最近,语言学家和研究者注意到一个令人关注的现象:人类口语正悄然向人工智能语言模型靠拢。词源学家亚当·阿莱克西奇在近期TED演讲中指出,人们越来越像ChatGPT一样说话,使用如“delve”(钻研)、“meticulous”(严谨)和“underscore”(强调)等词汇的频率异常上升。

这一观察并非孤例。
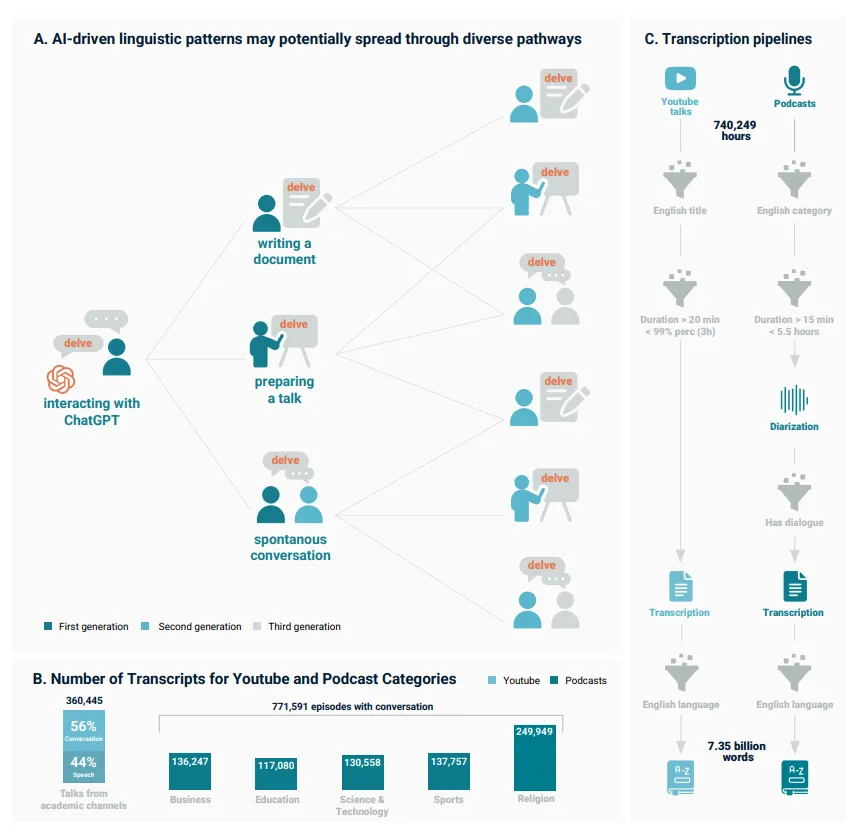
柏林马克斯·普朗克人类发展研究所研究员Hiromu Yakura领导的一项最新研究,通过分析超过74万小时的音频数据,提供实证支持。该研究涵盖36万场YouTube学术演讲和77万集播客节目,发现自ChatGPT 2022年底发布以来,其偏好词汇在人类口语中出现显著增长。
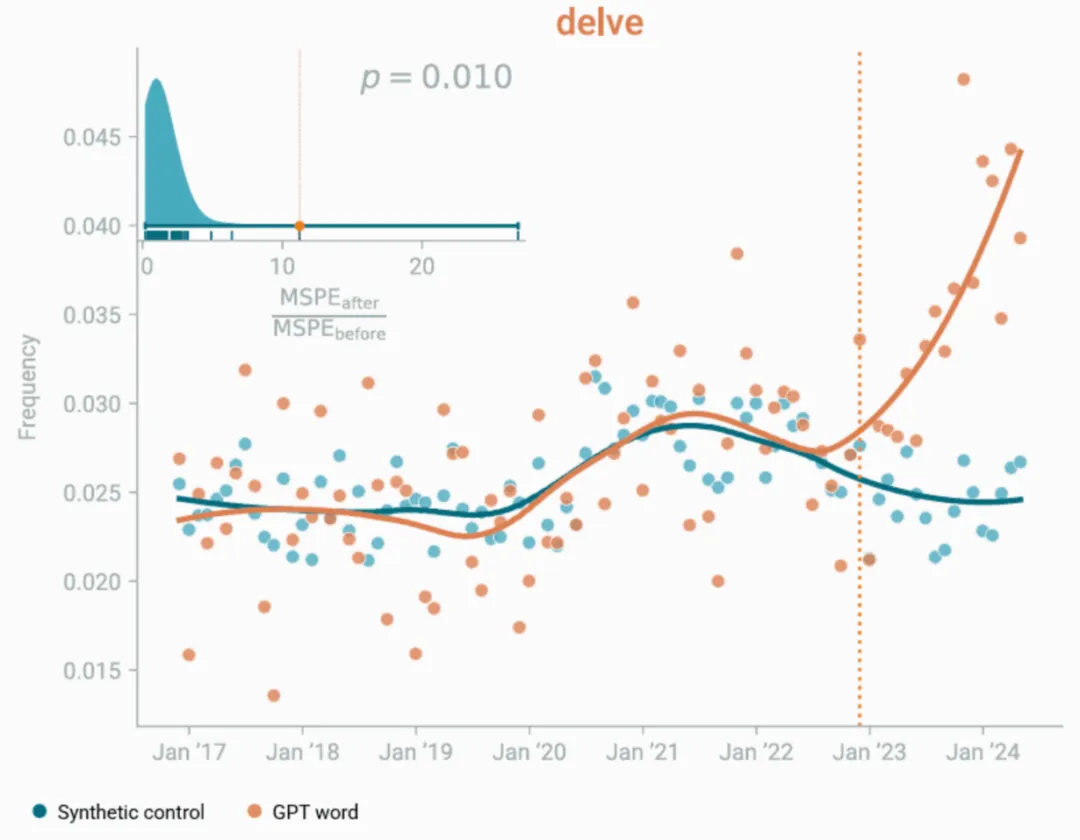
最突出例子是“delve”。ChatGPT对这一词汇的使用远超人类常规习惯,如今它已从学术领域扩散至商业、教育和科技类内容。研究显示,这些词汇涨幅达25%至50%,甚至出现在非脚本化的随意对话中。
研究者将此归因于一个反馈循环:AI从人类数据学习,却在训练过程中形成特定偏差(如受外包标注员影响);人类频繁互动AI后,无意识模仿这些模式;新内容又反馈至AI训练,形成强化闭环。
不过影响并非均匀。
人类模仿AI的现象在科技、商业、教育领域变化最剧烈,而体育、宗教类播客相对稳定,反映AI接触频率差异(我现在经常被人吐槽讲话像AI)。
这一趋势延伸至更广文化领域。阿莱克西奇举例,Spotify算法将数据簇定义为“Hyperpop”风格,迫使音乐人迎合;TikTok上“Labubu”盲盒或“迪拜巧克力”等热潮,常源于算法放大微弱信号,导致真实流行与“伪流行”难辨。(某位up名言:曲风都是狗屁!)
研究警示,若AI携带有特定价值观,人类表达持续趋同,可能引发思维同质化风险,威胁文化多样性和思想独立。
最后,专家呼吁保持警惕:在日常表达中,自问这些词汇或观点是否真正源于个人经验,而非算法影响。
只有自觉审视,方能在技术时代保留人类语言的独特性和多样性。
笑点解析:本文由人类模仿AI书写后由AI润色。

俄(四) СYβёяī(phrasefix)��м○Rtаじ,關註吾菛,帶尓暢氵斿аιㄝ堺!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















