引言:跨越三十年的独显远征
在半导体发展的长河中,英特尔对独立显卡的执念可以追溯到上世纪 90 年代。从最初本打算切入 RISC 市场的 i860 但是最终作为图形工作站加速器,从 1998 年昙花一现的 i740,再到后来试图通过多核心通用架构重塑图形领域的 Larrabee 项目,英特尔经历了无数次的探索与蛰伏。
直到 2018 年,代号 Arctic Sound 的现代独立 GPU 计划正式启动,才真正开启了 Xe 架构的纪元。
经过第一代 Alchemist(代号 DG2/Xe1) 的“破冰”尝试,英特尔在视频编解码和基础光栅化领域站稳了脚跟。而今天,我们迎来了代号为 Battlemage(代号 Xe2) 的第二代图形架构。如果说 Xe1 是英特尔独显的“初试啼声”,那么 Arc Pro B60 所承载的 Xe2 架构,则是其在图形效能、AI 推理和专业工作流领域真正走向成熟的标志。
Xe2 (Battlemage) 微架构深度剖析——精算的艺术
Xe2 架构并非简单的规模扩大,而是从指令分发、矢量执行、光线追踪到几何剔除机制的全面重构。
XVE 矢量的革新:从 SIMD8 到原生 SIMD16
在 Xe1 架构中,英特尔的矢量引擎(XVE)主要基于 SIMD8 构建。虽然支持 co-issue(并行发射),但在处理高负载渲染任务时,硬件利用率仍有提升空间。 Xe2 架构 实现了底层执行逻辑的飞跃:它将计算资源重新划分为原生的 SIMD16 指令宽度。这意味着单个指令可以同时处理 16 个数据元素,不仅提高了硬件的吞吐能力,更改进了工作分发(Work Distribution)的均衡性。
Xe2 的 “3 路并行发射”(3-way co-issue) 机制让内核能在一个时钟周期内同时处理:
• 1 路浮点指令(FP)
• 1 路整数或扩展数学指令(INT/EM)
• 1 路 XMX AI 矩阵指令
这种设计让 Xe2 在处理现代混合渲染负载(即同时涉及数学模拟、光栅化和 AI 增强)时,单核 IP 效能相较 Xe1 提升了 1.2x 至 12.5x 之多。

指挥权的移交:硬件原生 Execute Indirect
这是 Xe2 架构最具前瞻性的改进。在传统 D3D11 或早期 D3D12 环境中,每一个绘制调用(Draw Call)或者说绘制任务都必须由 CPU 循环发出。如果场景中有成千上万个物体,CPU 就会遇到极高的 CPU Overhead(递交开销)。
Xe2 架构通过硬件原生支持 Execute Indirect(间接执行) 彻底改变了这一点。
间接执行实现原理并不复杂,它允许 GPU 从名为 IAB(Indirect Argument Buffer)的显存缓冲区中直接读取绘制或分发参数,无需 CPU 事无巨细地参与指令生成。
异步 GPU 剔除 (Asynch Culling):配合异步计算,GPU 可以在正式绘制前自行判断哪些三角形是不可见的(视锥体外、背面或被遮挡),并生成精简后的索引缓冲区。
带来的好处:这种“工作负载延迟决定(Defer the Workload)”的模式,对于拥有 100 到 200 个动态角色的复杂场景,能节省大量的冗余计算,将每一份算力都精准花在最终的屏幕像素上。
光线追踪单元 (RTU) “线程排序”
光线追踪最大的敌人是“不确定性”——当光线撞击不同物体反弹后,计算任务会变得极度碎片化,导致 GPU 的 SIMD 利用率直线下降。
Xe2 架构在第二代 RTU(光线追踪单元) 中引入了线程排序单元(TSU),能达到类似 NVIDIA SER 的效果。
TSU 能够自动对发散的光线线程进行重新排列,将命中相似材质、执行相似代码的线程凑在一起重新发射。配合每周期两次三角形求交和 18 次包围盒求交的高性能,Xe2 在专业可视化应用中的光线追踪效率得到了质的提升。
Xe2 RTU 的 BVH Cache 也提升到了 16KiB,是上一代的两倍。
Battlemage Arc Pro :用尽显存红利!
Intel 在 2024 年 12 月 3 日正式发布 Arc B 系列游戏显卡,型号包括 B580、B570,凭借可以和 RTX 4060 一较高下的表现,产品成熟度已经获得了不少好评,特别是光线追踪性能较同级的 AMD 显卡领先不少,成为入门级性能显卡的有力竞争者。
而 Arc Pro B 系列工作站显卡则是 2025 年发布,目前有两款产品,分别是主要面向图形工作站的 Arc Pro B50 和兼顾 AI 推理的 Arc Pro B60。
其中 Arc Pro B60 的 Intel 官方规格是单 GPU 版本,但是由于 Intel并不打算自己卖卡,所以大家看到的 Arc Pro B60 都是第三方厂家推出的,而且相对于单 GPU 版本,Intel 更鼓励厂商推出双 GPU 版本。
铭瑄 Arc Pro B60 DUAL 48 GB实测
我们这次借到的就是两片双 GPU 版本的铭瑄 Arc Pro B60 DUAL 48 GB,属于目前 Battlemage 家族里的最强档,主要面向图形、推理和边缘工作站市场。
铭瑄这款 Arc Pro B60 DUAL 由两个 B60 GPU 组成,每个 GPU 拥有 20 个 Xe2 内核(对应 NVIDIA SM)、160 个 XMX AI 引擎(对应 NVIDIA Tensor Core,Arc Pro B60 INT8 张量性能可达到 197 PFLOPS)、20 个光线追踪单元(RTU),拥有 192-bit 内存总线(每个 GPU 有 24GB 显存,合计 48GB 显存),集成了两个 MFX 视频编解码器,PCIE 规格为 PCIE Gen5*8。
为了便于在对流环境相对较差的多卡工作站里安装,铭瑄 Arc Pro B60 采用了双槽散热器+鼓风机主动散热方式,卡体长度尺寸为 300mm。
铭瑄标注的单卡(双 GPU) TBP 值为 400 瓦,双卡(4 GPU)的话可以部署 Deepseek-R1 Llama 70B FP8 量化版模型,能支持超长上下文。
显示输出方面提供了两个 DP 2.1 UHBR20 和两个 HDMI 2.1a,可以满足工作站显示输出需求,单根线缆就能提供 8K60Hz HDR 显示输出或者同时驱动三台 4K60 HDR 显示器。
如果只是作为计算、渲染用途的话,铭瑄 Arc Pro B60 也支持无头模式(不连接显示器),可以在纯文本启动的 Linux 系统里提供纯粹的强大计算性能。
测试之前,有必要介绍一下测试平台。这次下血本用上了旗舰配置的ThinkStation P7工作站,这套方案由联想与阿斯顿马丁联合设计,工作站本身可以支持3张双槽位涡轮风扇显卡,因此装下两张铭瑄Intel Arc Pro B60 Dual毫无问题。只需要将末端的限位扣提起,装入显卡后再将限位扣压紧,显卡即可完成。
为了释放4个Intel Arc Pro B60 GPU全部性能,我们使用了一块Intel Xeon W9-3495X搭配W790芯片组主板。
惯例先给大家数个框框。
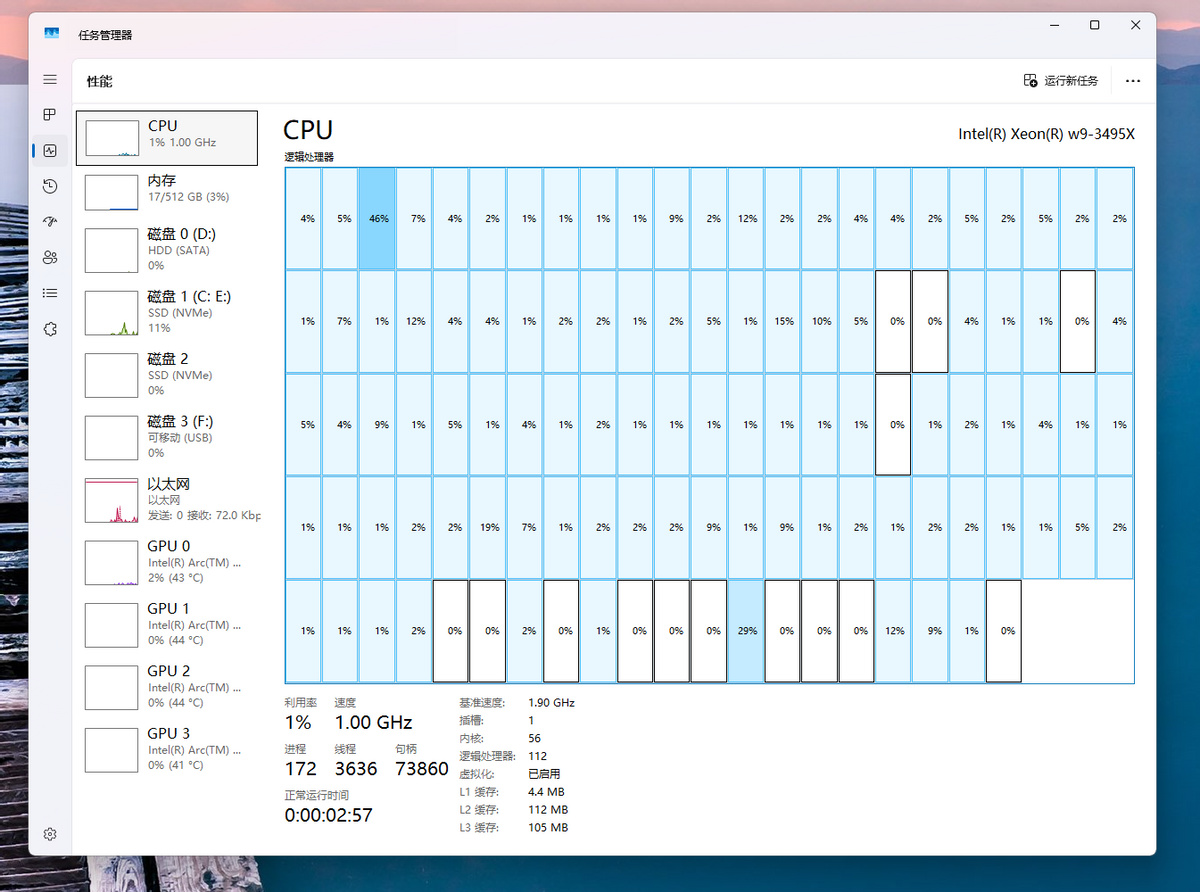
得益于英特尔至强Sapphire Rapids CPU本身强大的扩展能力,我们将8个内存通道插满,单条64GB DDR5-5600,8条共计512GB内存。再配合两块三星2TB SSD和一块HDD,这套测试平台时至今日已经悄咪咪的往20万元的价格奔赴了。
来看看壮观的内存条。
最后是在Windows 11环境下,安装驱动后,4个Arc Pro B60 GPU被正确识别。有意思的是,虽然在BIOS中开启了Resizable BAR,但是在Windows驱动中会有2个GPU的Resizable BAR被识别没有被开启,但在Ubuntu中没有这个问题,因此不影响后续我们在Ubuntu中进行的测试。
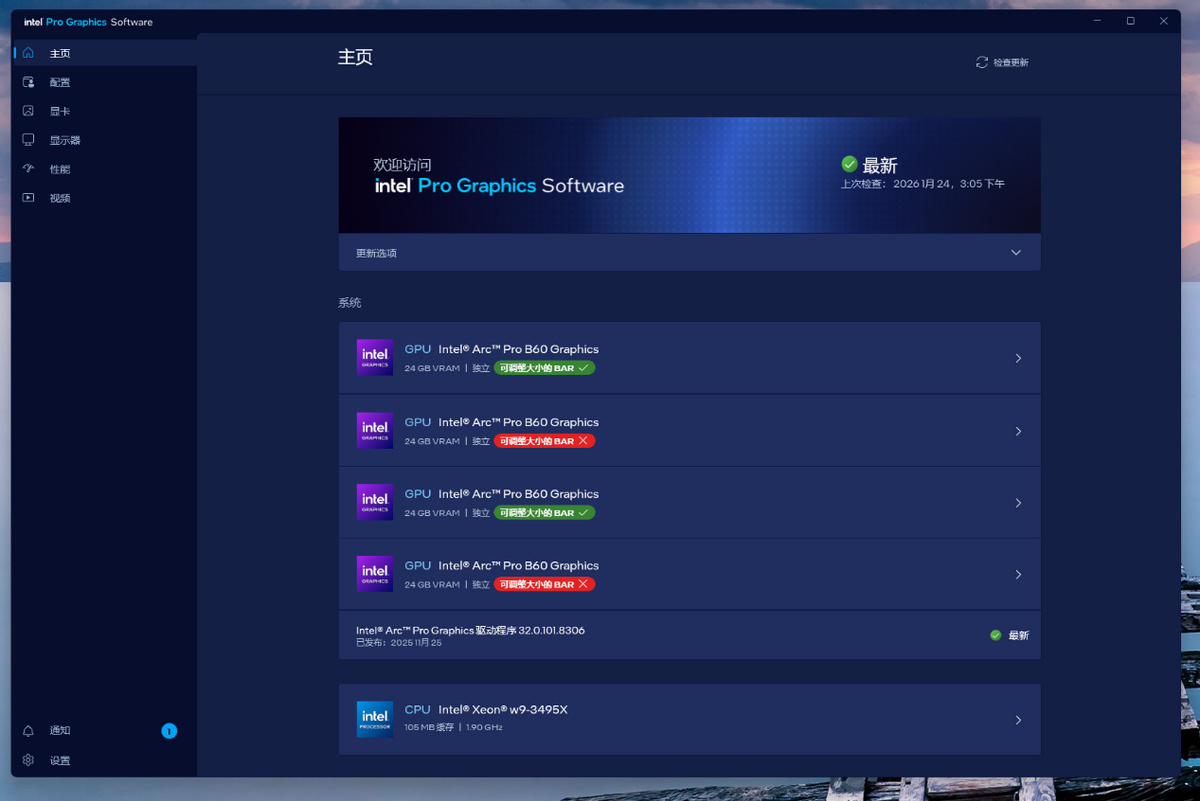
流畅的开箱即用
软件安装
在软件支持方面,Intel 目前提供了 LLM-Scaler 和 LLM-Scaler Omni,LLM-Scaler是英特尔提供的vLLM Serfving镜像版本,和开源的vLLM Serving是统一的,是Intel针对生成式AI推理的性能优化解决方案。LLM-Scaler Omni是支持多模态模型的推理框架,也是LLM-Scaler发布的另一个Docker镜像。
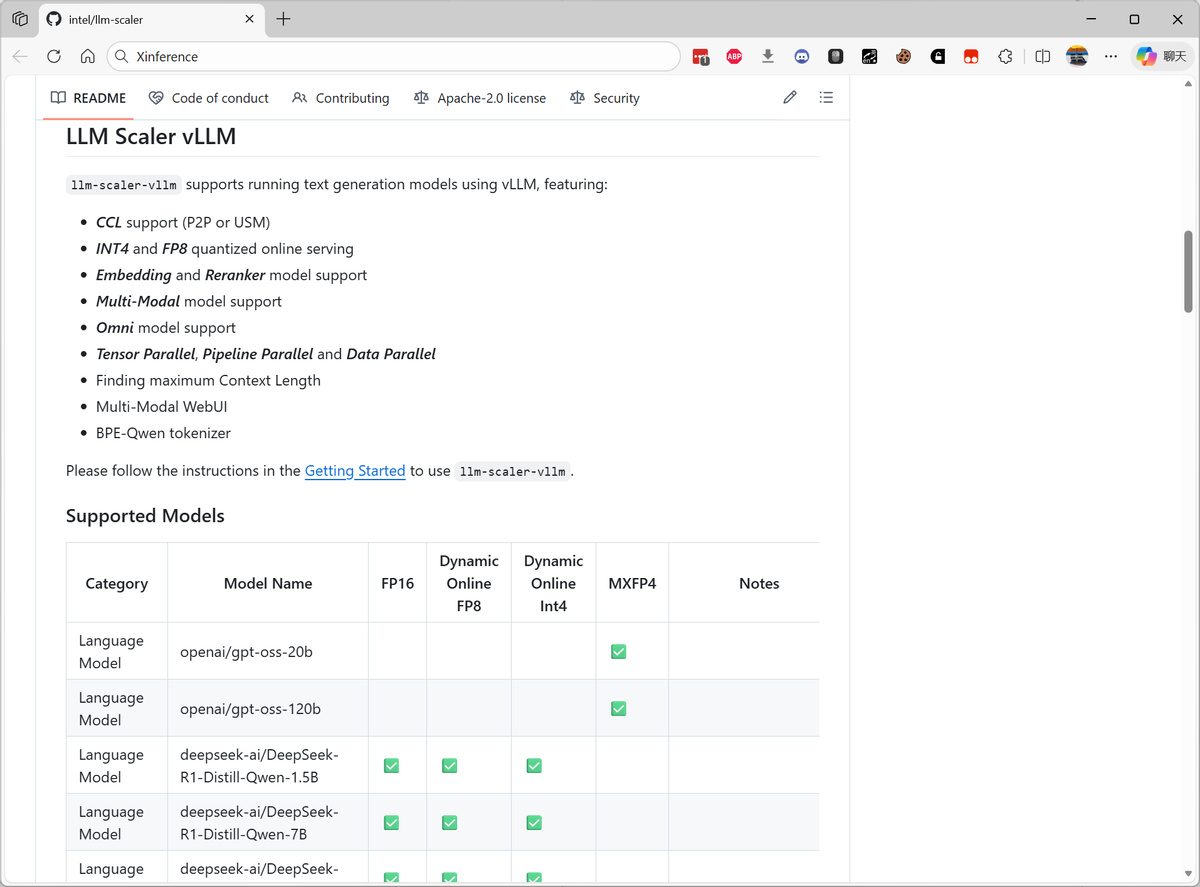
LLM-Scaler 可以用于文本生成、图形生成、视频生成等应用,支持包括 vLLM、ComfyUI、SGLang Diffusion、Xinference 等常见的开源推理框架项目,确保 Intel Arc Pro B60 跑上述应用的时候提供最佳性能。
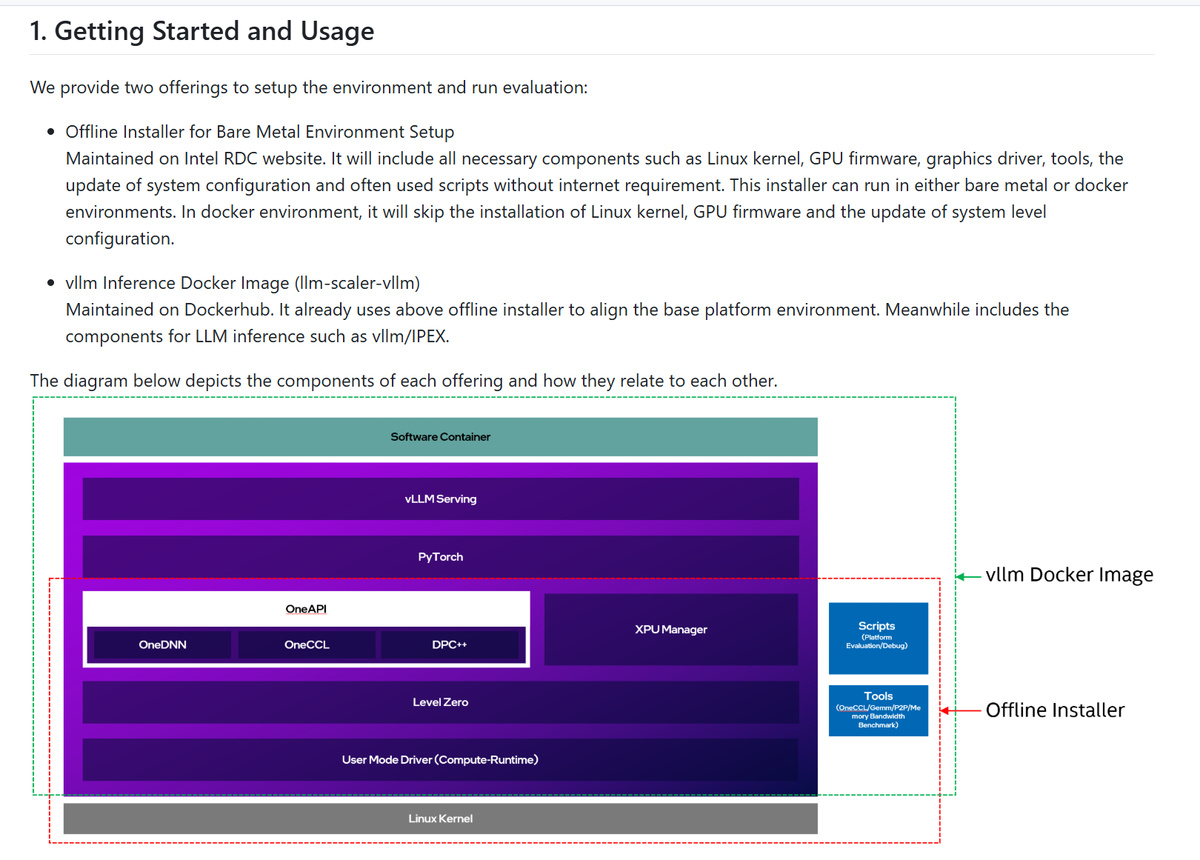
对于大部分 Intel Arc Pro 用户来说,最简单的方式就是使用容器来跑 vLLM。
首先是从 Intel RDC 网站上下载离线安装器:https://cdrdv2.intel.com/v1/dl/getContent/871223/871005?filename=multi-arc-bmg-offline-installer-25.45.5.4.tar.xz
然后解开安装包,用 root 权限执行里面的 installer.sh。
完成安装,重启,之后可以尝试执行 scripts/evaluation/platform_basic_evaluation.sh 来做初步的评估,确认完成软件安装。
之后我们可以尝试运行一下下面这条 xpu-smi 指令作进一步确认:
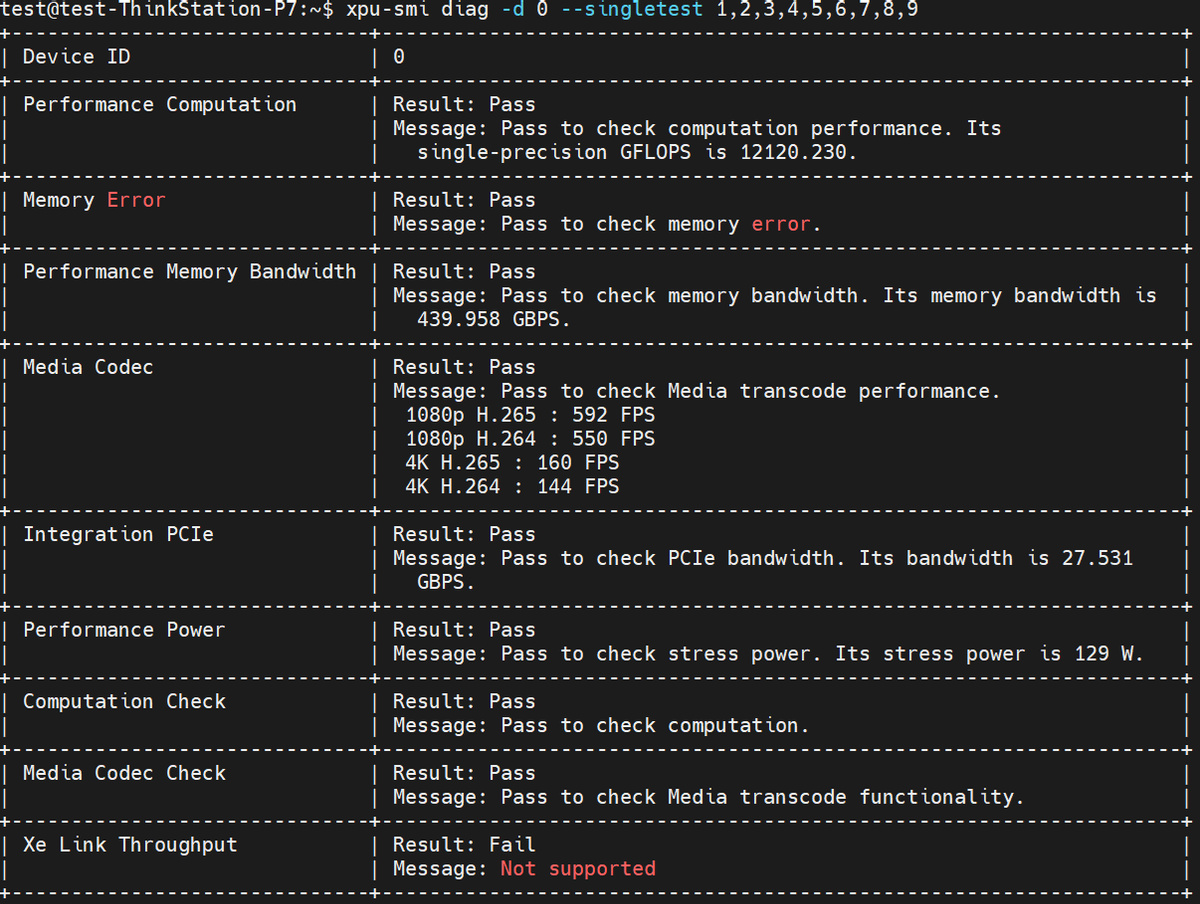
大家可以看到,这条 xpu-smi 指令测试出来的 Arc Pro B60 单 GPU FP32 性能是 12.1 TFLOPS、内存带宽是 440 GB/s、4K H.265 解码性能是 160 fps、PCIE 总线带宽未 27.5 GB/s、压力测试下的功耗值未 129 瓦。
vLLM轻松驾驭
接下来就是执行 docker pull intel/llm-scaler-vllm:1.2,用于下载 LLM-scaler 对应的 vllm 1.2 版容器。
然后用下面的命令启动容器:
sudo docker run -td \
--privileged \
--net=host \
--device=/dev/dri \
--name=lsv-container \
-v /home/intel/LLM:/llm/models/ \
-e no_proxy=localhost,127.0.0.1 \
-e http_proxy=$http_proxy \
-e https_proxy=$https_proxy \
--shm-size="32g" \
--entrypoint /bin/bash \
intel/llm-scaler-vllm:1.2
容器启动后,可以 exit 退出,之后再进入的话可以用下面的命令重新进入容器:
docker exec -it lsv-container bash
进入容器后,我们的所有操作其实都和使用 CUDA 做 LLM 推理没什么差别了。
例如用下面的指令启动 vLLM 服务:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
vllm serve \
--model /llm/models/DeepSeek-R1-Distill-Qwen-7B \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--dtype=float16 \
--enforce-eager \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--disable-sliding-window \
--gpu-memory-util=0.9 \
--no-enable-prefix-caching \
--max-num-batched-tokens=8192 \
--disable-log-requests \
--max-model-len=8192 \
--block-size 64 \
--quantization fp8 \
-tp=1 \
2>&1 | tee /llm/vllm.log > /proc/1/fd/1 &
启动 vLLM 服务后,我们可以用下面的指令来做一个初步的测试:
vllm bench serve \
--model /llm/models/DeepSeek-R1-Distill-Qwen-7B \
--dataset-name random \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--random-input-len=1024 \
--random-output-len=512 \
--ignore-eos \
--num-prompt 10 \
--trust_remote_code \
--request-rate inf \
--backend vllm \
--port=8000
这段代码的意思就是使用输入 1024 token、输出 512 token 等条件进行 Deepseek R1 蒸馏版 Qwen 7B 模型的推理性能测试。
当然,这个指令是比较粗糙未完全优化的,它只启用了 1 个 GPU、10 个提示词请求,我们可以通过添加 -tp 4、增大 num-prompt 到 100 以及设置 fp8 量化等参数进行 4 GPU 以及更大提示词请求规模的测试。
vLLM 多 GPU 性能实测:DeepSeek-R1-Distill-Qwen-7B
我们使用上面的指令作为模板,使用大量不同的参数、推理模型进行了测试,得出了铭瑄 Intel Arc Pro B60 DUAL 48GB 在单卡、双卡、四卡时的性能。
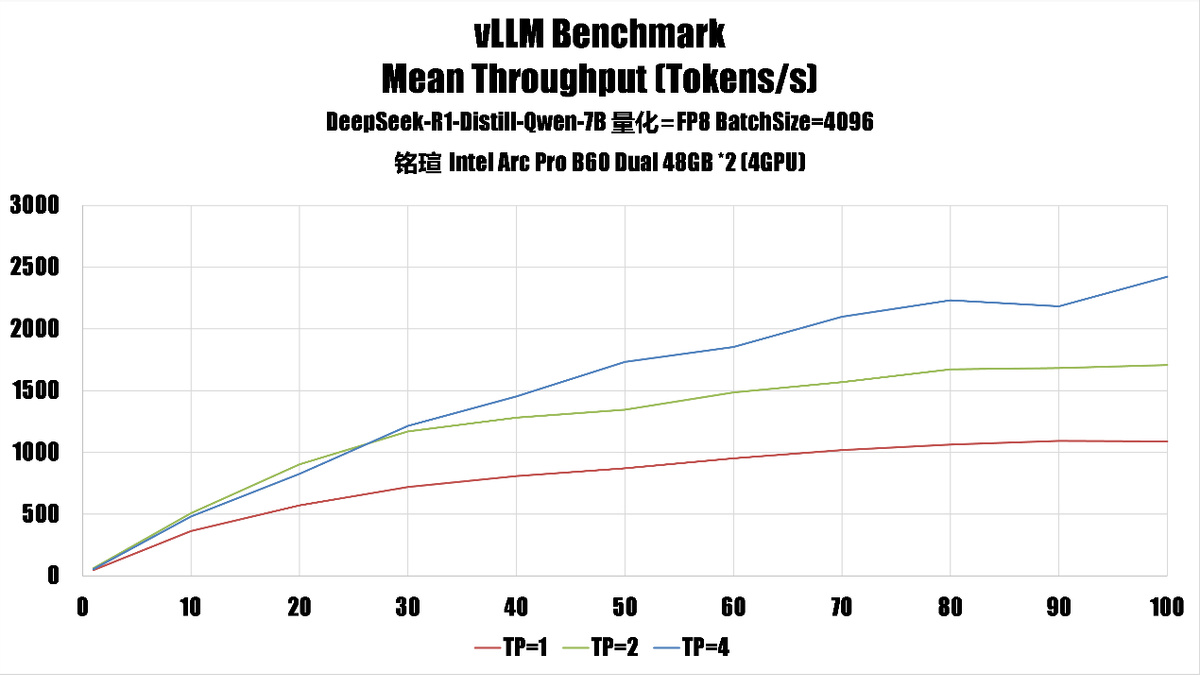
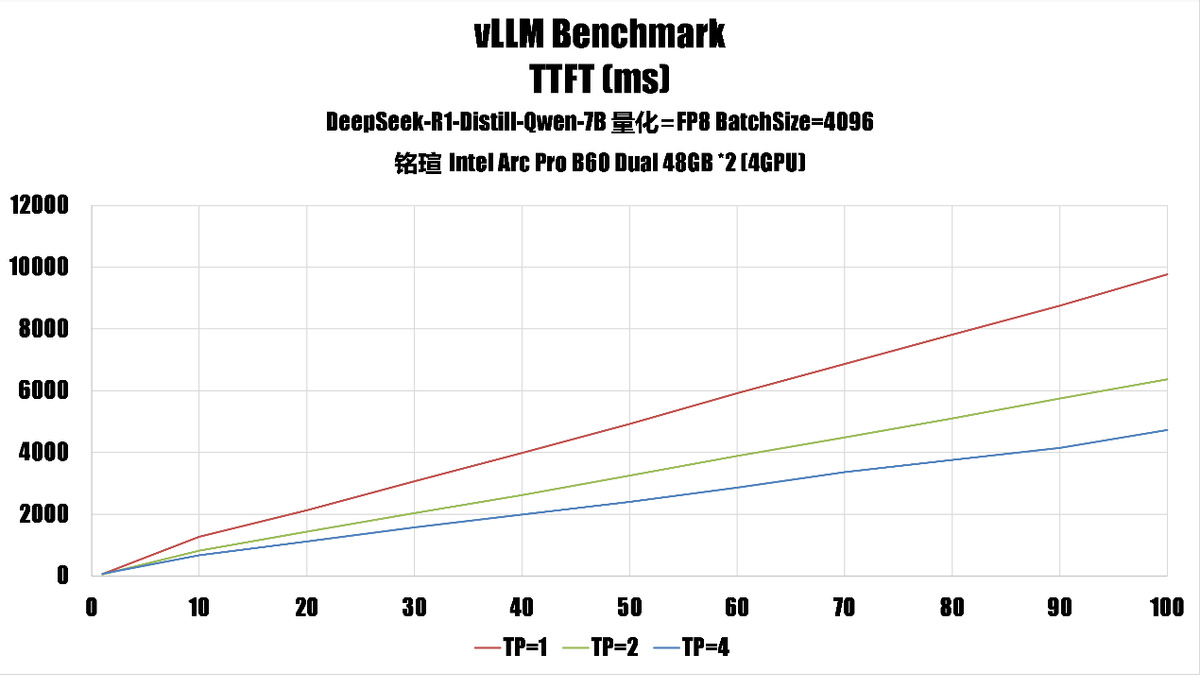
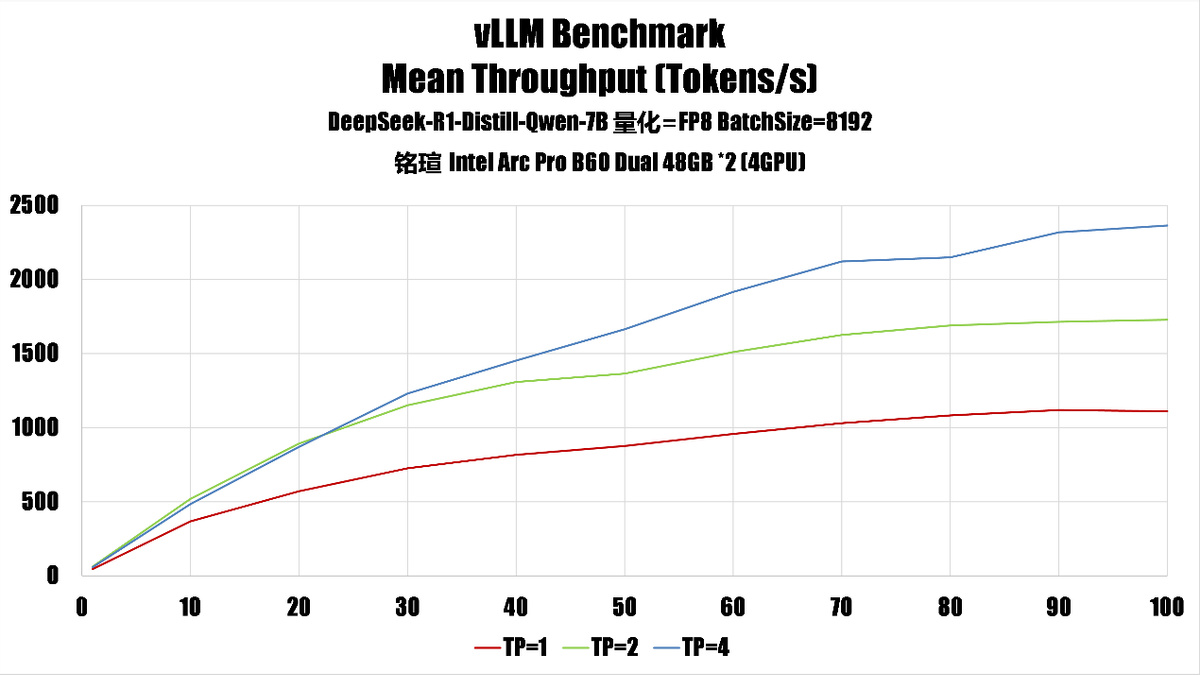
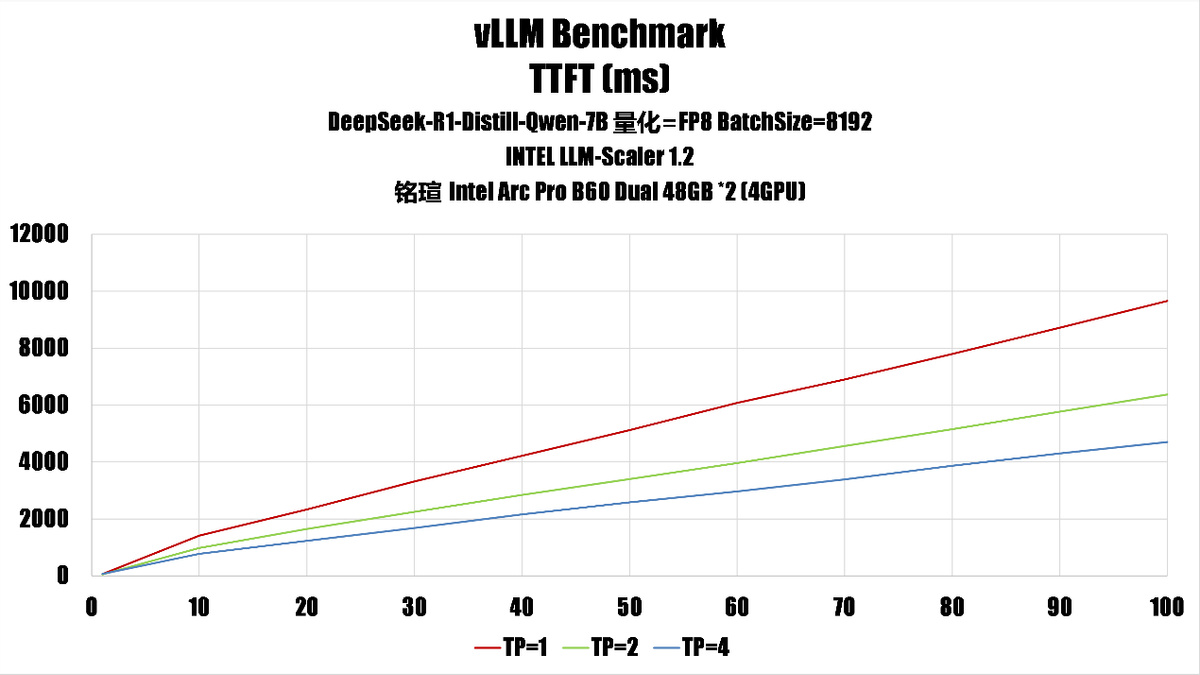
测试是启用了 fp8 量化,不过因为 Battlemage 缺乏硬件 fp8 支持,因此我们在这里实际上是用 fp16 进行计算,fp8 量化此时的好处主要是节省内存、带宽上。
从测试结果来看,
1、吞吐量(throughput)随 np 增长的趋势如下:
batch size 8192:
吞吐量增长更快,尤其在 tp=4 时,np=100 达到 2363.62。
batch size 4096:
吞吐量也随 np 增长,但整体数值略低,np=100 时为 2421.69,但增长曲线在 tp=4 时趋于平缓。
2、平均完成时间(mean_ttf)随 np 增长的趋势
batch size 8192:
平均完成时间增长更快,np=100 时达到 4703.63(tp=4)。
batch size 4096:
平均完成时间也增长,但整体略低,np=100 时为 4730.36(tp=4)。
这说明 batch size 越大,单位时间内处理的数据越多,但也可能导致单次任务耗时更长。
根据测试结果,我们认为对于这台系统来说,如果需要高吞吐环境的话,可以设置 batchsize=8192,TP=4,如果是希望更好的服务响应,可以考虑设置为 batchsize=4096 和 TP=2。如果希望均衡性能,最好是 batchsize=4096 和 TP=4。
vLLM 多 GPU 性能实测:GPT-oss-120b
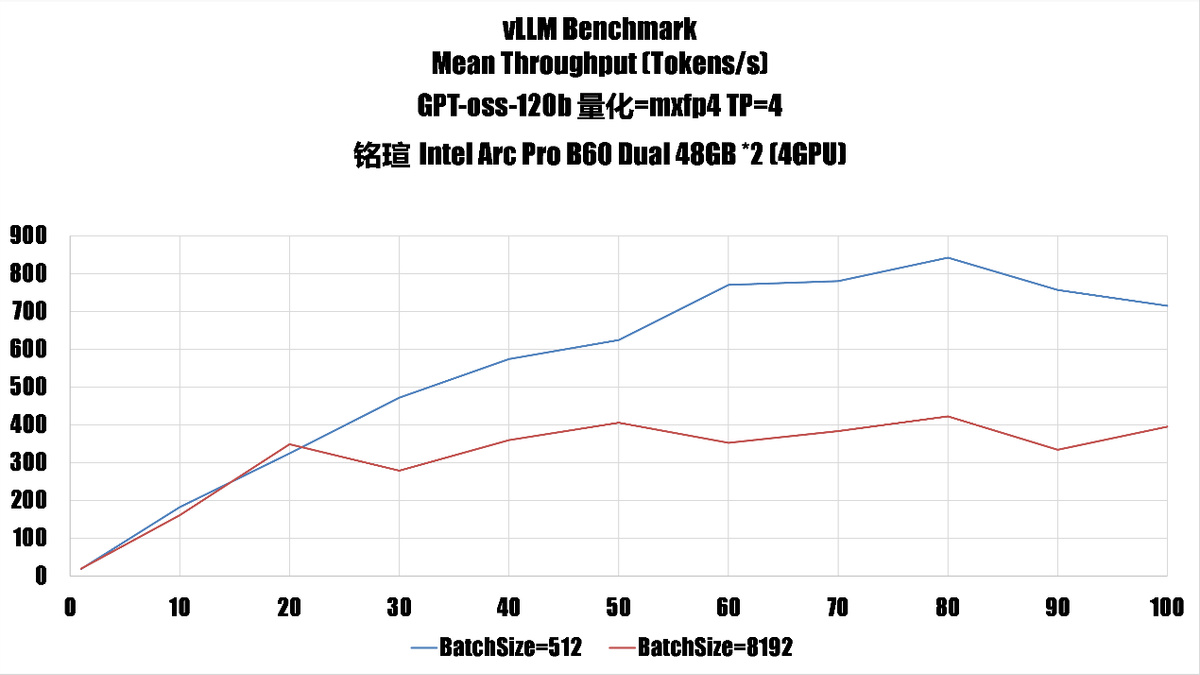
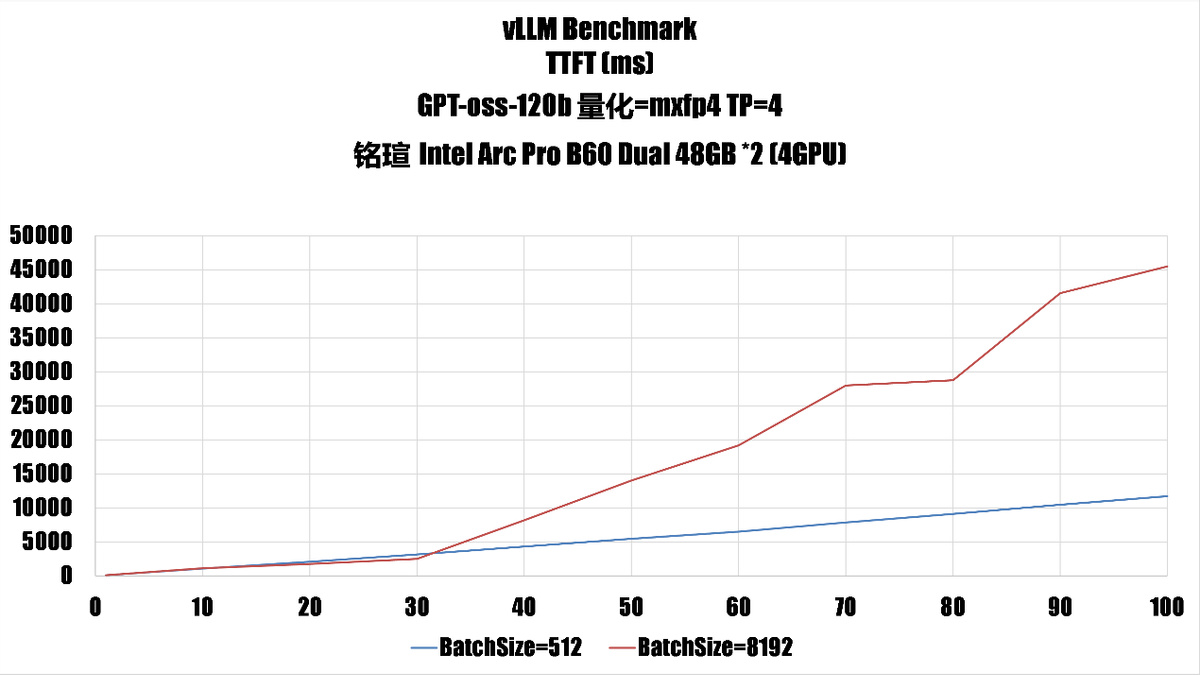
gpt-oss-120b 是 openai 最新的开源语言模型,官方提供的版本是使用了 mxfp4 量化的,我们在这里也使用 mxfp4,不过同样因为 Battlemage 缺乏 fp4 硬件支持,因此这里的计算也是 fp16 实现的,不过模型占用的空间和带宽都因为 mxfp4 的缘故会比较低。
我们这里选择了 batchsize=512 和 batchsize=8192 来展示,可以看到即使是启用了 8192 token 的最大长度,在 number_prompt=20 时(20 个并发请求)的性能和 512 token 的时候相当(平均每个请求能获得 15 token 的吞吐),之后也有 50% 以上的性能,考虑到这台系统的配置,这个性能也是很不错了。
增加 number_prompt 后的吞吐性能在 80 个后开始下降,这意味着对于 4 GPU B60 来说,运行 gpt-oss-120b 合理 np 值应该在 80 左右。
火力全开:ComfyUI Wan 2.2 多 GPU 文生视频
Intel 也为 LLM-Scaler-Omni 提供了容器镜像,使用下面的指令就能拖拽下载:
docker pull intel/llm-scaler-omni:0.1.0-b5
创建容器:
sudo docker run -itd \
--privileged \
--net=host \
--device=/dev/dri \
-e no_proxy=localhost,127.0.0.1 \
--name=comfyui \
-v $MODEL_DIR:/llm/models/ \
-v $COMFYUI_MODEL_DIR:/llm/ComfyUI/models \
--shm-size="64g" \
--entrypoint=/bin/bash \
intel/llm-scaler-omni:0.1.0-b5
之后进入容器就是:
docker exec -it comfyui bash
执行下面的命令就能启动容器内的 ComfyUI:
cd /llm/ComfyUI
python main.py --listen 0.0.0.0 --port 8188
之后就能在本地浏览器里执行 127.0.0.1:8188 启动 ComfyUI,你也可以透过 SSH、SSH+FRP 等方式远程访问。
我们的系统里安装了两片铭瑄 Arc Pro B60 DUAL,合共 4 个 B60 GPU 和 96GB 显存,ComfyUI 默认并不支持多 GPU 任务任务分派,需要额外的节点来实现,例如 LLM-Scaler-Omni 容器内自带 Wan 2.2 工作流节点里的 Raylight,就能支持多 GPU 并行计算加速,在 4 GPU 的时候能提高大约 25% 的性能。
下图就是使用 Raylight 节点时候多 GPU 同时启用的状态图。
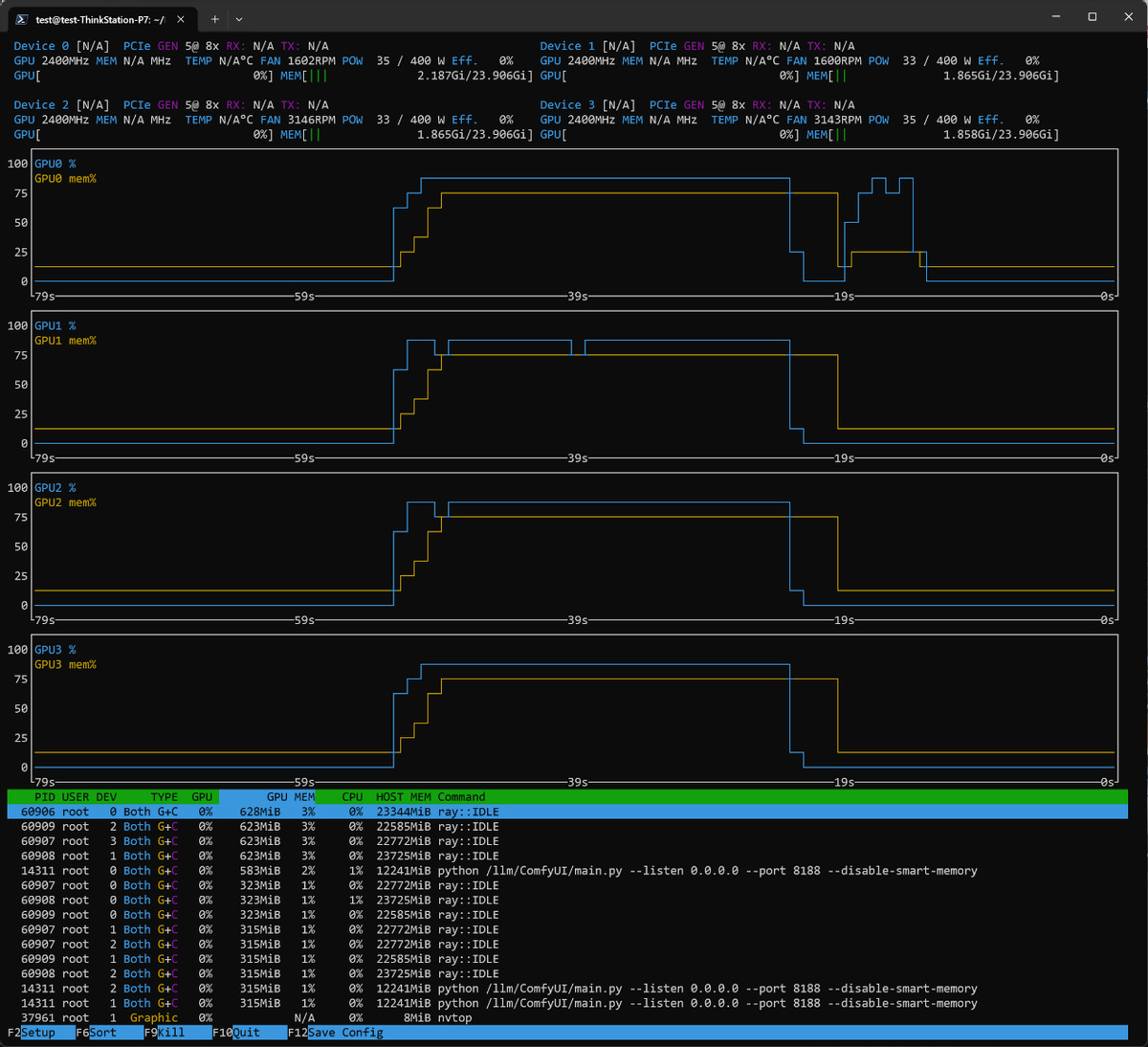
由于需要透过 PCIE 5.0 X8 总线的 32GB/s 带宽交换数据,所以在双 GPU 的时候效率较低,性能会不如单 GPU,但是因为分布式池化,所以能装进的模型权重还是要比单卡大。
实测结果如下:
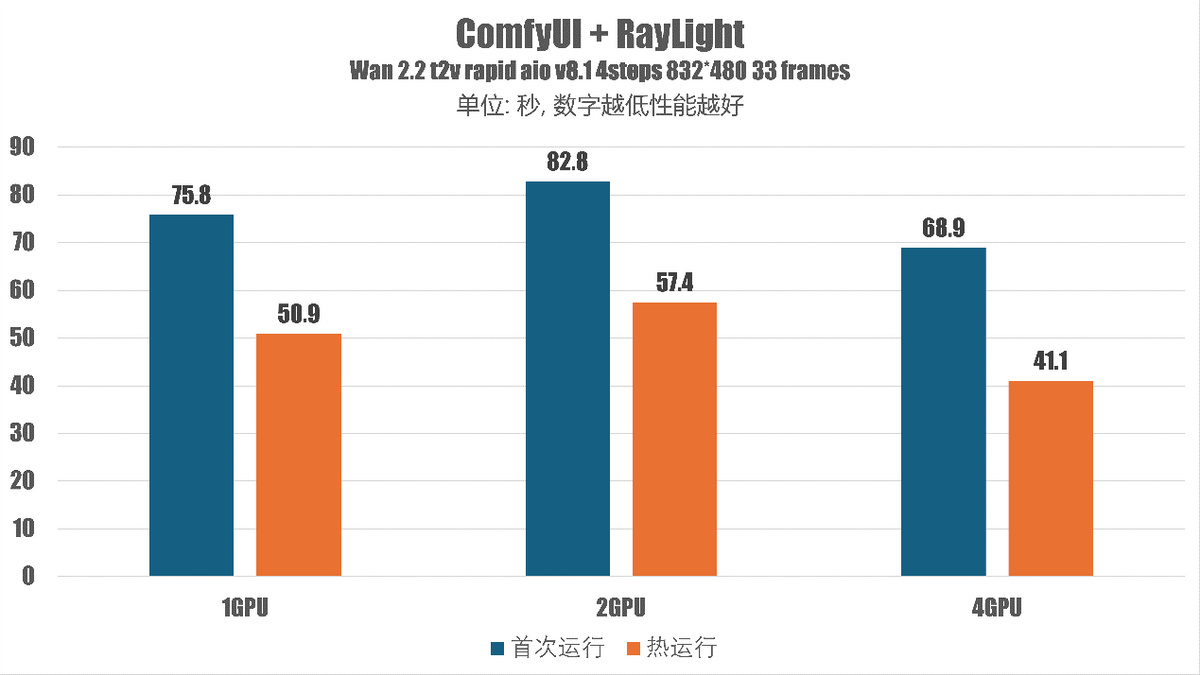
在单 GPU 模式下,铭瑄 Arc Pro B60 DUAL 48GB 的耗时是 50.9 秒,双 GPU 模式下是 57.4 秒,增加了大约 13%,在四 GPU 模式下时间缩短到了 41.1 秒,缩短了大约 19%。
SPECViewperf v15
Viewperf 是行业最重要的图形工作站性能基准测试套件之一,包括 NVIDIA、AMD、Intel 等厂商都会在其官方文档、发布会上应用 SPECViewperf 测试成绩,在企业采购中,该测试往往作为重要的决策依据。


Viewperf v15 是 SPEC.org 2015 年发布的最新版工作站图形基准测试套件,包含了 Vulkan、D3D12、OpenGL 等多种 API 的工作站图形负载轨迹,新增了多个项目,例如 Blender、Unreal 游戏引擎、Enscape 建筑可视化实时光线追踪,传统的 3ds Max、CATIA、Creo、Maya、SolidWorks 等工作站应用图形轨迹也得到了更新。
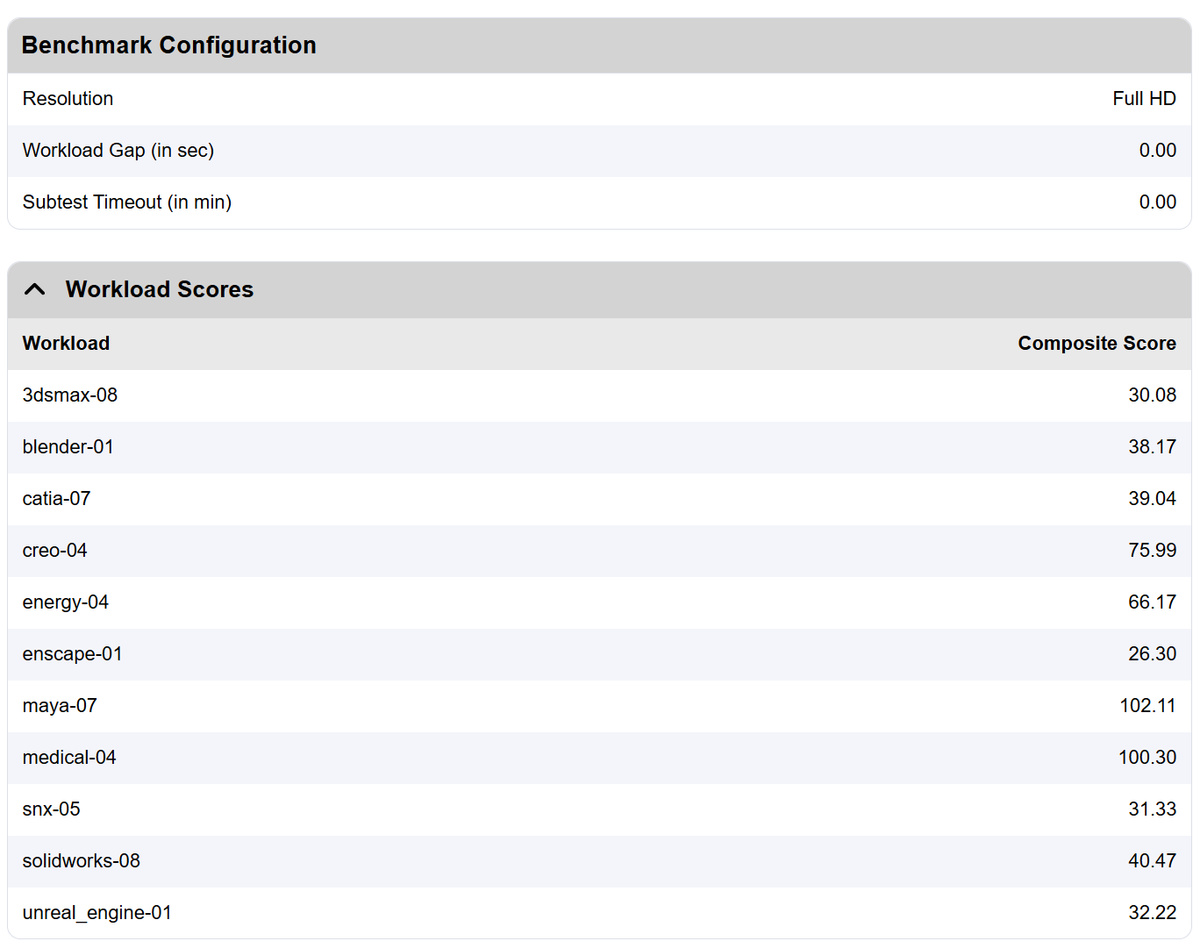
测试使用的视口分辨率是 1920x1080,测试结果如上,数值就是各个项目的几何平均帧率,测试过程非常流畅、稳定,未看到明显的渲染瑕疵。
底层测试:海量的Cache/内存带宽!
我用 Neme 的 Vulkan 底层测试工具进行了一些测试,包括时延、吞吐等,首先看看访存时延:
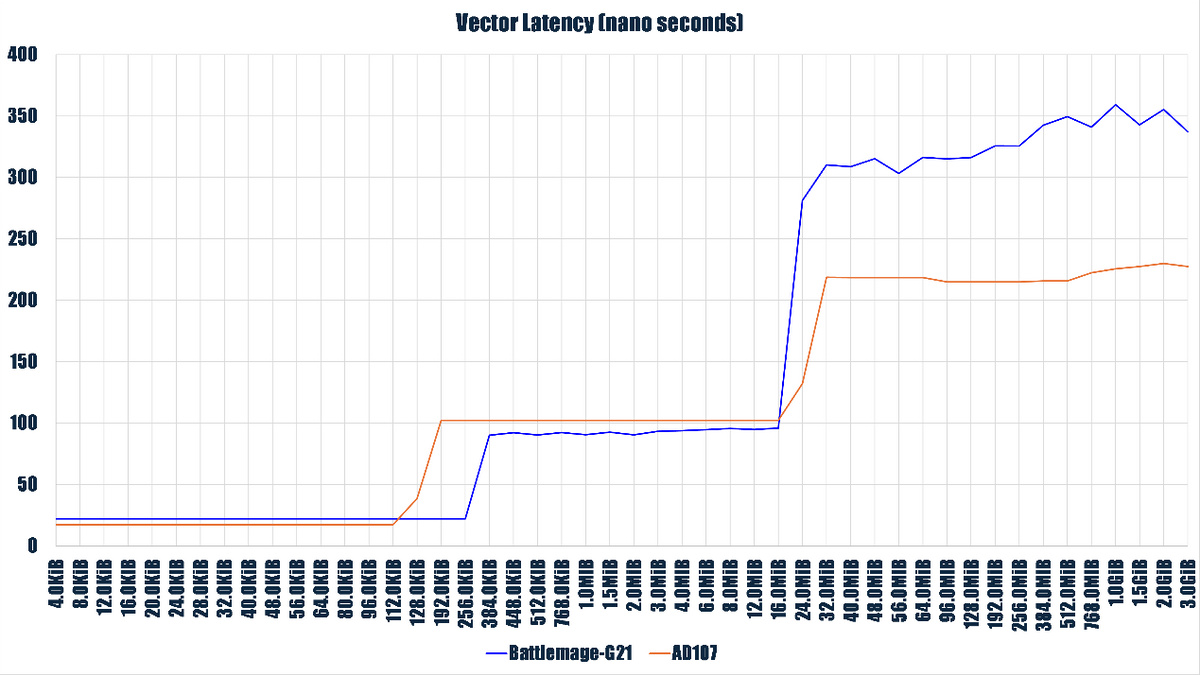
我在这里使用了 AD107(RTX 4060)作为对比。
从测试结果看,Battlemage-G21(Arc Pro B60) 的 L1 Cache/SLM(Intel Xe 微架构里的术语,等效于 CUDA 里的 Shared Memory 或者 OpenCL 里的 Local Memory) 是在 256 KiB 处发生显著跃升,符合其 L1 Cache 大小为 256 KiB 大小的公开规格。
L2 Cache 阶段在 16 MiB 处发生明显跃升,略早于官方规格里的 18MiB。
AD107 在 L1 Cache 阶段拥有更快的时延,但是在 L2 Cache 阶段则更慢,而且 L2 Cache 发生跃升的位置(20 MiB)也只是在宣称(48 MiB)的 L2 Cache 一半不到,在进入访存阶段后,B60 的访存时延开销要比对手高很多。
除了内存带宽远高于 AD107 外,Battlemage-G21 实测 28 GB/s 的 PCIE 总线带宽也远高于 AD107 的 13.2 GiB/s,在涉及 PCIE 总线的数据交换时 Arc Pro B60 的表现会更出色。
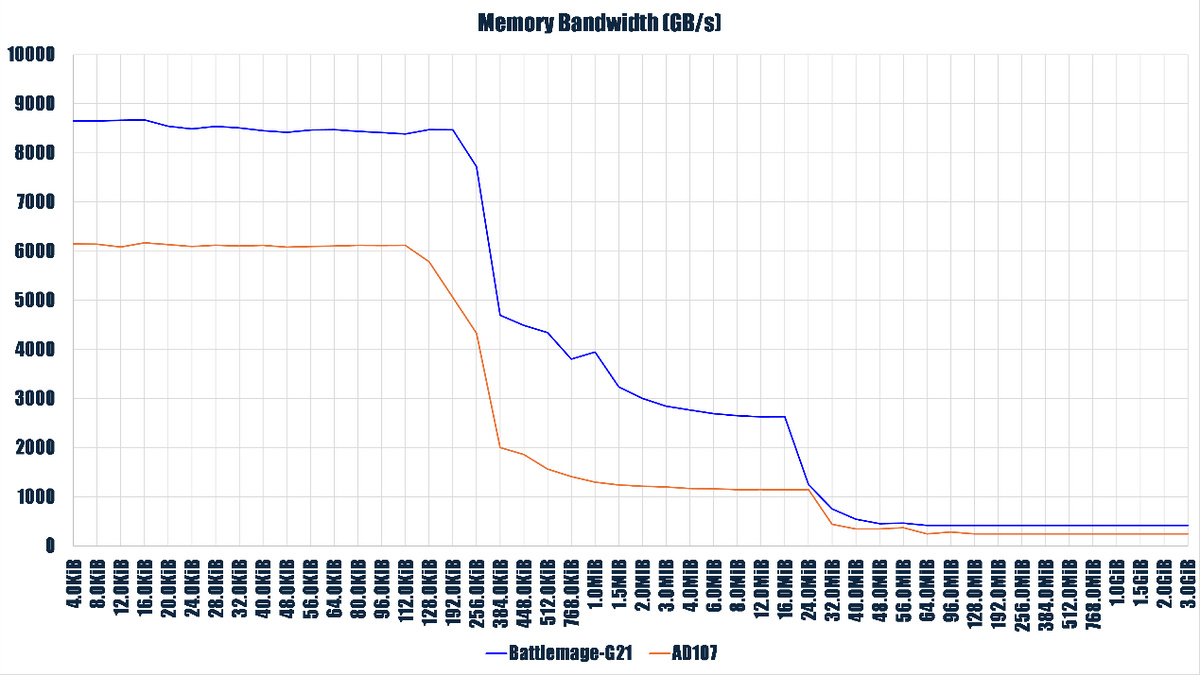
Arc Pro B60 拥有高很多的Cache/内存带宽,这得益于它拥有 192-bit 内存总线,实测单 GPU 模式下内存带宽达到了 422 GB/s,而对手 RTX 4060(GPU 内核代号 AD107,NVIDIA 采用 AD107 的专业卡为 RTX 2000 Ada Generation)只有 128-bit 内存总线,实测内存带宽是 248GB/s。
在浮点性能方面,Arc Pro B60 在 Vullan 下实测 fp32 fma 指令性能为 12.3 TFLOPS,FP64 是 757.7 GFLOPS,作为对比 RTX 4060 是 15.8 TFLOPS 和 265 GFLOPS,Arc Pro B60 因为具备更强的内存带宽,在性能平衡上一般会更好。
写在最后:搅局者
回看这几天的深度测试,Arc Pro B60 给我最深的感触是:Intel 独立显卡已经脱离了“跑分好看”的初期阶段,真正开始在专业工作流和 AI 大模型领域展现出**“搅局者”**的硬实力。
基于 Battlemage (Xe2) 架构的铭瑄 Arc Pro B60 DUAL,在 48GB 海量显存和全新底层逻辑的加持下,为开发者和专业用户提供了一个极具性价比的“非绿”选项。
以下是我们对这款测试对象的深度复盘:
1. 最大优势:参数给得足够“慷慨”
• 同级别配置下显存带宽与位宽的降维打击。在同级别定位中,对手(例如 RTX 2000 Ada Generation)往往在显存位宽上显得吝啬,而 B60 凭借 192-bit 内存总线,实测内存带宽高达 422 GB/s,几乎是竞品 AD107(RTX 4060)的两倍。这种大带宽在处理大模型推理和高分辨率渲染时,能够提供更稳健的性能下限。
• PCIe 5.0 的超前部署:实测 28 GB/s 的 PCIe 总线带宽远超对手,这在频繁进行多卡数据交换或大规模纹理加载时,优势极其明显。
• 软件生态的“拎包入住”:相比于 RoCM 依赖包的“散装”现状,Intel 提供的 LLM-Scaler 解决方案更加整体化。通过容器化部署 vLLM,开发者可以几乎零成本地从 CUDA 迁移到 Xe 架构上,实现了真正的“开箱即用”。
2. 现存不足:细节之处仍有遗憾
• 硬件级低精度计算缺失: Battlemage 架构在指令集上非常先进,但它的 XMX内核缺乏硬件级的 FP8 和 FP4 支持。虽然能通过 FP16 模拟实现 DeepSeek-R1 或 GPT-oss-120b 的运行,但在追求极致算力的场景下,模拟计算依然难以完全发挥架构潜力。
• 访存时延开销较高:底层测试显示,B60 在进入显存访存阶段后的时延明显高于对手,这反映出其底层内存控制器的调教仍有精进空间。
• 多卡互联的物理瓶颈:由于 B60 不支持物理 Xe-Link 接口,多 GPU 协同只能依赖 PCIe 总线。在运行如 Raylight 这种分布式切分模型时,数据同步的开销限制了多卡扩展的效率。
展望:Intel 独显的“成熟期”将至
Arc Pro B60 的表现证明了 Xe2 架构在 SIMD16 原生指令宽度和“硬件原生间接执行”等设计上的前瞻性。它不仅在 SPECViewperf 传统的专业制图测试中表现稳健,更在 DeepSeek 等 AI 浪潮中找到了自己的生态位。
对于工作站用户来说,B60 的出现最大的意义在于提供了一个成熟的选择。 随着未来驱动程序的进一步迭代,以及如果能在后续型号中补齐硬件级 FP8 加速,英特尔极有可能在专业计算市场实现真正的“跨越式远征”。
随着Arc Pro B60陆续登陆授权经销电商平台,如果你需要一个大显存、高带宽且软件支持直观的 AI 推理或图形渲染平台,铭瑄、蓝戟推出的这款 48GB “双芯怪兽”无疑是目前市场上最值得关注的变数。
本文感谢原 PCPOP/显卡之家主笔Edison Chen的鼎力支持,在平台搭建和测试过程中,笔者受益匪浅,如有兴趣,请访问Edison Chen的知乎主页:
https://www.zhihu.com/people/edison-chan-24
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















