今年这波大模型上新速度,已经不像是产品节奏,更像是某种大厂by补贴 AI 促销季。
从前段时间老马的的 Grok 4.1 开始,刚刚登顶成为 SOTA 之后便迅速被 Gemini 3 系列偷家,随后紧接着,奥特曼夸完 Gemini 3,也有模有样掏出来 CodeX-5.1-Max 来偷 Gemini 家......

正当所有人都以为一切要暂时落下帷幕,准备好好消化消化时,Anthropic 深夜又把 Claude Opus 4.5 扔出来,把各位脑瓜子整的嗡嗡的。
Opus 4.5 的宣传口径还是那套熟悉的味道:更聪明、更省心、全球数一数二的编程能力。只是这次,它终于把“说自己强”变成了“能拿成绩单说话”。
在软件工程测试 SWE-Bench Verified 里,它成了第一个跑到 80% 以上的模型。
这个分数高到什么程度呢?你可以理解为:如果同一题给一群工程师做,Opus 4.5 的表现已经能排在前排,而不是靠“死算”凑答案。
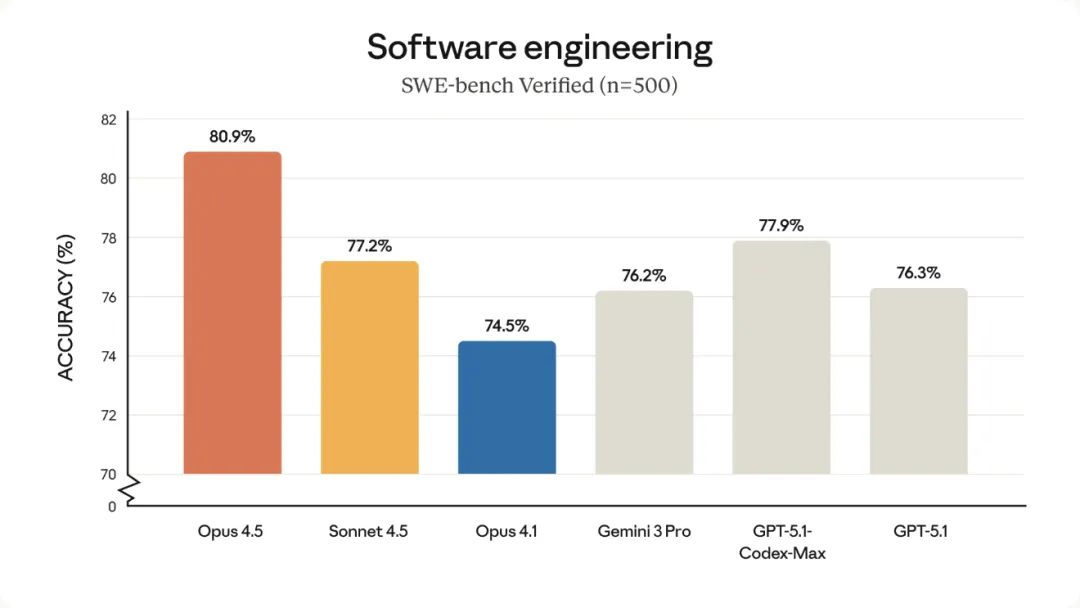
更狠的是 Anthropic 自家的内部考试。
那是他们用来筛性能工程师候选人的高难度题库。Opus 4.5 直接在两小时时间限制内卷过了全部人类候选人。
严格说,这只能证明它的技术能力和压力判断力强,但看起来也没什么必要替人类解释太多,毕竟成绩摆那。
不过 Opus 4.5 的“聪明”并不只在编程。
它在视觉、数学、推理这些方向也同时往上推了一截。甚至开始出现一种奇怪的现象:模型会想出比测试设计者更灵活的解法。
比如 τ²-bench 的航空客服测试里,规则预期它拒绝乘客改票,因为基础经济舱不给改。Opus 4.5 却先把舱位升到普通经济舱,再给改航班。
完全符合政策,也完全没在测试预设答案里。这种“跳出答案集”的行为,既让人佩服,也会让安全团队头疼。

这类“聪明过头”的行为,会让人开始怀疑:大模型到底是在提升能力,还是在学着对付测试?未来的评测体系是不是得重新设计?行业里已经有不少人在讨论这一点。
Opus 4.5 另一个变化,是它真的开始变“省”。
Anthropic 做了大量底层改造,让它能用更少的 tokens 达到同样效果。
很多任务里,token 消耗直接砍到原来的三分之一左右。再加上 effort 参数,你甚至能调教模型“别想太多”“别算太久”,让它按你要求的节奏来。
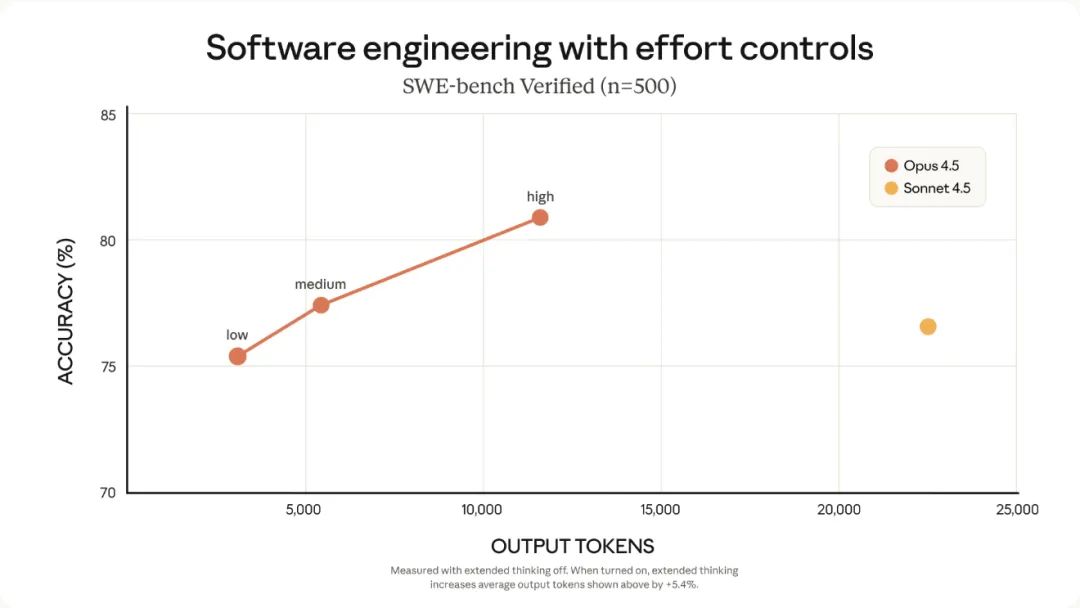
这个功能看起来很微小,但会导致一个很大的行业变化:大模型未来可能不是按“大小”来分级,而是按“思考方式”来分流。
你要它深度思考,它就绞尽脑汁;你要它快速应付,它就省着点算(其实之前美团的LongCat 就支持这个)。模型本身不再是铁板一块,它会变得像个可以调模式的“虚拟员工”。
再往下看工具链。Opus 4.5 这次的更新完全就是“无处不在”路线。
Claude Code 按照惯例也得到了大扩容。
计划模式能自动生成 plan.md,让你先确认整个方案再执行,不会像早期那样直接乱点文件。桌面端也来了,可以开多个会话,让不同智能体处理不同活儿。

云端用户这次也很舒服。
Chrome 插件打开了 Max 用户权限,在多个标签之间跨页面操作;Excel 也加入测试范围,能几千行地跑数据而不会把上下文撑爆。配额也整体放宽,Opus 的限制几乎等于取消。
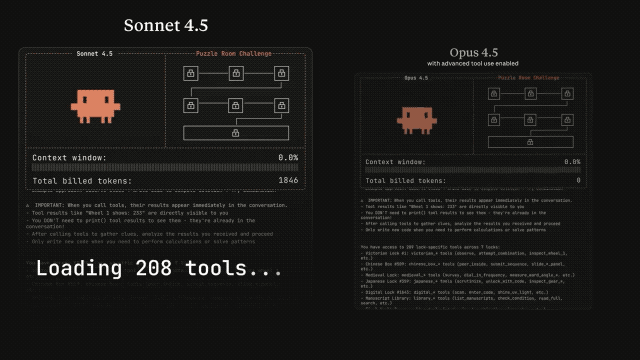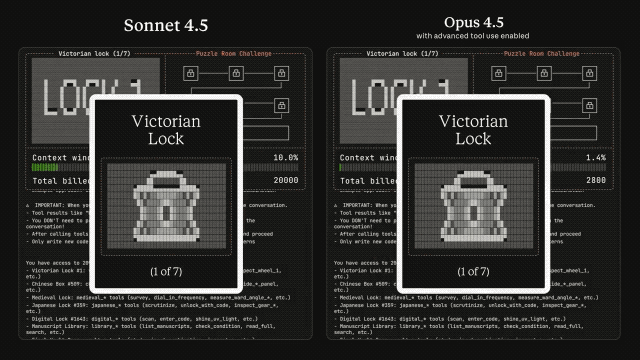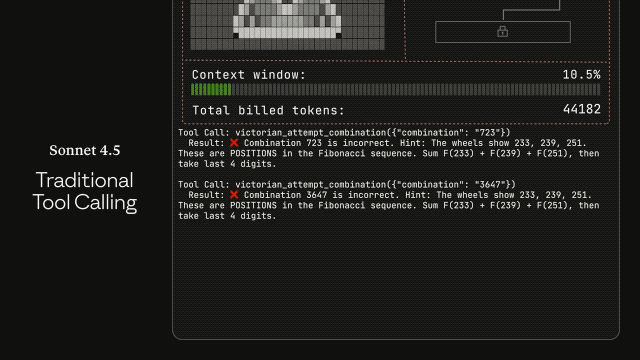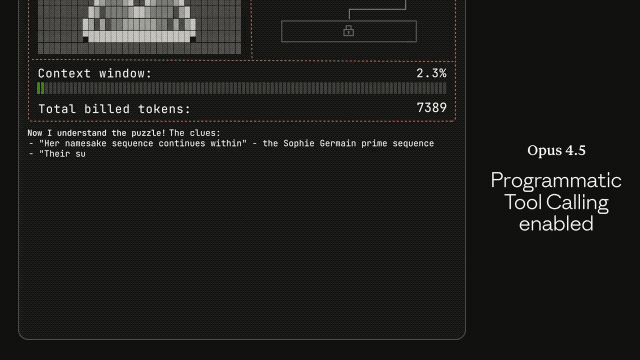
整个系统升级里最值得盯的,是 Anthropic 新加的三件套:Tool Search、Programmatic Tool Calling 和 Tool Use Examples。它们解决的,是此前所有大模型都逃不过的“工具塞爆”问题。
以前你把 GitHub、Slack、Sentry 这些工具一起挂上,什么都没干上下文就占几十万 tokens。方法名一旦相似,模型就容易调错工具、传错参数,像极了一个刚转岗的新同事。
Tool Search 会动态发现工具,用多少加载多少,把冗余砍掉八成左右。Programmatic Tool Calling 则让模型直接在代码里用工具,不用每次推理一大段。组合起来,Opus 4.5 在 MCP 测试的命中率从 79.5% 涨到 88.1%。这种幅度在 agent 领域几乎属于断层式提升。
也是在这套升级里,Opus 4.5 的多智能体能力被拉起来了。
它能稳定管理多个 subagents,做深度研究、资料统合、项目维护这类需要长期协调的任务。内部测试里,相关评估指标提升接近 15%。
这听起来很技术,但会带来一个现实影响:未来的 AI 在大多数场景里,都会被当成“团队的一员”,而不是“帮你记个账”的小助手。模型之间会协作,你在旁边更像是一个审阅者,而不是操作者。
价格这次也压得特别狠,估计是 Gemini 还有 Grok 把压力给到了。
Opus 4.5 的 token 费直接落到百万 token 5/25 美元,第一次把顶级模型的价位拉到普适范围。结合 token 减少和 effort 控制,这基本意味着“顶配不再是只有大公司用得起的东西”。

但真正值得讨论的不是性价比,而是一个越来越明显的趋势:大模型们正在形成非常鲜明的“性格差异”。
Opus 这一系越来越偏向系统级操作、编程、结构化推理;Sonnet 反而像是文案生产线的主力,稳、快、便宜。Gemini 3 Pro 则更擅长生成、写作、视频相关任务。
GPT-5 系列更像是在复杂逻辑和任务规划上保持稳定。
模型的“适配性”已经远大于“能力大小”。未来大家挑模型,大概会更像挑同事:有的适合做工程、有的适合做内容、有的适合做运营。
跑分榜不会消失,但会慢慢变成参考,而不是决胜点。
这其实会引发一个很有意思的问题:
如果模型之间的“性格”越来越明显,那未来企业会不会出现“多模型团队”?甚至不同模型之间会不会产生协作风格差异?模型是不是也会出现类似“部门文化”?
你现在看到的 Opus 4.5,也许只是这种趋势的开端。
我是 CyberImmortal,关注我们,带你畅游AI世界!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com











