来源——硬件世界
最近,两款国产GPU引发极大关注,一款是摩尔线程MTT S90,另一款则是号称真自研的砺算科技7G100系列。两款显卡在性能上都实现了巨大飞跃,在多个测试项目中逆袭RTX 4060。
首先是摩尔线程新一代显卡MTT S90游戏GPU,实测性能展现出与NVIDIA主流产品RTX 4060相当的水平。
据了解,MTT S90是摩尔线程在两年前就计划推出的产品,与其AI智算卡MTT S4000采用同一芯片架构。知名博主“差评”对摩尔线程S4000的图形性能进行了实测跑分,考虑它与S90同宗同源,基本可以拿来参照。
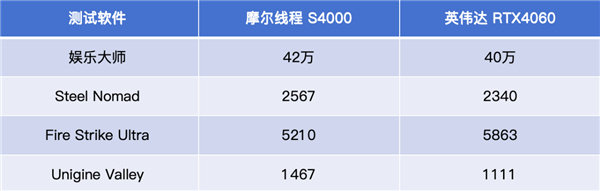

实测结果显示,摩尔线程S4000的鲁大师、3DMark Steel Nomad和Unigine Valley得分均超过RTX4060,只在Fire Strike Ultra中稍逊一筹。
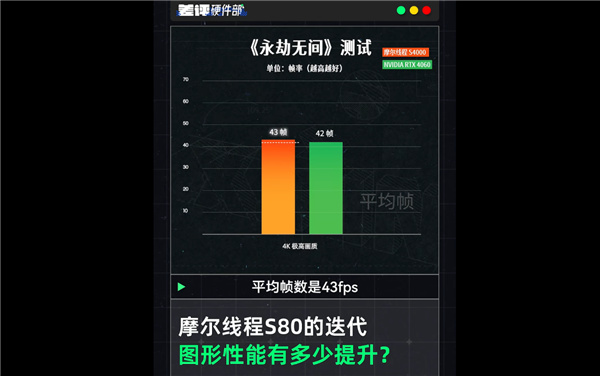
不仅是Benchmark,该卡在实际游戏测试中尤为亮眼,4K极高画质设定下的《永劫无间》平均帧率达到了43fps,同样略高于RTX 4060(42fps)。
据悉,测试版驱动并未针对S4000进行过专门的优化,如果能像S80一样持续深度优化,S4000很可能在图形性能上实现对RTX 4060的大幅超越。
摩尔线程S4000于2023年9月正式发布,与RTX 4060基本属于同时期发布,可以说已经追上了同时期NVIDIA主流型号的性能水平。
依照“差评”的测试数据,对比S80在最新驱动下的性能,其跨代性能提升达到了80%以上。考虑到S4000只比S80晚发布不到一年,这个跨代提升幅度可谓惊人。
另一款是7月26日砺算科技发布的首款GPU芯片7G100系列。据官方介绍,砺算7G100系列作为一款全自研高性能图形GPU,从指令集到计算核心完全由自主设计,基于自研TrueGPU天图架构,并自研指令集、自研软件栈(非市场中常见的通过采购Imagination等现成IP授权),多重性能优势达到国际主流、国内领先水平,完全掌握着GPU架构的自主权。
此外,砺算GPU支持NRSS动态优化渲染画质,可对标NVIDIA DLSS和AMD FSR技术。
其中,7G106主打消费级显卡,搭配12GB GDDR6显存,支持4x DP 1.4a接口,支持8K60Hz HDR FreeSync显示分辨率,API方面支持的DX12、Vulkan 1.3、OpenGL 4.6、OpenCL 3.0等。

从3DMarK Fire Strike、Steel Nomand基准测试来看,7G106略低于RTX 4060,但二者基本处于同一水平。Geekbench OpenCL基准测试中,7G106表现抢眼,不仅压了RTX 4060一头,甚至直逼RTX 5060。
游戏性能方面,《黑神话 悟空》平均FPS>70(分辨率:1080p 画质:高)。最新测试显示,7月24日正式上线的国产第二款3A大作《明末:渊虚之羽》同样能流畅运行。
虽然两款国产GPU和NVIDIA高端产品仍有很大差距,但性能已经媲美其主流产品,更意味着国产显卡从可用变成了好用。
以上也充分说明,国产GPU企业通过技术研发和产品创新,部分产品性能已接近或超越国际同类产品,在市场上具备了一定竞争力,能够与国际大厂竞争,打破国外企业的垄断局面,促使全球GPU市场竞争更加充分。
对于国内游戏玩家,意味着未来将有更多选择,且国产芯片在价格上可能更具优势,可降低硬件购置成本。同时,游戏开发者能更有针对性地对国产GPU进行优化,开发出更贴合国内玩家需求的游戏。
在2025世界人工智能大会上,沐曦也正式发布了基于国产供应链的旗舰GPU曦云C600。
沐曦表示,曦云C600标志着国产高性能GPU实现历史性突破。
该芯片基于沐曦自主知识产权核心GPU IP架构,构建从设计、制造到封装测试的全流程的国产供应链闭环,核心技术自主可控。
据介绍,曦云C600集成大容量存储与多精度混合算力,支持MetaXLink超节点扩展技术,并内置ECC/RAS多重安全防护模块。
曦云C600为金融、政务等关键领域提供高可靠算力基座,满足下一代生成式AI的训练和推理需求,性能强劲,全面对标国际旗舰GPU产品。
此外,沐曦联合创始人、CTO兼首席软件架构师杨建博士还首次全景披露MXMACA软件栈技术体系,展现国产GPU的“端到端”能力闭环。
杨建将MXMACA比作“AI领域的Android系统”,单机16卡即可支持百任务毫秒响应的工程实践,将高性价比算力落地变为可能。
另外在大会上,华为首次展出被称为“算力核弹”的昇腾384超节点真机,即Atlas 900 A3 SuperPoD。
华为表示,昇腾384超节点被评选为本次WAIC 2025镇馆之宝。
昇腾384超节点通过高速互联总线,突破互联瓶颈,让超节点像一台计算机一样工作。
相比传统集群,主要有以下3大优势:
超大带宽
超节点内任意两个AI处理器之间通信带宽,相较于传统架构提升15倍,超节点内单跳时延降低10倍。
超低时延
昇腾超节点支持全局内存统一编址,具备更高效的内存语义通信能力。通过更低时延指令级内存语义通信,可满足大模型训练/推理中的小包通信需求,提升专家网络小包数据传输及离散随机访存通信效率。
昇腾384超节点是业界唯一突破Decode时延15ms的方案,满足实时深度思考下的用户体验需求。
超强性能
经过实际测试,在昇腾超节点集群上,LLaMA3等千亿稠密模型训练性能可达传统集群的2.5倍以上。
在通信占比更高的Qwen、DeepSeek等多模态、MoE模型上,可以达到3倍以上的提升。
据了解,昇腾384超节点首创将384颗昇腾NPU和192颗鲲鹏CPU通过全新高速网络MatrixLink全对等互联,形成一台超级“AI服务器”,其算力总规模达300Pflops,是英伟达NVL72的1.7倍。
网络互联总带宽达269TB/s,比英伟达NVL72提升107%;内存总带宽达1229TB/s,比英伟达NVL72提升113%;单卡推理吞吐量跃升到2300 Tokens/s。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















