這年頭,AI圈裏這些大廠八卦的娛樂性真是越來越高了。
繼“Sora 偷日本版權內容被集體起訴”和“Midjourney 被控偷藝術家畫作訓練”之後,這回輪到了 Meta。
罪名有點難蚌:偷偷下黃片來訓練 AI。
起訴方由美國兩家老牌成人電影公司牽頭——Strike 3 Holdings 和 Counterlife Media(你經常會在某黑黃色 Hub 網站上看到他們的視頻)。
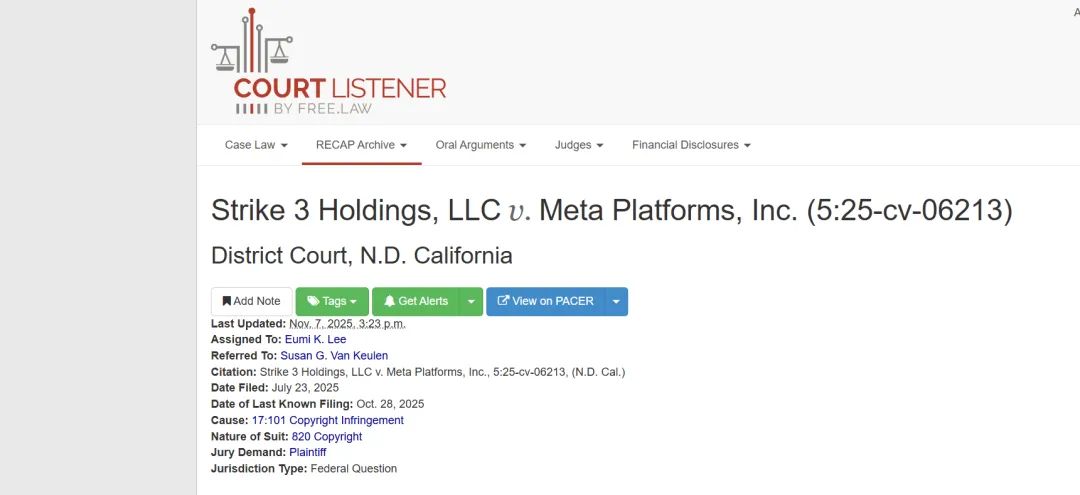
他們說,從 2018 年起,Meta 用 BitTorrent 下載了 2396 部成人電影,用來訓練自家的 AI 模型。
包括視頻生成器 Meta Movie Gen,還有 LLaMA 那些大模型。
要賠多少錢?
算下來 3.59 億美元,每部片子 15 萬。
這價,,,這邊個人建議 Meta 可以自己成立個部門專門來拍片,這樣成本還低一點。
案件還在審理,目前 Meta 作出的最新回應也很“風騷”:
我們沒下片,根據我們的內部調查,那是某位員工爸爸下的。

具體說法是這樣的:
Meta 提交了駁回動議,稱這些視頻“數量太少,不足以訓練 AI”,並且其中一些下載行爲來自“某位承包商父親的家庭 IP 地址”,與公司無關。
換句話說,不是我乾的,是我爹(員工老爹:爹也不能這麼坑啊)。
這理由一出,先不說別的,社區倒是笑嘻了。

再說回案件。
最早是 Strike 3 和 Counterlife 跟蹤到了 47 個與 Meta 有關的 IP 地址,而這些地址,從 2018 年到 2025 年,一直在穩定地下載並播種他們家的成人影片。

還不是普通人那種“偶爾下載”,而是高頻、長時段、分辨率多版本同步下載。
行爲模式非常像機器在幹活。
他們用 MaxMind 做了地理定位,發現其中一個 IP 地址屬於 Facebook 的公司網絡,還有幾個落在員工家裏。
看上去像是公司內部搞了幾臺服務器專門幹這個事,連員工家裏的 Wi-Fi 都變成了數據入口。
這下,Meta 想裝作“不知道”恐怕就有點難...
爲什麼偏偏是色情片?
Strike 3 的律師解釋得一本正經。
他們說,這些影片畫質高、鏡頭長、動作自然、情緒真實、對話連貫、場景變化少。
用來訓練 AI 模型,尤其是生成視頻的模型——再合適不過。
但鄙人認爲👆這個纔是更合適的解釋。
拍攝太快的電視劇不行,人物太多的綜藝不行,網紅視頻也太亂。
只有成人電影能提供長鏡頭的、連續的、以人爲核心的自然運動數據。
換句話說,這是訓練視頻生成模型的黃金素材。
你要訓練 AI 學“人怎麼動、怎麼說話、怎麼表情連貫”,
那這類視頻是最直觀的樣本。
問題是,這些片子,Meta 沒付版權。
而是從 BT 網絡上下載的,,如果你不懂 BT,那我說用x雷下片,我想在座的各位沒幾個不懂吧?
這背後暴露出的,是整個 AI 行業的灰色套路,也是整個計算機行業的一個潛規則:
訓練數據太貴,合法買不起,就先偷。
等被發現,再和解。

OpenAI、Stability、Google、Meta,哪個不是這麼幹的?
只不過這次,Meta 碰上了一個專門靠打官司賺錢的版權公司(這也是爲什麼這些公司這麼好心在某黑黃色 Hub 網站上免費放片的原因之一)。
Strike 3 每年打幾千起訴訟案,光靠寄律師函收和解費就能年入幾千萬美元。
對他們來說,抓這種大公司可比拍片賺錢多了。
這場官司,就像一場哲學討論。
到底什麼算“訓練素材”?
AI 模型吞下的數據,能不能包含版權內容?
當模型在生成畫面時,它算不算“再創作”?
這些問題沒人敢回答。
更滑稽的是——Meta 不是第一次被抓。
早在 2023 年,它就承認自己用 BT 等途徑,從大量非法渠道(其實就是盜版)下載了海量的書籍內容來訓練 LLaMA(其中包括 zlib)。
那次是“文學藝術”;這次是“動作片”。
方向不同,本質一樣。
AI 的胃口越來越大,什麼都能喫。
小說、音樂、新聞、影像,只要能喂進去,它都要。
而行業的邏輯也很簡單:誰先喂到足夠多的數據,誰就贏。
所以,Meta 被告的真正尷尬,不在於“看了黃片”,而是他們根本分不清自己餵了什麼給模型。
AI 模型喫進去的內容沒人能追溯。
公司內部的人大概率都不知道哪些文件被納入了訓練集。
就像有人半夜開了個下載腳本,第二天數據就自動進了倉。

而這正是整個 AI 領域的危險點:
當“數據來源不透明”成爲常態,沒人能分清模型到底學了什麼、用了誰的作品。
今天是成人電影公司告你,明天可能是醫院、出版商、新聞社。
再往後,說那啥點是個人都可以告你。

也許有人會笑 Meta 離譜,但殊不知其手機上的雲服務,上傳到社交平臺的照片、部分公開羣的聊天記錄等,都被廠商在你幾乎沒有察覺的情況下,拿來訓練。
所有的便利,都在一開始的“用戶協議”裏就標註好了價格。
它可能沒惡意,可它確實在看、在聽、在記。
這起官司鬧得再大,也不過是冰山一角。
我們在討論 Meta,卻其實是在討論整個行業的底線。
AI 靠什麼學?靠誰的數據?要不要徵得同意?
這些問題遲早要被擺上桌面。
只不過,這次是靠“2396 部片子”幫大家提了個醒。
Meta 目前還沒作出什麼很正式的具體回應或者對策,也許在準備技術解釋,也許在等法院判,也許乾脆在等大家忘。但不管結果怎樣,這個問題遲早要被解決。
技術在前跑,法律在後追。

我只希望,下次 AI 再被曝“看片訓練”等類似事件時。
Meta或者別的什麼能不能別把你老爹推出來擋槍?
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com









![不清楚是不是站崗站傻了,想不清楚去年發生了什麼,大事件記得[cube_捂臉哭]](https://imgheybox1.max-c.com/bbs/2026/06/28/bccafc3417454fb6e3871cef41a3b410.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)







