最近在一次整理電腦文件的時候遇到了這樣一個問題,在C盤的用戶文件夾裏,有許多“������”“閻滃緙氶柧鐠ppData“等等這些令人摸不到頭的名字。
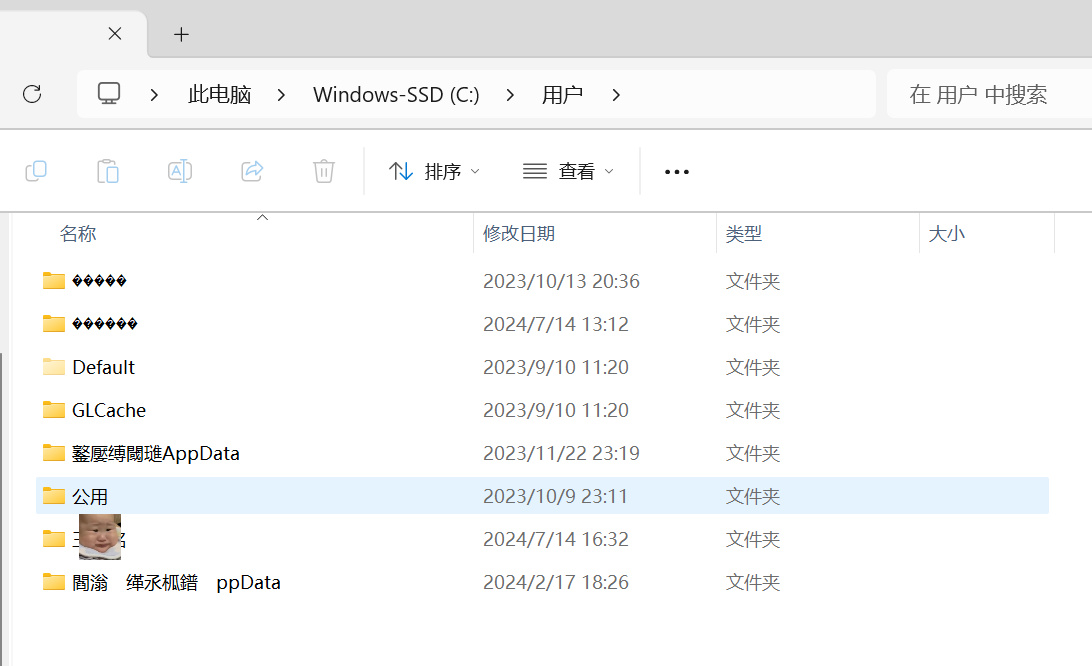
我的c盤
爲了理解這一問題,我們首先要明白,我們的計算機只能識別二進制語言,無法直接讀取”盒“”h“”3“這樣的漢字,字母或者數字。換句話說,我們的計算機只認0和1。
計算機顯示出文字,這一過程涉及三個概念,”字符“”字符集“”字符編碼“。”你“”好“這兩個就是字符,而組在一起”你好“,便成了字符集,可是我們的計算機無法理解”你好“,這時候便需要我們進行編碼轉換成計算機可以理解的“語言”。
這裏我們可以運用小學數學知識進行理解
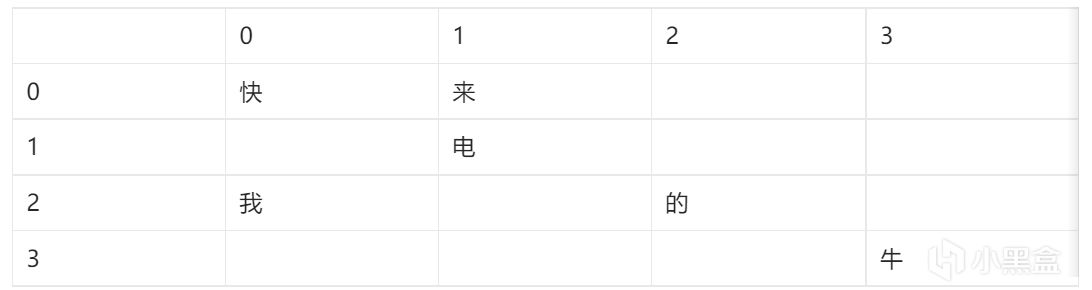
可以理解爲座標?
我們首先把行和列的標號轉換爲二進制
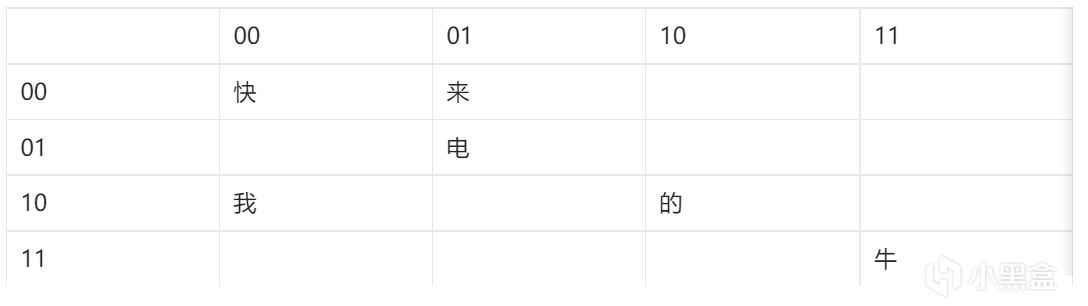
編碼成二進制
”快來電電我的牛牛“這句話在計算機看來就成了”0000 0001 0101 0101 1000 1010 1111 1111“

計算機存儲的基本單位是”字節“,一個字節有8個二進制位(0或1)組成,這樣的話,一個字節便可以表示2^8個狀態,可對於26個英文字母可算是一個天文數字了。後來美國人制定了”美國信息交換標準代碼“,也就是ASCII,其中收錄了26個英文字母以及數字標點還有其他字符,總共所佔用的字符也就是128個。
此時此刻英語體系的世界完成了計算機文字編碼和使用。
可是世界上的語言有很多,其他國家也需要自己的編碼標準來適配自己的語言。上面說到了1個字節可以有256個狀態,ASCII只佔用了一半的空間,剩下的一半就被其他國家自己拓展使用,制定了許多版本的“擴展美國信息交換標準代碼”EASCII,如此紛雜的標準,導致同一段字符集在不同的標準體系下表示不同內容,這時便產生了亂碼。
這時我們將目光轉到漢語。漢語比於其他語言體系要大得多,單單日常生活中最常用的漢字已經有了上千個,外加一些生僻字簡直數不勝數。同時漢字不但有簡體和繁體之分,整個東亞文化圈的國家都或多或少有漢字的使用,這就爲信息交換代碼標準的制定造成了很大的困難。
中國自己制定了GB2312標準,日本朝鮮韓國也都有自己的編碼標準,彼此之間的兼容性很差,後來微軟制定了GBK,對GB2312進行一個拓展,但實際上也沒有改善兼容性問題。

爲了解決不同語言體系編碼標準不同這一問題,人類制定了Unicode”統一碼“,它覆蓋了多種語言,體系也十分龐大。
但是但是但是!
雖然統一碼的覆蓋範圍廣,可是編碼方式有很多種,比如UTF-8,UTF-16、UTF-32
這些不同的編碼方式將Unicode的字符以特定的方式轉換成二進制,生成計算機語言。但是不同的編碼方式彼此之間無法相互理解,同一個字符或許在不同的編碼方式中意思天差地別!
理解了這些,那”錕斤拷“的來歷就好說了。
本質上說,這些所謂的亂碼就是轉碼標準不同的結果,GBK標準與Unicode標準兩者的轉化,最後導致信息錯亂,生成了”錕斤拷“等亂碼。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















