米娜桑扣你吉瓦,好久不見
首先!!up是一個cs比賽究極愛好者,這不,上海major正如火如荼地開展,up出去逛街都看到巨型完美吉祥物了(ps:由於太喜歡donk甚至把微信名改成Donkk!
現場看的這個1v5真的當場顱內高潮好嗎qwqwqwqwq
衆所周知,一名cs選手的比賽狀態收到諸多方面的影響,老觀衆都知道,強如g2,實力強的時候強的不像話,可是卻是休賽期出了名的“娛樂隊”,往往假期過後新賽事第一兩場都表現的十分疲軟

桌子hp-100
由此可見!選手的表現受到場內外諸多因素的影響!
於是upup就有了用選手的比賽數據這個場內因素加上新聞代表場外因素得到選手綜合狀態的想法
於是這期的主題是用比賽新聞加選手數據加一些評論數據 用一些nlp的手法去預測比賽結果~~

Let’s begin~
1. 選一個模型(Longformer)
總所周知,因爲Bert的max_lenth輸入是512,而經過up處理的一場比賽的數據輸入就有上百,加上新聞數據,輸入起碼是幾千起的!於是up綜合考慮,選了Longformer這個模型,其max_lenth可以支持到4092,勉強滿足需求哈哈
2.爬取數據(從Html)
由於html有防爬蟲這個設置,導致這一步驟格外漫長與麻煩,up一共爬取了近五年的所有比賽和新聞數據,加起來一共有50多個g的大小,如果有uu想要這個數據可以找我要~~~
爬取出來的結果是這樣的
密集恐懼症犯了對吧((我也是qwq
於是我們需要一點工具對這個頁面進行處理(對news和match的網頁分別處理),用到的是BeautifulSoup這個庫去解析網頁,同時由於json文件太大,我們需要用ijson這個庫來解析巨型json文件,由於代碼有近400行,於是我這裏就不展示代碼啦,放在評論區有github連接裏面model_longformer.py這個文件裏~

{"time":1612725840,"content":"The middle of the pack sees Sangal square off with Endpoint, while GODSENT will continue on in their debut tournament against Izako Boars to cap off the first-round matches.","url":["sangal","endpoint","godsent","izako-boars"]}
這個爲新聞的一個示例,每一條新聞的不同段落都是不同的數據,數據還包含新聞發佈的時間(時間戳)以及url是這一個自然段涉及到的選手和隊伍
於是我們可以得到108627條這樣的新聞和25000場比賽數據(其實還有更多,不過來不及處理文件太大啦)
{"time":1717688400,"content":"Team ENCE won! Team HEROIC lost. The match was a Best of 1 (LAN) * Group A series that took place in 2024-06-06 23:40:00.kyxsan is a member of Team HEROICThe kd,adr,kast and rating of player degster are 22-11,108.0,80.0% and 1.63 respectively. ","url":["kyxsan","TeSeS"],"team":["ENCE","HEROIC"]}
比賽數據大概是這樣子的,包含比賽發生時間,比賽性質,誰贏誰輸,選手數據,url包含選手和隊名,team代表隊名(例子有刪減一點東西不然太長了)

3. 數據預處理
所以我們要把這些比賽數據處理成我們要的數據,就是用什麼預測什麼的數據
(在github的model_progress這個文件裏面)
代碼也有點長,我口頭敘述一下吧~大概就是把最近3個月的比賽和新聞的數據加到一個句子裏面,由於一個比賽有贏家有輸家,贏家輸家比賽分別有小於1500詞的數據,新聞各有小於500詞的數據,加起來是小於4000詞的數據,贏家輸家分別大概2000詞的數據,如果贏家在前label成1,輸家在前label成0,讓模型預測0還是1
for index, row in df_main.iterrows():
count_str = 0
timeend = int(df_match_clean.iloc[index]['time'])
timestart = int(df_match_clean.iloc[index]['time'])-3*2592000000
urllst = df_match_clean.iloc[index]['url']
winteam = df_match_clean.iloc[index]['team'][0]
loseteam = df_match_clean.iloc[index]['team'][1]
timeend1 = int(df_news_copy.iloc[index]['time'])
timestart1 = int(df_news_copy.iloc[index]['time'])-3*2592000000
urllst1 = df_news_copy.iloc[index]['url']
df1 = df_match_clean[df_match_clean['time']>=timestart]
df2 = df1[df1['time']<(timeend-100)]
df_win = df2[df2['team'].apply(lambda x: winteam in x)]
df_lose = df2[df2['team'].apply(lambda x: loseteam in x)]
df5 = df_news_copy[df_news_copy['time']>=timestart]
df6 = df5[df5['time']<(timeend-100)]
df_win1 = df6[df6['url'].apply(lambda x: winteam in x)]
df_lose1 = df6[df6['url'].apply(lambda x: loseteam in x)]

放個大概的代碼在這哈哈哈3*2592000000代表的是三個月的時間戳值
4.訓練模型
一樣是github的Longtransformer.py這個文件~
核心的代碼大概是:
texts = df1.content.tolist()
labels = df1.url.tolist() ###這裏是輸入文本和標籤(誰贏誰輸)
# 將數據分爲訓練集和測試集(這裏爲了簡化,我們不再單獨劃分驗證集)
train_texts, test_texts, train_labels, test_labels = train_test_split(texts, labels, test_size=0.2, random_state=42)
# 初始化Longformer的分詞器
tokenizer = AutoTokenizer.from_pretrained("allenai/longformer-base-4096")
# 數據預處理函數
def preprocess_function(examples):
# 對文本進行分詞
encodings = tokenizer(examples['text'], truncation=True, padding='max_length', max_length=4096)
# 將標籤轉換爲tensor
encodings['labels'] = torch.tensor(examples['label'])
return encodings
# 創建數據集對象(這裏爲了簡化,我們直接使用字典來模擬數據集)
train_dataset = {'text': train_texts, 'label': train_labels}
test_dataset = {'text': test_texts, 'label': test_labels}
# 應用預處理函數
train_encodings = preprocess_function(train_dataset)
test_encodings = preprocess_function(test_dataset)
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
return item
def __len__(self):
return len(self.encodings['input_ids'])
train_dataset = CustomDataset(train_encodings)
test_dataset = CustomDataset(test_encodings)
# 設置訓練參數
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
evaluation_strategy="epoch")
# 加載Longformer模型並設置爲二分類任務
model = LongformerForSequenceClassification.from_pretrained("allenai/longformer-base-4096", num_labels=2)
# 實例化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
)
# 開始訓練
trainer.train()
# 保存模型
model.save_pretrained('./longformer-binary-classification')
tokenizer.save_pretrained('./longformer-binary-classification')
大概就是這樣啦
5.模型訓練情況與結果
由於輸入實在太大了。。。對顯卡的要求也巨大,我試着在4090上跑顯示顯存不夠你敢信lmao

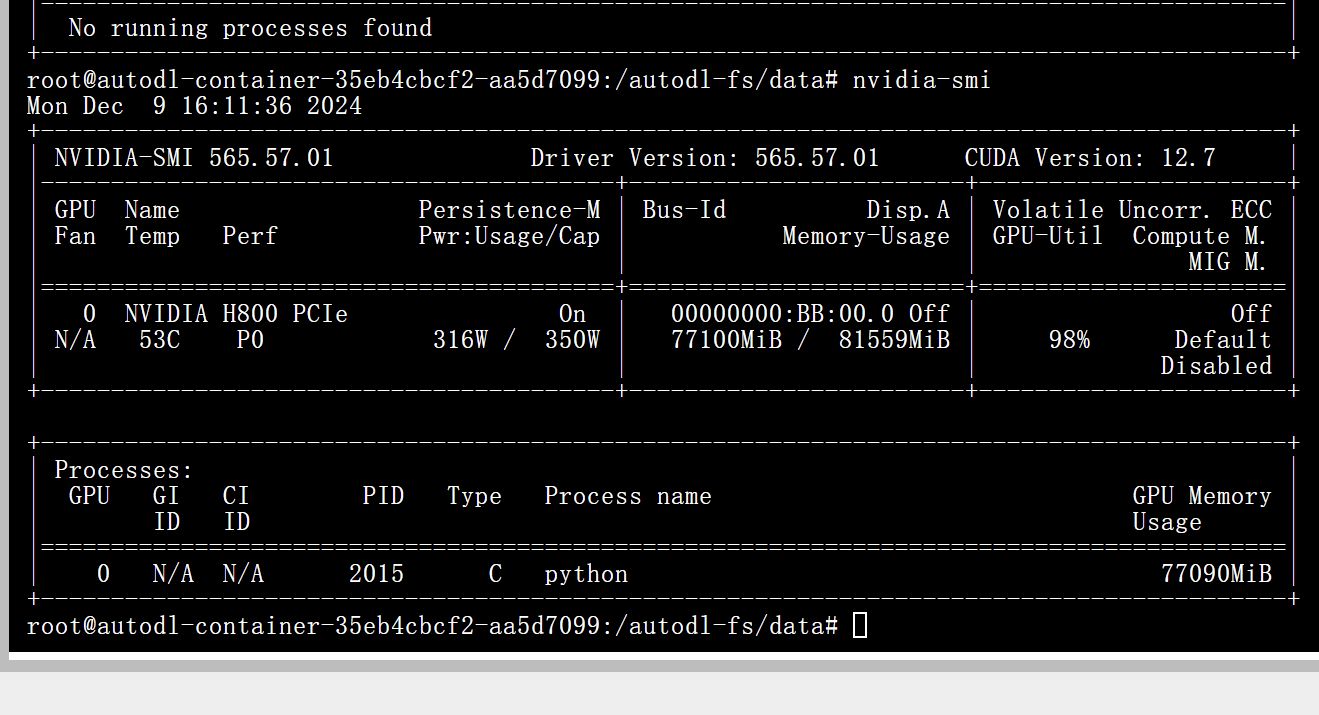
如圖啦,最後是用H800跑了一個多小時才跑出來的哈哈哈
不過結果不是很如意,預測準確率不到七成

預測結果如下
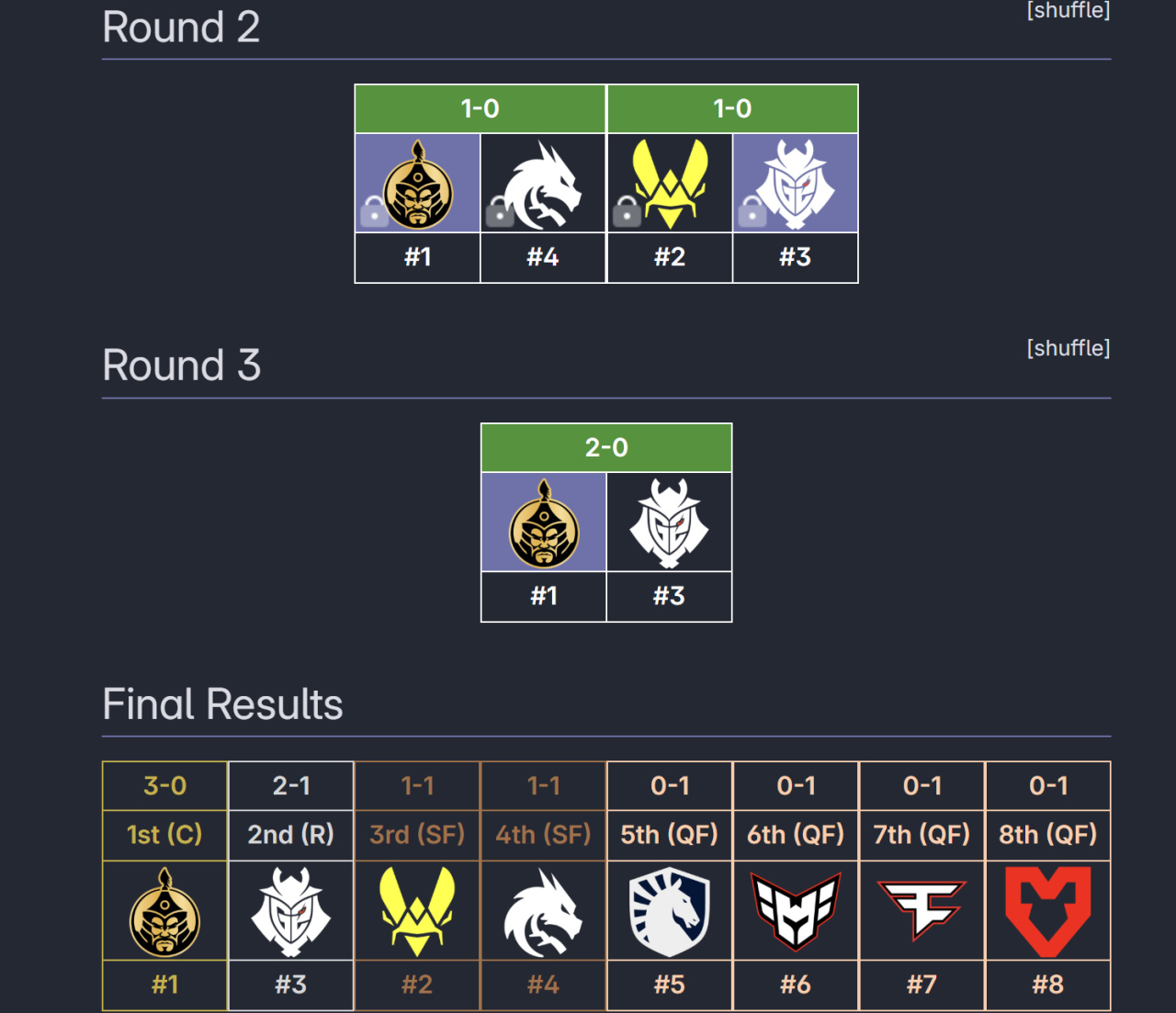
The Mongolz取得了最後的勝利好吧大家還是別輕易相信(可能是那些說蒙古黑馬黑馬的新聞發多了
6.總結 與改進展望
其實跑整個模型耗時挺久,結果也不太理想,思來想去,可能是選手數據文本化模型不是很能理解得到(當初這麼做是想讓模型學習然後有選手名字對選手數據以及選手新聞的依賴)
所以也有另一種做法就是單獨把新聞bert_tokenizer數值化,然後選手的比賽數據直接用數值輸入(你可以對一場比賽五個選手的不同數據做一個卷積,確定特定的輸入比賽數目,諸如此類)
不過因爲upup要期末啦,所以這些新的實驗就交給萬能的盒友們啦,大家有什麼新想法也可以告訴我呀~
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













