在 DeepSeek-R1 發佈一週年前後,社區有人注意到,DeepSeek 的部分 GitHub 倉庫中悄悄出現了一個此前從未公開過的名字——MODEL1。
該信息最早由X上@nopainkiller發現。

這種“非正式曝光”,讓外界不少人判斷:這很可能是 DeepSeek 下一代核心模型的內部代號。
從目前能看到的線索來看,MODEL1 並不像 V3.1、V3.2 那樣是 V3 系列的延續版本。它在代碼中與 “V32”(即 DeepSeek-V3.2)並列存在,使用不同的參數假設和內存佈局,這通常意味着一個新的模型族。
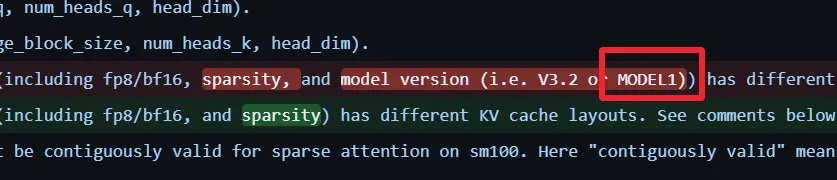
MODEL1 被集中發現於 DeepSeek 的 FlashMLA 倉庫。這個倉庫專注於注意力內核的底層優化,目標是讓 V3 系列在 H800 等 GPU 上跑得更快、更省內存。

目前的實現已經能在特定配置下逼近 660 TFLOPs,這本身就說明它處在非常貼近硬件的一層。
也正因爲如此,這裏出現的新參數,往往意味着模型結構本身發生了變化。MODEL1 在多個文件中被單獨提及,尤其是在 KV cache 佈局和 FP8 解碼相關的邏輯裏。比如在稀疏 FP8 解碼模式下,MODEL1 對 KV cache 的對齊要求是 576 字節,而 V3.2 使用的是 656 字節。這樣的差異不會是隨手改的,它通常意味着注意力結構、head 設計或者稀疏策略已經不一樣了。
換句話說,MODEL1 很可能是圍繞 DeepSeek 的稀疏注意力機制重新設計過的一套模型。
更有意思的是,後來的一次提交中,DeepSeek 把這些與 MODEL1 明確相關的註釋和說明幾乎全部刪掉了。

提交說明看起來只是一些小調整,但實際上,像“extra_k_cache 用於支持 MODEL1”這樣的表述被統一模糊化,MODEL1 專屬的 KV cache 對齊要求、head 維度、FP8 稀疏塊結構等信息也一併消失。
這種做法通常只有兩種可能:要麼這些內容是實驗廢案,要麼就是不想讓外界繼續順着代碼猜下去。結合 DeepSeek 一貫在模型發佈前收緊信息的習慣,後者顯然更合理一些。這反而從側面確認了 MODEL1 的存在並非偶然。
並且,如果只看代碼,很難判斷 MODEL1 的整體方向。但把時間線拉長,會發現它和 DeepSeek 最近公開的兩項研究工作高度一致。
一項是 mHC(Manifold-Constrained Hyper-Connections)。這項工作試圖在不顯著增加計算和內存開銷的前提下,擴展殘差流的“寬度”,讓模型在更深層仍然保持穩定訓練。從實驗結果來看,它確實能在較小代價下帶來性能提升,也非常適合大模型和稀疏結構。

另一項是 Engram 記憶模塊。它的思路是把一些可複用的靜態模式,用類似哈希 N-gram 的方式緩存下來,實現近乎 O(1) 的訪問,把負擔從模型早期層移走。DeepSeek 在論文中已經把 Engram 明確描述爲“下一代稀疏模型的基礎組件”,這幾乎是在明示它會被用進新模型。

如果把這些點連起來看,MODEL1 很有可能是一次新的圍繞稀疏性、內存結構和推理效率的整體重構。
最後,從代碼回滾、論文補充、以及 R1 文檔從 22 頁擴展到 86 頁這些信號來看,DeepSeek 顯然正處在爲下一代模型“收尾”的階段。
社區普遍猜測,MODEL1 可能會以 V4 或 R2 的正式名稱出現,時間大概在 2026 年初,春節前後並不算誇張。
如果這個判斷成立,那麼 MODEL1 很可能會延續 DeepSeek 一貫的開源策略,並在推理效率、稀疏建模和工程可落地性上,進一步拉開與傳統 dense LLM 的差距。
至少從目前泄露出的痕跡來看,這不像一次常規更新,更像是 DeepSeek 在爲下一個階段做準備。
讓我們拭目以待。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















