在今年六月份,英特爾宣佈Meteor Lake架構酷睿處理器引來命名規則的重大改變,即P、U等低電壓處理器更名成酷睿Ultra系列,並全系更新品牌標識,包括酷睿,Evo平臺,vPro平臺,分級方式劃分成酷睿Ultra 5、酷睿Ultra 7和酷睿Ultra 9,酷睿新時代的序幕緩緩拉開。

英特爾低電壓處理器平臺爲何從酷睿i系列轉向酷睿Ultra系列,Meteor Lake有什麼樣的魅力?在Intel Tech Day 2023上,我們看到了12代與13代酷睿,即Alder Lake和Raptor Lake後,最大的一次升級。隨着技術解禁,讓我們花一些時間詳細瞭解Meteor Lake的特性,本次將分成整體架構和SOC架構解析兩篇文章進行,此爲第一篇整體架構解析,幫助我們瞭解Meteor Lake的大致細節。如果想更深入瞭解每個Tile的工作方式,可以移步至《酷睿Ultra的高效能祕籍,英特爾Meteor Lake SOC模塊架構淺析》。

從整體上來說,Meteor Lake的提升主要概括爲幾個方面,分別是:
1、能耗比進一步提升,即性能和續航都將有更好的表現;
2、首次引入人工智能加速引擎NPU,即NPU原生放在Meteor Lake中;
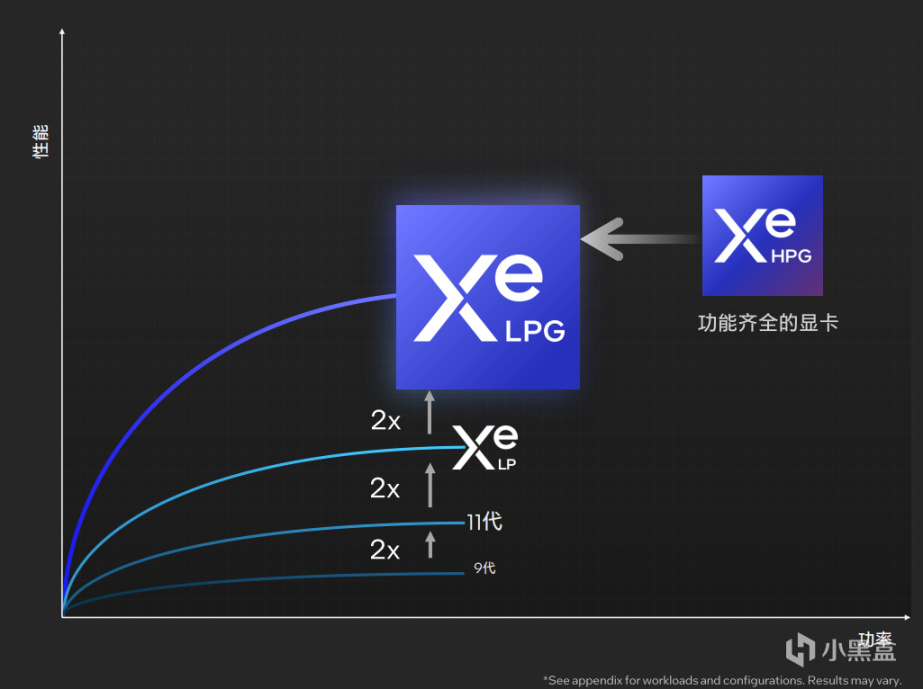
3、核顯iGPU獲得了獨顯GPU的經驗回饋,Meteor Lake的圖形性能將大幅提升;
4、首次採用Intel 4製程以及Foveros 3D封裝,併爲其匹配了合適的P-Core與E-Core微架構。
接下來我們將逐一說明。

分離式模塊一馬當先
如果說12代酷睿的P-Core與E-Core劃分是分水嶺的開始,那麼更進一步的分離式模塊設計將會成爲酷睿Ultra未來的主題。按照英特爾的設計思路,處理器通常由Core和UnCore部分組成,前者負責常規的模塊計算,後者負責計算之外的內容,從而增強處理器在實際使用中的兼容性,或者針對特定場景有明顯加速等等。例如提供比AMD擁有更好的擴展兼容,以及新增的AI模塊就是很好的例子。

在Core部分,也就是計算模塊,可以看到英特爾展示的Core由6個P-Core和2組E-Core族羣組成,每組E-Core族羣內包含4個E-Core,因此在物理計算單元上爲6個P-Core,8個E-Core,並且由於P-Core本身支持超線程技術,從而構成了14C20T的結構。而酷睿Ultra 5、7、9的劃分,則主要依靠P-Core、E-Core頻率和數量實現,與酷睿i系列時代相當。

UnCore部分則比以往要複雜得多,從大體上看,包含iGPU、I/O以及位於Die正中間的SOC部分。SOC模塊與封裝層面的SoC(System on Chip)概念略有不同,這裏是指芯片級別的整合,可以將其理解爲CPU的範疇內。
英特爾重新定義SOC模塊是將UnCore提升到了一個更重要的級別。實際上在SOC模塊中我們依然能夠看到很多的熟悉的模塊。比如負責無線連接的Wi-Fi 6E & Bluetooth,同時也將會通過外接的形式實現對Wi-Fi 7的支持。再比如原來放在iGPU中的媒體處理計算單元,也就是編解碼器硬件,這裏包含對AV1格式編碼、8K HDR的支持。除此之外,SOC模塊還包含輸出單元、內存控制器等等。
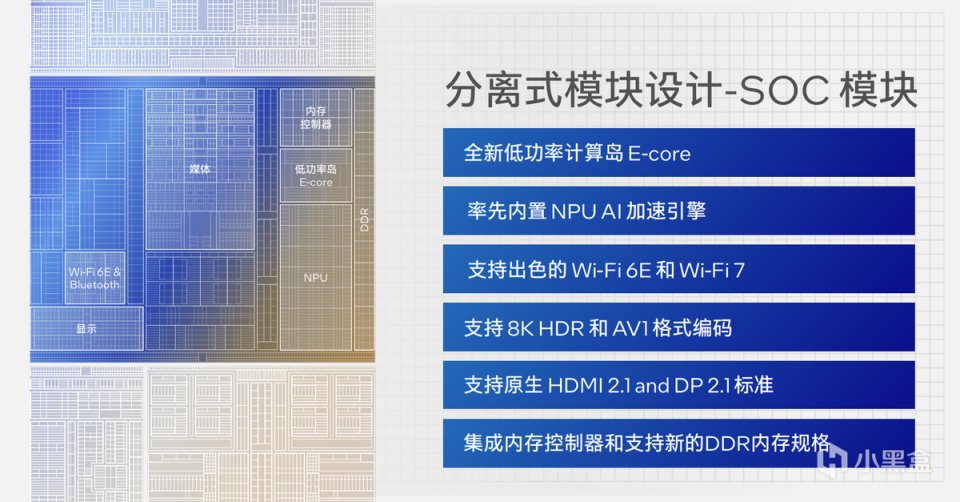
SOC模塊中還包含一個新的低功率島E-Core,以及用於AI加速的全新NPU。因此在Meteor Lake的計算方式上,從原來的P-Core、E-Core二階計算模式基礎上,通過增加SOC模塊實現三階混合計算架構。英特爾希望通過新的計算層級,實現更好的線程調度與功耗平衡。

在SOC模塊中,我們需要關注首次集成人工智能加速引擎的NPU。這不是英特爾處理器第一次涉及人工智能加速,部分13代酷睿處理器中就包含了Movidius VPU用來實現CPU與GPU分載形式完成AI加速。英特爾希望通過新增的NPU模塊實現更低功耗的人工智能加速,比如連續3個小時視頻通話的背景虛擬化加速,再比如利用輕薄本運行時下流行的Stable Diffusion。
更重要的是,NPU與Meteor Lake的連接使用了Foveros 3D封裝技術,這是英特爾首次大規模在消費領域使用Foveros。在此之前,Foveros基本應用在服務器處理器、高密度計算GPU、FPGA以及2019年小批量嘗試的Lakefield中,屬於非常高科技的疊疊樂,具體封裝細節我們會在後續封裝中進行詳細說明。
在SOC模塊上方,則是Meteor Lake引入的全新iGPU核顯,按照英特爾的說法,新核顯在性能上有更明顯的提升,並且能夠更好的支持DirectX 12功能集,讓輕薄本獲得更好的圖形效果。

最後一個重要模塊則是負責整個處理器對外設備的I/O模塊,包括PCIe支持以及Thunderbolt連接。其中PCIe最高支持PCIe 5.0版本,Thunderbolt則仍然是Thunderbolt 4,前段時間發佈的Thunderbolt 5在未來一段時間中將以獨立芯片的設計存在。

Intel 4製程工藝參上
Meteor Lake性能與功能進步很大原因取決於Intel 4製程工藝能夠支持其進入量產。按照英特爾的說法,Intel 4目前進度符合預期,能夠很好的幫助英特爾進階到接下來的Intel 3、Intel 20A和Intel 18A製程工藝中,屬於重要的製程節點。

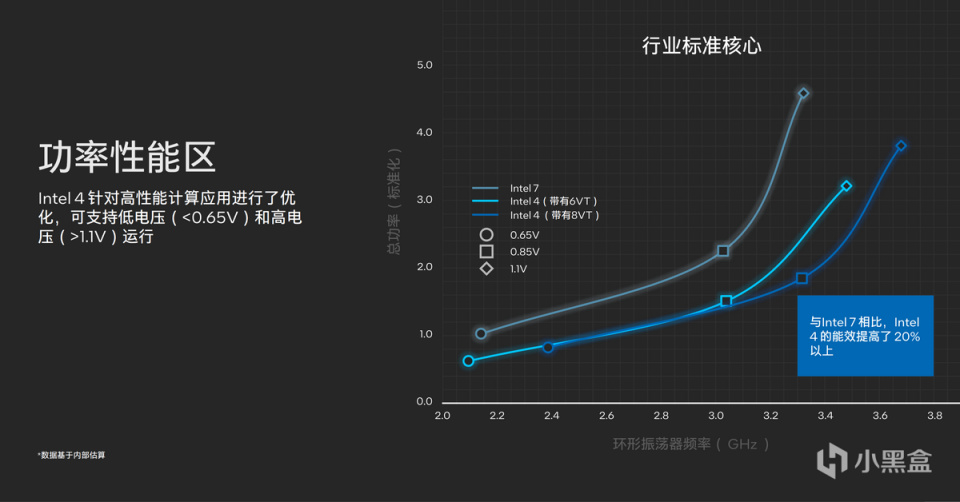
Intel 4製程工藝幫助英特爾CPU實現了更高性能的邏輯庫,讓Die的面積相對Intel 7有兩倍的縮減,同時所採用的EUV光刻技術不僅滿足了將Die變小的工藝,也進一步在製造中簡化了流程,並幫助CPU提升了20%的性能與能耗比。

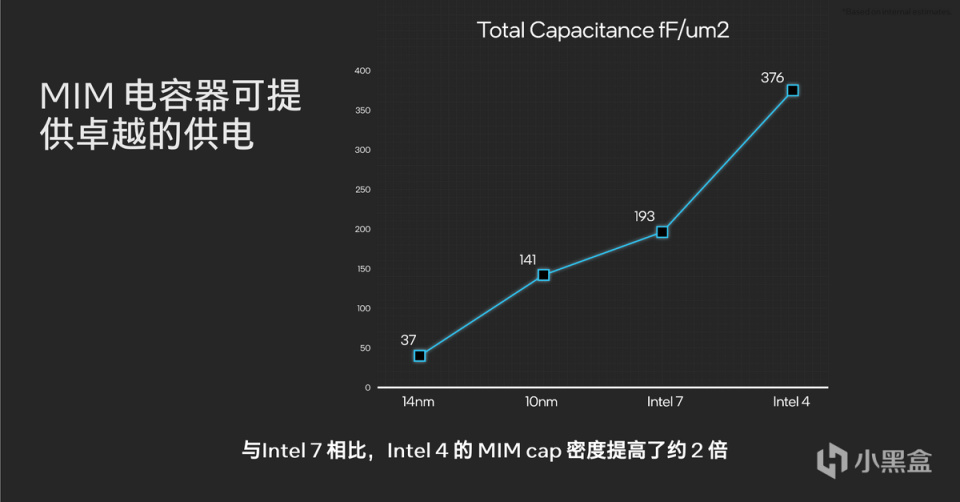
與此同時,在CPU設計上,英特爾通過8VT的場效應晶體管(FET)的閾值電壓(Threshold Voltages)實現更好的頻率與電壓關係,同時進一步加大MIM(Metal-Insulator-Metal)電容器設計密度,實現高密度MIM的高效底層供電。
當然,重點是Intel 4製程工藝帶來的整體Die集成度變化,以高性能庫高度爲例,Intel 7的高度可以做到408nm,Intel 4則可以進一步縮減到240nm,縮減了將近0.6倍,也就是40%的尺寸縮減。同時,鰭片間距和M0(金屬0)間距均有不同程度縮減。
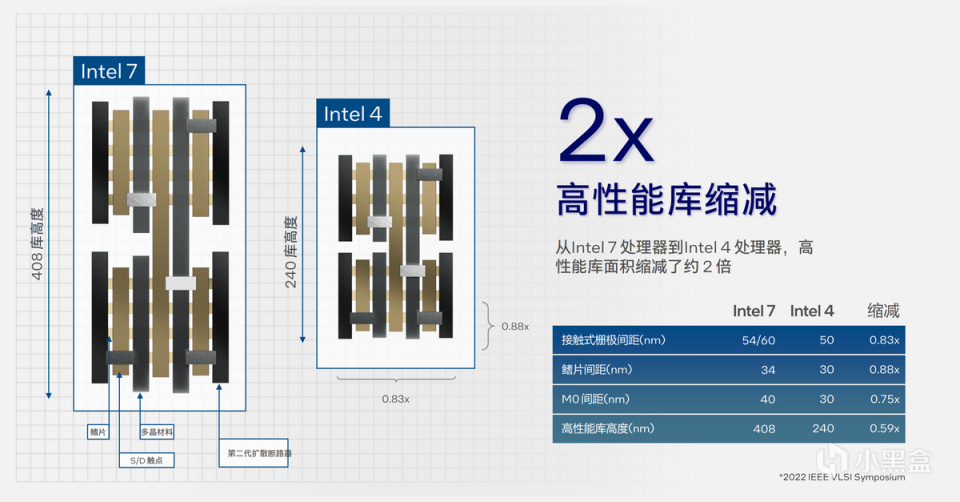
在18層金屬層堆棧上,由於多層級EUV技術,英特爾通過四重自動成像工藝,實現了更高的密度,進一步使得30nm金屬層間距縮小,也爲佈線提供了很好的支持。

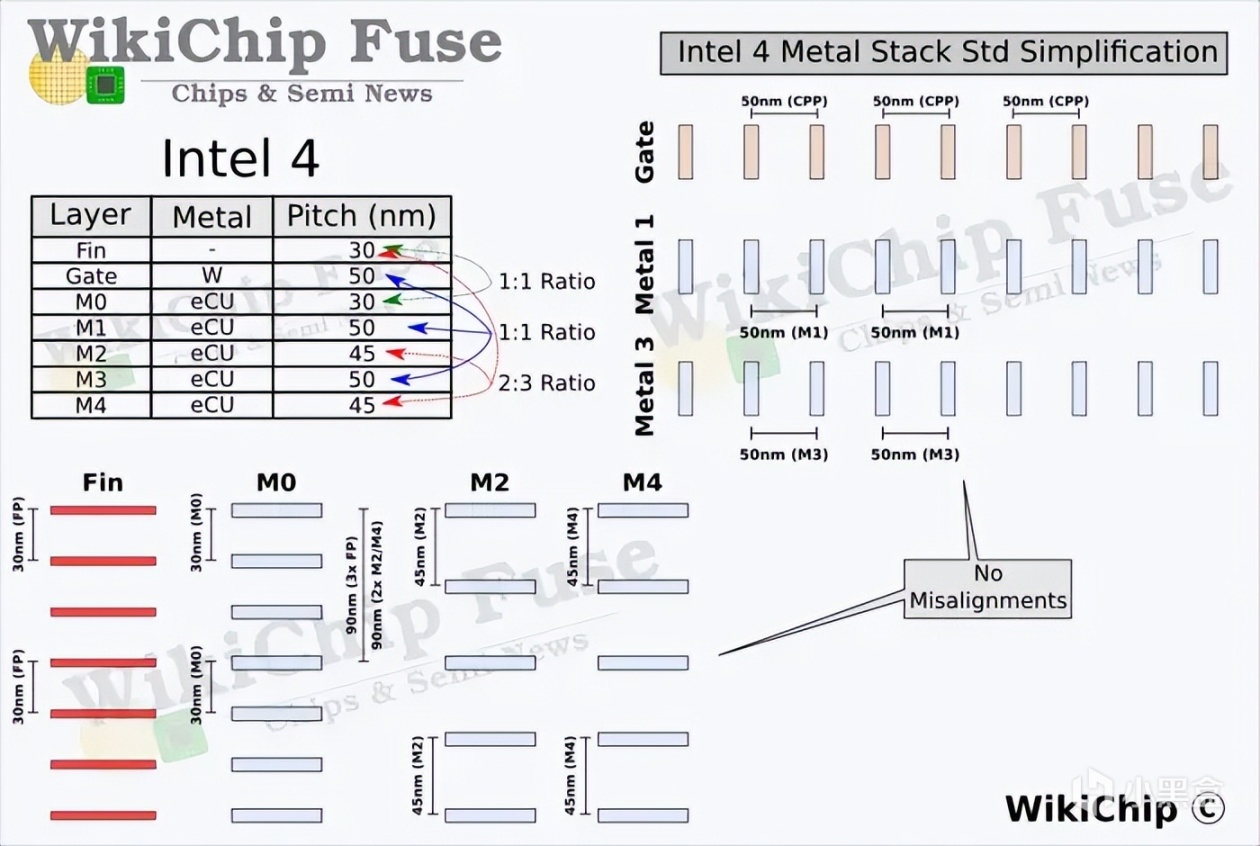
圖片來源:WikiChip
通常而言,新制程工藝主要關注兩個指標,一個是如何在間距變小的情況下提升導電率,即降低電阻。同時也要保證電子遷移的壽命足夠長,讓其處在一個理想的工作區間。在Intel 7製程中,英特爾嘗試使用不同材質的特殊金屬層說來達到兩者平衡,但實際情況事與願違。例如銅合金雖然能夠降低電阻,電子遷移壽命成了問題,但如果使用鈷金屬,電子遷移壽命延長,但電阻隨之變大。因此Intel 4嘗試使用新的增強型銅金屬工藝,也就是鉭/鈷與純銅合金來解決這個問題。

EUV極紫外光刻技術是另外一個幫助Intel 4實現提升的重要技術。如前面所言,在EUV投入使用之後,不僅提升了晶體管密度,並且答覆減少了流程複雜度,原本1個柵格+4個收集層的工藝,現在只需要單層EUV即可實現,從整體上降低了3到5倍的處理步驟。因此可以這麼理解,在使用更高階的EUV之後,工藝沒有變複雜,反倒變得簡單高效了。

不僅如此,新的EUV技術讓連接結構變得更標準化,原本Intel 7需要多個標準實現不同的連接模式,在EUV上可以做到統一。並且自動分佈和自動路徑工具APR Tool也可以在佈局、單元擺放、時鐘數統一和佈線上做到更高效的自動化設計,在不降低效率的前提下,進一步降低對人工經驗的依賴,這無疑是很大的進步。

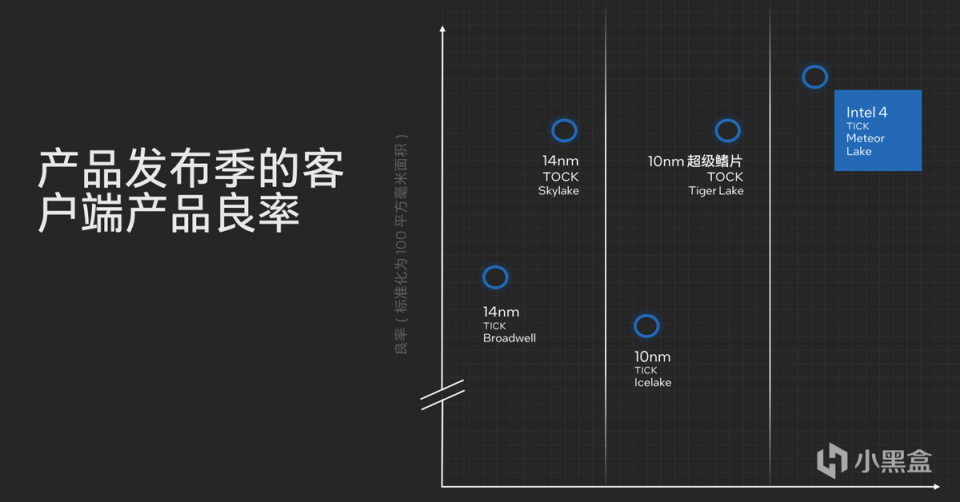
英特爾強調,在使用Intel 4製程工藝和EUV後,處理器的良率表現非常好,相比14nm和10nm時代都是一個明顯的進步,更重要的是Intel 4的良品率提升,也會推進會進一步加快未來Intel 3、Intel 20A和Intel 18A的進度。
3D封裝的勝利
戈登·摩爾曾經表示,在構建大系統時,將其分解爲單獨封裝並互連的較小功能可能更經濟。在構建複雜系統時,通過分解成單獨封裝並提供小型化的互聯模塊可以帶來更好的經濟性。

隨着小型化互聯技術的成熟,多模塊、小芯片Chiplet設計開始變得司空見慣,在Meteor Lake上,通過小型化模塊連接實現2.5D和3D封裝,實現Die與Die之間的高密度連接,無疑可以讓產品功耗、成本、性能都佔盡優勢。

英特爾嘗試具備互聯模塊的封裝其實由來已久。從2013年開始,就嘗試將酷睿處理器和芯片組放在同一個封裝內。在2017你那則實現了EMIB(嵌入式多芯片互連橋接)的2.5D封裝來量產FPGA Stratix 10。在2023年,至強處理器Sapphire Rapids,更是進一步大規模使用了EMIB技術。
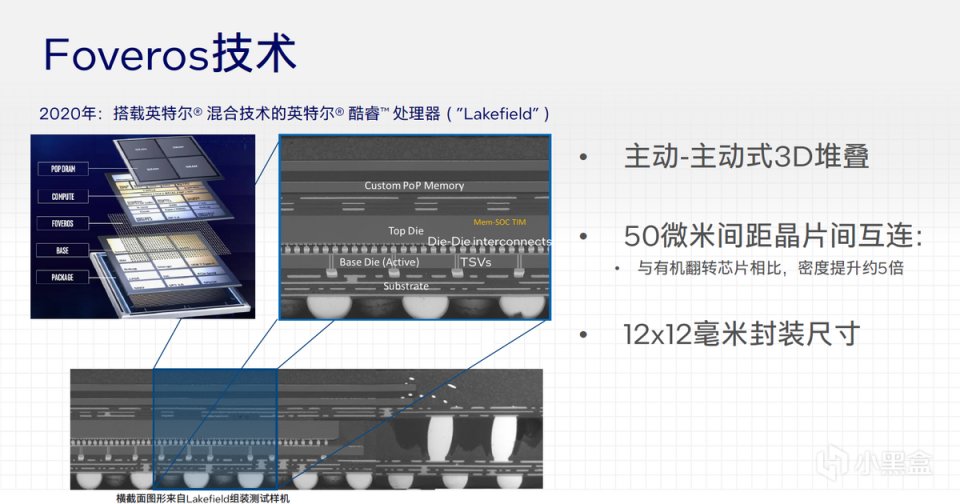
不僅如此,在2020年,英特爾首次在一款獨立筆記本上實現了Foveros 3D封裝技術,最終構建了具有里程碑意義的Lakefield移動處理器。Lakefield不僅實現了1個Ice Lake與4個Atom的混合架構,並且吧內存和處理器封裝在了一起,混合架構的概念則自然延續至今,12代酷睿的P-Core與E-Core混合架構便是如此。
在2022年,英特爾首次推出了2.5D與3D封裝技術混合的GPU產品,幫助GPU實現高密度複雜計算的應用場景。

EMIB的2.5D封裝技術其實很好理解,即兩個Die之間需要通過一個基板進行互聯,也就是通過第二層基板實現不同Die之間的連接。不同於常見的PCB電路板,負責基板的連接密度可以實現55微米的間距。

Foveros 3D封裝則是更進一步,它繞過了基板連接的環節,而是通過Die與Die之間的疊加和高密度連接,功率損失更小,連接性更好,第一代Foveros觸點間距爲50微米,而第二代Foveros則可以做到36微米觸點間距,連接密度增加一倍。
值得一提,第三代Foveros也早已提上議程,被稱爲第三代Foveros Omni。Foveros Omni使得原本第一代Foveros的頂部芯片尺寸限制被取消,可以允許每層多個尺寸芯片疊加。因爲Foveros Omni允許銅柱通過基板一直延伸到供電部分,因此解決了大功率硅通孔(TSV)在信號中造成局部干擾的窘境。此時Foveros Omni觸點間距降低到25微米。
模塊化與2.5D或者3D封裝相結合是非常有好處的,它可以讓每一個標準晶圓只專注CPU模塊中的一個Tile。英特爾推算在標準晶圓上,100平方毫米麪積的芯片可以壓縮到50平方毫米麪積,每個晶圓可以獲得10%以上的芯片數量。


讓我們回到Meteor Lake封裝流程,主要過程包括製造晶圓,分割晶片,測試,晶圓組裝,封裝組裝,最終測試幾個步驟。
如前面所言,Meteor Lake是由4個Tile組成。分別是計算Tile、SOC Tile、GPU Tile以及I/O Tile。這4個Tile來自於不同的工廠,在拿到之後先進行Die與Die以及Base Tile的封裝測試。測試通過之後進行二次分割,再進入傳統處理器封裝流程,最後進行系統級別測試。
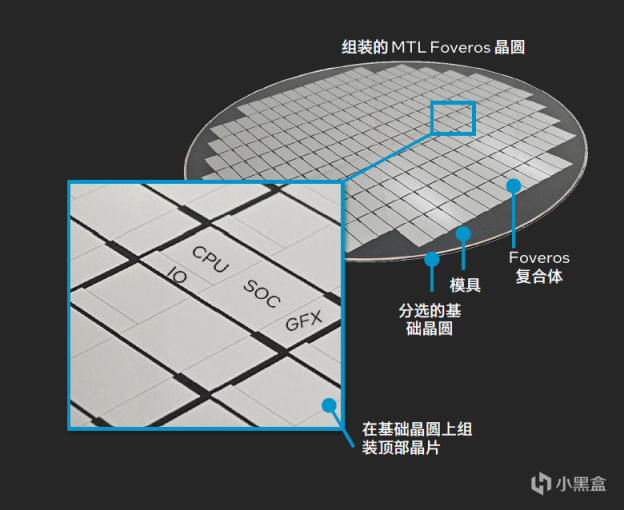
3D封裝對最終測試要求很高,因此封裝工廠也需要加大投資以配合Meteor Lake生產。英特爾也特意在原來的基礎上,新增了新墨西哥以及檳城兩個地方的封裝工廠,確保封裝量產規模化運作。
Meteor Lake AI:人工智能普適的第一步
最後一個話題是圍繞Meteor Lake NPU打造的人工智能生態。Meteor Lake將會從硬件和軟件層面獲得完整的生態加持。事實上,我們所熟悉的AI不再限制於雲端計算,而是開始向終端轉移。
原因在於雲端部署一旦擴大,對於資金成本的壓力會進一步增加,雲端服務商很難從單一的AIGC服務中平衡成本。不僅如此,雲端AIGC需要全程聯網,對隱私的保護並不可靠。

更重要的是,從終端層面看硬件其實已經具備了一定的加速能力,Meteor Lake在做的是將其功耗進一步降低,並讓更多人從AI應用加速中獲得更好的體驗。這個部署實際上從數年前英特爾與合作伙伴的合作中開始,視頻增強、美化、背景模糊、超分辨率計算均是AI終端加速的實際案例。隨着生成式AI應用的火熱,AI的應用場景變得更爲豐富,文生圖、圖生圖,文字生成視頻都將成爲可能,這也給Meteor Lake的NPU提供了用武之地。
在英特爾計劃中,NPU引入僅僅是一方面,更重要的是軟件生態、工具、合作伙伴的全面發展。在英特爾XPU戰略中,GPU、NPU、CPU實際上都可以承載對應的AI算力,不同核心之間可以相互協同。例如CPU負責輕量級AI場景,GPU負責高性能、高吞吐場景,NPU則是在低功耗的狀態下,實現高效的AI終端化應用。

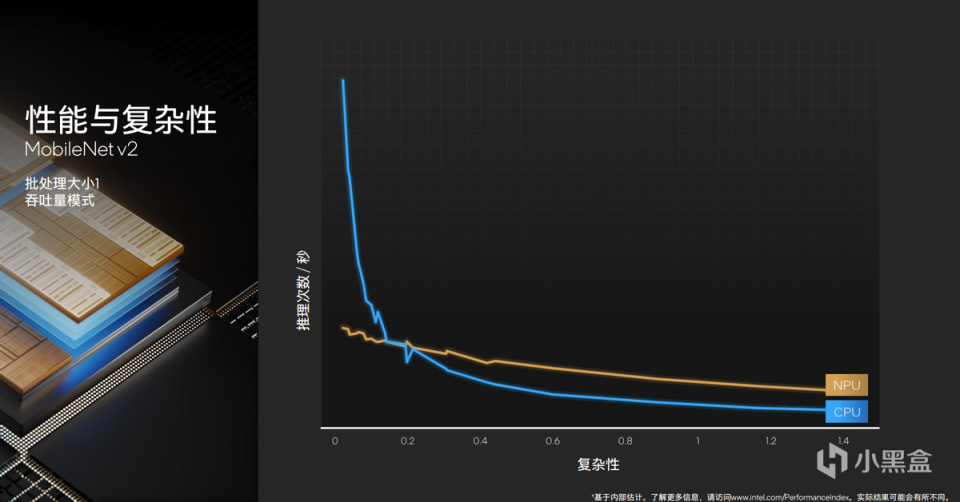
以MobileNet v2爲例,在複雜度較低的應用場景中,可以看到CPU更爲高效。而隨着複雜度增高,NPU則更爲擅長。
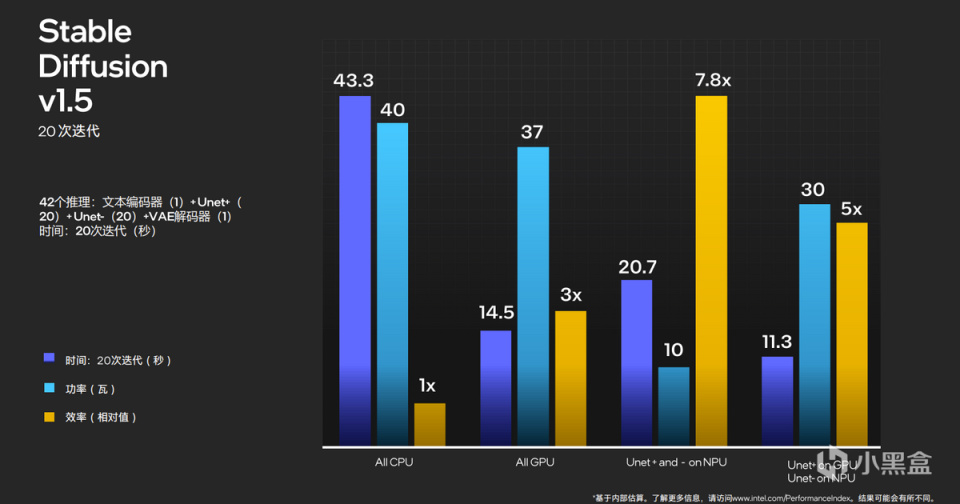
另外一個例子則是時下火熱的Stable Diffusion。Stable Diffusion網絡結構中主要氛圍文本編碼器,Unet+、Unet-構成的圖像生成,VEE圖像解碼器,最終纔是輸出。


如果讓Unet進行20次迭代,整個過程中只依靠CPU,功耗將達到40W,耗時43.3秒。如果將工作全部交給GPU,效率將提升3倍。但其實在英特爾XPU生態中,CPU、GPU和NPU可以同時調用,如果讓NPU和GPU承擔一部分的Unet工作,不僅效率提升明顯,並且功耗還可以進一步降低。
目前,英特爾已經開始與軟件開發商接觸,進一步推動終端AI的生態應用,以豐富PC用戶在AI加速上的體驗。不僅如此,英特爾也持續與微軟合作,在Office套件、Windows Studio Effects和DirectML中展開合作,經一部發揮XPU的優勢。

不同應用可以根據不同的需求對疫情進行調用,比如Teams通過OpenVINO引擎實現人物背景虛化等功能,最終會通過Windows Studio Effects調用NPU。Adobe Photoshop則是GPU的忠實用戶,在AI加速時會調用DirectML進行加速。
有意思的是,OpenVINO還可以根據XPU的情況及逆行動態調整,會主動分配CPU、GPU和NPU資源,實現動態優化加速。

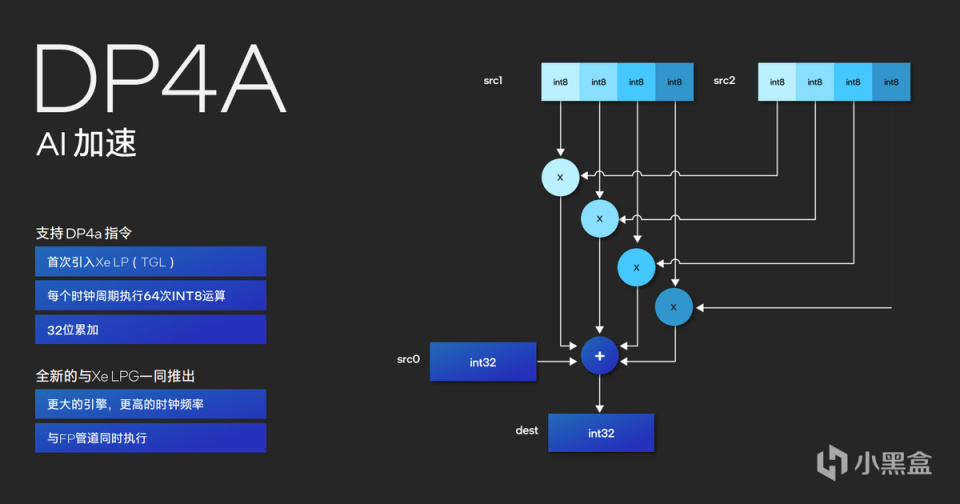
值得注意的是,Meteor Lake的GPU由於獲得獨顯的IP,在執行AI的過程中實際使用的DP4a指令集,一個週期可以提供64int的整形計算累加,並且頻率很高,配合矢量引擎和EU單元,就能獲得很好的AI加速效果。
重點在於NPU實際上是由2個神經網絡處理引擎組成,用於相乘後累加,即我們常說的MAC。這個過程在NPU中是由硬件實現的,並備激活函數的硬件單元。

NPU的兩個單元支持INT8整數運算或者FP16浮點運算,提供MMU,專門的內存接口,可以直讀內存的DMA,以及自用的RAM。如果運算中還涉及INT4或者FP32計算,則可以通過兩個獨立的DSP提供支持。

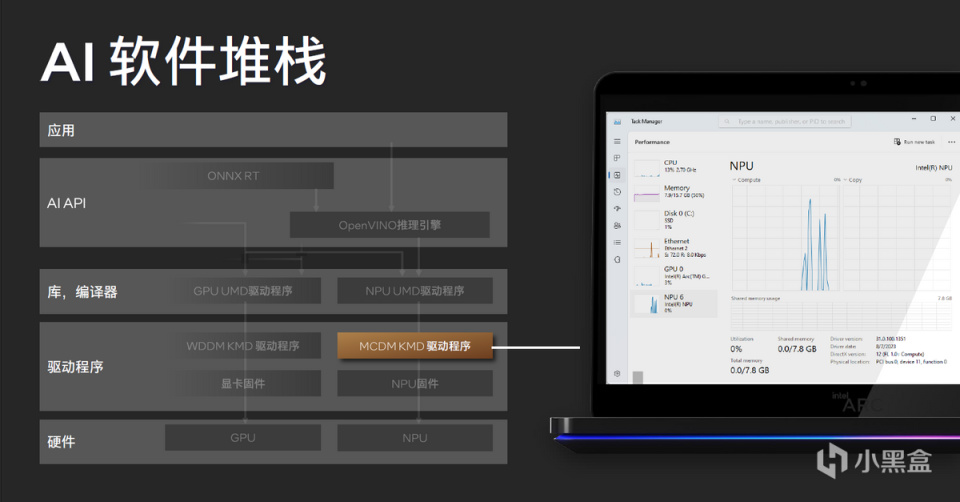
在軟件層面NPU符合微軟MCDM驅動框架,因此在Windows任務管理器中可以看到NPU的存在,屬於計算設備中的一種,可以隨時查看NPU的負載情況。

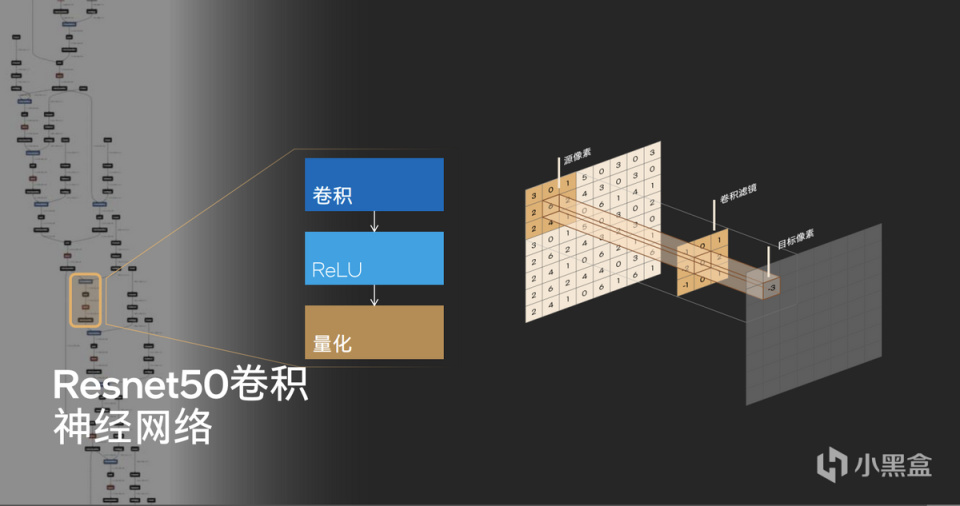
AI加速神經網絡中的ReLU非線性激活函數也是由硬件實現的量化轉換的,原本大模型訓練中使用的FP32浮點計算實際上對精度並不敏感,實際推理中會通過ReLU轉換成INT8,以實現高效和節約空間的目的。
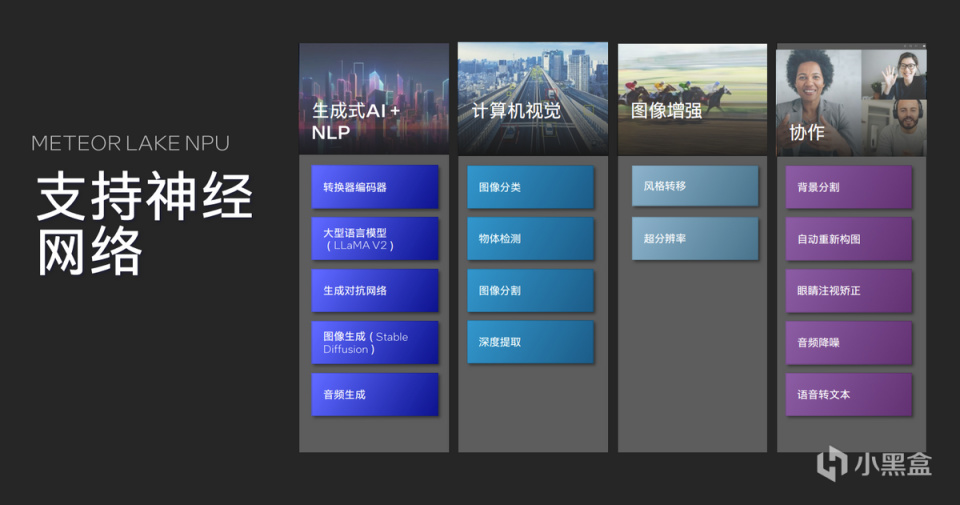
目前爲止NPU已經獲得了完整的軟件接口、編程接口支持無論是AIGC、計算機視覺加速、圖像增強還是Teams等協作軟件中的背景虛化工作,都是NPU擅長的範圍。同時英特爾藉助Meteor Lake進一步推進XPU概念,讓產品可以更好的支撐起整個AI生態系統,NPU在正式發佈之前,已經成功邁出了第一步。
酷睿Ultra預示的新可能
相比起臺式機處理器,酷睿Ultra的Meteor Lake架構被賦予了更多的可能性。按照英特爾的說法,EUV與Intel 4搭配實現了更好的效能以及更高的良品率,Foveros 3D封裝和模塊化設計讓產品成本變得更爲可控,NPU補充加速的AI生態,則進一步幫助英特爾向XPU策略邁出更爲重要的一步。正因爲如此,英特爾也在輕薄筆記本端嘗試放棄酷睿i系列的命名規則,轉向酷睿Ultra的命名方式,顯然桌面端的命名規則轉換,也不過是時間的問題罷了。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















