前言
這篇不是零基礎教程!最起碼你也是突擊了一遍課本準備解決做題做不對的問題纔來看這個。
雖然基本包括了所有知識點,並且詳細講了裏面的考點易錯點,但是不會把最基礎的怎麼寫這一類東西拿出來說,
這是給在上完課/自學過之後,用來應對c語言考試用的,是針對c語言考試喜歡出的題型進行特化的。
因爲C語言考試和實際的開發隔得很遠,會開發並不一定會做那些題,所以有了這篇專爲應試考點特化的文章。
同時文章對考試中喜歡考的那些類似“茴香豆有幾種寫法”這些沒什麼營養甚至不太規範的考點進行了重點提醒。
另一方面,在c中,曾流行這樣的寫法
a == 6 && a += 5
a == 6 || a += 5
這些寫法的確是更緊湊了,代碼佔用的存儲空間更小了,代碼量更少。
但是這些寫法並不好,因爲它非常不利於代碼的可讀性和可維護性,可能會誤導維護者。還可能導致未定義問題,一些順序可能會未定義。
而且這類寫法很可能會出現邏輯運算的短路問題,就是對於||,只要兩邊有一個是成立,那就成立;對於&&,只要左邊是 false那就不用做右邊了就是false。。像這樣左邊就 已經能決定結果,就不會做右邊的運算。這就會導致右邊的a+=5不會執行。
一些教材還是喜歡拿這種東西來折騰,可能跟作者的年代有關,也與可能是單純需要一些方便考察的東西用來考察。
基礎
使用IDE
可以使用dev-c++,它簡單快捷,不需要我們手動配置編譯器。
如果要使用這個,建議編輯器裏字體選黑體。
更好的是使用vs code,它在各方面更加適合使用。
報錯
常見的語法錯誤常常是
expected xxx before yyy
就是說期望在yyy前面要有xxx。
通常是末尾漏掉分號的時候,這樣對下一行報錯。
因爲c語言換行不意味着任何事情。
然後還有就是用了全角符號,就會stray \xxx
有可能會報三個錯,比如說用了全角的分號,兩個是stray \xxx,因爲這個符號可能用到兩個字節去表示;然後再報一個缺失分號的
格式化輸出printf
printf最簡單的用法是可以用來直接打印一個字符串:
printf("hello world\n");
還可以格式化輸出,比如%d是格式化一個數值
printf("%d", 12+34);
也是和前面打印hello world一樣,把這個字符串打印出去,只是不同的是它把%d這裏替換爲後面輸入的這個12+34的值。
注意%d是輸出爲十進制。%x是輸出爲十六進制。
%p是輸出爲一個內存地址那樣的形式。
%f是打印float,默認是打印出存儲的全部精度,還可以控制打印的小數位數,比如%.2f表示打印兩位小數。
%lf是打印double
%c是打印字符
%s是打印一個字符串。
考試可能會出的寫法
控制字符的格式爲%[標誌][寬度][.精度][長度]轉換字符
但只需要掌握標誌、寬度、精度、轉換字符即可
考試可能會出#,是會根據打印的類型補上一個前綴
二進制、十進制則沒反應,八進制補上前綴0,十六進制補0x
寬度是打印的這個東西的寬度。如果不夠就在左側補空格。
printf("%8d", 121); // >> 121
精度就是.2之類的,表示顯示到小數點後幾位。
除了前面說的那些%f、%p什麼的,打印數字,控制字符也可以有很多花樣
%d是打印十進制整數,%x是十六進制整數,
%u是無符號十進制整數
變量
int、float、char
有幾種大類:
整數:char、
浮點數
邏輯
指針
自定義
注意,整數的在內存裏存的是二進制數,而浮點是需要編碼的,所以不能直接拿來做運算,自然把浮點%d也不會有結果。
而且,浮點數是包含了正負無窮大(+INF和-INF)和不存在(NAN)的,所以整數除以0會報錯說未定義,但是浮點數除以0是會得到NAN
以及,小數默認是使用double而不是float,所以需要1.345f這樣後面加個f後綴表示。
變量名,只能包括字母、數字、下劃線;第一個字不能是數字;不可以用c的關鍵字(如果用到可以加點下劃線、數字,比如myint1,my_return之類的)。
強烈建議在變量聲明時賦一個初始值,不然要是後面也忘記了賦值
另外應試可以變量名寫得隨便一點,課本上也是這樣寫的,什麼int1,num1,a,b,c之類的,包括在平時舉個例子之類的也可以這樣寫,很方便。
但是在開發中這是個壞習慣,會影響自己或別人分析代碼。如果真的
浮點數
可以嘗試一下3/2,發現結果是1.
這是因爲這是3和2都是整數,在c裏面整數相除只能得到整數,也就變成了整除(丟棄小數部分,不是四捨五入)。
所以要用浮點數,也就是3.0/2.0
包括我們要存儲的可能帶小數時,也得使用float或float.
然後,如果是運算兩邊是整數和浮點數,c會先進行格式轉換把兩個都變成浮點數,然後再運算 (隱式轉換)。
由於浮點數有精度問題,可能會出現兩個相等的浮點數內部表示的不同,然後就不相等。
所以比較兩個浮點數不能要用等於,而是比較它們的差距,如果它們的差距小於保存的精度差異,比如說
fabs(a-b) < 1e-12
所以,一些精確的數據計算就不能用浮點數,比如說算錢的時候。算錢可以用整數去算,以分爲單位。
字符
之前說 ,字符型是一種整數型的數據類型。因爲實際上它是用整數表示。
所以,對char賦值的時候,可以賦一個數字(ascii),也可以給一個單引號括着的字符。
char c = 65; char d = 'A'
實際上, 'c' == 49。
所以我們甚至可以搞一些好玩的:判斷一個字符是不是大寫字母,可以
my_char >= 'A' && my_char <= 'Z'
格式化輸出的時候,用%c。當然也可以用%d來輸出
所以,
char c = ' ';
scanf("%c", &c);
printf("c = %c,也是%d", c, c);
char是單引號。
轉義字符(逃逸字符)
比如說要在雙引號裏用雙引號,得在裏面那個前面加個反斜槓來轉義。然後\\表示反斜槓本身。
還有\n、\t等特殊字符也是。
注意換行符的機制是在一行的固定一些位置,而不是多少個字符,
比如
printf("ab\t");
printf("\n");
printf("abc\t");
會能夠看到這兩行是對齊的。
只是通常IDE會把tab替換爲四個空格(沒有替換就麻煩了!對於Python等用縮進來控制的語言,tab和空格混用會導致嚴重的問題)
一個有意思的東西是\b,比如說abc\bd,顯示出來就是abd。表示用後面這個去覆蓋前面這個。
又比如說,空格我們也可以用轉義字符來寫,寫成\x20.
邏輯類型
bool
注意它是需要引入stdbool.h才能使用,而且實際上它就是一個int。要想顯示它也只能用%d
所以c裏面的bool其實不太算是一個原生的類型。
類型轉換
自動轉換(隱式轉換):當運算符兩邊出現不一致的類型時,會自動轉換爲容量較大的類型。
char -> short -> int -> long -> long long
int -> float -> double
然後賦值給一個類型不同的內容也會自動轉換,比如把1賦值給float,會自動把它轉換爲int;而如果把1.45賦值給int則會轉換爲int(丟失精度),然後一些編譯器會給一個warning.
而且,printf會把所有小於int的類型轉爲int,把float轉爲double。因此
然後我們也可以手動地去做類型轉換
(int)32.5就是強制把32.5轉爲int
常量
在程序中會有一些常數是不變的,這些不要直接寫在程序裏,讓人莫名其妙不知道是什麼、爲什麼是這個數。(這種令人莫名其妙的行爲稱爲magic number)
而是定義一個常量。
const int AMOUNT = 100;
const只是一個修飾,後面還是一個變量定義的格式,只是表示這個被保護了不可變而已(後面如果試圖修改就會報錯)。
常量名一般用全大寫,然後用下劃線分隔多個單詞。
這樣的好處很明顯,除了更易讀,以後想要改這個常數(比如以後倍率變了)的時候,只需要在這個常量這裏改一處就行了,更好維護。
sizeof判斷
注意如果要打印的話是%zu,因爲它是一個無符號整數。
int是4個字節,double是8個字節。
但是sizeof是靜態的,裏面如果包含了賦值等(比如a++),並不會被執行,只是取這個值。
宏定義
也叫符號常量。
比如
#define PI 3.14
實際上就是一種字面量的替換。寫了這個,在編譯前編譯器會把代碼中所有PI替換爲3.14,僅此而已。
當然也可以加上一些邏輯判斷什麼的。
運算
加減乘除+-*/
%是取餘。
賦值(=)也是一個運算符,優先級最低。
注意賦值是有返回值的,就是我們賦給變量的值。這也是爲什麼我們可以a = b = 3+9這樣,因爲b = 9執行完後,返回值會是9,然後再賦值給a。
因此也許會有些刁難的題目,出些
int c = 1 + (b=a);
這樣的題目,把賦值通過嵌入到運算內部。
複合賦值【重要考點】
+=、-=、*=、/=等。
考試也可能會故意出些沒什麼實際意義的奇怪寫法,比如什麼 total += total * (sum +12);
還有++,--,分別表示+=1、-=1。
這裏就出來一個考試喜歡故意玩弄的東西了:a++與++a。
a++和++a都表示a = a+1。
所以和一般的a = a+1這樣,它會返回a的值。
它們的不同在於,a++是返回a的值再給a+1,而++a是先給a+1再返回+1後的a
int a = 10; int b = 10; printf("a++=%d\n", a++); printf("++b=%d\n", ++b);
比如這個我們就可以看到,a++的返回值還是10,而++b的返回值是11.
然後考試還會結合
常見陷阱題
正常的入門教材應該指出哪些是未定義行爲,並且提醒初學者主動避免未定義行爲,而不是像某些書籍那樣去研究未定義行爲(因爲這種研究毫無意義)。
(當然,由於這兩個的不同是這個運算的返回值,也就意味着如果我們並不用它的返回值,只是想要讓a +=1而已,那兩個都可以,不會有差異。比如在for裏面,最後是寫i++還是++i都是一樣的了。)
邏輯運算
!爲非
&&爲與
||爲或。
注意,!是單目運算符,比所有雙目運算符的優先級都高。所以 ! age > 20是不對的,會變成判斷!age是否大於20.,由於!age只可能是0或1,所以!age>20恆爲0(false)。
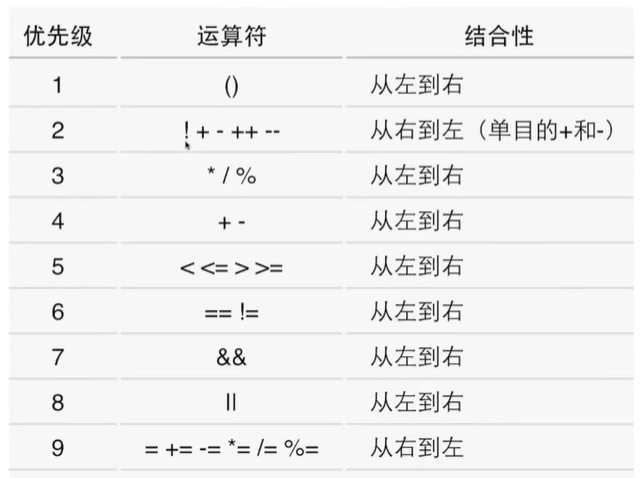
條件運算符
count = (count >20)?count-10 : count+10;
printf((count >20)?"20以下" : "20以上";)
條件、條件滿足時的值和條件不滿足時的值。
可以在表達式中暗含一個if判斷。有時候只是想簡單輸出一個狀態時很有用
其他時候不太建議這樣用。
位運算符
<<
>>
這個一般不考
運算符優先級
格式化輸入 scanf
scanf("%d", ¶m);
裏面的%d表示要讀取一個整數
而後面的param是接收這個整數的變量,但是要在前面加上一個&表示取地址,這個在指針部分再詳細說明。
int price = 0; printf("你有一張100元的鈔票。輸入你購買商品的價格:"); scanf("%d", &price); printf("找您%d元。", 100 - price);
然後如果用戶輸入的字符串不是一個數字,而是一些隨便什麼別的比如hello,那price就還是初始值0。
當然也可以去對這種情況去做判斷來獲取。
然後可以設置好格式,就可以輸入多個值。比如
scanf("%d %d", &a, &b);
注意裏面的空格是要求輸入一個東西。比如,如果上面這個只輸一個120,回車,它會要求再輸入一個東西(也就是給b的)。
而如果是"%d %d "後面還多一個空格的話,那就是在輸完兩個數之後還要再給它一個東西,當然那個可以隨便填。
所以scanf別學着printf那樣在末尾加一個\n,那樣的話就會被要求再輸入第三個東西
出現在scanf字符串裏的東西,是它要你輸入的東西,不是它給你看的東西。
注意printf和scanf別亂寫,比如打印的是整數就別寫%f,不然會出現值是0或者是亂七八糟的數。
也不要%d,但是操作的卻是一個char變量。
而且,scanf如果是讀兩個值,一定要按照自己設置的格式來,比如scanf("%d %d", &a, &b);,那兩個值之間就一定得是用空格隔開;寫的是逗號就得是逗號。不然第二個值就讀不到了,就是初始值了。
判斷語句
if
if (條件){ }else if(條件){ }else{ }
if如果要執行的內容只有一行,可以不寫大括號直接寫在if同一行。
if (a>3) printf("a>3");
也可以這樣寫:
if (a>3) printf("a>3");
因爲直到最後的分號才代表這一行語句的結束。
switch
switch (要判斷的表達式){ case 常數1: // break; case 常數2: // break; default: }
如果switch的表達式等於某個case後面寫的數,就會執行對應的那一條。
但是注意,switch case只能用於判斷int
可以發現,switch的結構是隻有它有大括號,裏面的case的內容不是大括號括着的。 實際上由於它實現的方式,實際上switch裏面的各個case是在同一作用域的。所以,比如是case1,如果沒有break跳出switch,那它會一路往下,一路把後面的case2,case3什麼的都執行了。
這些case是沒有劃分作用域的作用,只是一個“站牌”而已,不會阻止程序繼續往下運行
循環
while
當條件滿足時一直執行。可以從另外一個角度理解,就是類似if,只不過在條件滿足、執行完一次後會再次判斷
while (條件){ }
do-while
有些時候我們會希望,無論如何都先進行一次while裏面的內容(比如這樣處理才能產生循環所判斷的數據),這時候就可以換成do-while
do { }while ();
別忘了這種寫法下while後面的分號!
for
注意,在dev-c++中for會報錯,因爲它的編譯器默認沒開c99。
可以自己在cmd用gcc編譯。
通過編譯器選項啓用 C99
打開 Dev-C++,點擊菜單欄中的 “工具” -> “編譯器選項”。
在彈出的“編譯器選項”窗口中,切換到 “設置” 標籤頁。
在“設置”標籤頁中,找到 “編譯器” 下拉菜單,選擇 “GCC Compiler”。
在“編譯器”選項卡中,找到 “命令行參數” 部分,並在 “添加編譯器命令行參數” 框中輸入 -std=c99。
點擊 “確定” 保存更改。
或者直接把自己的mingw添加爲編譯器即可。
continue和break
使用continue或break可以在循環中實現跳出。
其中,continue是跳出本次循環,循環裏往後的代碼不再執,直接跳到下一次(比如說i++)
而break是直接結束循環,開始執行循環後面的內容。
比如說,我們可以用它來輸出素數
!!注意!1不是素數!
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int is_loney(int num){
int flag = 1;
for (int i = 1; i<= num; i++){
for (int j = i; j <= num; j++){
if ((i*j == num)&&(i!=num)&&(j!=num)){
printf("%dx%d=%d ", i, j, num);
flag = 0;
break;
}
}
}
printf("\n"); return flag;
}
void main(){
int num = 0;
while (1){
printf("輸入一個數:");
scanf("%d",&num);
printf("%d是否素數?%d\n\n", num, is_loney(num));
}
}
是不是想寫成這樣?但是實際上,我們可以直接用取餘就能解決這個問題
#include <stdio.h> #include <stdlib.h> #include <time.h> int is_loney(int num){ int flag = 1; for (int i = 2; i< num; i++){ if (num % i == 0){ printf("%d是%d的係數 ", i, num); flag = 0; break; } } printf("\n"); return flag; } void main(){ int num = 0; while (1){ printf("輸入一個數:"); scanf("%d",&num); printf("%d是否素數?%d\n\n", num, is_loney(num)); } }
goto
如果是多重循環,如果要一次性跳出,通常是用一個flag,在每個for末尾判斷如果已成功就break。
也可以使用goto。
goto out;
........
out;
在我們需要的地方寫一個跳出點(比如這個out),然後在循環裏goto即可。
但是,使用goto很容易導致各種問題,目前多數語言都取消了這種設計,更推薦使用函數包裝、狀態變量等來實現。
調試器
可以使用調試來調試
比如說dev-c++,先在代碼上點幾個斷點,然後點擊調試即可。
然後會出現調試的那幾個按鈕,左邊工具欄也會顯示各個變量的值。
可能會有bug,需要在主函數末尾加一個`system("pause");或者getchar();,不然會直接無視所有斷點直接運行完,也就表現爲終端窗口一閃而過。
注意在第一次調試之前,要先菜單欄的工具-編譯器選項-代碼生成/優化-連接器-產生調試信息,改爲Yes。
想要執行一行,就點下一步。
不過下一步是不會把函數的步驟調試的,函數是直接一次執行完的。如果是希望調試函數里面的內容,需要點單步進入。
函數
函數可以把某個功能包裝起來,增加可讀性;同時也使代碼複用,避免出現代碼複製現象,這是程序質量不良的表現。
void sum(int begin, int end){ }
定義時,函數名前面要寫類型,裏面的參數要聲明。
注意,調用函數時,如果不寫括號就變成是指針了
函數原型
由於一個函數需要先調用才能使用(c沒有變量提升等),這意味着我們必須先把所有用到的函數都寫在main的前面。
否則,編譯器會去嘗試猜這個函數是怎麼樣的
void main(){
cheer(5)
}
void cheer(int times){
// 內容
}
像這樣,在cheer(5)的時候,它會猜測cheer是int cheer(int times),但實際上並不是,所以在讀到後面的真正的cheer定義的時候,就會報錯。
這時候可以使用函數原型
void cheer(int times);
void main(){
cheer(5)
}
void cheer(int times){
// 內容
}
第一行這個就是函數原型,用來提示這個函數的各個類型,避免編譯器去猜又猜錯。裏面的參數可以只寫類型不寫名字。
實際起到的作用就是js中的變量提升的功能。
還有就是,原型設計的時候其實是可以不寫參數,表示不清楚。但是這樣編譯器會猜測裏面的值,結果就導致出現猜錯的問題。因此不要這樣,函數原型一定要把所有參數寫全。
返回值
然後要注意就是,如果是那種需要使用
main也可以有返回值,那個是用來給外部調用看的,比如說如果是在shell裏面調用,可以讀取這個的返回值。
傳參:形參和實參
這個時候我們會發現,如果
void main(){
int a = 3, b =4;
swap(a, b);
}
void swap(int x, int y){
int cache = x;
x = y;
y = cache;
}
這並不能調換a和b。
而且,如果調試會發現,在swap內部,a和b會變成"在當前上下文未找到"。因爲a和b是聲明在main裏的,現在不在作用域內。
傳參時,傳入的a、b是實參,會把實參的值傳遞給函數。
然後函數里面接收的那兩個變量叫形參,是在函數定義域內新建的兩個變量,你也可以把它們命名爲a、b,但是和外面的a、b沒有關係。
局部變量與全局變量
以大括號作爲塊,定義在塊裏面的就是局部變量。定義在函數里面、循環裏面等的,是局部變量。
全局變量是直接寫在代碼根部的
局部變量可以覆蓋同名全局變量
int a=5;
if (b == 2){
int a = 0;
printf("a:%d", a);
}
當然不是所有語言都是這樣的。
以及,在同一個作用域就不能定義同名變量裏,會報錯說重定義。
數組
int number[100];
類型表示它裏面每個都是int。後面有方括號表示它是一個數組。
後面的中括號裏面的數字是聲明長度。可以不填,在後面賦值的時候才確定。在c99及以後也可以使用某個變量。
然後可以通過number[i]來訪問裏面的第i項。
數組賦值
給數組賦值,比如說初始化,除了用for遍歷nuber[i]這種形式,給數組賦值時也可以
int number[10] = {0,0,0,0,0,0,0,0,0,0};
像這樣去寫來表示一個數組。
但其實有更簡單的特性:如果這種大括號寫法,裏面的列表項數量少於數組元素數量,會自動把剩餘的初始化爲0.
因此,直接
int number[10] = {};
即可達到同樣的效果,生成一個全爲0的數組。(但是考試還是建議寫{0},更明確,和課本的一樣,避免老師不認識)
還可以指定其中幾個
int number[10] = {[1]=5,4,[7]= 8};
像這樣,就會得到除了number[1] == 5,number[2] == 4, number[7] == 8,其它都是0.
同時,數組的長度也可以不填只寫一個空的中括號在那裏,它會在第一次賦值的時候根據賦值設置的最大下標,把長度設爲那麼多長。比如
int number[] = {0,0,0,0,0,0,0,0,0,0}; // 將會產生一個長10的數組
int number[] = {[1]=5,4,[7]= 8}; // 將會產生一個長爲8的數組
注意數組不能用來賦值另一個數組。要把一個數組的所有元素交給另一個數組,必須採用遍歷的方式。(後面會講,否則會因爲發生隱式轉換而變成把指針賦值給它)
左值和右值
c的數組索引是從0開始的,所以索引只能在[0,數組長度-1]之間。
但是編譯器並不會去檢查這個下標是否會越界,所以一旦越界就可能導致嚴重後果。
通常報錯Segmentation fault就是內存越界。
那麼我們可以寫點東西:

很明顯,這個並不需要存儲每個輸入的數,只需要一個數組用於統計0-9,也就是
#include<stdio.h>
void main() {
int number[10] = {0,0,0,0,0,0,0,0,0,0};
int input = 0;
do {
scanf("%d", &input);
if ((input >=1)&&(input <=9)){
number[input] += 1;
}
}while (input != -1);
for (int i = 0; i< 10; i++){
printf("%d:%d\t", i, number[i]);
}
}
裏面多次出現了10,可以把這個數組長度10給定義爲常量更好。
遍歷數組、數組大小
如果給出一個數組,不知道該怎麼做的時候,那自然是先數個數,然後去遍歷。
這就有點尷尬了。
其實,我們可以獲取它的長度
int number[] = {0,0,0,0,0,0,0,0,0,0};
此時sizeof(number)能獲取到數組佔用的內存大小,而sizeof(number[0])能獲取到數組第一項佔用的內存大小(int是4字節),由於每一項都得是一樣的(都是int),除一下即可得到長度。
sizeof(a)/sizeof(a[0])
因此,要遍歷一個數組,只要用類似這樣的方式就可以了:
int a[] = {1,2,3,4,5};
for (int i = 0; i < sizeof(a)/sizeof(a[0]); i++){
printf("第%d項:%d\n",i, a[i]);
}
實際上,數組就是一段連續的內存,分配了這麼多(比如說是int,長度爲8,那麼就是連續的4*8 = 32字節)
注意,c的數組大小一旦確定下來就沒辦法修改。
所以通常來講,要麼就是設置長度爲]]
程序效率優化
if的執行其實還是很快的,主要問題是循環。所以我們可以儘可能去減少循環的次數
比如說判斷是否是素數
int is_prime(int num){
bool result = true;
if (num == 1){
result = false;
}else {
for (int i = 2; i < num; i++){
if (num % i == 0){
result = false; break;
}
}
}
return result;
}
原本是num-1次
那麼我們可以優化一下,比如,2是素數,然後除此之外所有偶數都是2的倍數,不是素數,所以把所有2
int is_prime(int num){
bool result = true;
if ((num == 1)||((x!=2)&&(num % 2 == 0)){
result = false;
}else {
for (int i = 3; i < num; i+=2){
if (num % i == 0){
result = false;
break;
}
}
}
return result;
}
這樣由num-1次變成現在這樣,(num-1)/2,縮短了一半的時間。
二維數組
在名稱後面多加幾個中括號就是多維數組。
它的本質就是外層數組的元素還是數組。
兩個就是二維數組。第一個是行標,第二個是列標。
遍歷
for (int i = 0; i< 3; i++){
for (int j = 0; j<5; j++){
a[i][j] = i*j;
}
}
遍歷二維數組需要用兩個變量來遍歷索引。
賦值
同樣也可以這樣初始化
int a[][5] = { {0,1,2,3,4},
{2,3,4,5,6}
}
注意,二維數組的列數不能省,不能讓編譯器去幫你數(雖然是列數其實是外層數組的每個元素的長度。)
經典實戰題:井字棋裁判
輸入一個二維數組表示的棋盤,判斷現在的勝負.
檢查行,就是判斷這一行X的數量夠不夠三個;檢查列,就是這一列的X的數量夠不夠三個;檢查對角線,就是for 0-3,判斷[i][i]形成的對角線和[3-i][i]形成的對角線。大致就是這樣。
指針相關
取地址
前面scanf接收數據的變量需要在前面加上&
實際上,&表示獲取變量所在的內存地址。它的操作數必須是變量。
注意,32位下的內存地址是4字節(32位bit),而64位下的內存地址是8字節(64位bit)
然後,如果我們試圖
int a[10];
printf("%p", &a);
printf("%p", a);
printf("%p", a[0]);
就會發現,三個是一樣的。也就是說,數組本身就是一個地址!同時它的第一位也就是它的第一個元素的地址。
指針
說明:
在下文,指針指的是一個內存地址,而指針變量指的是存儲一個內存地址的變量。
有的地方可能會把兩者混爲一談,但本文不採用那種講法。
我們知道,&i表示獲取i的內存地址,這就叫一個指針。我們可以聲明一個變量專門存儲它,這叫指針變量。
int i;
int* p = &i;
printf("%p", p);
這說的是聲明一個p,類型是int*。還可以有char*等類型。
(這個可以寫成int*p、int *p、int* p、int * p都行)
然後,我們可以解引用這個指針變量,是*符號,獲取這個指針指的內容。比如
int i = 666;
int* p = &i;
printf("p的內容:%p,這是一個內存地址,對應的這塊內存存儲的內容是%d",p, *p);
運行結果
p的內容:000000000062FE14,這是一個內存地址,對應的這塊內存存儲的內容是666
注意不要寫錯了,*p是對p解引用,&p是獲取p的內存地址!
我們就可以用這個,去讀取i的值、修改i的值。這就是指針的用處。
那麼,一個指針,實際上就是一個長度爲32位或者64位(4byte或者8byte)的地址,那麼不是隻要隨便整一個能放得下它的變量就可以存放地址了嗎?
爲什麼指針變量要有int*、char*等不同類型呢?
比如說,我們就搞一個指針類型,表示所有指針不好嗎?
實際上,int*、char*等,內容都是一樣的,都是一個地址(都是4byte或8byte)。
只是,對指針的各種操作,編譯器都需要知道這個指針指向的元素是多少字節一個元素:
在操作*p的時候,我們得知道所指向的這個元素,屬於它的內存有多大,這樣才能知道該從這個地址開始往後在多大的地方進行操作(讀取/寫入多少個字節);
指針的+1、++操作跳轉到下一個元素(比如說數組跳到下一個元素就是下一個數組項)功能,也需要知道下一個的話要往後跳多少。
所以,就有了各種int*、char*等類型,用來表示指向的是int、char,然後對應的指針做++就分別是向後4字節、向後1字節。
但是實際上它們都是一樣的,比如
int a = 666;
int *p = &a;
char *q = &a;
printf("p:%p q: %p", p, q);
可以看到p和q的內容是一樣的。
它們並不會存儲說自己是int*還是char*等。c的變量都是很單純的,內存裏只存儲值,類型是由編譯器管理的。
所以,關鍵就在於,c裏面引用一個變量,使用的是它起始位置的內存地址,但是並沒有記錄它的結束位置。這就是一切指針混亂的源頭。
這就導致需要用int*等類型作爲“標籤”,告訴編譯器如何操作,提供一點點保護,但是說到底還是由程序員自己來管理指針指向的數據有多大。包括這也導致數組的大小需要手動寫在類型裏(int(*)[長度]),導致無法用這個獲取數組大小,傳遞數組爲參數時必須還得傳遞數組大小。
實際上,在c的前身b語言中,指針甚至沒有類型,導致各種危險的野指針到處跑。
由於當時設備資源有限,再加上當時編程任務的要求更爲底層,c並沒有徹底改革指針的結構,僅僅只是加上int*、char*等“類型”,從現在的角度,有點像是發現這個問題後,一種水多加面、面多加水的和稀泥行爲,一種打補丁的無奈之舉。
在這之後的更現代的語言已經通過各種數據結構,去更好地管理內存,像是Java、Python等更是直接用對象去包裝數據,杜絕了指針的使用。
這些int*等的保護機制很脆弱,我們可以把指針強制轉換爲其它類型,然後用在別處,可能用在一些更加靈活的地方。當然,這樣很容易造成野指針等問題。
比如
char a;
int *p = (int*)&a;
當然把char*轉爲int*本質上也就只是告訴編譯器,之後是4個字節地往後跳罷了,值是不會變的。
當然,c也定義了一種非常純粹的存儲指針的類型:void*。
它沒有說明指向的變量的類型,所以它不能++,也不能解引用,需要轉換爲別的之後才能正常使用。
int i;
int * p = &i, aa = &i;
(講這些並不是說要這樣用,別用!別搞野指針!只是瞭解了這些,能更全面、更完整地理解指針)
注意
int *p, q;
這樣寫並不是聲明兩個int*,而是聲明p爲int*,q爲int.
這時候,我們就可以通過指針,讓別的函數獲得也能操作我們作用域裏的東西了
void f(int *p){ }
經典問題:swap(a,b)
int a = 5, b = 3;
如果我們需要使用一個函數來交換a、b的值,無論是什麼語言,都不會允許你這樣做:
void swap(int a, int b){ int tmp = a; a = b; b = tmp; }
原因首先是,不管是什麼語言,其實不能swap的關鍵是作用域不同,我們傳入進來的是swap的形參,交換它們也無法改變實參。
因此,理論上什麼語言都可以改成用全局變量來解決swap(a,b)的問題:
#include <stdio.h>
int x = 3, y = 5; // 要交換的內容寫在最外層,成爲全局變量
void swap() {
// 不需要參數,直接操作全局變量
int temp = x;
x = y;
y = temp;
}
int main() {
printf("交換前: x = %d, y = %d\n", x, y);
swap();
printf("交換後: x = %d, y = %d\n", x, y);
return 0;
}
等效於Python的:
def swap():
global x, y # 聲明要修改全局變量
x, y = y, x # 交換 x, y
x, y = 3, 5
swap()
print(x, y) # 輸出 5, 3
但是,這可能會導致污染全局作用域,而且swap也只能用於這兩個變量。
所以,在c中,我們一般會用指針來完成。
因爲,如果是直接傳遞一個變量,我們得到的只是它複製出來的形參,也就是隻能得到值;
但是如果我們傳遞的是它的地址,那麼就可以在後面解引用,然後就可以對它進行修改。
#include<stdio.h>
void swap(int* add_1, int* add_2){
int tmp = *add_1;
*add_1 = *add_2;
*add_2 = tmp;
}
void main(){
int a = 6, b = 32;
swap(&a, &b);
printf("a: %d, b: %d", a, b);
}
就可以用這種方式,去訪問到外面的變量。
當然,換句話說就是,可以訪問到(按照定義域)原本不該給你訪問的變量,可能導致一些錯誤。
但是,雖然指針像是一種“作弊”,指針依然是一個優秀的設計,是c的精華。因爲
在傳遞參數的時候,直接傳遞指針,而不是傳遞值,然後讓形參也保存一份值導致產生多一份的拷貝;
可以使用指針直接修改外部變量;
一些數據結構的實現,完全依賴指針完成動態分配;
由於數組退化,需要使用指針來正確操作數組。
而在現代語言中,更加
比如Python、java在傳遞參數時,對於可變對象(list、)等是直接使用引用,(不過與使用指針相比,就無法修改不可變對象的值了)
同時,有了這些語言提供的機制和高級數據結構,就不需要手動進行內存管理、手寫鏈表和管理數組了。
同時,隨着技術的發展,更規範的做法是使用返回值、全局變量等方式去管理,而不是直接修改外部的變量。現在連全局變量都不提倡使用了。
指針出現在c裏,。在現代語言已經被更安全的機制取代了。
嵌套指針
前面說了,由於c語言的設計,指針變量需要有一個類型的類型,是指向的類型*。
那麼,指向指針變量的指針,就是指向的類型**
比如
int a;
int* p = &a;
int** pp = &p;
然後我們可以發現一個有趣的現象,那麼。
而且,如果需要傳遞好幾次
當然,。並不提倡。這裏也只是做個介紹而已。
數組、指針與傳參
把一個數組作爲參數傳給一個函數,會是怎麼樣的呢?
int isPrime(int a[]);
要傳入一個數組,形參那裏是這樣寫的。
給函數傳入一個普通變量,那就是傳入它的值給形參;給函數傳入一個指針,也是給形參傳入指針這個值。
然而,傳入一個數組,傳入的並不是數組,而是數組起始位置的指針。
我們可以實驗一下
#include<stdio.h>
void main() {
int a[] = {11,22,3,4,5}; printf("a :%p\n", a); printf("&a: %p\n", &a); printf("*a: %d\n", *a); printf("*(a+1): %d\n", *(a+1)); int b = 8; printf("b %p", b); }
a :000000000062FE00 &a: 000000000062FE00 *a: 0000000000000001 b 0000000000000008
結果表明,我們很多時候可以把數組可以看作一個指針——因爲,它的確是一段連續的內存,但是在大多數表達式中,它會被隱式轉換爲指向首元素的指針,即數組退化。
比如說我們傳遞數組給函數,就是隻是傳遞了一個指向首元素的指針。
甚至我們還可以把參數直接寫成一個指針也是可以的。
int isPrime(int* a);
兩種寫法都是通用的。因爲我們使用的a[0]等數組運算符,其實就是對(退化後的)數組進行解引用,只是一種語法糖(指更簡單好用的寫法)。
比如a[0] 實際上就是*a,a[1]就是*(a+1),以此類推。
正因爲如此,還出現了一個有趣的現象
#include<stdio.h> int fx(int arr[]); void main() { int a[] = {1,2,3,4,5}; fx(a); printf("a[0]: %d", a[0]); } int fx(int arr[]){ arr[0] = 555; }
運行結果是a[0]: 555
由於arr實際上只是一個指針、arr[0]是對指針解引用的賦值,所以會導致它和前面的swap那樣,通過指針成功修改了外部的變量。
但是,也正因爲它退化成了一個指針,我們無法正常判斷它的長度了。
#include<stdio.h> int fx(int arr[]); void main(){ int a[] = {1,2,3,4,5}; printf("現在在main判斷sizeof:%d\n", sizeof(a)); fx2(a); } int fx2(int arr[]){ printf("現在在fx2內判斷sizeof:%d", sizeof(arr)); }
結果是
現在在main判斷sizeof:20 現在在fx2內判斷sizeof:8
還記得前面說的嗎,遍歷數組需要用sizeof(a)/sizeof(a[0])來判斷。而由於傳遞後的數組退化爲指針,無法進行這個操作了,導致我們也無法正常遍歷數組了。
這導致,我們必須還得把數組的長度一起傳進去
int fx(int arr[], int len){
for (int i = 0; i< len; i++){
int item = arr[i];
}
}
總而言之,數組在大多數情況下,我們寫數組名稱,實際上都會直接退化爲指向首元素的指針。這也是爲什麼有的人以爲int *就是數組。
只有兩種情況會除外,不會發生這樣的退化。
比如說對於int a[] = {1,2,3,4,5};
&a獲得到的會是指向整個數組a的指針,而不是指向a[0],類型是int(*)[5]而不是int*.
sizeof(a)能得到整個數組a的大小20,而不是一個指針的大小。
因爲是一段連續內存,數組會發生退化,可是a[0]是值(int等),指向指針的指針int*也是一個值,不會退化。這也是爲什麼我們通常用int*表示
指針返回
比如說我們想要返回一組數的最大值和最小值,返回值只能返回一個啊,那我們就可以像scanf這樣,傳入一個指針,產生的值就直接通過指針寫到對應變量裏面。
比如說,
還有一種用法是,函數的返回值只作爲狀態變量(比如0是正常,-1是異常,或者是0/1之類的),返回的數據用指針寫到外部變量裏去。而在更高級的語言裏(c++、python等),我們可以直接raise異常來解決。
字符串
像是我們之前那些雙引號括着的東西,就是字符串。它的本質是一個字符數組。不過有一個特殊的點是
char str[] = {'h', 'e', 'l', 'l', 'o', '\0'};
它末尾必須得是\0,用來標誌字符串的結束,這樣它纔是一個字符串,否則只是一個普通的字符數組。
而用雙引號寫法,它等效於這樣的形式,也就是自動在後面補一個\0。
所以sizeof(str)的需要的存儲空間不是5而是6,但是作爲一個字符串的strlen(str)是5.
由於前面說的
char str[] = "hello world"
就是聲明一個字符數組。它還沒有退化,就是一個數組
然而,如果是用指針的形式去定義,
char* str = "hello world";
那也就是說,這個僅僅只是一個指針,它是無法存儲"hello world"這個數組的。那hello world哪去了呢?
編譯器會把這個hello world在一開始的時候聲明爲一個const數組,然後再讓str去指向它的首元素。(這個是複用的,比如說如果寫char*s1、char*s2都= "hello world",那麼它們會指向同一個const數組的首元素)
兩種寫法是完全不同的!一個是數組,一個是指向一個const變量的指針。
而且,第二種這種寫法,編譯器自動生成的這個數組是const,是不能修改的!
因此,有的時候,口頭上說,或者是一些書說,char*是字符串,這是錯的。這不是字符串,只是一個指針。不要和字符串退化後形成的指針混淆。
字符串的兩個長度
由於c是需要我們自己管理內存的分配,一個字符串就擁有了兩個長度:存儲的長度和字符串長度。
char str[100] = "";
是聲明一個存儲長度爲100,但是爲空字符串的字符串,它裏面只有str[0]有一個\0,字符串長度爲0(\0不算字符串的內容)。
但是
char str[] = "";
就只會聲明一個存儲長度爲1,裏面存了一個\0,字符串長度爲0的字符串。這就沒有意義了,因爲放不下任何字符串。
之前讀取用戶輸入是用scanf,我們也可以用%s來格式化一個字符串。而且,由於傳遞字符串會退化爲一個指針,所以可以直接寫字符串,不需要寫&
scanf("%s", str);
但是用它來讀取字符串的話,和我們之前那樣,如果用戶輸入了空格,會以爲是截斷。
所以。
但是無論是用哪個都要注意,要避免溢出。比如說,我們聲明
char arr[8];
結果用戶輸入了9個字符,或者是比較多的中文那就會溢出,scanf會直接越界,寫到後面的內存去了。因此必須得保護。
比如說scanf("%7s", arr);這樣寫,指定最多讀7個字符(因爲要留一個字節給\0,後面%s會自動添加一個\0)。
不過注意,這樣的意思是從第7個後面開始截斷,如果你scanf是一次格式化兩個,那第8個字符開始就會分給第二個變量。
比起數組,字符串擁有一些特殊簡便操作
在函數里對數組參數進行遍歷,由於傳進去的數組退化爲指針,所以我們得傳入它的長度。
(那個數組寫成int arr[]或者int* arr都是一樣的)
void fx(int arr[], int len){
for (int i = 0; i < len; i++){
printf("第%d項:%d\n",i, arr[i]);
}
}
但是前面說過,字符串末尾的\0是c識別字符串用的。有了這個結束符,就能玩出很多花樣來。
(以下功能都需要#include <string.h>,都是傳入char []/char*)
strlen
比如說,我們就可以用函數求字符串長度了,傳入一個字符串(退化爲一個指針)或者傳入一個指向字符串的指針,反正都是一個指針,然後它就會從這個指針開始一路往下讀,遇到第一個\0,那就是這個字符串的結尾了,就可以停止了。
於是就有了strlen()獲取字符串長度
strcmp
strcmp是判斷兩個字符串是否相等,如果不相等,還能給出誰大誰小。
畢竟直接str1 == str2是不對的,這比較的是兩個指針,肯定是不相等的。
而strcmp是這樣用的
strcmp("abc", "abc") // 值爲0,表示相等
printf("%d",strcmp("1234", "123")); // 值爲1,表示第一個大於第二個 printf("%d",strcmp("123", "123455")); // 值爲-1,表示第一個小於第二個
strcat
傳入兩個字符串變量,把第二個的內容寫入到第一個的末尾,實現字符串的拼合。
char str[] = "123";
printf("%s", strcat(str, ",再加上456"));
123,再加上456
注意,這是直接對第一個字符串寫入,不是返回結果!
所以別這樣寫,這樣寫是去修改編譯器定義的const字符串"123",會導致出問題!
printf("%s", strcat("123", "456"));
尤其是,strcat還不檢查直接寫,也不會報錯,內存越界什麼的都是小意思。
字符串數組
字符串數組,就是裝着字符串(字符數組)的數組,也就是二維數組。
需要注意的點是
前面也說過,由於聲明二維數組是分配一段連續內存,再加上c的指針只標註起點不標註終點,所以需要知道它的每個元素有多大,而且每個元素得一樣大。比如說,
char a[][10] = { "Hello", "World" }
就會變成這樣:
或者排版爲二維,就是
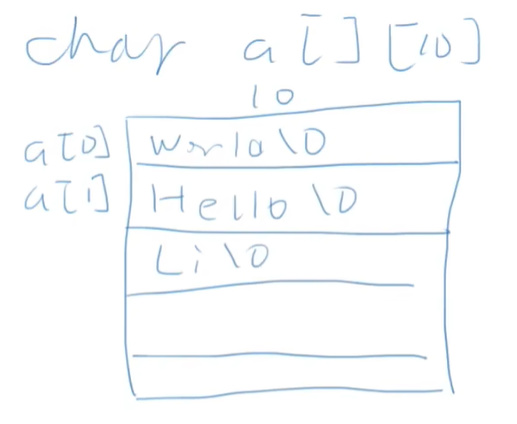
因此,我們得給每個元素分配一個大一點的,達到能夠比存的字符串要多一點。
還可以寫成這樣:
char* a[] = { "Hello", "World", "abcdefghijklmnopqrstuvwxyz" }
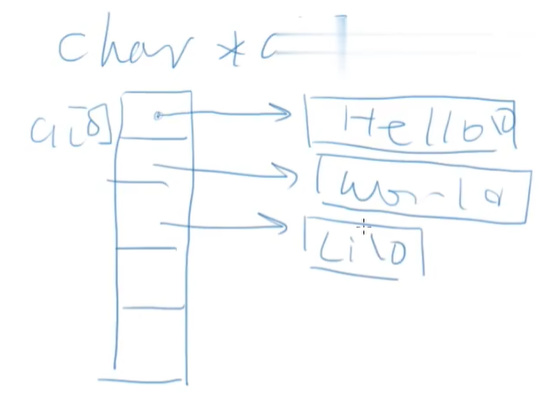
第二種這個是指針數組,它就和之前說的
char* str = "hello world";
一樣,後面的這個字符串是編譯器幫忙聲明爲常量的,然後我們就只是指向這個。
這個就是一個指針數組,每個項指向後面賦值的這個字符數組的對應的項。
這樣的好處是,不用擔心每個字符串的長度、考慮需要給每個多大。
但是缺點是,實際的字符串是編譯器幫忙聲明的const字符串,無法修改。因此兩種方法要根據情況選擇。
main的參數
main可以寫參數。會讀取到argc、argv
如何返回一個字符串?
正是由於前面說到的原因,在c中函數返回一個字符串會比較麻煩。
這與c裏表示數組的方式有關。
字符串,也就是字符數組,數組的通病,它只是指向首元素的指針,就只是一個地址。
而在返回之後,函數內的局部變量就會銷燬。
因此,如果返回的是普通的變量比如int,那返回的是值;
返回一個字符串,調用方接收到的就會是一個指向一個已銷燬變量的指針,也就是懸空指針,並不能獲得到內容。
通常,我們會用,也就是說
但是這種方法並不適用於。
得動態分配堆。
這也是爲什麼,scanf是使用指針直接傳值回去了,這種方法在缺乏各種自動化內存管理的c裏,寫起來足夠簡單
putchar、getchar、puts、gets
putchar是打印一個字符到終端。
實際上putchar(c)就相當於printf("%c", c);
只不過putchar寫法更簡單而已。
getchar是接收一個鍵盤按鍵輸入。
注意它只是讀取一個字符。
#include<stdio.h> void main() { char input; input = getchar(); putchar(input); printf("!輸出結束!"); }
4564 4!輸出結束!
所以像這樣使用循環,或者多個變量依次getchar的方式就可以獲取一個字符串。
#include<stdio.h> void main() { char input; while (1){ input = getchar(); putchar(input); printf("輸出!"); } }
不過有一個特性是,由於我們輸入東西,按下回車,終端纔會把東西給程序。所以,輸入一長串,它是每次給一個字符給程序,程序執行完,又到getchar()那裏,又接收到下一個字符
123456 1輸出!2輸出!3輸出!4輸出!5輸出!6輸出! 輸出!
所以運行結果就是這樣。最後面那個是把換行符也接收到了,然後又被putchar給打印出來,於是就換行了。
但是,這個只是玩玩罷了,真的要輸入、輸出一個字符串,要麼printf和scanf,要麼就是puts:(gets已經被廢棄,不做介紹)
puts是用來打印一個字符串並換行的。
實際上就是等價於printf("%s\n", str)
有一些課程陷入到一種鑽牛角尖的地方去,比如說講到getchar,getchar裏面有個EOF,於是就專門大篇幅講那個。但實際上正常使用EOF基本不會被觸發——畢竟普通人也不知道按ctrl+z/ctrl+d去觸發啊
就是講了很多里面很可能這輩子都用不到的設計。
在自學一門語言的時候,很容易遇到這個,比如說使用軟件
讀出類型
int a表示聲明一個整形
int * p表示p指向一個int
int arr[10]表示arr是一個長爲10的數組,裏面的10個元素都是int。
int * arr[10]表示聲明一個數組arr,裏面每個都是int*,也就是裝了10個指向int的指針。也就是說arr是指針數組。
int (*arr)[10]表示聲明一個指針arr,它指向一個數組int [10]。中間用括號括起來提高優先級,也就是先讀出它聲明的是*arr,而之所以順序是這樣是因爲c要求把[]放在末尾,所以要用括號提升優先級,並且把int [10]分別放在前後了。
附1:一些功能
隨機數與猜數遊戲
使用rand()即可產生一個隨機數。
使用方法會有些複雜:
#include <stdio.h> #include <stdlib.h> #include <time.h> int main(){ srand(time(0)); int a = rand(); }
主函數第一行這個可以不用太瞭解,或者知道它是設置一個隨機種子,輸入的是時間,來讓數隨機即可。
這樣我們就能得到一個隨機數a。
但是這樣產生的隨機數是很大的,我們可以通過取餘的方式獲取指定大小以下的隨機數,
比如
rand() % 100,即可生成100以內的隨機數。(當然,這個是[0,99],也許還得+1變成[1,100])
那麼,寫一個猜100以內的隨機數的遊戲,可能會是這樣的:
#include <stdio.h> #include <stdlib.h> #include <time.h> void main(){ int num = 0; int ans = 0; int trail_count = 0; // 生成num srand(time(0)); num = rand() % 100; printf("已生成一個0-100的隨機數。猜一猜是什麼:"); scanf("%d", &ans); while (ans!=num){ trail_count ++; printf("猜錯了!"); if (ans>num){ printf("比這要小。"); }else { printf("比這要大。"); } scanf("%d", &ans); } trail_count ++; // 猜對猜錯,都得+1 printf("猜對了!你猜了%d次來猜中。", trail_count); }
然後我們可以發現,實際上scanf讓用戶輸入猜的數,以及讓次數++這個在代碼中重複了(在循環內和循環外都有),這就是一個標誌,意味着實際上我們的代碼是沒有充分利用循環的,實際上我們可以通過改成do-while來優化
優化的方法很簡單,就是我們看到它這樣就知道是可以用do-while優化,所以就先把循環體外面改成do while,然後再順序下來走第一遍(就是不需判斷的那遍do),看看如何調整,怎麼寫行爲能夠同時滿足猜中和沒猜中都能合適。
#include <stdio.h> #include <stdlib.h> #include <time.h> void main(){ int num = 0; int ans = 0; int trail_count = 0; // 生成num srand(time(0)); num = rand() % 100; printf("已生成一個0-100的隨機數。"); do{ printf("\n猜一猜是什麼:"); scanf("%d", &ans); trail_count ++; if (ans>num){ printf("不,比這要小。"); }else if (ans<num){ printf("不,比這要大。"); } }while (ans != num); printf("猜對了!你猜了%d次來猜中。", trail_count); }
更復雜一點還有
#include<stdio.h> void main() { int num = 0; int n = 0; scanf("%d %d", &num, &n); int trail_count = 0; int is_success = 0; int input = 0; while (trail_count <= n){ scanf("%d", &input); trail_count ++; if (input == num){ is_success = 1; break; }else if (input == -1){ break; }else if (input > num){ printf("Too big"); }else if (input < num){ printf("Too small"); } } if (is_success){ if (trail_count == 1){ printf("Bingo!"); }else if (trail_count <=3){ printf("Lucky You!"); }else { printf("Good Guess!"); } }else { printf("Game Over"); } }
算平均數
算n個數的平均數。由於我們不知道它需要傳入多少個數,一種非常簡便的方法是可以讓用戶輸入一系列數,最後輸入一個結束符(比如可以規定爲-1)來表示輸入結束開始計算。
#include <stdio.h> #include <stdlib.h> #include <time.h> void main(){ int input_sum = 0; int count = 0; int input = 0; do{ scanf("%d", &input); if (input != -1){ input_sum += input; count ++; } } while (input != -1); printf("輸入的%d個數的平均數爲%d/%d=%.2f", count, input_sum , count, 1.0*input_sum / count ); }
獲取一個整數的各個位
對一個整數%10,就能獲得它的個位;
對一個整數/10(整除10),就能去掉它的個位。
兩種方法都可以,就看要提取的是哪個部分了
於是我們既可以寫出這樣的一個讓輸入的整數逆序的
#include <stdio.h> #include <stdlib.h> #include <time.h> void main(){ int num = 0; printf("輸入一個數:"); scanf("%d",&num); int count = 0; int i = 0; int reverse = 0; while (num != 0){ i = num%10; reverse = reverse * 10 + i; printf("%d, up till now:%d\n", i,reverse); num /= 10; } }
然後我們可以發現,用這種方法來獲取正序的每個位是比較困難的。可以反過來,是從左到右去讀,這就需要和它位數一樣多的10^n去取餘。
#include <stdio.h> void main(){ int num = 0; printf("輸入一個數:"); scanf("%d",&num); int num_i = num; int baser = 10; while (num_i/baser >= 10 ){ baser *= 10; } printf("%d和%d的位數一樣多。",num, baser); for (int i = baser; i>= 1 ; i/=10){ printf("%d", num_i/i); num_i = num_i % i; if (i != 1){ printf(" "); } } }
這樣就能正常運行了。不必擔心處理5000之類的後面都是0的數會失效(如果是用第一種的這種基於%的方法獲取,然後再翻轉一次順序的話,不會那麼好。
輸入一個數:500241 500241和100000的位數一樣多。5 0 0 2 4 1 --------------------------------
當然,獲取了它有多少位之後,我們也可以直接去獲取逆序,然後逐個乘以1、10、100......這樣也可以。
最大公約數
找a、b的最大公約數,通常有兩種方法:枚舉和
枚舉就很簡單了,遍歷所有小於a、b的數,記下里面所有能夠同時整除a和b的數(使用覆蓋的方式,即可找到最大的那個)。
int max_pon = 0; for (int i = 1; i<=son; i++){ if ((son % i == 0)&& (mom % i == 0)){ max_pon = i; } }
分式化簡
利用這個可以做分式化簡
#include<stdio.h>
void main() {
int son = 0, mom = 0;
scanf("%d/%d", &son, &mom);
int max_pon = 0;
for (int i = 1; i<=son; i++){
if ((son % i == 0)&& (mom % i == 0)){
max_pon = i;
}
}
son /= max_pon;
mom /= max_pon;
printf("%d/%d", son, mom);
}
打印楊輝三角
斐波那契數列
遞歸
迭代
附2:常見錯誤
未賦值
不要覺得這個很基礎,實際上很常見,就是int一個變量沒有賦值,然後導致出現問題。
避免的方法也很簡單,一定要養成聲明變量賦初始值的好習慣!
哪怕是在別的更加現代的語言,哪怕不會出現這個問題,也這樣做!
寫錯內容
比如說
int i = 6;
scanf("%d", i);
像這樣忘記寫&.
由於地址和整數的大小有時候是一樣的4 byte,再加上。結果就給傳了個6進去,那它就變成去在0x00000006(不一定是這個,前面補多少個0看是32位還是64位)的位置寫入。
操作系統會提供內存保護,不允許訪問分給其它程序的內存。所以,如果這個地方可以寫入,就會寫到錯誤的地方,但是不會報錯;
如果這個地址恰好是受保護的區域,那就會報錯Segmentation fault。
附3:考試的時候的一些概念性的東西
C語言本身不提供輸入輸出語句。printf、scanf等是由標準庫stdio.h提供的。
ASCII中,65爲A,97爲a,A往後32纔是a,也就是說Z和a之間還有幾個別的符號。
0%任何數都是0. 可以這樣想:0自己都是0了,它再怎麼樣除,能餘下來的也都只有0.
算法可以有0個或多個輸入,但是必須有1個以上輸出!
一個程序是由函數組成的。
記得,一個字符串最後會有一個"\0"!所以,字符串"a"是要2字節的空間的!
C語言中,二維數組在內存中存儲,遵循 按行主順序 放入。
對於那些c實踐題,說是對一個數進行處理,通常都是用scanf輸入進來。包括數組也是,用for來一個一個數輸入jin'lai
附4:一些易錯點
!!!注意!!!scanf輸入字符串會出現遇到空格就會截斷!別掉進坑了!
對於那些亂幾把寫的賦值寫到判斷裏的要小心。
比如說
#include<stdio.h>
#include <string.h>
void main() {
char a[80] = "AB", b[80] = "LMNP";
int i = 0;
strcat(a, b);
while (a[i++]!='\0') b[i] = a[i];
puts(b);
}
結果是LBLMNP!
不是ABLMNP
首先拼合之後a == "ABLMNP"
後面的這個循環,它是i++,所以在while判斷取的是a[i],但是在循環裏面的時候++生效了,裏面判斷的實際上是下一個了,所以裏面的複製,i是從1開始的!!!!所以L沒有被覆寫爲A !
while的執行需要注意一些
# include <stdio.h>
int main(){
int num = 0;
while (num <= 2){
num ++;
printf("%d", num);
}
}
需要注意,它不是for,這個結構是會導致num它能獲得到的值有4個!
0,1,2,3
因爲num++是在中間的,導致它讓num = 3之後,printf能獲得它,把它打印出來,然後纔是到while的頭部,判定它無法進入下一次循環!
而for,相當於是在while的末尾才進行++!
數數別數錯!
比如說,a是97,要求z的位置。
一共有26個字母,所以A、B、C.....X、Y、z一共26.[a,z]
但是我們說的+n,就是從A開始往後數n,也就應該是(a,z],比如a往後數1就是b而不是a。
所以,(a,z]的話,少了一個a,就變成25個。所以z是97+25!
這個也可以用等差數列的公式來證明,an = a1 + (n-1)d,因爲間隔是比數量少1,所以要乘的是n-1的距離d。
總而言之,z是97+25 = 122
二維數組的項數
二維數組a有m列,則在a[i][j]前面的元素有i*m+j項
比如說
1 2 3
4 5 6
7 8 9
6,是第二行第三個,a[1][2],1、2剛好就是除去自己這一行、這一列的數量。所以行數乘以一行多少格,然後加上那幾個,即可。
筆算進制轉換
無論是變大進制還是小進制都是這個方法:
比如說十進制變八進制
用 8 除 該數,並記錄餘數,直到商變 0,然後 倒序排列餘數。
求121轉八進制
121 / 8 = 15 -- 1
15 / 8 = 1 -- 7
1 / 8 = 0 -- 1
把1、7、1倒序排列,就是轉換的171.
121轉16進制:
121 / 16 = 7 --9
7/ 16 = 0 -- 7
倒序得到79
常用算法
x % n的結果是[0, n-1]的一個整數。
比如說,1234 % 100是34.
這樣就能很方便地解決相關問題,尤其是,把rand()生成的隨機數變成一個100以內的數。
一些小技巧
這些小技巧是寫代碼的時候可以節省精力、減少出錯的方法,不僅適合用於考試,也是平時寫代碼用的。
單一出口
對於很多東西,包括函數、一大坨判斷(就是一堆if-else if或者switch-case的那種),我們可以使用單一出口技巧來寫。
if (a>1){ printf("a>1"); }
這樣寫死在代碼裏面,後面要修改的時候要改好幾處;
同時,這樣的話要讀這個代碼,也得挨個情況看看都做了什麼。
int max(int a, int b){
if (a > b){
return a;
}else{
return b;
}
}
像這樣就不太好。像是這個,其實就是返回if比較處理的值,如果是想要改掉,就得把這兩處都改了。
可以改成單一出口,這樣就只有一個IO輸出的地方,這樣看的時候,就不需要看這一坨if-else if都幹了什麼,printf只有一處,就一眼就看到是怎麼運作的了。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















