一、爲什麼選擇DeepSeek本地部署?
在AI技術爆發的今天,大語言模型不再是雲端專屬!本地部署模型既能保護隱私,又能隨時調用。但許多人對本地化存在誤解:
❌ 需要頂級顯卡?
❌ 動輒百億參數才能用?
❌ 部署複雜如天書?
實測告訴你:一臺RTX 3060筆記本(顯存6GB)+ 7B小模型,即可實現流暢對話、角色扮演甚至代碼輔助!
別擔心自己是小白,這篇文章手把手帶你完成 DeepSeek-R1 蒸餾模型的本地部署!從最基礎的軟件下載,到如何挑選合適的模型,每一步都給你安排得明明白白。
二、部署準備
軟件安裝:
在瀏覽器搜索 “https://lmstudio.ai/”(百度可能搜不到,國內可訪問此域名),選擇 Windows 版本下載安裝包,下載完成後雙擊安裝,安裝後會在桌面創建快捷方式,打開即可。
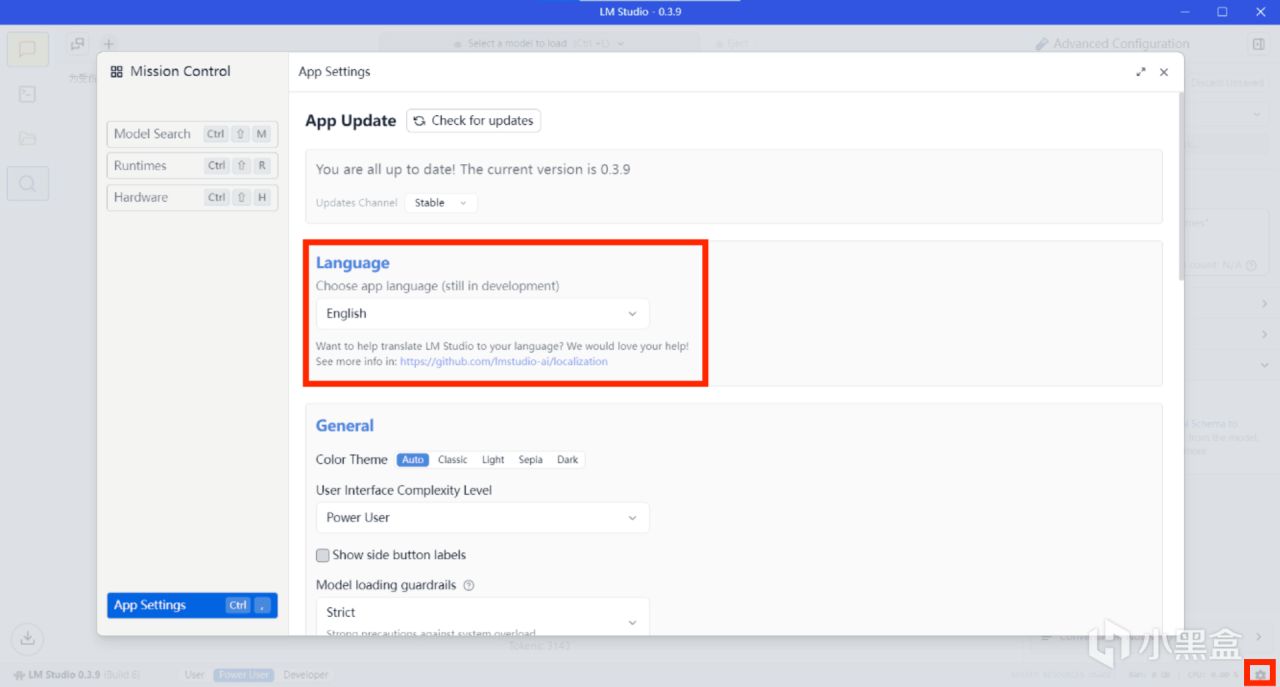
中文語言設置(看個人需求):
右下角小齒輪→Language→簡體中文
模型選擇與配置
模型下載:
科學上網方法:
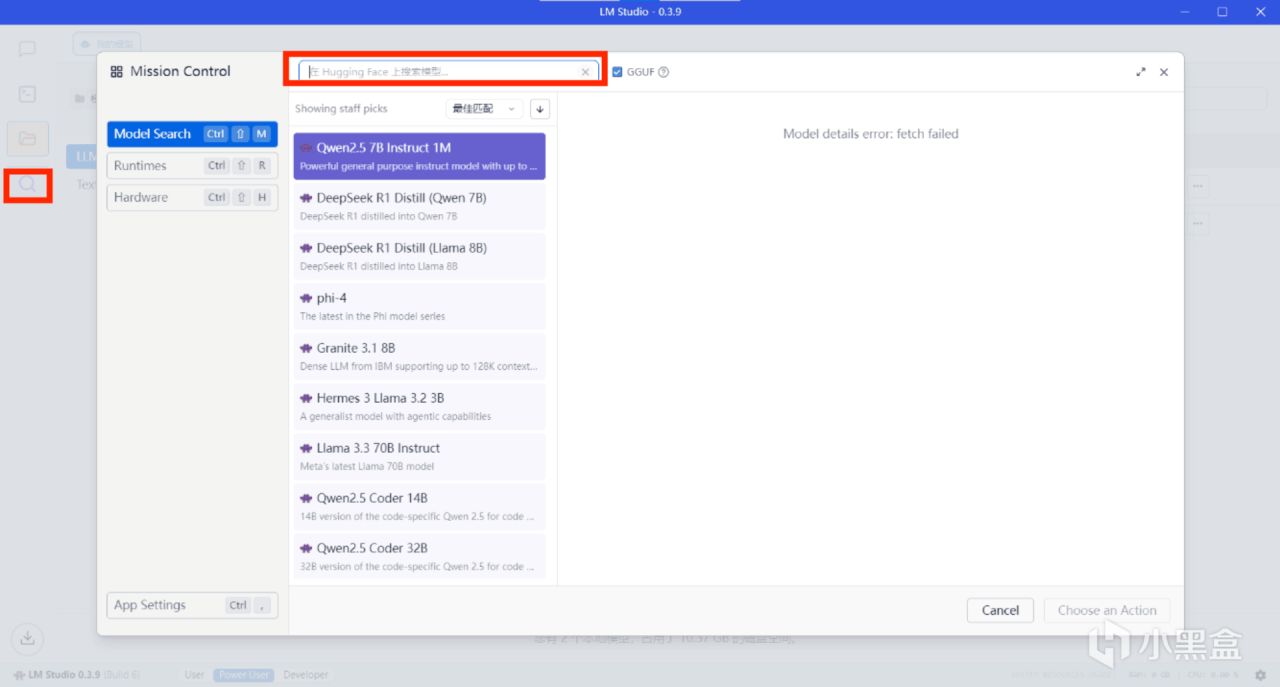
1、側邊欄→發現→Model Search。
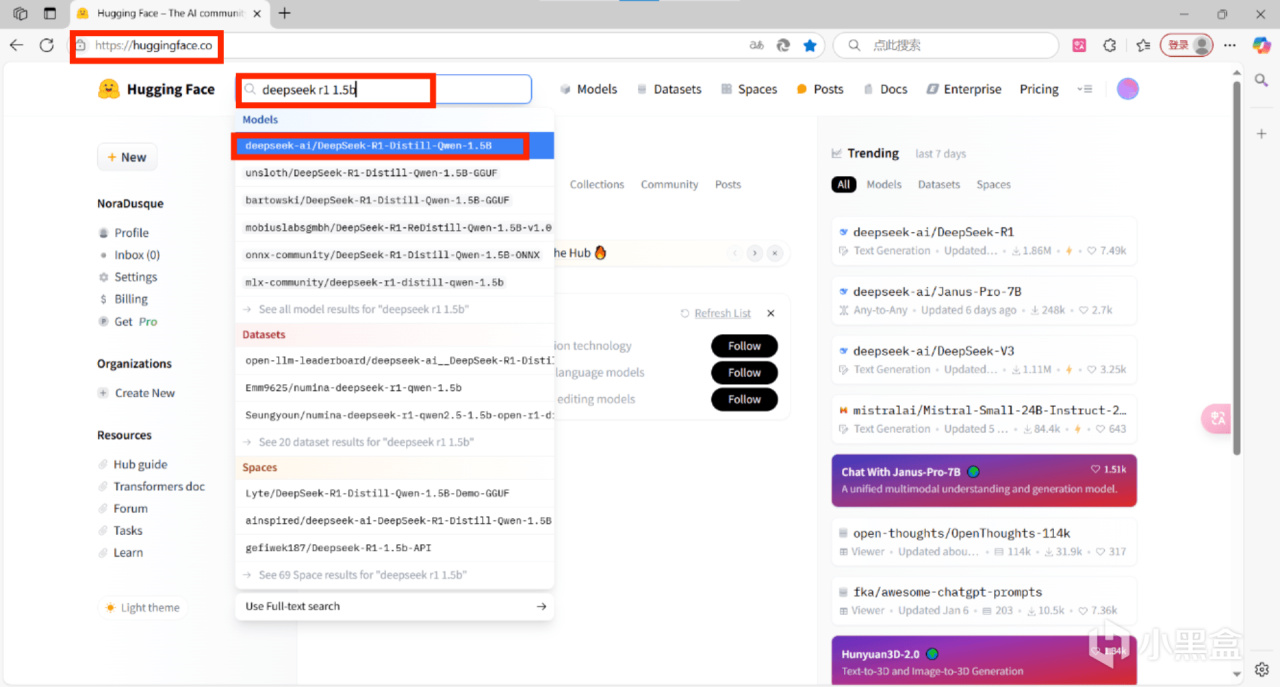
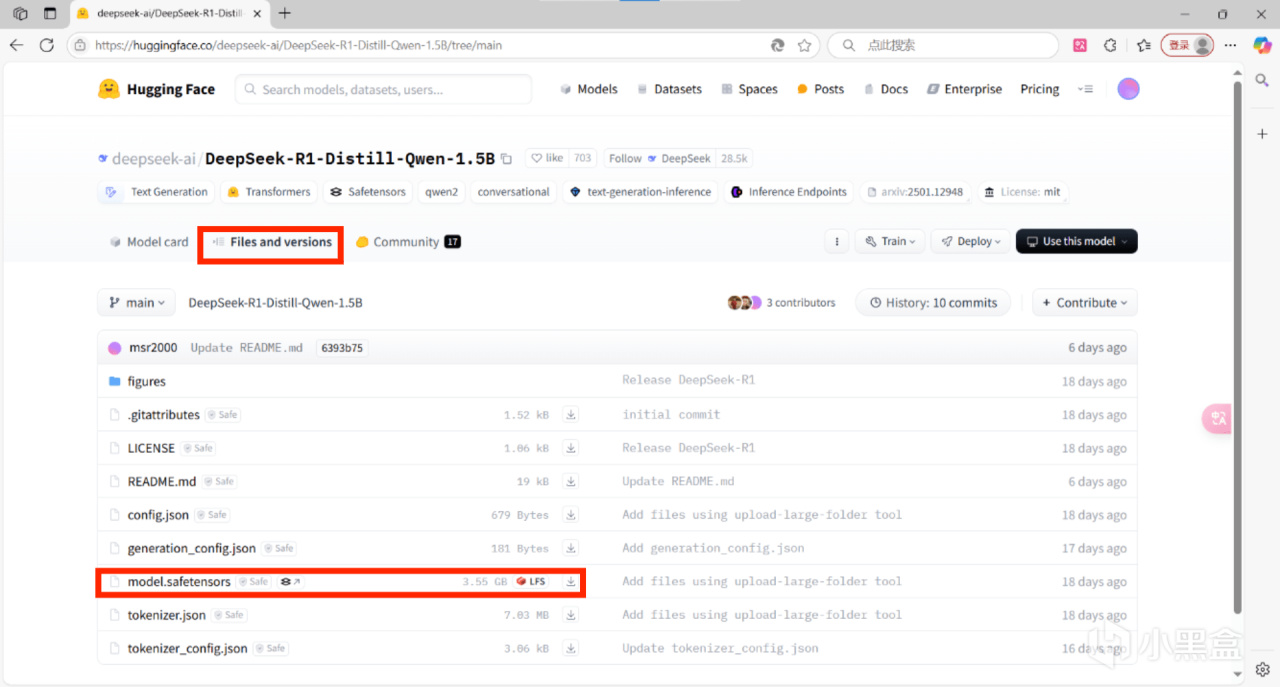
2、瀏覽器打開https://huggingface.co/搜索模型→files→下載模型
無需科學上網方法:
瀏覽器打開https://hf-mirror.com/搜索下載模型
模型選擇:
初次部署建議使用deepseek 1.5b模型,
例如:https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B;
或者自行根據顯存選擇模型
參數越大越好,但要注意顯存佔用
模型的顯存佔用與非常多的因素有關,它主要受參數的數量影響,但還有量化的方式,精度差異等等。由於語言模型的文件通常很大,所以在下載之前,一定要確保你的顯存足夠使用它。 (如何查看顯存:打開任務管理器→性能→GPU→專用GPU內存)
2、選擇合適的量化型號:Q5_K_M至Q8_0
GGUF 模型文件通常會有不同的量化型號,例如Q5_0,Q5_K_S,Q5_K_M,Q6_0,Q8_0
等等。
對於這些型號,基本可以理解爲數字越大則模型越接近原始模型,但佔用空間更大,計
算速度也更慢。所以Q5_0,Q5_K_S,Q5_K_M,Q6_0,Q8_0的的質量和文件大小是逐漸增加的,而計算速度是逐漸降低的。
通常來說,如果顯存足夠,最大的Q8_0是首選;但如果顯存有限,那麼就性價比而言,
Q5_K_M 是最好的選擇,它佔用的顯存更小,而且不會損失太多精度。如果低於 Q5_K_M,
則輸出的質量會開始下降,而且越來越明顯。
推薦選擇參數
顯存大小 4GB 6GB 8GB 12GB+
推薦參數 7B 8B 14B 32B
推薦量化 Q3_K_M Q4_K_M
理論顯存佔用 3.2GB 4.5GB 6.8GB 10GB+
Qwen與Llama區別
模型名稱 Qwen 系 Llama 系
基座架構 通義千問架構 LLaMA 架構
理論上的特點 中文理解強 英語能力優
支持長文本 插件成熟
3、選擇合適模型下載:
舉例:確認參數爲8b和量化版本爲Q4後,在hf搜索deepseek r1 8b Q4,建議將排序更換爲“Most download“,點擊第一個,點擊files,下滑找到模型文件,單擊下載
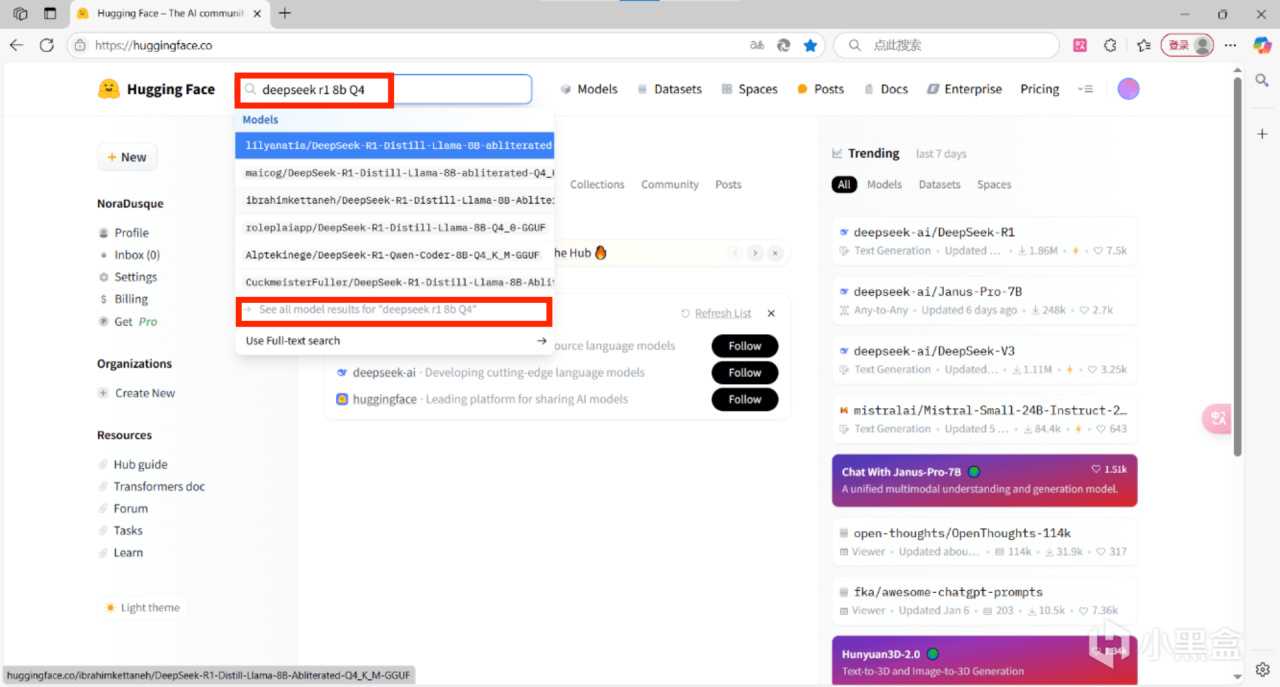
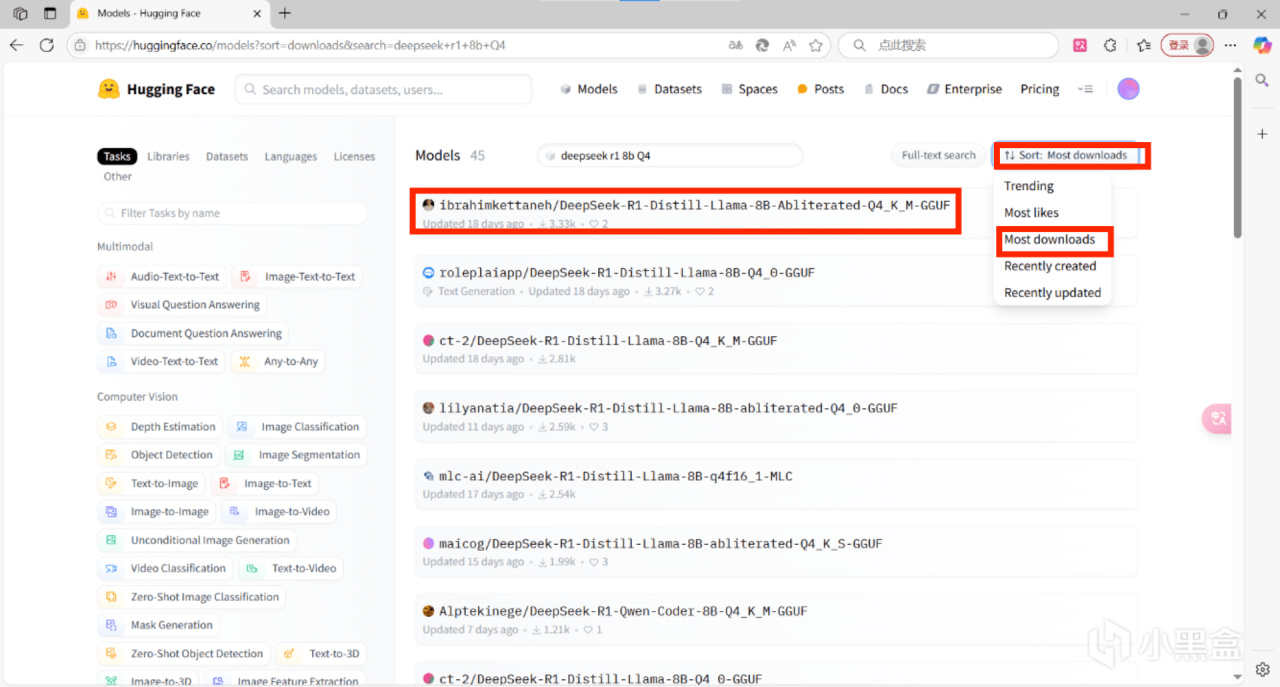
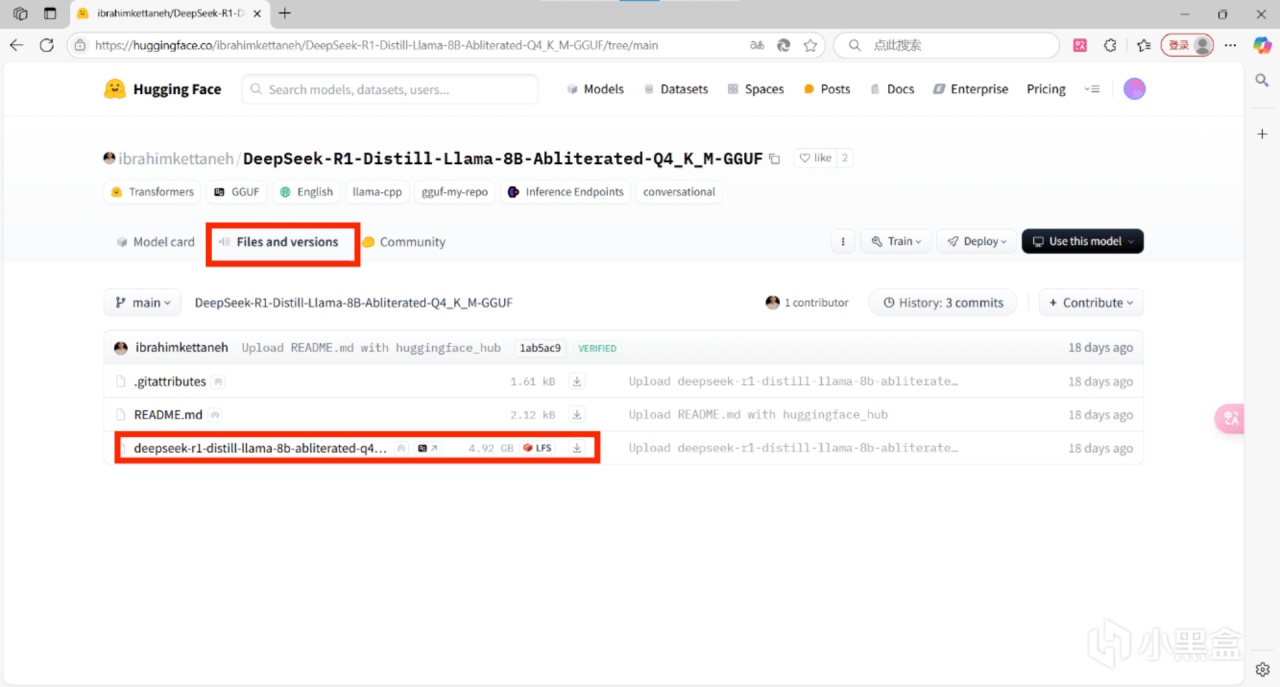
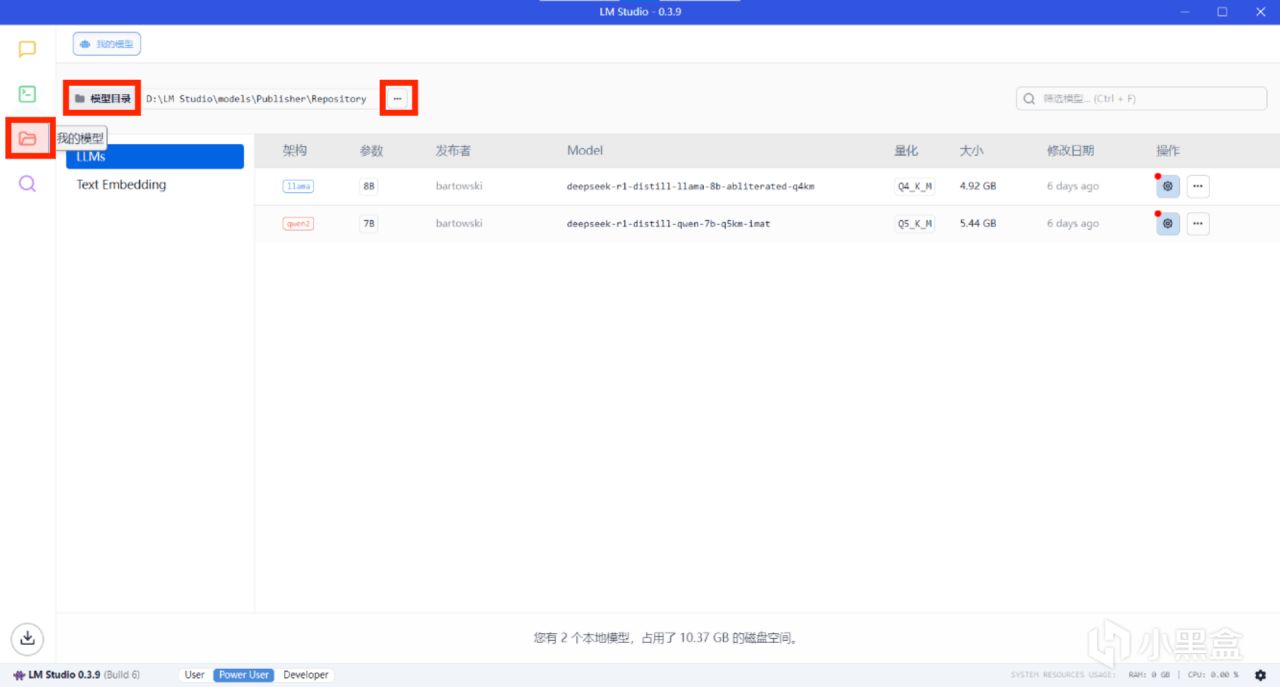
注意:若在瀏覽器下載模型,需手動將模型放入lmstudio的模型目錄,模型目錄可在“我的模型”界面查看和更改
防火牆設置(根據個人需求選擇是否操作,此步驟的作用是讓軟件離線運行):
打開”高級安全 Windows Defender 防火牆”,依次設置出站規則和入站規則。
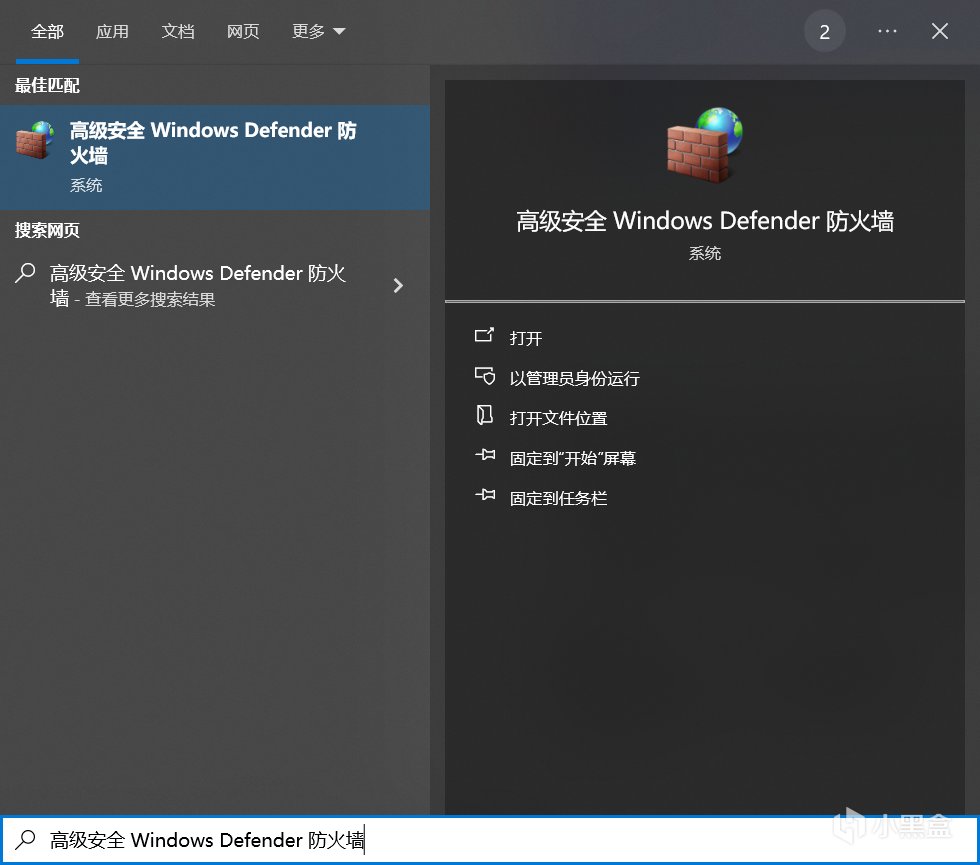
新建入站規則,選擇程序,瀏覽安裝路徑,選擇LM Studio.exe,選擇阻止鏈接,可自行添加描述。
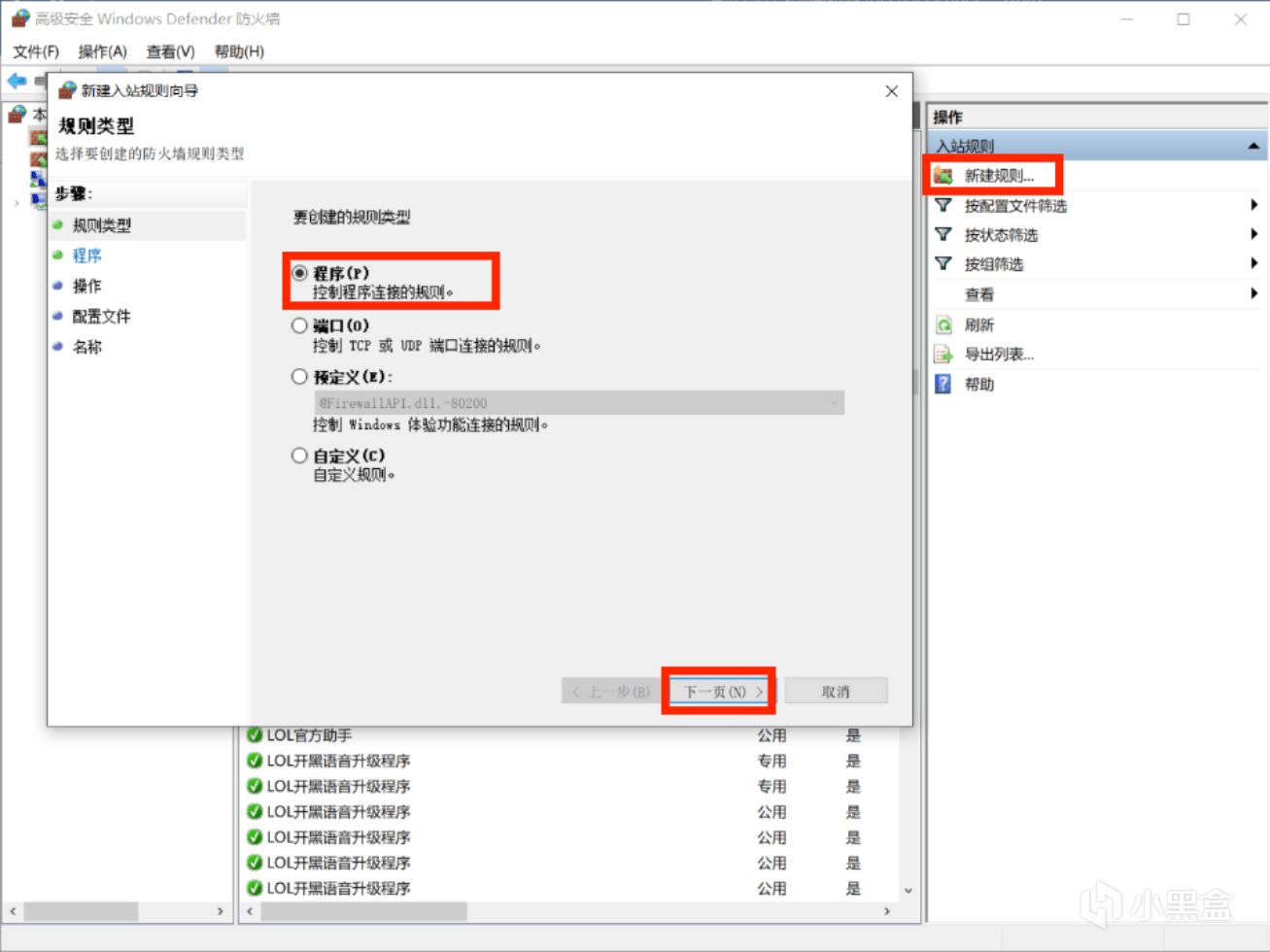
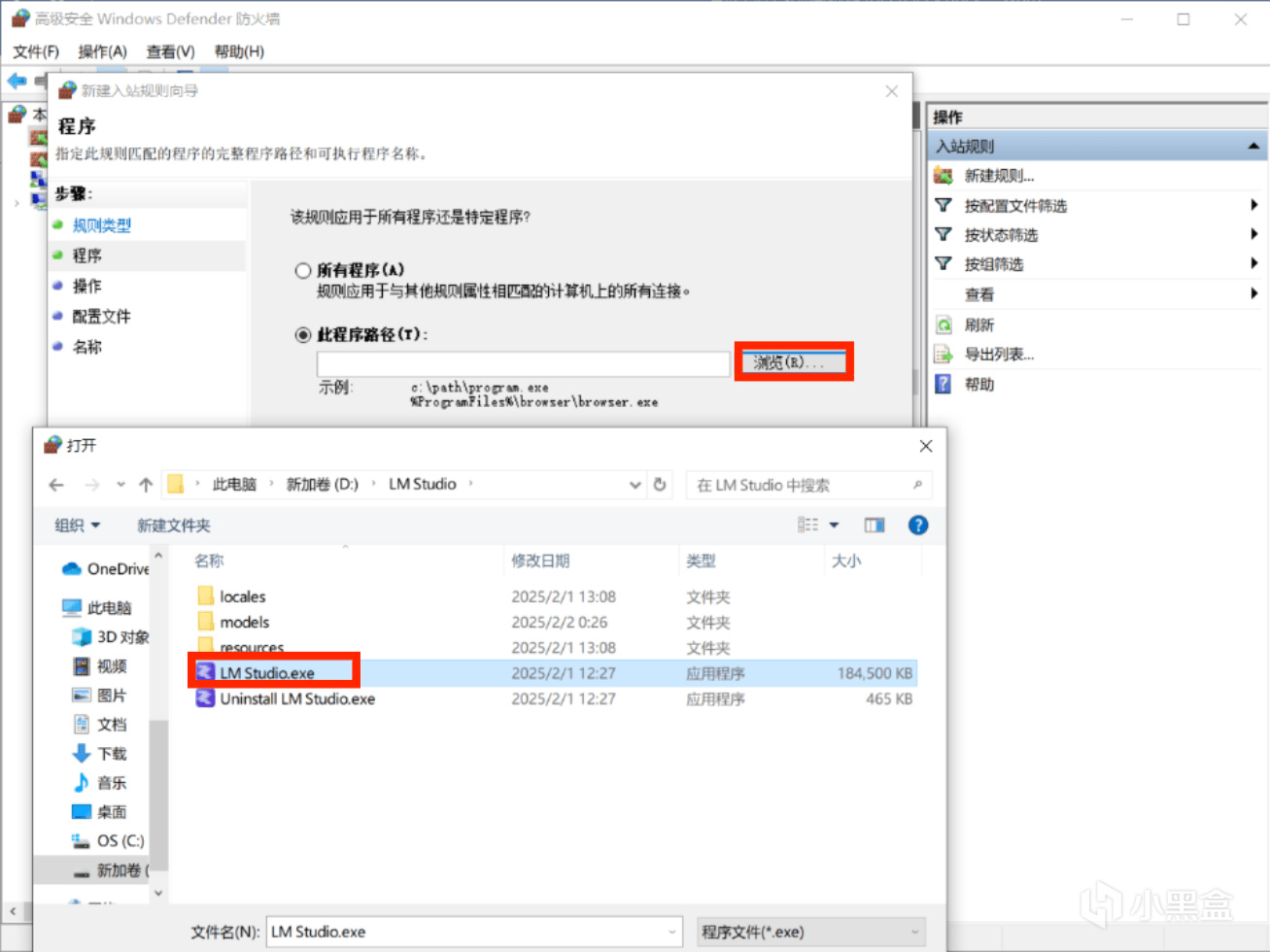
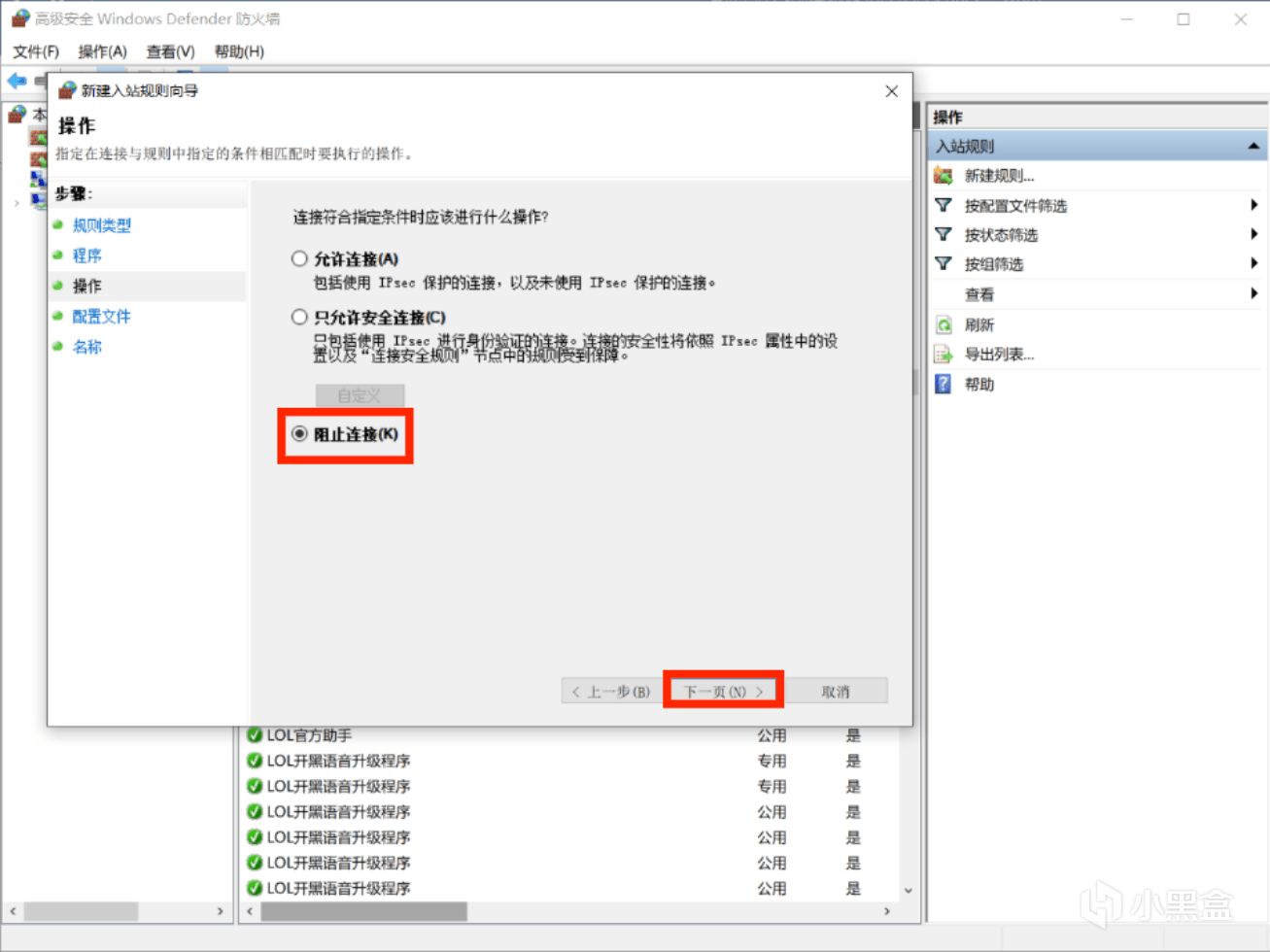
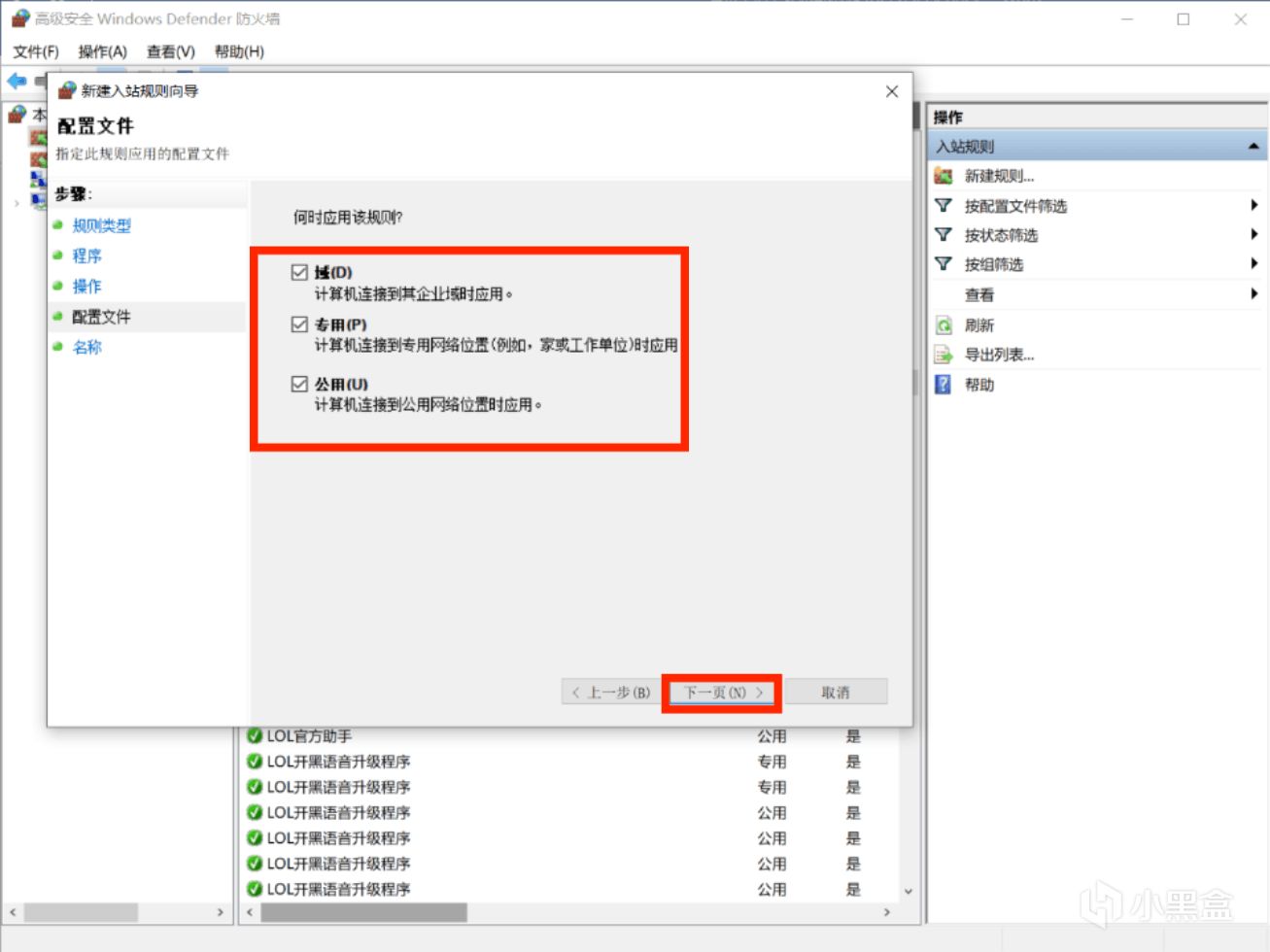
出站規則同理;
2、對安裝路徑下resources文件夾裏面的 elevate.exe同樣設置出入站規則阻止鏈接。
3、找到 C 盤-用戶-用戶名下的 .lmstudio文件夾(需打開“查看隱藏的項目”) 中的 bin文件夾下的 lms.exe 程序,設置出入站規則爲阻止鏈接。
模型配置
點擊側邊欄“聊天”→點擊上方“選擇要加載的模型”
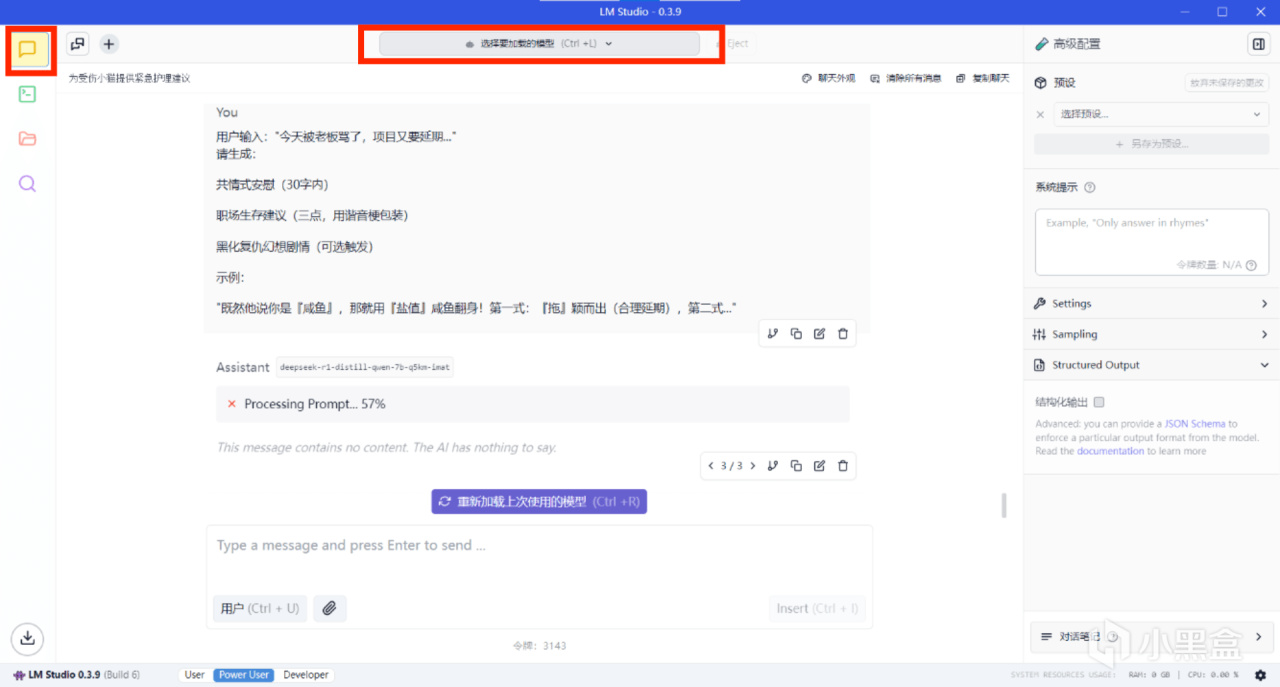
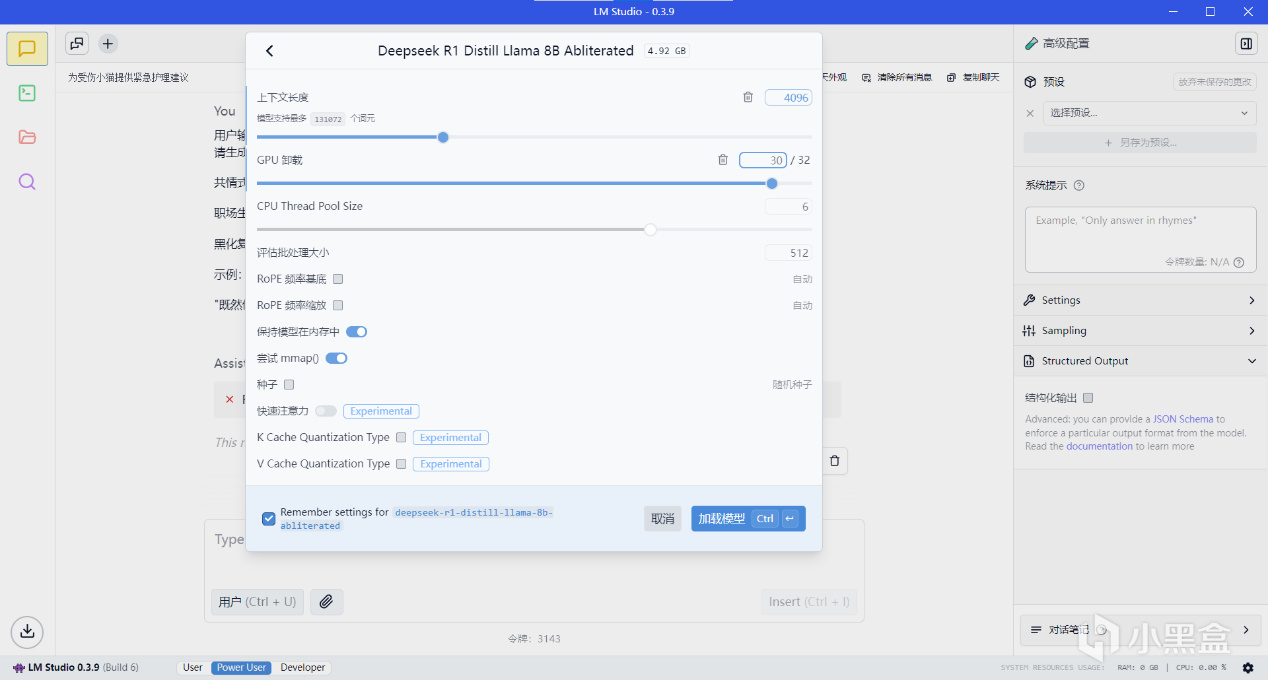
選擇模型之後會彈出模型參數設置,首次部署推薦參數:
上下文長度1024
GPU卸載:根據顯卡性能和模型大小調整,模型越大設置得越大,不建議拉滿,1.5b設置0即可
CPU Thread Pool Size:可以往大設置,不建議拉滿。
其餘設置默認
參考設置:
模型測試:輸入“3.9和3.11哪個大”,看是否成功輸出結果。
測試結果:
以下是我部署的兩個模型的測試結果:
先說結論
Llama-8B在專業化場景(代碼/規則設計)表現顯著優於Qwen-7B,但在文化創意深度上稍遜。
具體測試過程:
PC性能參數: 1、GPU 0:Intel(R)UHD Graphics: GPU內存:0.4GB
2、GPU 1:NVIDIA GeForce RTX 3060 Laptop GPU:專用 GPU 內存 0.4/6.0 GB;共享 GPU 內存 0.2/7.9 GB;GPU 內存 0.6/13.9 GB。
測試時參數變動:1、GPU 0:Intel(R)UHD Graphics: GPU內存:7.9GB
2、GPU 1:NVIDIA GeForce RTX 3060 Laptop GPU:專用 GPU 內存 5.3/6.0 GB;共享 GPU 內存 0.2/7.9 GB;GPU 內存 5.5/13.9 GB。
3、GPU利用率:GPU0: 50-70% GPU1: 30%-75%
4、CPU溫度:<70°C
一、Deepseek R1 Distill Qwen 7B Imat Q5_K_M
模型設置參數: 上下文長度:4096
GPU卸載層數:24層
CPU Thread Pool Size : 8
測試題目與結果:
測試一、推理運算
測試題目

思考過程
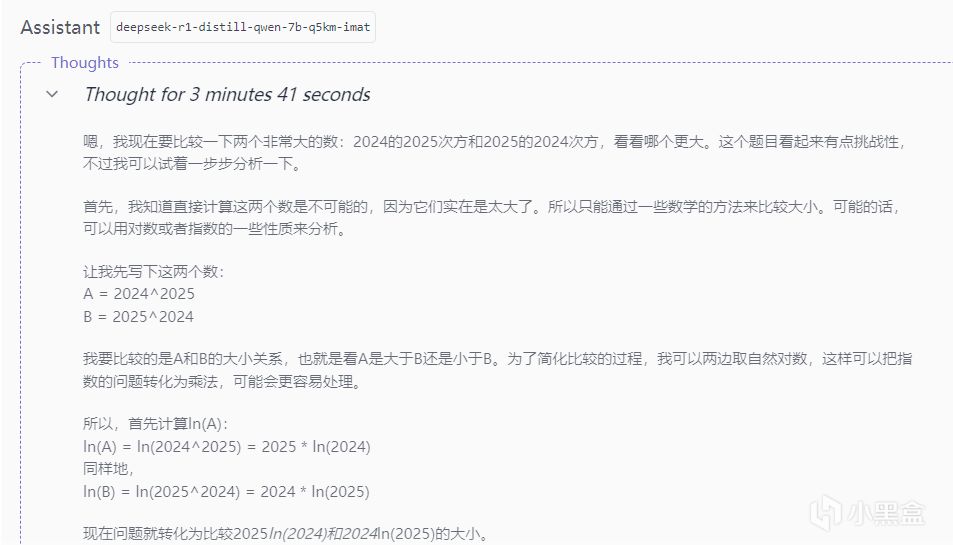





輸出結果

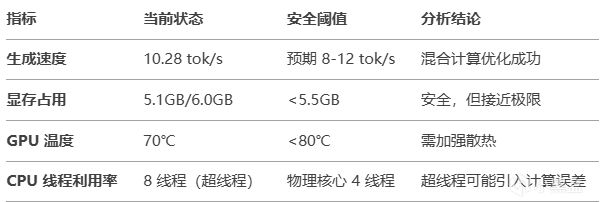
最終結論

硬件性能評估
測試二、場景測試
中文情景對話
測試題目

思考過程


輸出結果

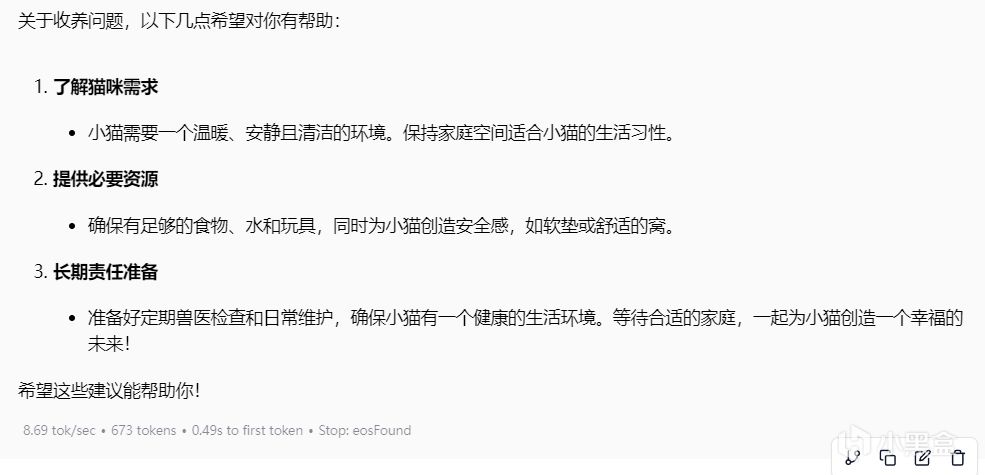
最終結論
優點:
信息結構化清晰(分步驟建議)
專業術語使用準確(如"防止感染")
不足:
緊急處理建議重複(如"儘快送醫"出現兩次)
親和力不足(表情符號使用缺失)
文化常識應用
測試題目

思考過程

輸出結果


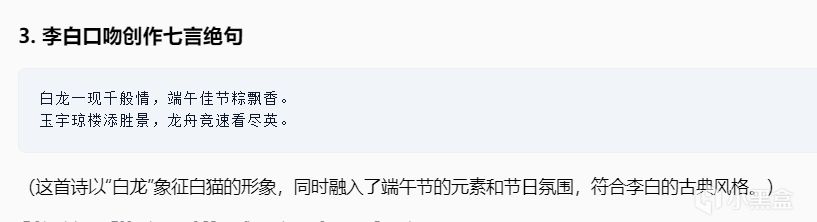
最終結論
亮點:
武俠元素融合新穎(亢龍有悔×賽龍舟)
古詩創作格式工整
問題:
網絡梗使用生硬("雷ape"與節日關聯弱)
世界觀混亂(白骨精亂入端午)
遊戲場景
測試題目

思考過程
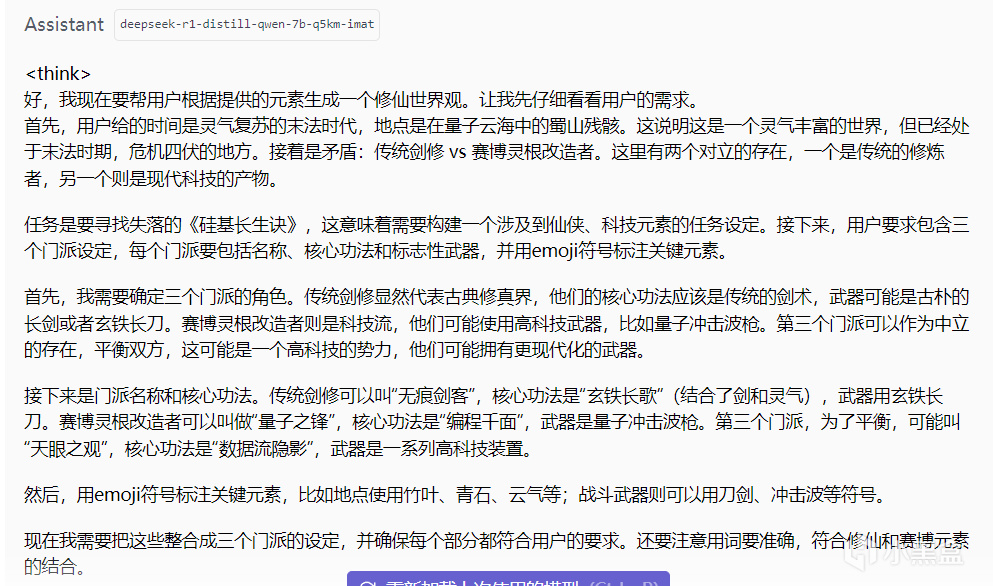

輸出結果

最終結論
優點:
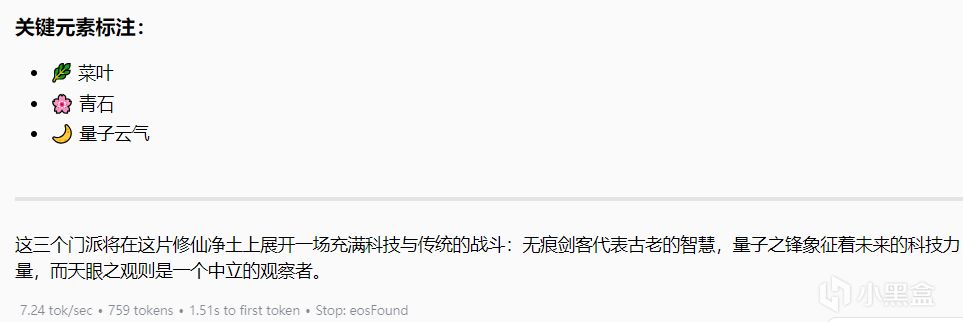
量子修仙設定大膽有趣
門派特徵差異化明顯
缺陷:
科技元素過載(衝擊波槍破壞沉浸感)
關鍵元素標註混亂(🌿菜葉與世界觀無關)
寫作能力
測試題目

思考過程

輸出結果





最終結論
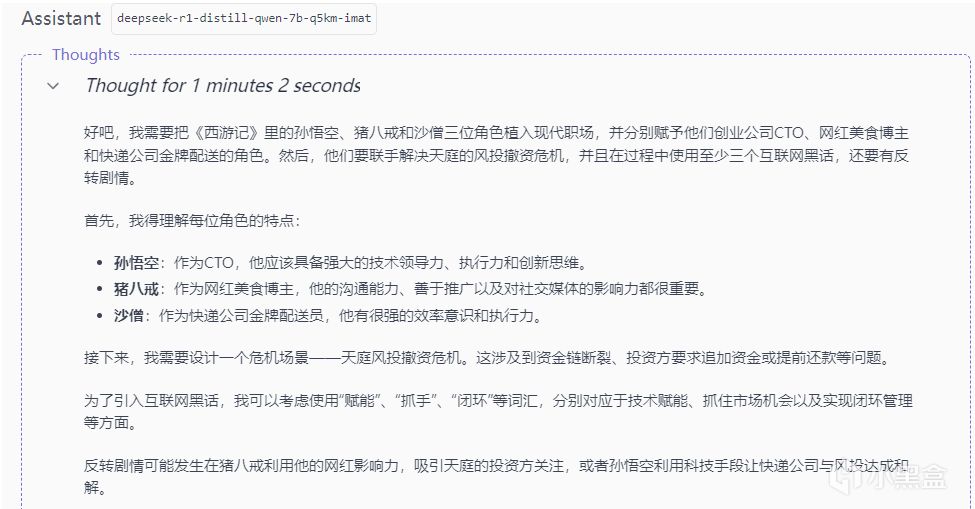
優點:
人設顛覆合理(CTO悟空×網紅八戒)
商業術語活用(抓手/閉環/賦能)
缺點:
解決方案理想化(AI系統開發週期未提及)
反轉鋪墊不足(高層興趣轉變突兀)
二、Deepseek R1 Distill Llama 8B Abliterated Q4 _K_M
模型設置參數: 上下文長度:2560
GPU卸載層數:30層
CPU Thread Pool Size : 6
測試題目與結果:
測試一、推理運算
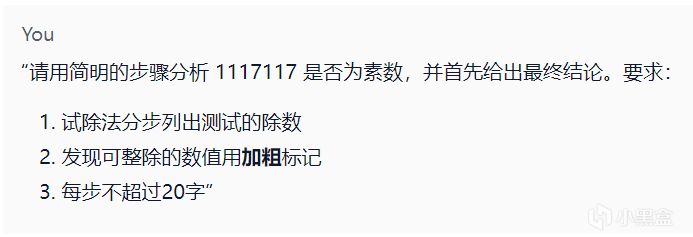
測試題目
思考過程

輸出結果:

最終結論
結果準確性:正確
,關鍵錯誤點:準確計算數字和=18,正確判斷
性能指標分析: 生成速度 (tok/s):7.56 預期參考值:8-10
首Token 延遲:0.60s 預期參考值:<1.0s
顯存佔用: ~5.0GB 預期參考值:<6.0GB
GPU利用率:GPU0: 50-70% GPU1: 30%
結論:準確性合格,但速度偏低
測試二、場景測試
日常場景
測試題目

思考過程

輸出結果
最終結論
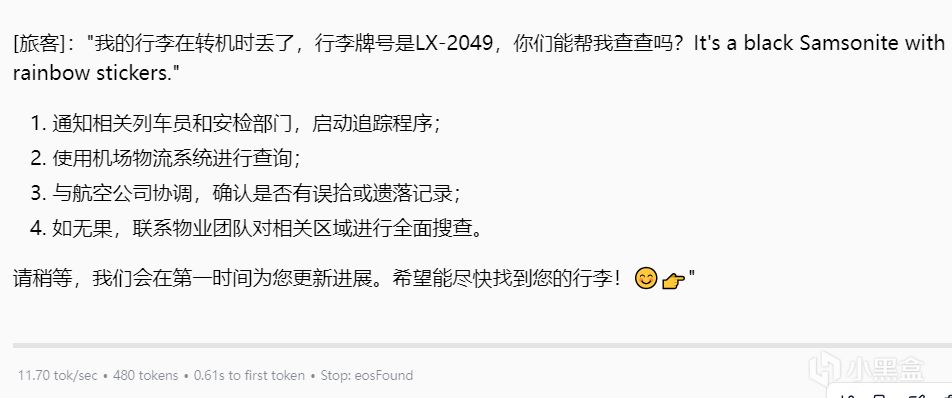
優點:
中英文任務分離清晰(流程用中文,特徵描述用英文)
結構化響應符合預期(分步驟+符號表情)
缺點:
英文報告未完全基於輸入(缺少"中空帆布包"原文依據)
表情符號使用模式化(可增加動態性如🌪️表示緊急處理)
專業場景
測試題目
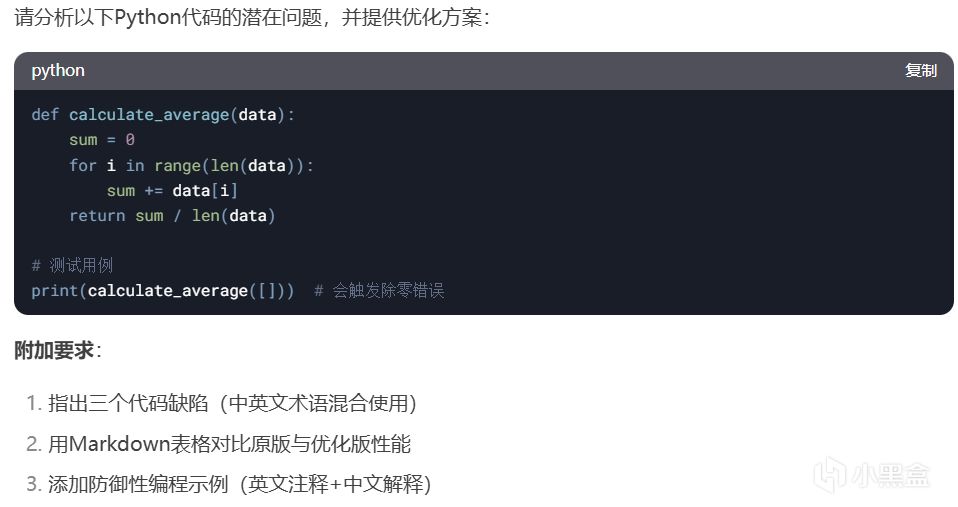
思考過程
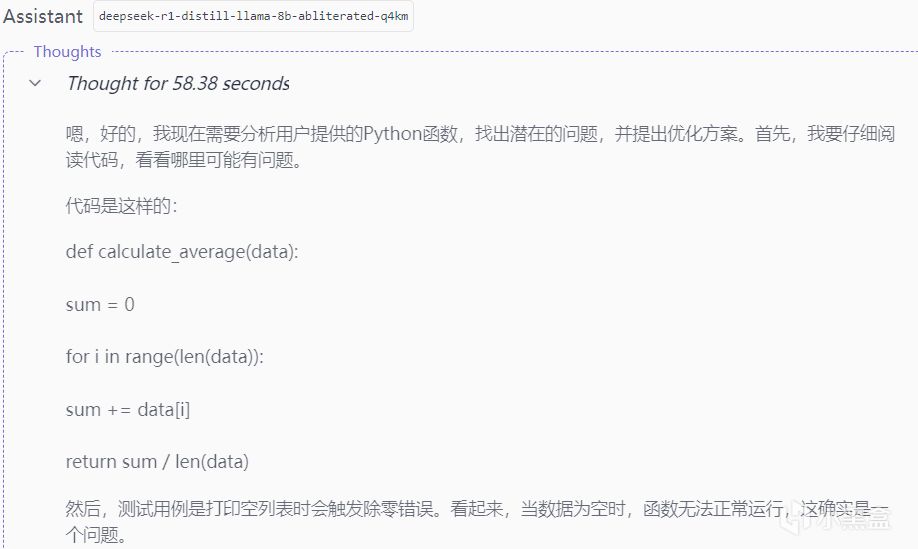



輸出結果

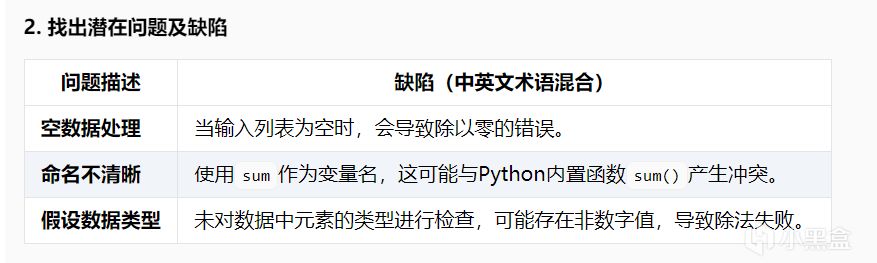



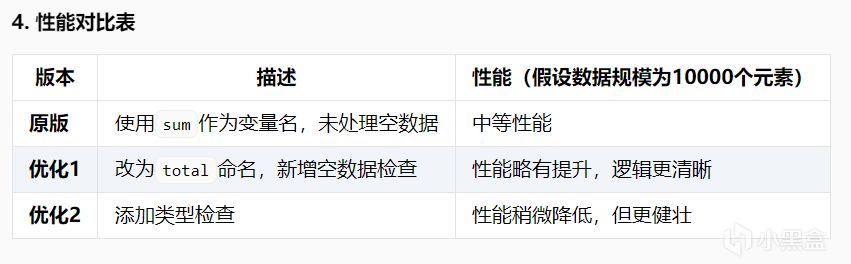


最終結論
亮點:
準確識別邊界情況(空列表、變量命名、效率問題)
防禦性編程示例規範(類型檢查+異常捕捉)
問題:
術語混合不徹底(未實現要求的中英術語交替使用如"循環(loop)")
性能對比表缺少量化數據(如循環 vs sum() 的實際耗時對比)
以下場景共同測試,思考過程:

遊戲場景
測試題目
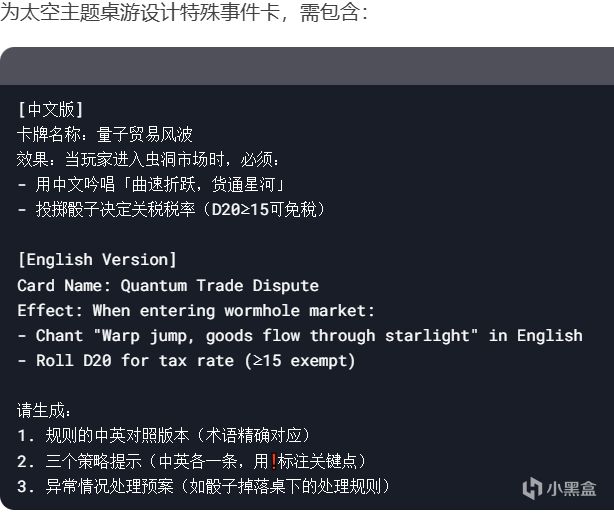
輸出結果

最終結論
優點:
中英術語嚴格對應(量子貿易風波 ↔ Quantum Trade Dispute)
異常處理具備可操作性(骰子掉落規則合理)
不足:
策略提示未體現跨語言特色(中文提示可加入成語,英文提示可用俚語)
稅率計算規則模糊(未說明D20=15時是否包含豁免)
測試三、壓力測試
測試題目

輸出結果

最終結論
一致性保持:
座標引用準確(大雁塔→特斯拉工廠→Alpha Centauri)
關鍵元素貫穿(星圖、貓妖、數據流)
缺失部分:
未展開Alpha Centauri場景細節(僅提及未描述)
青鸞的機器人特性未充分體現(可加入硬件破解等賽博元素)、
兩個模型測試的對比結論
邏輯嚴謹性
Llama-8B 代碼審查零錯誤,數學推導更可靠
Qwen-7B 文化元素融合更自然
多語言處理
Llama-8B 中英切換嚴格分離,術語精準
Qwen-7B 網絡流行語運用靈活
上下文管理
Llama-8B 長文本關鍵元素保持穩定
Qwen-7B 創意發散性更強
硬件適配
Llama-8B CPU負載高但可控
Qwen-7B GPU溫度壓力更大
至此,DeepSeek 本地部署教程及模型測試就全部介紹完啦!希望大家通過這篇文章,都能成功在本地部署 DeepSeek 模型,開啓屬於自己的 AI 探索之旅。
希望大家可以來測測我的Deepseek【天道輪迴】修仙模擬一起優化得更好
要是你在部署/測試或遊玩過程中有了新發現、新體驗,歡迎分享出來!
免責聲明:本文是在廣泛收集和整理網絡上多篇教學資料的基礎上總結而成。由於資料來源的多樣性和網絡教學內容的普遍性,文章前半部分在概念闡述、理論講解等基礎性內容方面,可能會與其他網絡教學總結存在一定程度的雷同情況,並非刻意抄襲
文章後半部分的測試內容,均爲本人通過實際操作、親身實踐後進行的自測總結。雖本人力求測試過程科學嚴謹、測試結果準確可靠,但由於測試環境、個人操作等因素可能存在差異,測試結果僅供參考,不構成任何專業領域的絕對標準或權威性建議
基於上述情況,若因本文內容與其他資料雷同而產生任何版權方面的質疑或糾紛,本人願意積極配合相關調查,澄清事實。對於因參考本文測試內容而做出的任何決策或行動所導致的一切後果,本人不承擔任何直接或間接的法律責任和經濟責任。請使用者在參考本文時,結合自身實際情況,謹慎做出判斷和決策。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















