我們在很多場合中不止一次提到過Intel Arc銳炫顯卡是一款會成長的GPU,在推出僅一年多的時間內,Intel Arc就歷經了數次重大升級,包括對DX11、DX9主流遊戲的不斷優化,新遊戲發售當天即刻適配等。在Intel Arc發售以來,已經有超過30次的驅動更新,已經頗有當年A/N卡驅動大戰,驅動大戰的味道。

而就在最近,在英特爾大灣區科技創新中心的英特爾技術分享會上,Intel Arc再次放出接大招,包括DX9、DX11和DX12遊戲性能再次提升,並推出了全新的GPU Busy性能指標參考,Apple ProRes到AV1的高效轉碼,以及包括包括ChatGLM-6b、Llama 2-13b在內的AI生成式內容創作。


海量的功能和技術更新讓筆者忍不住看了一下現在Intel Arc A380僅有三位數的實際售價,嘖嘖,真的是Arc用戶血賺的節奏。
GPU Busy:提升響應新法寶
如何降低遊戲中可能遇到的各種延遲響應是每一家GPU廠商在提升技術和驅動時需要先考慮的問題。比如NVIDIA Reflex會考慮I/O輸入到顯示器輸出過程中的整體系統響應表現,其中有一種情況是,如果遇到CPU性能太強勁,比如Core i9,那麼就會通過CPU Boost來降低CPU速度來確保GPU跟上節奏。

讓CPU受限或者性能過剩,顯然都是不對的。過往的大部分遊戲情況中,如果在Core i5上就能運行很好的遊戲,在Core i7和Core i9中很可能提升不明顯,原因是CPU與GPU之間沒有一個均衡的解決方案,而隨着英特爾優化驅動的引入,這個問題得到了很好的解決,特別是引入的GPU Busy性能指標檢測,就能很好的觀測到這一點。
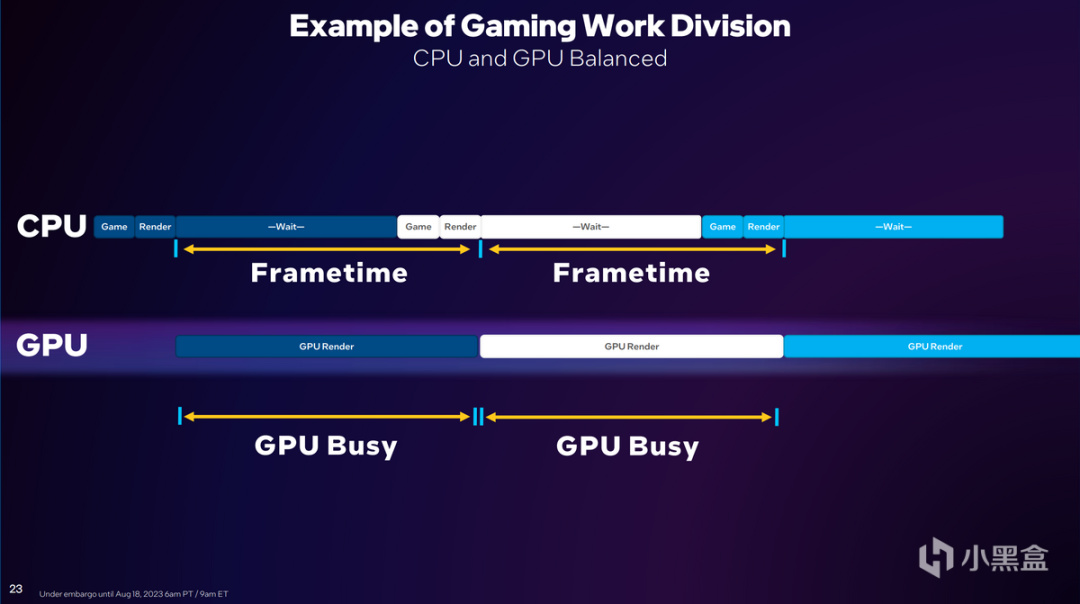
解鈴還須繫鈴人,CPU和GPU之間搭配的問題,實際上還是需要CPU與GPU之間溝通優化來解決。也就是降低CPU在每幀上花費的時間,並且縮短與GPU的溝通延遲,因此就引出了CPU中的Frametime概念。

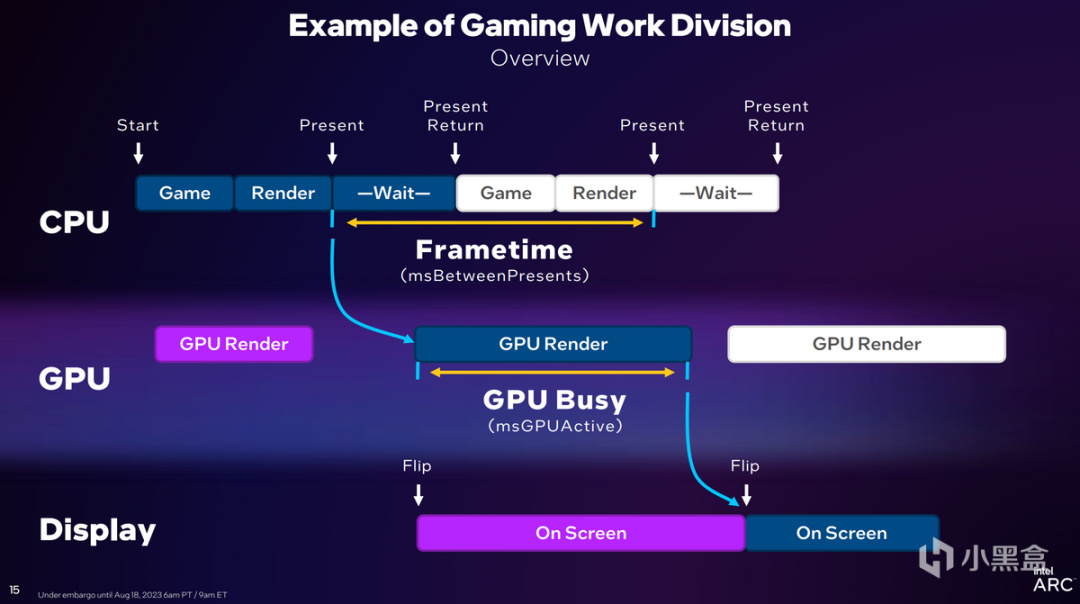
不同於GPU在顯示過程中的大規模並行處理,遊戲單幀畫面在CPU中需要歷經遊戲邏輯處理、物理計算、調用I/O、命中檢測等等,而後纔是調用渲染器將當下的遊戲狀態傳遞給GPU進行下一步操作。
但在動輒5GHz的時代,當下想讓GPU趕上CPU的頻率是不可能的,在執行的過程中,CPU會執行一段Wait的命令,等待GPU回饋之後再進行下一個流程。顧名思義,Wait就是CPU在等待GPU做出反應,而這個過程也包含在Frametime的過程中,導致Frametime的實際時間被延長。
當CPU的Frametime大於GPU渲染時間,英特爾就會將其稱爲GPU Busy。是的,這個時候GPU真的很忙。
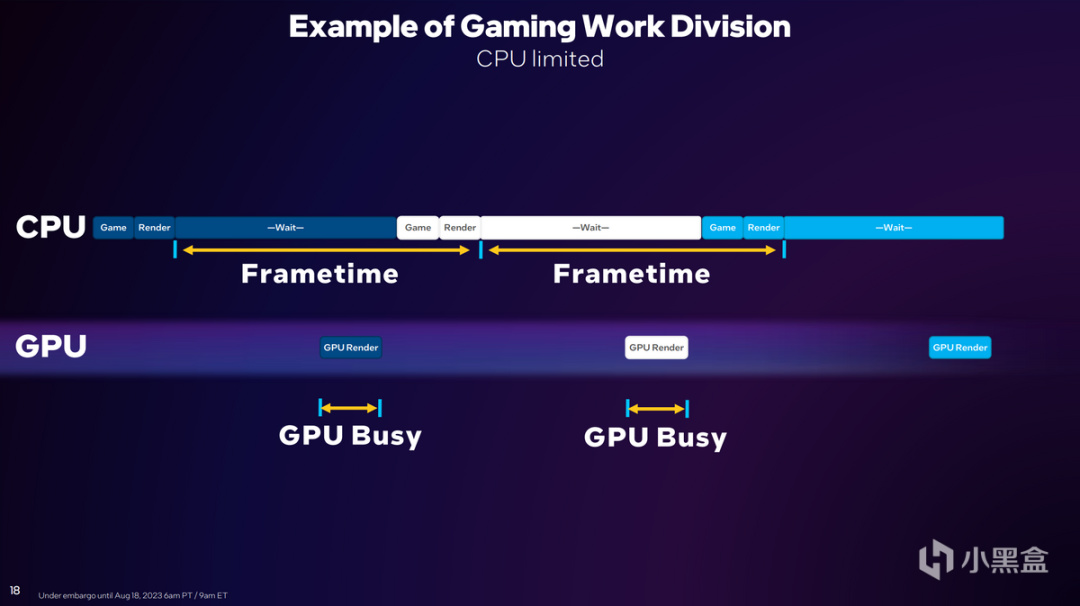
而原則上,Frametime時間與GPU渲染時間同步,才能保持效率最大化,不會有單方面的處理單元瞎忙活,費力不討好。因此Intel在最新一版的驅動中降低了CPU Frametime,特別是其中Wait的過程,並且消除一些無意義的行爲,讓每一次執行變得更爲高效。
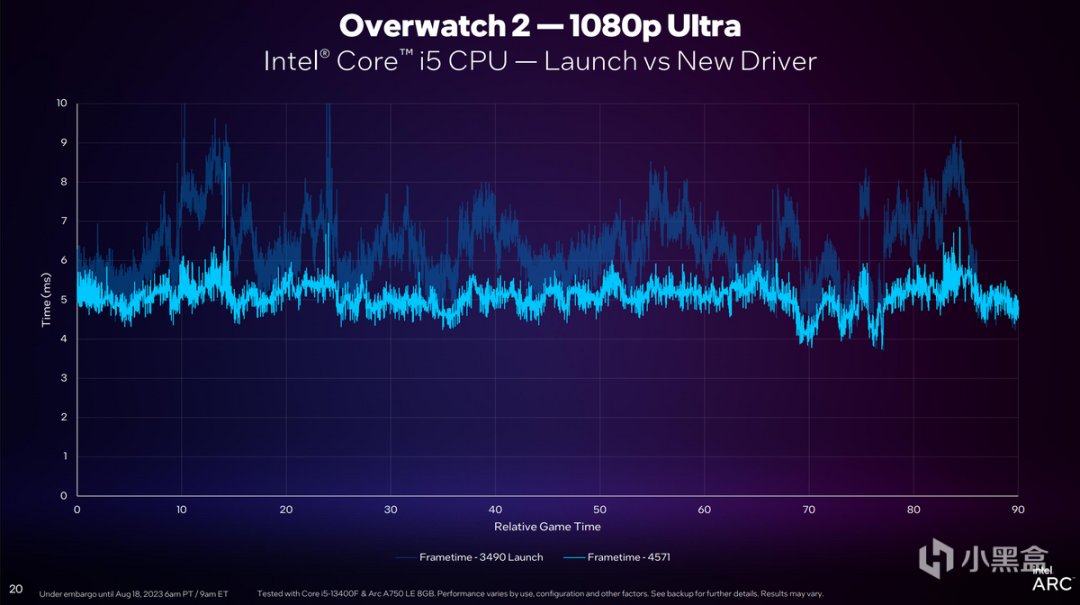
通過對比可以看到,Frametime在《守望先鋒2》1080p Ultra畫質下成功降低了CPU Frametime與GPU渲染之間不同步的問題,並將Frametime響應時間從原本的6-10ms,降低至5ms左右,可以說進步是相當巨大的。
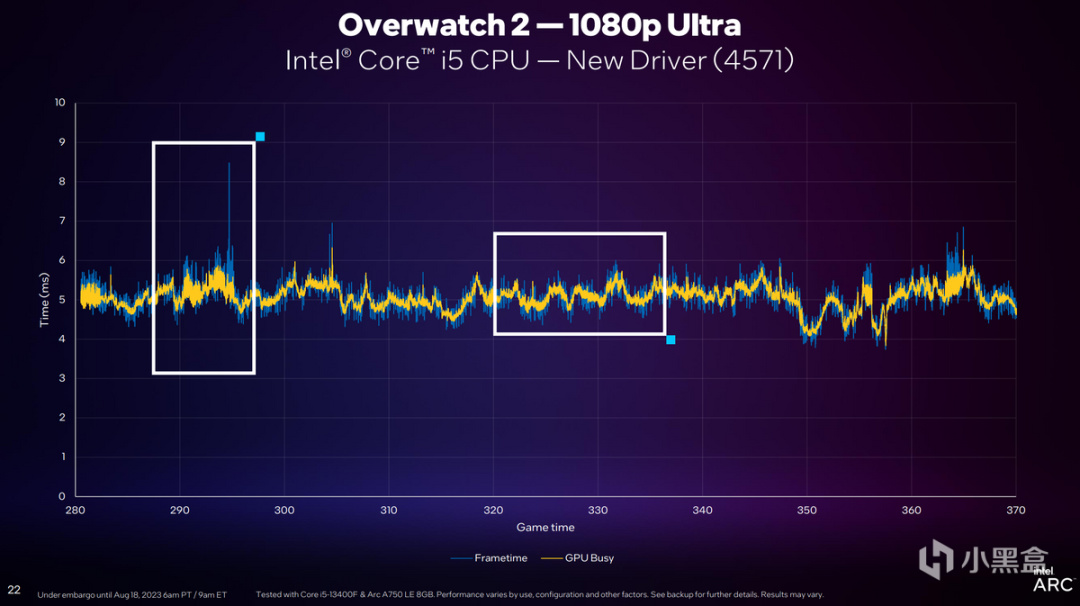
同時這意味着如果與高性能CPU搭配,CPU與GPU之間達到平衡,也可以給GPU帶來更多提升的機會。
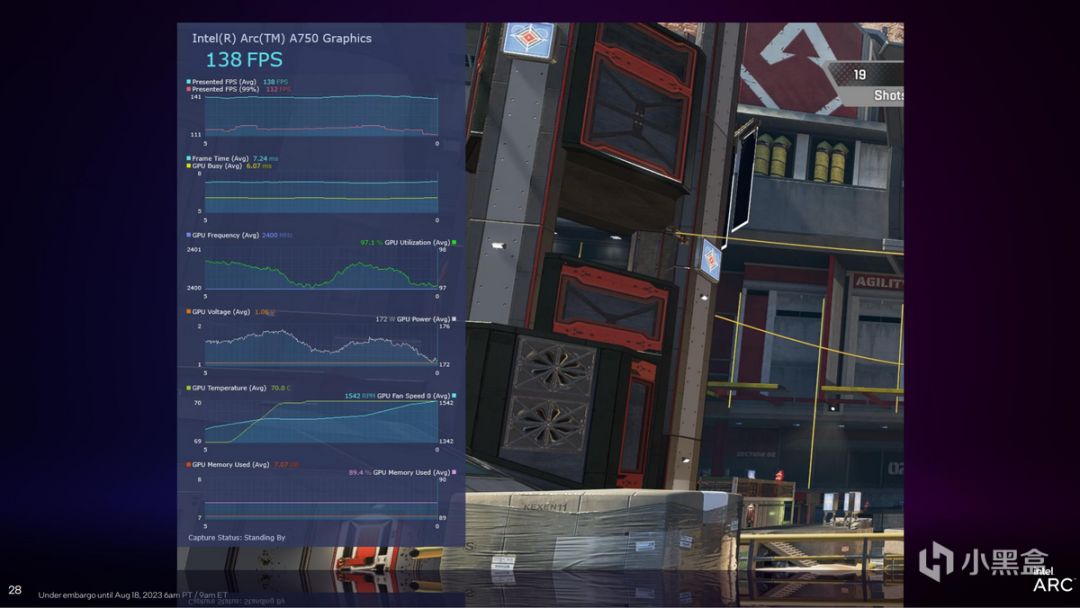
重點是GPU Busy是個通用性的概念,它不侷限於英特爾的CPU和GPU中,而是可以檢測到不同品牌CPU、GPU之間的配合,比如Intel CPU+NVIDIA GPU,Intel CPU+AMD GPU,AMD CPU+Intel GPU等等。在最新一版本的PresentMon Beta監測工具工具中,英特爾已經將GPU Busy作爲一個獨立的檢測項,在遊戲的過程中提供CPU與GPU之間匹配度的參考。
DirectX 11體驗再提升
讓我們把目光放回Intel Arc。我們知道Intel Arc在設計之初是針對DirectX 12進行硬件設計的,但顯卡適配本質上是個經驗與體力活,特別對於Intel Arc沒有出生之前的遊戲適配,實際上會存在很多困難。就好比一個英語專業的大學生,畢業之後爲了獲得更好的工作機會,必須重新去學習文言文。

從實際情況來看Intel Arc在推出的一年多的時間內,表現得很好。英特爾首先對DirectX 9驅動進行了重構,放棄了之前轉換層兼容的低效模式,從而獲得43%以上的平均性能提升。
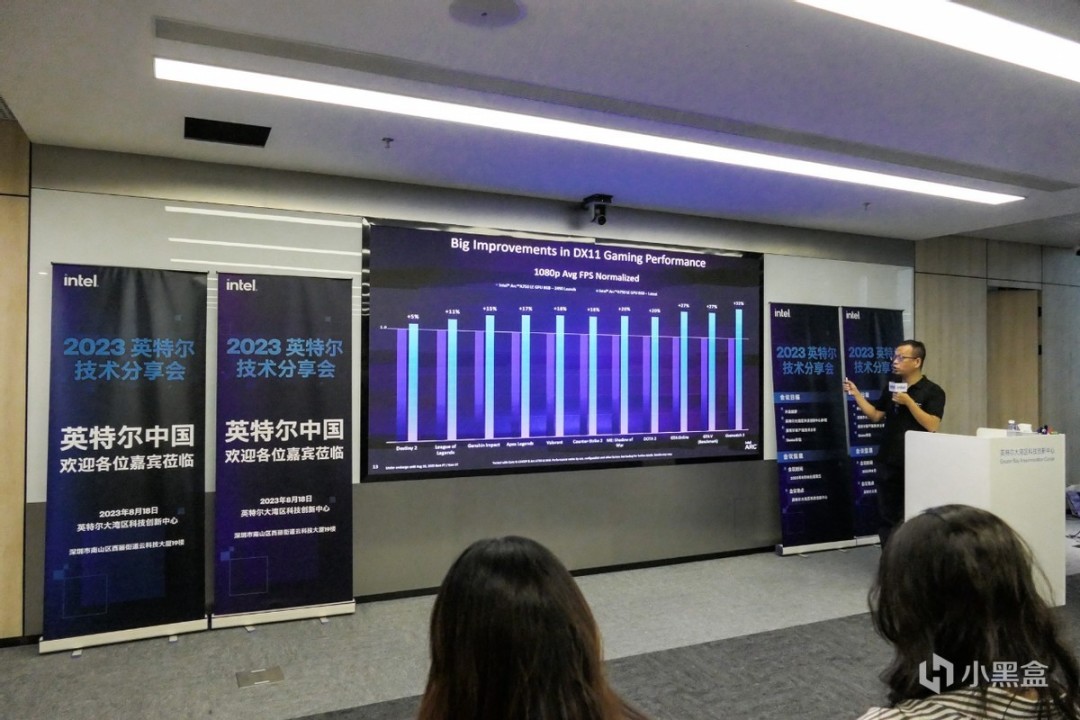
但只有DirectX 9是不夠的,因爲DirectX 11也佔據了主流遊戲的半壁江山,比如時下火熱的《永劫無間》,不要看宣傳說即將支持DirectX 12,支持光追等大量新技術,實際上它現在仍然是基於DirectX 11的遊戲。同等性能GPU下,你振刀的效率低於對手,那作爲玩家的你肯定是無法忍受的。
現在Intel Arc針對DirectX 11再讀給出更新,這也是在第一季度驅動更新之後,Arc針對DirectX 11的再次加強,從Intel官方數據來看,所測試的11款遊戲幀率平均提升幅度將近20%。
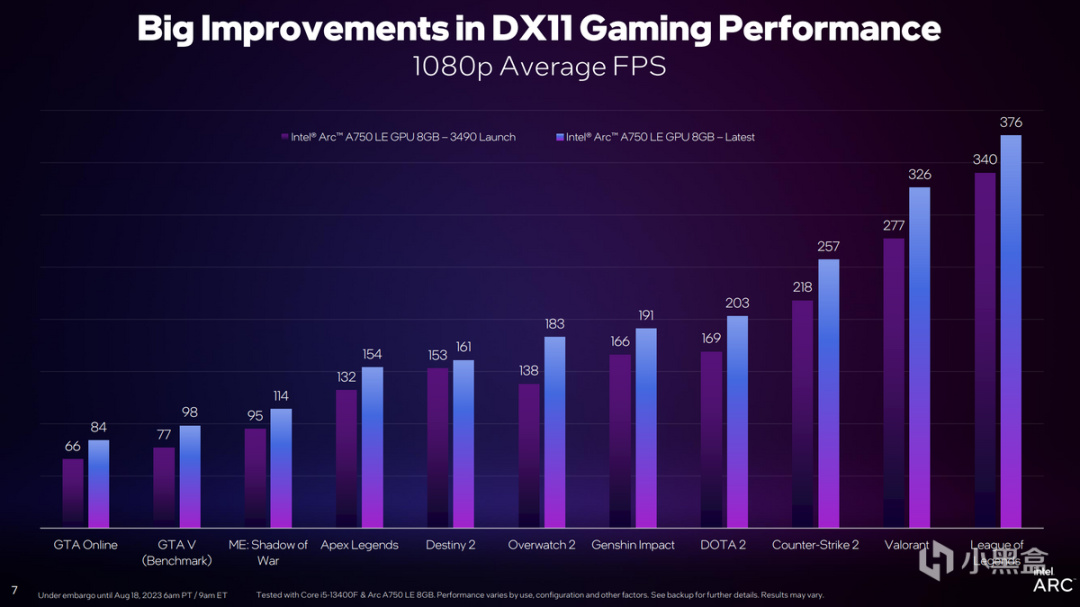
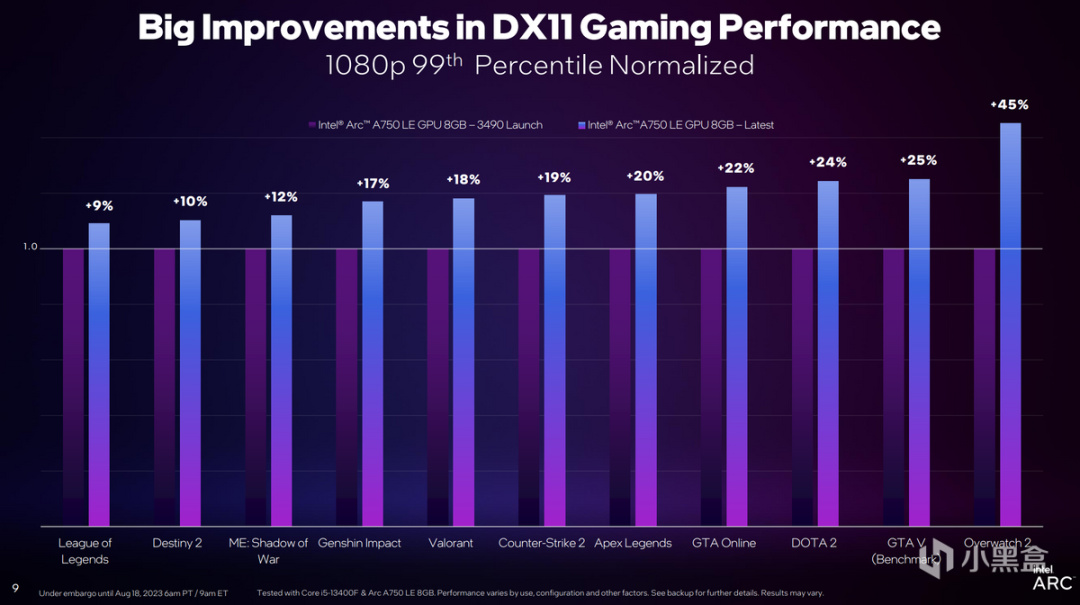
而我們常說的1% Low幀,或是99th Percentile情況也更爲明顯,提升幅度也有20%,最高提升可達45%。而所有的測試都是在Intel Core i5-13400F搭配Intel Arc A750完成,可見Arc驅動的成熟度仍在在不斷提升,現在已經有了很好的執行效率,並且未來的表現可能還會更好。
生成式AI:用輕薄本也能跑
一旦提到大語言模型,我們第一個反應是Grace Hopper集齊一套,上千萬美元投資使勁砸,跟我們普通消費者沒什麼直接關係。相比之下,英特爾的想法其實會更激進一些,就是在離線狀態下,也能讓普通消費者體驗到本地生成式AI帶來的優勢和高效。換而言之,英特爾已經着手將AIGC應用到了我們現在常見的輕薄型筆記本上。

在現場,英特爾給我們展示了兩個DEMO。一個是當下喜聞樂見的Stable Diffusion,另一個則是基於ChatGLM-6b、Llama 2-13b的計算。對於開源的AIGC,英特爾的態度顯得非常積極,同樣也得益於OpenVINO優秀的兼容性以及對開發者的友好。

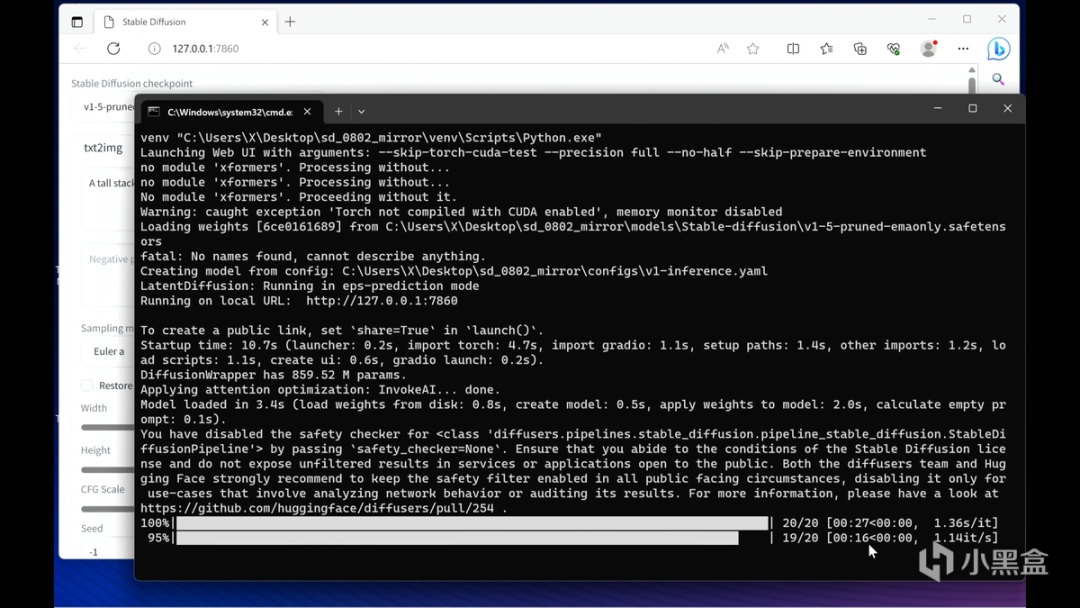
其中Stable Diffusion使用了社區中火熱的Automatic1111模型,將一段推理關鍵詞交個Core i7-13700H的輕薄本來執行。英特爾還特別強調了,利用OpenVINO加速的Stable Diffusion在配置過程中,只添加了一行代碼,就能實現PyTorch模型的加速。

整個過程只依靠Core i7-13700H的核顯來完成,一張512x512分辨率的圖片實現時間爲17秒左右,與獨顯比起來算不上快,但是對於移動過程中臨時生成一張圖片而言,已經完全足夠。
如果是使用獨顯的Arc A770作爲比較,同等條件下生成所需時間則只需要2秒,生成速率大概在9.65it/s左右,也就是每秒迭代9.65次,是個不錯的成績。
另外一個演示則是基於ChatGLM-6b、Llama 2-13b的表現。同樣是Core i7-13700H搭配Xe核顯。其中ChatGLM-6b可以做到首個token生成first latency 241.7ms,後續token平均生成率after latency 55.63ms/token。同時Llama 2-13b則執行了更爲複雜的中文與英文生成,在幾乎不影響閱讀速度的情況下,筆記本也能夠做到快速的生成效果。
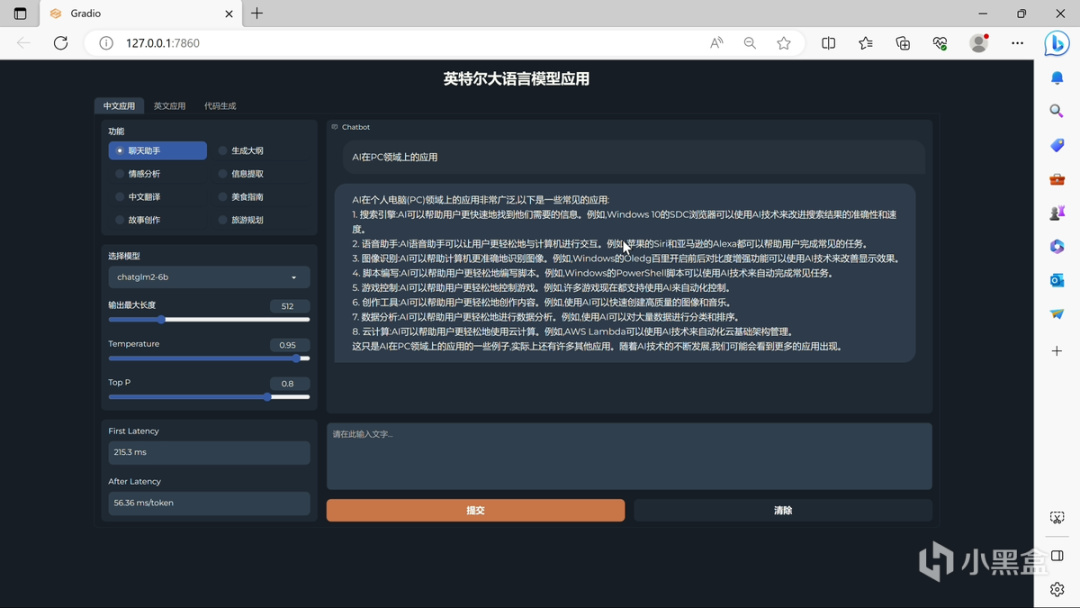
順帶一提,ChatGLM-6b、Llama 2-13b中的b是billion的意思,即ChatGLM的60億參數版本,和Llama 2的130億參數版本,前者由清華大學知識工程和數據挖掘小組開發,後者由Facebook,也就是現在的Meta開發,均爲開源。
而根據現場演示,英特爾輕薄本最高可以做到StarCoder-15.5b規模的大語言模型LLM推理演示,將近160億個參數是目前13代酷睿輕薄本執行的天花板,已經非常驚人。這也讓我們看到輕薄本實際上已經具備了一定的AIGC實際應用體驗,在未來不同場景、客戶端中,通過AIGC替代繁瑣的人工,實現更高效的內容創作已經近在咫尺。
寫在最後:Intel Arc進階時
在遊戲和AIGC之外,Intel還在現場利用Arc A770進行了通過單一攝像頭實現人物動作的3D數字重建,通過抓去27個骨骼點實現快速的虛擬人物生成、渲染,並且流暢度達到70FPS。

同時利用Arc A380在極短的時間內完成Apple ProRes到AV1的高效轉碼,效率甚至高過NVIDIA GeForce RTX 4090,確是讓人倍感意外。
不僅如此,英特爾還在積極設計單槽GPU,計劃在未來一段時間中,讓Intel Arc向邊緣計算進一步擴展。

由此可見,Intel Arc仍然處在一個進階狀態,英特爾進軍GPU市場不一定要與A家和N家正面硬剛,通過挖掘Xe架構的優勢,挖掘新的GPU應用與生態,給消費市場提供更豐富且高性價比的選擇,讓人更喜聞樂見。從GPU Busy提出,到DX9、DX11驅動的全面優化,以及對開源大語言模型的積極應對,對AIGC普適化給出解決方案,都已經很好證明了Intel Arc深耕GPU的決心。


更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















