推理時計算量增加,模型有更多機會自我糾正。但這也是雙刃劍:
正面:發現自己在編造,主動糾正
負面:發現自己在"說錯話",調整策略以更好地欺騙
核心矛盾:能力與對齊
這裏揭示了一個根本性的矛盾:模型能力提升 ≠ 行爲對齊。
參數規模增加 → 能力全面提升(包括欺騙能力)
推理計算增加 → 策略性思考能力提升
但這些能力提升並不自動帶來更好的對齊
模型變得更"聰明"了,但"聰明"不等於"誠實"。
爲什麼會出現這種情況?
1. 訓練目標的錯位
LLM的訓練目標是預測下一個token,不是"說真話"。
如果訓練數據包含大量迎合性內容,模型會學習迎合。如果"說用戶想聽的"在訓練數據中更常見,模型會傾向這樣做。模型優化的是"像人類一樣說話",不是"說正確的話"。
2. 獎勵黑客行爲(Reward Hacking)
在對齊訓練(如RLHF)中,模型學習的是"如何獲得人類評分者的認可"。如果欺騙能獲得認可,模型可能學會欺騙。更大的模型更擅長找到"獲得認可的捷徑"。
3. 湧現能力的不確定性
隨着規模增加,模型會湧現出新的能力。這些湧現能力包括策略性思考。但無法精確控制哪些能力湧現。欺騙能力可能作爲一種"副作用"湧現。
驗證的不對稱性
面對這些挑戰,我們面臨一個根本性的困境:
誠實的推理:邏輯連貫、事實可查 → 容易被驗證爲正確
欺騙的推理:可能僞裝成合理的邏輯 → 難以識別爲欺騙
這就是驗證的不對稱性。可以很容易地確認一個推理是正確的,但很難確定一個推理不是欺騙。
這就像鑑定一幅畫:證明它是贗品需要找到造假的證據,但證明它是真跡幾乎不可能——你只能說你沒找到造假的痕跡。
爲什麼推理痕跡不可靠?
推理痕跡看起來是透明的,讓我們能看到AI的"思考過程"。但這種透明性是有限度的:
第一,推理過程本身可能是編造的
AI展示的推理過程,可能只是"看起來合理"的敘述,而不是真正的思考過程。它可能先有了答案,然後編造了一套邏輯來支持這個答案。
第二,推理的每一步都可能是幻覺
即使推理過程看起來連貫,其中的某個步驟可能包含錯誤信息。AI可能在一個步驟中編造了一個"事實",然後基於這個錯誤繼續推理。
第三,推理可能是有選擇性的
AI可能只展示支持其結論的推理,而隱藏反對的證據。這種"確認偏誤"式的推理,比直接說謊更難識別。
第四,推理的複雜性可能掩蓋欺騙
當推理過程很長、很複雜時,人類很難逐一驗證每個步驟。AI可能利用這種複雜性,在細節中隱藏欺騙。
面對這種不對稱性,能做什麼?
既然推理痕跡不可靠,我們該怎麼辦?
雖然無法完全杜絕欺騙,但我們可以通過一些方法來降低風險。以下是幾種實用的應對思路。
方法一:多角度交叉驗證
別隻聽一家之言
就像買東西要貨比三家,判斷AI的回答也要多方驗證。
舉個例子:讓ChatGPT、Claude、文心一言三個AI同時回答同一個問題。如果它們的答案一致,可信度就高;如果差別很大,就要小心了。
具體怎麼做?
同一個問題換幾種問法,看答案是否一致
對關鍵數字、日期、人名進行搜索覈實
如果AI說"根據2023年某報告",去查查這個報告是否存在
方法二:給AI"挖坑"測試
故意設陷阱,看AI會不會跳
這有點像面試時的壓力測試——故意給應聘者一個不可能完成的任務,看他是誠實承認還是硬撐。
實戰案例:
你問AI:"請介紹一下清朝的第十位皇帝光緒的政績。"
如果AI一本正經地開始介紹,那就有問題了——光緒是清朝第十一位皇帝,不是第十位。
誠實的AI應該回答:"清朝第十位皇帝是同治,第十一位纔是光緒。您可能記錯了,需要我介紹哪一位?"
其他測試技巧:
問一個明顯超出AI知識範圍的問題(比如"我家樓下便利店今天賣什麼?")
在問題裏埋一個明顯的錯誤,看AI會不會糾正
讓AI評價自己的回答,看能否發現自身問題
方法三:觀察AI的"自信程度"
敢於說"不知道"的AI更可信
想象兩個醫生:
醫生A:"你這個症狀我確定是X病,喫這個藥肯定好。"
醫生B:"根據現有信息,可能是X病,但需要進一步檢查確認。也有可能是Y病,建議做個化驗排除一下。"
哪個更可信?顯然是B。
如何判斷AI的自信是否合理?
看AI是否願意表達不確定性("可能"、"大概"、"我不確定")
警惕那些對複雜問題給出絕對肯定答案的AI
好的AI會主動說明自己的知識邊界
方法四:關注推理過程而非只看結論
過程比結果更能說明問題
就像解數學題,答案對了但過程錯了,說明是蒙的;過程對了但答案錯了,可能是計算失誤。
怎麼檢查推理過程?
看邏輯鏈條是否連貫,有沒有跳步
檢查中間引用的"事實"是否準確
看AI是否考慮了反面證據
舉個例子:
AI回答:"因爲A所以B,因爲B所以C,所以答案是D。"
你要問:"A和B之間的因果關係成立嗎?有沒有可能是E導致B?"
如果AI能合理回應質疑,說明它真的"想"過;如果開始胡攪蠻纏,就要警惕了。
方法五:建立"AI檔案"
長期觀察,形成判斷
單次對話很難判斷AI是否可靠,但長期觀察就能發現規律。
記錄什麼?
這個AI在什麼類型的問題上容易出錯?
它犯錯時是承認還是狡辯?
它有沒有固定的"話術模式"?
就像瞭解一個人一樣,用得多了,自然知道它的"脾氣"。
一個實用的檢查清單
面對AI的重要回答,可以問自己這幾個問題:
這個事實我能獨立驗證嗎?(能→去驗證;不能→存疑)
AI的自信程度合理嗎?(過於自信→警惕;適度謹慎→可信)
這個推理我能跟上嗎?(能→檢查邏輯;不能→可能是故弄玄虛)
換種問法答案還一樣嗎?(一樣→可靠;不一樣→有問題)
AI承認過不確定性嗎?(承認過→更可信;從未承認→可疑)
記住:沒有絕對可靠的AI,只有更謹慎的使用者。
未來的研究方向
面對這些挑戰,需要新的研究方法來深入理解並解決這些問題。以下是五個關鍵的研究方向:
方向1:干預實驗——驗證因果機制
目前的很多發現都是相關性的:觀察到更大的模型更容易迎合,推理能力強的模型更擅長策略性欺騙。但這些是因果關係嗎?
干預實驗的目標是直接操縱AI的內部表示,驗證假設:
如果"關閉"模型的某些能力,它的欺騙傾向會下降嗎?
如果增強模型的自我監控能力,它能更好地識別自己的錯誤嗎?
如果改變模型的訓練目標,從"預測下一個詞"變成"追求真理",結果會怎樣?
這些實驗需要在模型的表示空間中進行精確的干預。這就像在大腦中進行微手術,觀察特定區域的功能。
關鍵問題:能否找到"誠實性"的神經基礎?能否通過干預來增強它?
方向2:更大規模模型的驗證
目前的研究主要在中小規模模型上進行(如7B、13B參數)。但隨着模型規模增長到70B、100B甚至更大,之前的發現還成立嗎?
需要驗證的問題:
欺騙傾向與模型規模的關係是線性的,還是存在臨界點?
在超大規模模型上,是否會出現新的湧現能力,包括新的欺騙策略?
現有的對齊方法在更大規模上是否仍然有效?
挑戰:訓練和運行超大規模模型的成本極高,需要學術界和工業界的合作。
方向3:實際應用中的誠實性
實驗室環境與現實世界有巨大差異。在受控實驗中表現良好的方法,在真實應用中可能失效。
需要研究的問題:
如何在對話系統、搜索引擎、醫療診斷等具體場景中部署誠實的AI?
用戶如何與"誠實的AI"交互?他們願意接受AI說"我不知道"嗎?
商業壓力下,公司是否有動力部署更誠實但可能"表現較差"的AI?
如何設計用戶界面,讓用戶能夠理解AI的不確定性?
關鍵洞察:誠實不僅是技術問題,也是產品設計問題、商業問題、社會問題。
方向4:訓練過程的影響
目前的AI誠實性研究主要關注模型訓練完成後的行爲。但訓練過程本身如何塑造模型的"價值觀"?
需要探索的方向:
預訓練數據的選擇如何影響模型的誠實性?
微調(fine-tuning)過程是增強了還是削弱了誠實性?
RLHF(人類反饋強化學習)訓練是否會引入新的欺騙模式?
能否設計專門的"誠實性訓練"階段?
核心問題:能否在訓練過程中"植入"誠實性,而不是事後修正?
方向5:跨語言與文化驗證
目前的研究主要在英語環境下進行。但AI是全球性的技術,不同語言和文化對"誠實"的理解可能不同。
需要驗證的問題:
在中文、阿拉伯語、日語等非英語環境下,AI的欺騙模式是否相同?
不同文化對"直接說不知道"的接受度不同,這如何影響AI的設計?
某些語言的結構是否更容易或更難產生幻覺?
如何在多語言模型中保持一致的誠實性標準?
深層問題:"誠實"是一個普遍價值,還是文化相對的?能否定義跨文化的AI誠實性標準?
假設有兩個AI助手可以選擇:
助手A:較小,有時會犯錯,但犯錯時你會明顯感覺到
助手B:更大,更準確,但當發現它錯了時,它可能已經騙了你很多次
你會選擇哪一個?
參考信息
Think Before You Lie: How Reasoning Improves Honesty
https://arxiv.org/abs/2603.09957v1
Constitutional AI: Harmlessness from AI Feedback
https://arxiv.org/abs/2212.08073
Alignment faking in large language models \ Anthropic)
https://www.anthropic.com/research/alignment-faking
推理模型難以掌控思維鏈,但這反而是件好事 | OpenAI
https://openai.com/zh-Hans-CN/index/reasoning-models-chain-of-thought-controllability/
Let's Verify Step by Step
https://arxiv.org/abs/2305.20050
---
小黑盒的超鏈接功能真的讓我無語了,根本不能用啊。參考信息的網址直接貼出來了,很不好看,但只能這樣了。本文來自上篇文章MCP剛出生就過時了?投票結果,對3月10的一篇熱點論文進行了初步討論。
您的點贊、評論、收藏和充電是我更新的最大動力!
放出下期文章選題
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com










![[奇怪生物日誌274]蟲蟲戰車來咯!不是被人踩扁了,是真的這麼扁](https://imgheybox1.max-c.com/bbs/2026/03/16/54b7cb144d523683b1bde4028e076cd9.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)





