來源——硬件世界
2023年發佈的Instinct MI300X,可以說是AMD最成功的AI GPU加速卡,甚至稱得上AMD歷史上最成功的產品之一,用最快的速度拿到了1億美元收入。
更重大的意義在於,它在幾乎被NVIDIA完全壟斷的高端AI芯片市場上,撕開了一道口子,爲行業提供了更多選擇。
2024年,AMD再接再厲發佈了升級版的Instinct MI325X,主要提升了HBM3E內存,核心規格沒變。

北京時間6月13日,AMD在美國聖何塞舉辦新一屆Advancing AI 2025大會。
會上,AMD正式發佈了全新一代“Instinct MI350系列”,包括MI350X、MI355X兩款型號。
無論性能還是技術特性,新卡都再次取得了長足的進步,完全可以和NVIDIA Blackwell系列掰一掰手腕。

MI350系列最核心的變化,就是升級了新一代CDNA 4架構(可能也是最後一代CDNA),同時採用了新的N3P工藝。
從大的方向上講,這一代的提升主要有四個方面,首要的自然是更好的AI能力,針對生成式AI和LLM大語言模型增強了數學矩陣模型。
另外,支持新的混合精度數據格式、增強Infinity Fabric互連總線和高級封裝互連、改進能效,也都是重中之重。

MI350系列繼續採用延續多代的chiplets芯粒設計,仍然分爲頂層的XCD(加速器計算模塊)、底部的IOD(輸入輸出模塊)和周圍的HBM3E內存模塊。
其中,XCD工藝從5nm升級爲N3P 3nm級工藝高性能版本,IOD則維持在6nm工藝。
它採用了非常複雜的多重先進封裝技術,不同模塊之間使用了2.5D、3D混合鍵合,整體則用了臺積電的CoWoS-S晶圓級封裝,使用硅中介層作爲主要的連接媒介——NVIDIA也在大面積使用它,不過已經開始向更高級的CoWoS-L過渡。
上代MI300X就使用了1530億個晶體管,創下新高,MI350系列進一步增加到1850億個晶體管。

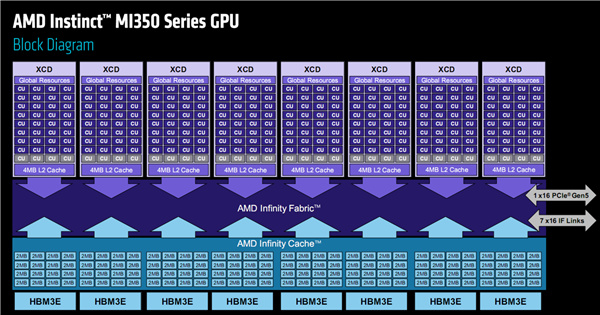
這是MI350系列的內部架構和佈局圖。
XCD模塊一共有8個,每個內部分爲4組着色器引擎,下轄36組CU計算單元,還有4MB二級緩存,配有一個全局資源調度分配單元。
整體合計288個CU單元、32MB二級緩存,但是MI350系列每個XCD中屏蔽了4組CU單元,實際開啓了256組(1024個矩陣核心),反而少於MI300X/MI325X 304組(另屏蔽16組),而每個單元的二級緩存容量沒變。
IOD模塊一共2個,集成128個通道HBM3E內存控制器、256MB Infinity Cache無限緩存,容量和上代相同,還支持第四代Infinity Fabric互連總線,雙向帶寬提升至1075GB/s。
HBM3E內存仍然是8顆,每一顆都是12Hi堆疊,和MI325X相同而高於MI300X 8Hi,只是這次開放了全部容量,單顆是完整的36GB而非32GB,因此總計多達288GB。
內存傳輸率8Gbps,總帶寬高達8TB/s,顯著高於MI300X 5.3TB/s、MI325X 6TB/s,尤其是平均到每個CU單元的內存帶寬提升了多達50%。
每一個IOD上堆疊四個XCD、四顆HBM3E,而兩個IOD之間使用5.5TB/s高帶寬的Infinity Fabric AP進行互連整合封裝。
整個MI350系列芯片與AMD EPYC處理器之間的通道,走的是完整的PCIe 5.0 x16,帶寬128GB/s。
功耗方面,風冷模組最高1000W,水冷模組則可以做到1400W。

在裸金屬、SR-IOV虛擬化應用中,爲了實現最大化利用,MI350系列支持對計算資源進行空域分區,最多可以分成8個。
不同分區可以支持多種使用模式,但不同於前代的NSP1、NSP4,這次改爲NSP1(單個分區)、NSP2(雙/四/八個分區),看似降級了,AMD解釋說NSP4模式的性能提升其實比較有限。
MI350系列在單分區+NSP1模式下,最高可以支持5200億參數的AI模型,而在八分區+NSP2模式下,可以支持最多8個700億參數Llama 3.1模型的併發。

MI350系列針對生成式AI、LLM的具體改進,包括矩陣核心的提升和更靈活的量化機制,過於專業就不一一解釋了。
注意這次支持行業標準的PF6、FP4格式,支持從FP16/BF16到FP32的基於硬件的Stochastic Rounding量化。
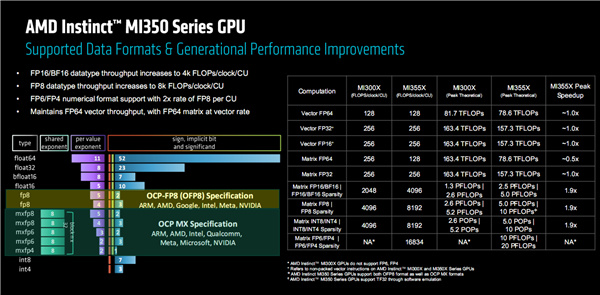
MI350系列支持豐富的數據格式,包括FP64、FP32、FP16、BF16、FP8、MXFP8、MXFP6、MXFP4、INT8、INT4。
通過提升每個CU單元每時鐘週期的性能,FP16、BF16、FP8、FP6、FP4的單位性能都得到了顯著提升。
正因此如,MI355X在覈心數更少的情況下,性能基本追上甚至超過了MI300X,其中矢量FP64、FP32、FP16和矩陣FP32下都基本一致,矩陣FP64下約爲一半(單位性能也是一半),矩陣FP16/BF16、FP8、INT8/INT4下的稀疏性性能則幾乎翻了一倍,還新增支持了矩陣FP6/FP4稀疏性。
可以看到,MIX350系列的性能並非全方位飛躍,有些數據格式下甚至更弱了,因爲這代更注重支持更多更靈活的數據格式、單位性能的提升(類似提升IPC),以及對於AI訓推更關鍵的矩陣稀疏性能。

Instinct MI350系列有兩款型號MI350X、MI355X,都配備完整的288GB HBM3E內存,帶寬均爲8TB/s。
區別在於,MI355X是滿血性能,峯值可達FP64 79TFlops(79萬億次每秒)、FP16 5PFlops(5千萬億次每秒)、FP8 10PFlops(1億億次每秒)、FP6/FP4 20PFlops(2億億次每秒),整卡功耗最高達1400W。
MI350X的性能削減了8%,FP4峯值可達18.4PFlops,整卡功耗最高1000W,和MI325X持平。

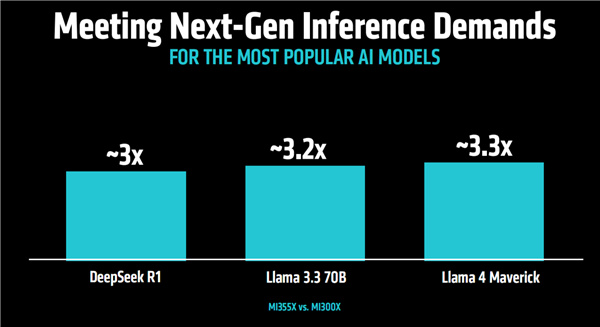
當然更關鍵的是實際性能,官方宣稱MI355X對比MI300X在不同AI大模型中的推理性能普遍提升了3倍甚至更多。
在AI助手/對話、內容創作、內容摘要、對話式AI等應用中,性能同樣全面提升,最高幅度甚至超過4倍。
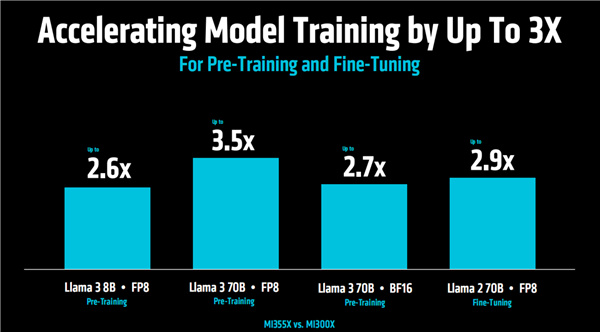
大模型預訓練與微調中,提升幅度也不容小覷,最高達3.5倍。

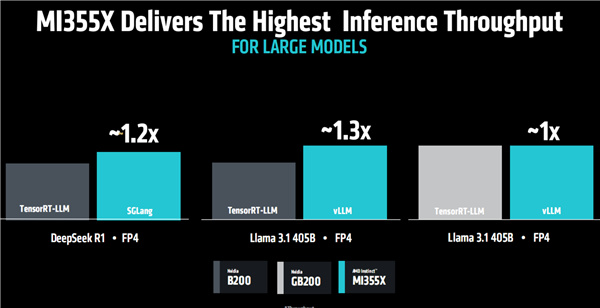

MI350X對比NVIDIA B200/GB200,內存容量多出60%(後者192GB),內存帶寬持平。
FP64/FP32性能領先約1倍,FP6性能領先最多約1.2倍,FP16、FP8、FP4領先最多約10%。
除了理論性能,大模型推理性能也處在同一水平,或者領先最多約30%,訓練性能BF16/FP8預訓練基本同一檔次,FP8微調則有10%以上的領先。
更關鍵的是高性價比,單位價格可以多生成最多40%的Tokens。



MI350系列依然支持多GPU平臺化部署,單個節點還是最多八卡,總計就有2304GB HBM3E內存,FP16/BF16性能最高40.2PFlops(4.02億億次每秒),FP8性能最高80.5PFlops(8.05億億次每秒)、FP6/FP4 161PFlops(16.1億億次每秒)。
八卡並行時,每兩者之間都是153.6GB/s雙向帶寬的Infinity Fabric通道互連,而每塊卡和CPU之間都是128GB/s雙向帶寬的PCIe 5.0通道連接。
MI350系列支持風冷、機架部署,其中風冷下最多64塊並行,液冷時支持2U到5U,最多128塊並行,也可以96塊。
128卡就能帶來36TB HBM3E內存,性能更是達到恐怖的FP16/BF16 644PFlops(64.4億億次每秒)、FP8 1.28EFlops(128億億次每秒)、FP6/FP4 2.57EFlops(257億億次每秒)。
AMD聲稱,AMD致力於在5年內將AI計算平臺的能效提升30倍,MI350系列最終做到了38倍!
下一步,從2024年到2030年,AMD將再次把AI系統的能效提升20倍,屆時只需一臺機架即可完成如今275臺的工作,節省多達95%的能源。


特別值得一提的是,作爲AI加速系統平臺的一部分,AMD此前還發布了一款超高性能網卡Pensando 400 AI(代號“Pollara”),首次與EPYC CPU、Instinct GPU一起組成完整的平臺方案。
這是業界第一個符合超剛剛發佈的以太網聯盟(Ultra Ethernet)規範的網卡,支持PCIe 5.0,帶寬達400G(40萬兆),完全可編程可定製,可卸載和加速AI處理。

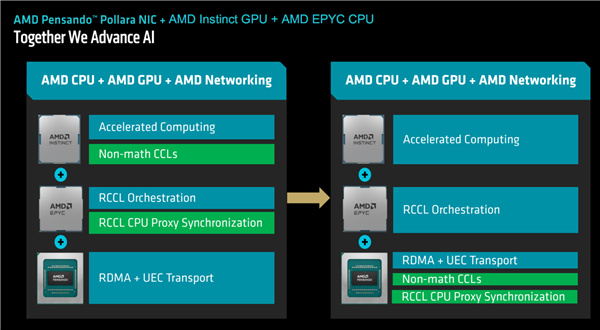
現在,AMD有了新一代全部基於自家技術和產品的AI加速系統平臺級解決方案。
EPYC CPU處理器、Instinct GPU加速卡、Pensando網卡無縫配合,尤其是網卡可以卸載接手並高效處理CPU、GPU的部分工作,釋放平臺的最大性能潛力。

M350系列方案將從第三季度開始供應客戶,可以看到各大OEM、ODM廠商基本都在名單之中了。

生態與應用合作伙伴方面,AMD Instinct的朋友圈正在快速擴大,全球十大AI企業中已經有七家用上了Instinct,包括微軟、Meta、OpenAI、特斯拉、xAI、甲骨文等。
Meta Llama 3/4模型推理廣泛部署了MI300X,還在與AMD共同研發下一代MI450。
甲骨文率先引入MI355X,新一代AI集羣正在部署多達131072塊。
微軟Azure私有和開源模型都用上了MI300X。
還有紅帽、Mavell、Cohere、Astera Labs等等,甚至提到了華爲,其正在與AMD探討共同利用AMD平臺打造開放的、可擴展的、高性價比的AI基礎設施。

最後順帶一提,最新發布的TOP500超級計算機排行榜上,AMD EPYC+Instinct平臺支撐了全球最快的兩臺超算,還在各個國家的不同項目中得到了廣泛的部署。
位居榜首的是位於加州勞倫斯利弗莫爾國家實驗室的El Capitan,採用第四代EPYC處理器、MI300A加速器的組合,擁有超過1100萬個核心,最大性能達到1.742 EFlops(147.2億億次每秒)。
緊隨其後的是田納西州橡樹嶺國家實驗室的Frontier,第三代EPYC、MI250X的組合,最大性能1.353EFlops(135.3億億次每秒)。
這兩臺超級計算機均由美國能源部實驗室運營,均屬於百億億次級的超算系統。


Instinct MI350系列硬件能力再次取得飛躍,進一步強化了面對NVIDIA的競爭力。
但是我們知道,硬件性能和技術要想完全釋放潛力,尤其是在AI加速系統中,強大的軟件開發平臺是必不可少的。NVIDIA能在AI行業有如今的地位,最大的功臣和護城河就是CUDA。

AMD也有自己的一套ROCm開發平臺,一直和NVIDIA CUDA都存在一定的差距,好在最近的進步幅度也是非常喜人的,包括對衆多AI大模型、框架的即時支持,全方位的開源。
現在,我們又迎來了全新的ROCm 7版本,在最新模型與算法支持、高級AI特性、新硬件支持、集羣管理、企業級特性等各方面,都再次有了長足的進步。

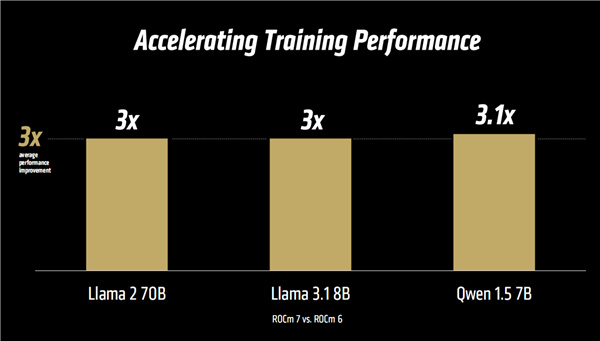
訓練方面,ROCm 7支持一系列新特性,包括多個AMD開源模型、增強的AI框架、增強的內核與算法、新的數據類型(BF16/FP8)等等。
官方聲稱對比ROCm 6,實測在Llama 2/3.1、千問1.5等多個模型中,性能提升普遍達到了3倍乃至更高。

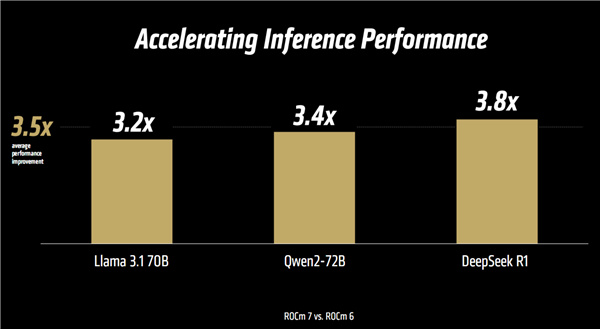
推理方面,新的變化同樣不少,包括增強框架、Serving優化、內核與算法改進、高級數據類型(FP8/FP6/FP4/混合)等。
性能提升同樣喜人,Llama 3.1、千問2、DeepSeek R1等模型實測平均達3.5倍,最高更是可達3.8倍。
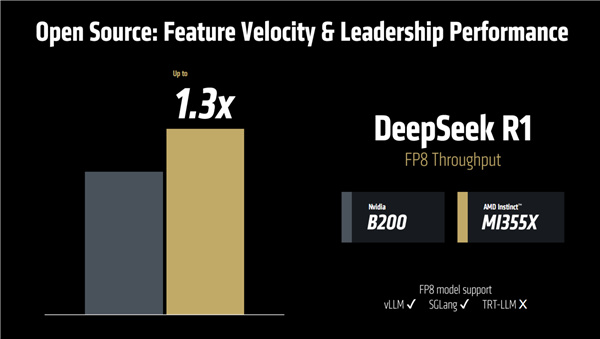
有了ROCm 7的加持,MI355X面對NVIDIA B200也是絲毫不弱,比如DeepSeek R1 FP8吞吐量可以領先達30%。
當然這只是一個例子,AMD並未更多地對比自家新品和友商競品。

除了數據中心、企業端,ROCm 7在消費端也有全面改進,新增原生支持Red Hat EPEL、Ubuntu、OpenSUSE等更多的Linux系統發行版,其中前兩者下半年實現。
Windows平臺上,也新增支持PyTorch、ONNX-EP兩大框架,分別在三季度和7月份開放預覽。

AMD還順帶介紹了下全線的消費級AI解決方案,比如移動端的銳龍AI 300系列最高可以本地端側運行240億參數大模型,銳龍AI Max 300系列更是能跑到700億參數,而新一代線程撕裂者處理器、Radeon AI顯卡組合最高可以搞定1280億參數。
同時,AMD還預告了下一代Instinct MI400系列,包括初步規格、性能、平臺等。
AMD首先公佈了一份穩健的路線圖,強調Instinct系列產品線將繼續堅持每年升級一次。
2023年的MI300X/300A,2024年的MI325X,2025年的MI350X/MI355X,2026年就是MI400系列。
不過注意,MI300A將成爲至少近期唯一的CPU+GPU融合設計產品,未來暫時不會有這種產品了,儘管最新公佈的全球第一超算用的就是它。
官方沒有明確解釋爲什麼,猜測是部署和開發適配的難度、成本更高,性能也可能不如傳統的獨立CPU+GPU。
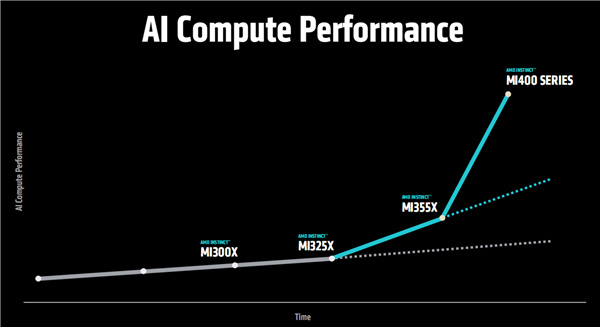

AMD聲稱,MI400系列將實現更大幅度的配置提升、性能跨越。
內存將升級爲下一代HBM4,單卡容量高達恐怖的432GB,帶寬19.6TB/s,對比MI350系列的288GB HEM3E、8TB/s分別增加50%、145%,平均每個CU單元的內存帶寬也提升到300GB/s。
FP8/FP6、FP4性能分別達到20PFlops(2億億次每秒)、40PFlops(4億億次每秒),直接翻番,事實上在某些應用中的極限性能提升幅度可達難以想象的10倍!
工藝和架構沒說,不知道繼續3nm還是升級到2nm,不知道叫CDNA 5還是首次改爲UDNA。

明年,AMD還將推出代號Vulcano(火山)的下一代Pensando網卡,依然符合UltraEthernet標準。
新網卡將升級3nm製造工藝,支持PCIe 6.0,帶寬翻番至800G(80萬兆)!
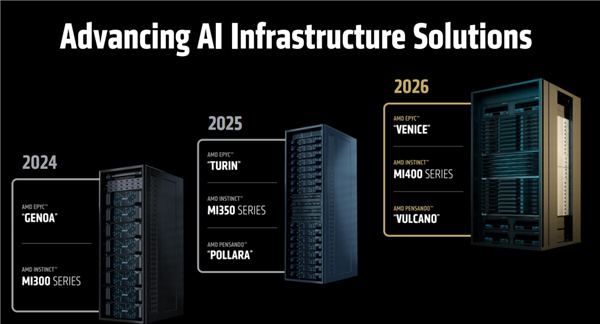
除了Instinct MI400系列加速器、Pensando Vulcano網卡,AMD明年還會推出代號“Venice”的下代EPYC處理器,升級Zen6架構。
三者共同組成新的AI加速系統平臺,AMD也會推出參考設計的AI機架方案,代號“Helios”。
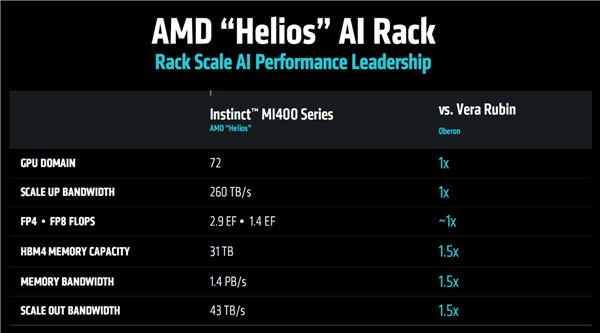
Helios AI機架可容納最多72塊MI400系列GPU,對標NVIDIA NL72,總帶寬260TB/s,HBM4內存總容量31TB、總帶寬1.4PB/s,超過競品足足一半。
整機性能,可高達FP8 1.4EFlops(140億億次每秒)、FP4 2.9EFlops(290億億次每秒),和競品基本在同一水平上。
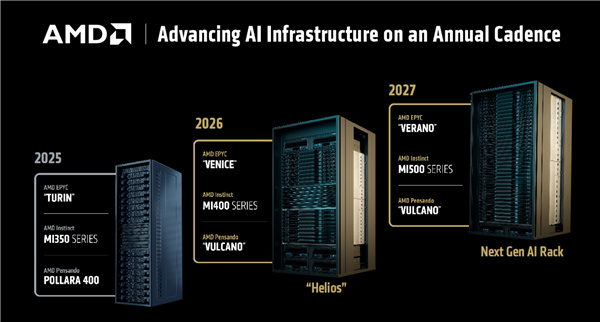
繼續向前,2027年,AMD還將推出再下一代的MI500系列,搭配代號Verano的再下一代EPYC處理器,應該會升級到Zen7架構了!
在發佈會現場,AMD與合作伙伴也展示了大量的AI服務器方案,有的已經升級到最新款MI350X、MI355X,有的雖然用的還是老一代MI300X、MI325X,但升級也很輕鬆,只是時間問題。
蘇媽現場圖與官方渲染圖——
MI350系列芯片、加速卡和平臺——
MI350系列芯片本體,MI350X、MI355X是一顆芯片的不同版本。
中間兩個最大的,就是兩顆XCD計算模塊,通過Infinity Fabric高速總線緊密結合在一起,周邊排布着八顆HBM3E內存,單顆36GB,總計288GB。
四角有四顆非常小的芯片,具體不詳。
IOD輸入輸出模塊位於下方,無法直接看到。
OAM形態的加速卡,非常緊湊,PCB是真的厚啊。
中間是安裝了大型風冷散熱器的加速卡。
八路並行平臺,裸板和安裝散熱器之後,共計2304GB HBM3E內存,FP6/FP4算力高達161.1 PFlops,也就是每秒超過16億億次。
合作伙伴服務器、機櫃——
SuperMicro超微的2U水冷服務器,最多八卡。
思科,8U,雙路四五代EPYC(組多64核心),12條PCIe 5.0,已適配MI350系列,24條DDR5。
廣達,7U,雙路四五代EPYC(最高500W),目前安裝的是MI300X、MI325X,也支持MI350系列。
Aivres,10U,雙路五代EPYC,八路Instinct OAM。
仁寶,7U,最多八路MI325X或MI355X。
緯創,8U,五代EPYC,八路MI350X。
英業達,全面支持MI300X、MI325X、MI355X。
戴爾,10RU,雙路五代EPYC,八塊MI350系列。
思科,雙路五代EPYC配古老的八塊MI210,很少見的組合。
超微,4U,雙路四五代EPYC,八塊MI355X,液冷。
超微,8U,雙路四五代EPYC,八塊MI350X。
神達,8U,雙路四五代EPYC,八塊MI325X。
華碩,7U,雙路五代EPYC,八塊MI325X、MI350系列。
華擎,8U,八塊MI355X。
華擎,4U,八塊MI355X。
技嘉,4U,支持MI325X、MI355X。
慧與/Cray打造的世界最強超算EI Capitan的一個計算節點,兩個四插槽MI300A APU,爲數不多的案例。
神達、和碩更是拜訪了兩臺完整的機櫃,當然不是真正的產品,只是演示之用,內部安裝了多款不同型號、配置的機架服務器,神達的還可以整體液冷散熱。
網卡——
最後是AMD做的全球首個400G超以太網卡,AI加速系統的重要組成部分,挺迷你的,而明年的下一代可以做到800G也就是80萬兆!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com






![任天堂前銷售負責人預判:Switch 2 硬件漲價已成定局[cube_摘墨鏡][cube_摘墨鏡]](https://imgheybox1.max-c.com/bbs/2026/04/05/3b368916849076608f90f840878267fb.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)







