AI大模型的推理訓練,最渴求的就是強勁的算力,可以來自CPU通用處理器,可以來自GPU加速器,可以來自ML/DL加速器,也可以是多種異構硬件的組合。
當下最火的當然是NVIDIA GPU加速器,但一花獨放不是春,能夠提供強勁算力硬件方案的廠商很多。
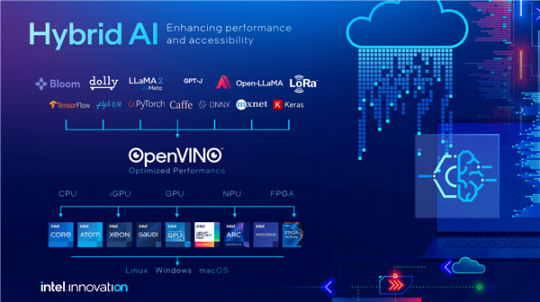
縱觀整個AI江湖,唯一擁有全套方案、可真正替代NVIDIA的,只能是Intel:至強處理器、GPU Max、Gaudi加速器多管齊下,再加上強大豐富的開發工具、開放生態的開發平臺,要啥有啥,表現還相當不賴。
今年6月,機器學習與人工智能開放產業聯盟MLCommons公佈了AI性能基準測試MLPerf Training 3.0的結果。
結果顯示,Intel四代至強內置的各種加速器,使其成爲在通用CPU處理器上運行大量AI工作負載的理想方案,Gaudi2加速器則在生成式AI、LLM大語言模型方面有着優秀的性能。
此外,Intel還提供了經過優化的、易於編程的開放軟件,降低AI部署門檻。

8月份,MLCommons又公佈了針對60億參數大語言模型、計算機視覺與自然語言處理模型GPT-J的 MLPerf 3.1基準測試結果,Intel的表現依然值得稱道。
其中在GPT-J模型上,Gaudi2加速器的GPT-J-99、GPT-J-99.9服務器查詢和離線樣本的推理性能分別爲78.58次/秒、84.08 次/秒。
與競品比較,Gaudi2相對於NVIDIA上一代A100的性能優勢可達2.4倍(服務器)、2倍(離線),而最新一代的H100相對於Gaudi2也只有1.09 倍(服務器)、1.28 倍(離線)的微弱優勢。


同時,Intel四代至強在視覺、語言處理、語音、音頻翻譯模型,以及更大的DLRM v2深度學習推薦模型、ChatGPT-J模型上處理通用AI負載時,性能都非常出色。
比如使用GPT-J對大約1000-1500字新聞稿進行100字總結的任務,四代至強在離線模式下每秒完成兩段,實時服務器模式下則可完成每秒一段。
此外,Intel還首次提交了至強CPU Max處理器的MLPerf測試結果,其集成最多64GB HBM3高帶寬內存,對於GPT-J而言是唯一能夠達到99.9%準確度的CPU,非常適合精度要求極高的應用。
還有非常關鍵的一點:迄今爲止,Intel是唯一一個使用行業標準深度學習生態軟件並公開提交CPU結果的廠商,Gaudi2是僅有的兩個向GPT-3大模型訓練基準提交性能結果的解決方案之一。

那麼,Intel Gaudi2加速器、至強處理器爲何能在AI算力上如此彪悍?Habana Labs中國區總經理於明揚做出了詳細解讀。
據介紹,MLPerf 3.1推理測試中,Gaudi2和H100一樣都採用了FP8精度,GPT-J測試結果非常令人滿意,準確率高達99.9%,和H100的差距非常小。
這主要是因爲Gaudi2 MME支持FP8、BF16精度加速,而且結構設計合理,可以高效提升推理能力。
同時,Gaudi2也和H100一樣使用了HBM高帶寬內存,Intel也很好地預測了市場,並預估了額外的需求,因此基本保證了供應和生產,可以滿足市場需求,不像NVIDIA那麼頭疼產能。
至於A100,它並不支持FP8而僅支持FP16,所以Gaudi2比之優勢非常明顯,這也顯示了Gaudi2架構和軟件設計的領先性,以及資源利用率的高效性。
非常關鍵的是,Intel Gaudi2的性價比優勢明顯,不像A100、H100那樣動不動幾十萬一塊,讓中小企業和個人開發者望洋興嘆。
Intel也已經開放了開發者雲,讓不同客戶可以訪問不同的Intel AI硬件,大大降低AI工作成本。

除了硬件性能的比拼,Intel也在軟件生態上持續大力投入,雖然暫時還做不到NVIDIA CUDA生態那樣有着獨一無二的優勢,但也有自己的突出特點。
於明揚強調,在軟件生態上,Intel一直主張開放,比如通過開發者社區與開發者互動,提供優化後的模型、開源驅動和工具庫,並支持Pytorch、Deepspeed等開源框架,加入和維護開放生態,爲客戶、合作伙伴和開發人員提供早期訪問和便捷、迅速的途徑。
Intel oneAPI也能提供更爲開放的環境,支持不同層面的定製化開發,Intel和客戶都可以在軟件中添加新的加速算子,並且upstreaming到框架開源社區中。
值得一提的是,在軟件上CUDA的影響已經大大縮小,對整體開發和應用環境更加有利。

事實上,NVIDIA目前的強大隻是GPU一條腿走路,CPU通用處理器是欠缺的。
雖然NVIDIA也開發了Grace CPU,並打造了所謂的“超級芯片”,可以將兩顆Grace CPU或一顆Grace CPU加一顆H100 GPU進行整合,但畢竟是基於Arm架構,性能較弱,而且缺乏通用性。
Intel則憑藉多管齊下的多硬件組合,可以構建強大、靈活異構計算平臺,從而支持更大的模型規模,滿足更廣泛的系統需求。
於明揚指出,至強可擴展處理器有着最好的通用性,可以運行各種AI工作負載。
四代至強還衍生出了的至強CPU Max系列,是行業唯一一款具有HBM高帶寬內存的x86處理器,無需更改代碼,即可加速多種HPC、AI工作負載。
Gaudi系列加速器則專注於機器學習、深度學習的環境,以及未來對大語言模型的需求。
當然還有數據中心GPU Max系列,雖然纔剛剛誕生,但是擁有47個功能模塊、1000多億晶體管的它,有着巨大的潛力和廣闊的前景,在各種科學負載中相比H100可綜合領先30%,還已經用於百億億次超級計算機“Aurora”。
這樣的豐富組合,別說NVIDIA,在整個行業內都沒有可與之匹配的。

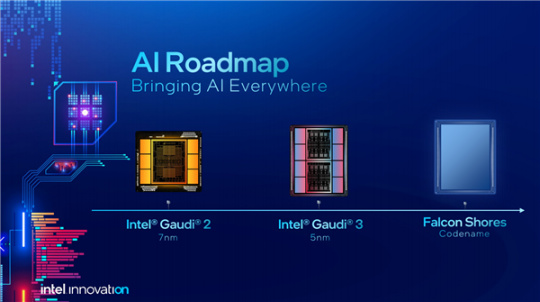
面向未來,Intel也自信滿滿地公佈了Gaudi加速器、至強處理器的多年路線圖,讓人充滿期待。
Gaudi 3將把製造工藝從7nm升級到5nm,帶來的性能提升堪稱一次飛躍:
BF16算力提升4倍,計算性能提升2倍,網絡帶寬提升1.5倍,HBM高帶寬內存容量提升1.5倍。
從示意圖上看,Gaudi3的主芯片將從單顆升級爲兩顆整合,HBM內存則從6顆增加到8顆。
再往後更是革命性的變化:Falcon Shores將是Intel第一次把x86 CPU、Xe GPU雙架構融合在一起,官方稱之爲XPU,類似AMD Instinct MI300A。
按照Intel之前給出的數字,對比當今水平,Falcon Shores的能耗比提升超過5倍,x86計算密度提升超過5倍,內存容量與密度提升超過5倍。
Emerald Rapids五代至強將在12月14日正式發佈,這是至強歷史上第一次一年內更新兩代,增加到最多64核心128線程,同樣功耗水平下可提供更高的性能和存儲速度。
2024年上半年,至強將首次採用E核能效核設計,代號Sierra Forest,最多達到驚人的288核心288線程,而且首次引入Intel 3製造工藝,預計可使機架密度提升2.5倍、每瓦性能(能效)提高2.4倍。
緊隨其後的是同樣Intel 3工藝、全部P核性能核設計的Granite Rapids,AI性能對比四代至強預計可提高2-3倍。
2025年,我們將看到代號Clearwater Forest的再下一代至強,純能效核設計,升級爲Intel 18A製造工藝。
按照規劃,那個時候,Intel將重新奪回製程工藝的領先地位,對於提高AI硬件的能效大有裨益。
總之,未來在AI計算領域,Intel將會提供更加強大、可滿足不同應用場景和TCO成本的AI產品組合,爲客戶打造統一的開發平臺,形成完整的產品生態鏈。

來源:快科技
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















