如果說CPU是計算機的“大腦”,善於處理各種通用型計算任務,但在面對大規模並行計算時,CPU就有點力不從心了。尤其是在圖形渲染、遊戲畫面處理、人工智能訓練等場景中,需要處理成千上萬的像素、頂點和矩陣運算,CPU的串行處理方式明顯效率不夠。

於是,GPU應運而生。最早的GPU被設計用於圖形渲染,一說到圖形渲染,聰明的你一定會想到顯卡,沒錯,GPU就是顯卡的核心元器件。
GPU的目標就是通過成百上千個小而高效的運算單元,實現對圖像的快速並行處理。
隨着AI、HPC的快速增長,GPU加速計算已經成爲推動科學發展的關鍵力量,在天文學、物理學等研究領域,GPU加速的AI正在幫助科學家們解決前所未有的複雜問題。
同樣是處理器,爲什麼GPU在並行計算中表現得如此出色?今天我們就從底層運作機制和設計原理,聊聊爲什麼GPU在並行計算的時候更高效。
處理器的三個組成部分
任何處理器的核心組成都離不開三部分:算術邏輯單元(ALU)、控制單元和緩存。但 CPU(中央處理器)和 GPU(圖形處理器)的 "工作思路" 卻大相徑庭。

簡單來說,CPU更善於一次處理一項任務,而GPU則可以同時處理多項任務。這是因爲CPU是爲延遲優化的,而GPU則是帶寬優化的。就好比有些人善於按順序一項項執行任務,有些人可同時進行多項任務。
通過打比方來通俗的解釋二者的區別:
CPU就好比一輛摩托車賽車,而GPU則相當於一輛大巴車,如果二者的任務都是從A位置將一個人送到B位置,那麼CPU(摩托車)肯定會更快到達,但是如果將100個人從A位置送到B位置,那麼GPU(大巴車)由於一次可以運送的人更多,則運送100人需要的時間更短。

換句話說,CPU 單次執行任務的時間更快,但是在需要大量重複工作負載時,GPU 優勢就越顯著(例如矩陣運算:(A*B)*C)。
因此,雖然CPU單次運送的時間更快,但是在處理圖像處理、動漫渲染、深度學習這些需要大量重複工作負載時,GPU優勢就越顯著。
綜上所述,CPU 是個集各種運算能力的大成者。它的優點在於調度、管理、協調能力強,並且可以做複雜的邏輯運算,但由於運算單元和內核較少,只適合做相對少量的運算。
GPU無法單獨工作,它相當於一大羣接受CPU 調度的流水線員工,適合做大量的簡單運算。
那麼是什麼導致CPU和GPU工作的方式不同呢?那還要從二者設計理念來說。
FLOPS並不是核心問題?
提到處理器性能,很多人會關注 FLOPS。但實際上,它並非決定效率的核心因素。
FLOPS每秒浮點運算次數(FLoating point Operations Per Second,簡稱 FLOPS)是基於處理器在一秒內可以執行的浮點算術計算數量,經常用來來衡量計算機性能的指標,表示每秒可以執行的浮點運算次數。

雖然有一些專家或特定算法的時候會特別關注FLOPS,但FLOPS其實並不是大衆關心的焦點。

爲什麼會這樣說呢?舉個例子,在CPU運行情況:CPU能以大約2000 GFLOPs FP64的速度進行運算,但內存卻只能以200 GB/s的速度向CPU提供數據,這是現代處理器的典型性能。
於是當CPU想要每秒處理2萬億個雙精度數值,但內存每秒只能提供250億個。這個時候就會產生設備的“計算強度”不平衡,這個時候就需要CPU設備需要付出多少努力來彌補內存提供數據的速度不足。
否則,處理器就會因爲閒置造成浪費,陷入所謂的“內存帶寬限制”模式。
而 GPU 的解決思路是:用高帶寬內存平衡計算能力。

比如 NVIDIA 的 GPU,不僅 FLOPS 更高,還配備了高帶寬內存(如 HBM),讓數據供給速度能跟上計算需求。但隨着 GPU 性能提升,計算能力增長往往快於內存帶寬,這就需要不斷優化算法,才能讓硬件高效運轉。
當然,高內存支持和代碼優化並不是GPU性能優勢的全部,我們還需要看一下延遲。
爲何延遲如此關鍵呢?
延遲,指的是從發起數據請求到數據返回的等待時間。它之所以關鍵,是因爲物理定律的限制 —— 電信號在芯片內傳輸需要時間,從內存取數據甚至可能耗時十到二十個時鐘週期。
我們可以通過一個時間線來直觀理解。從最基礎的運算操作來看:ax + y。
首先,要加載變量x。接着,加載y。因爲運算是a乘以x再加上y。
所以,會同時發起對y的加載請求。然後,會經歷一段相當長的等待時間,直到x的數據返回。這段時間往往是空閒的,也就是我們所說的延遲,這樣就導致計算非常不高效。
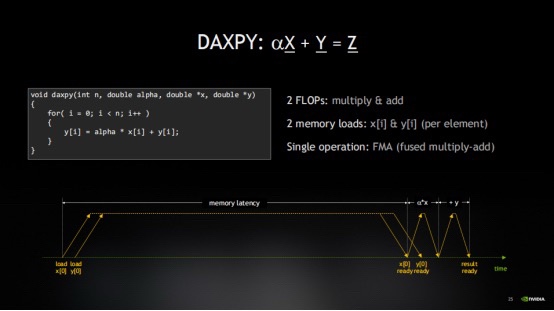
雖然這個時間很短,也可能被其它有用的計算工作所掩蓋,不會造成明顯的延遲。但處理器編譯器實際上花費了大量精力來進行流水線優化,確保數據加載儘可能早地發起,以便被其它計算操作所覆蓋。
這種流水線處理是大多數程序性能優化的關鍵,因爲內存訪問的延遲往往比計算延遲要大得多。

那麼爲什麼會這樣呢?
這是因爲在一個時鐘週期內,光只能傳播很短的距離。考慮到芯片的尺寸,電信號從芯片的一側傳輸到另一側可能需要一個或多個時鐘週期。
因此,物理定律成爲了限制性能的關鍵因素。尤其是當需要從內存中獲取數據時,數據的往返傳輸可能就需要十到二十個時鐘週期。

延遲就意味着花費了大量時間等待數據的到來。
CPU爲了減少延遲,會通過複雜的流水線優化,讓數據加載儘可能提前,用其他計算覆蓋等待時間。但即便如此,內存延遲仍可能成爲瓶頸。

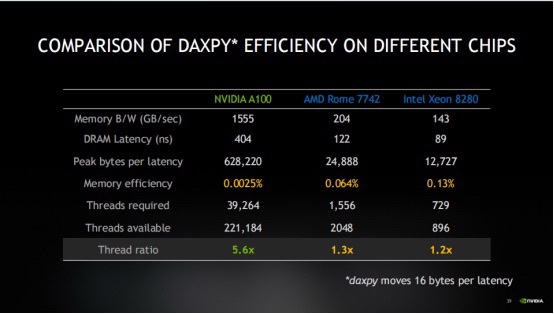
以Xeon 8280爲例,這款CPU擁有131GB的內存和89納秒的延遲。當內存帶寬爲131GB/s時候,那麼在一個內存延遲週期內,只能移動約11659字節的數據。
即使有高帶寬的內存來應對計算強度,實際上幾乎沒有利用到它的優勢。爲高性能的CPU和內存付出了巨大的成本,但結果卻並不理想。

這是因爲程序受到了延遲綁定的影響,這是一種常見的內存限制形式,其發生的頻率遠高於我們的想象。
如果將11659字節的數據除以16字節(即DAXPY操作加載x和y所需的總字節數),發現需要同時執行729個DAXPY迭代,才能讓花在內存上的錢物有所值。因此,面對這種低內存效率,需要同時處理729個操作。

這個時候,就需要併發來解決這個問題了。併發,顧名思義,就是同時進行許多事情。
GPU編譯器有一種優化手段叫做循環展開,它能夠識別出可以獨立執行的部分,並將它們連續地發出,從而提高執行效率。
但是在實際循環進行的優化方式受限於硬件能夠同時跟蹤的操作數量,幾乎是不可能完成的。在硬件的流水線中,它只能同時處理有限數量的事務,超出這個數量就不得不等待之前的事務完成。
因此,循環展開確實有益,它可以讓流水線更加飽滿,但顯然它也受到機器架構中其它多種因素的制約。
這個時候,就需要看硬件的所能支持的最大線程數了,這意味着多個操作是真正同時發生的。
線程在GPU中起到什麼作用?
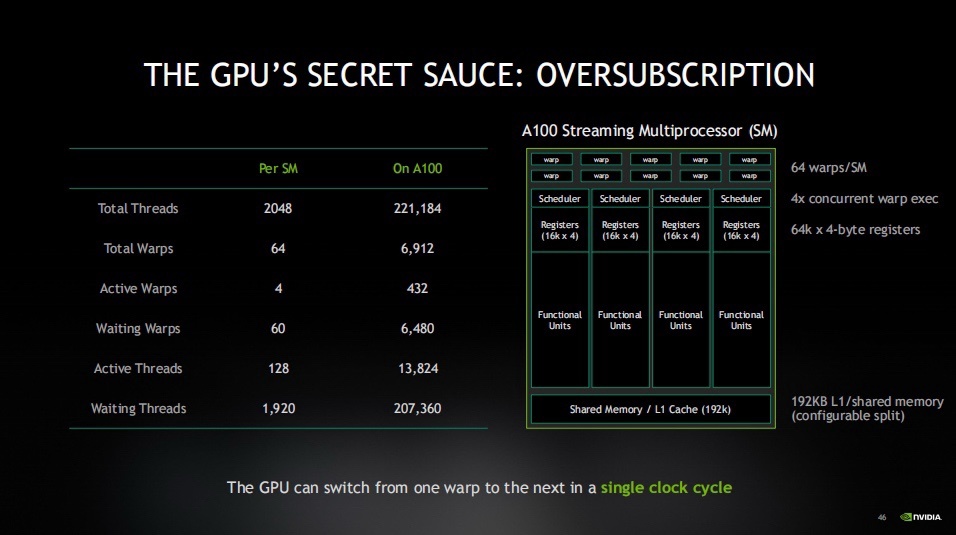
GPU與CPU之間一個非常值得關注的差異點,GPU的延遲和帶寬要求比CPU高得多,這意味着它需要大約40倍的線程來彌補這種延遲。

實際上,GPU擁有的線程數量比實際運算需要的多出五倍半,而其它類型的CPU,它們的線程數量可能只夠覆蓋1.2英寸範圍內的操作,這就是GPU設計中最爲關鍵的一點。
GPU擁有大量的線程,遠超過它實際需要的數量,這是因爲它被設計爲“超量訂閱”(oversubscription)。它旨在確保有大量線程在同時工作,這樣即使某些線程在等待內存操作完成,仍然有其它線程可以繼續執行。
GPU通常被稱爲“吞吐量機器”。GPU的設計者將所有的資源都投入到了增加線程數量而不是減少延遲上。相比之下,CPU則更側重於減少延遲,因此它通常被稱爲“延遲機器”。
記住,GPU設計者通過增加線程數量來對抗延遲,而不是通過減少延遲來降低延遲。
另外,需要注意的是GPU是被超量訂閱的。這意味着,當一些線程在等待讀取數據時,其它線程已經完成了讀取並準備執行。
GPU內存需要足夠大
除了線程設計,內存架構也是 GPU 高效的關鍵。所有計算都圍繞數據展開,而數據的存儲和訪問速度直接影響效率。
GPU爲每個線程分配了大量的寄存器來存儲實時數據,從而實現了非常低的延遲。這是因爲與CPU相比,GPU中每個線程都需要處理更多的數據,因此它需要能夠快速訪問這些數據。
所以,GPU需要一種靠近其計算核心的快速內存,並且這種內存需要足夠大,以便能夠存儲進行有用計算所需的所有數據。
不僅如此,當你發出一個加載操作(比如將某個指針的值加載到變量x中)時,硬件需要一個地方來暫存這個加載結果。而GPU所擁有的寄存器數量直接決定了它能夠同時處理的內存操作數量。
GPU的主內存就是高帶寬的HBM內存。如果我把GPU主內存的帶寬看作一個單位,無論它有多快,都只能算作一。而L2緩存帶寬則是它的五倍,L1緩存,也就是我即將提到的共享內存,更是快了13倍。
因此,隨着帶寬的增加,它更容易滿足計算強度的需求,這無疑是一件好事。
GPU工作中是如何獲取吞吐量的?
GPU 之所以在並行計算中高效,核心在於它的設計完全圍繞 "吞吐量" 展開。

我們假設訓練了一個AI來識別互聯網上的貓。現在,我們有一張貓的圖片。我會在這張圖片上覆蓋一個網格,這個網格將圖片分割成許多工作塊。
然後,我會獨立地處理每個工作塊。這些工作塊是彼此獨立的,它們在圖片的不同部分工作,而且工作塊的數量非常多。
因此,GPU會被這些工作塊過度訂閱。但記住,過度訂閱是我們追求高效執行和最大內存使用的一種策略。
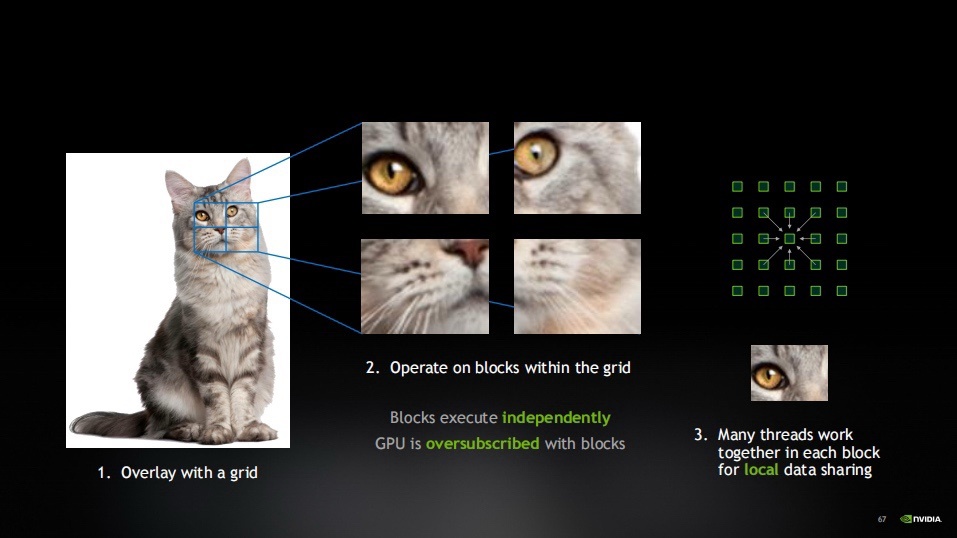
在每個工作塊中,都有許多線程共同工作。這些線程可以共享數據並完成共同的任務。所有的線程都同時並行運行,這樣GPU就能夠實現高效的並行處理。
現在,已經構建了層次結構。在最高層,有總工作量,它通過網格被分解成工作塊,這些工作塊爲GPU提供了所需的過度訂閱。然後,在每個工作塊中,有一些本地線程,它們一起協同工作。
通過這種方式,能夠充分利用GPU的並行處理能力,實現高效的吞吐量。
如今,GPU 已從圖形處理擴展到 AI、科學計算等衆多領域。未來,隨着帶寬瓶頸的進一步突破,GPU 還將解鎖更多可能性。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com









![不清楚是不是站崗站傻了,想不清楚去年發生了什麼,大事件記得[cube_捂臉哭]](https://imgheybox1.max-c.com/bbs/2026/06/28/bccafc3417454fb6e3871cef41a3b410.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)




