此處鳴謝:
B站ID:秋葉akki,賽博佛祖,免費提供SD整合包,部分教程,降低AI繪畫門檻。
B站ID:Nenly同學,匆匆and甜甜等賽博菩薩,免費提供完整,準確,精美的教程,本期導論基於其教程加上本人淺顯的經驗總結。
除此之外,鳴謝每一位開源者,不斷迭代AI繪畫進步的程序人,以及爲降低AI繪畫入門門檻而言傳身教者。
1.歷史概述(不想看可略過到2)
AI繪畫的概念,想必各位這幾年已經聽得爛透,我便不再重述,最近AI繪畫在經歷了control net以及各個版本插件迭代後,基本進入了一個穩定的版本,工作流程也基本確定。
一個合格的流水線,首先要確定的就是一套完整的流程,只有在流程確定之後,才能讓工人們各司其職,輸出令人滿意的產品。
AI繪畫,從2022年之初以來就以“不確定”聞名,說難聽點叫抽大獎,因爲其圖生文模型CheckPoint以及配套VAE的不確定性只能依靠文字來限定,即使能夠以圖生圖的方式進行二次迭代,但也是以抽獎的方式,通過大模型不斷抽獎,屬實是算不上什麼“高效”的生產機器,此時的AI繪畫被稱爲
大模型時代。
龐大的模型讓各個使用者非常頭疼,相比起現在4-8G的中規模大模型,以前的模型動不動就十幾個G,包含了大量的圖片解算數據,這就帶來了第一個問題,大模型的數據大差不差,如果只是換一個畫風,就必須要加一大種訓練數據,那到最後模型只會龐大得令人髮指。
大模型帶來的第二個問題就是訓練者的限制,越大的模型訓練需要的顯存和顯卡要求就越高,以目前AI的進步,4090被爆顯存也是輕輕鬆鬆,4090在steam硬件統計中持有率也僅爲0.4%,如此下去很快就面臨只能通過大型礦站才能訓練模型的境地——然而這是不可能的,因爲AI繪畫開源意味着幾乎沒有收益。
就在此時,微軟研究員提出了一個新的方案,AI繪畫得以模塊化迅速發展,由此進入了第二個時代
Lora時代。
LORA(Low-Rank Adaptation of Large Language Models,大型語言模型的低秩適應)模型最早並非使用在AI繪畫上,而是使用在諸如GPT-2模型上,從大型模型中得到的回覆並不盡如人意,因此大模型工程師想到利用大模型的增補模型進行模型微調,意外得到了較爲滿意的成果。
作爲增補模型,Lora並不需要大模型那種龐大的體型,它更像是PS裏的濾鏡,負責給大模型出圖的部分進行風格化,特殊化,精確化的工作,因此它只要少部分模型進行訓練,將模型的風格以及特化部分能夠精確限制大模型就可以了,基本上最大的Lora也不會超過200MB。
Lora的主要作用相當於一個書籤,而大模型就是一個字典,它單獨的時候並沒有什麼作用,但當它在字典裏的時候,就能爲你精確的翻閱到字典的對應頁碼。
現在你在任意一個AI繪畫的論壇分享站,看到的絕大部分都是Lora模型。
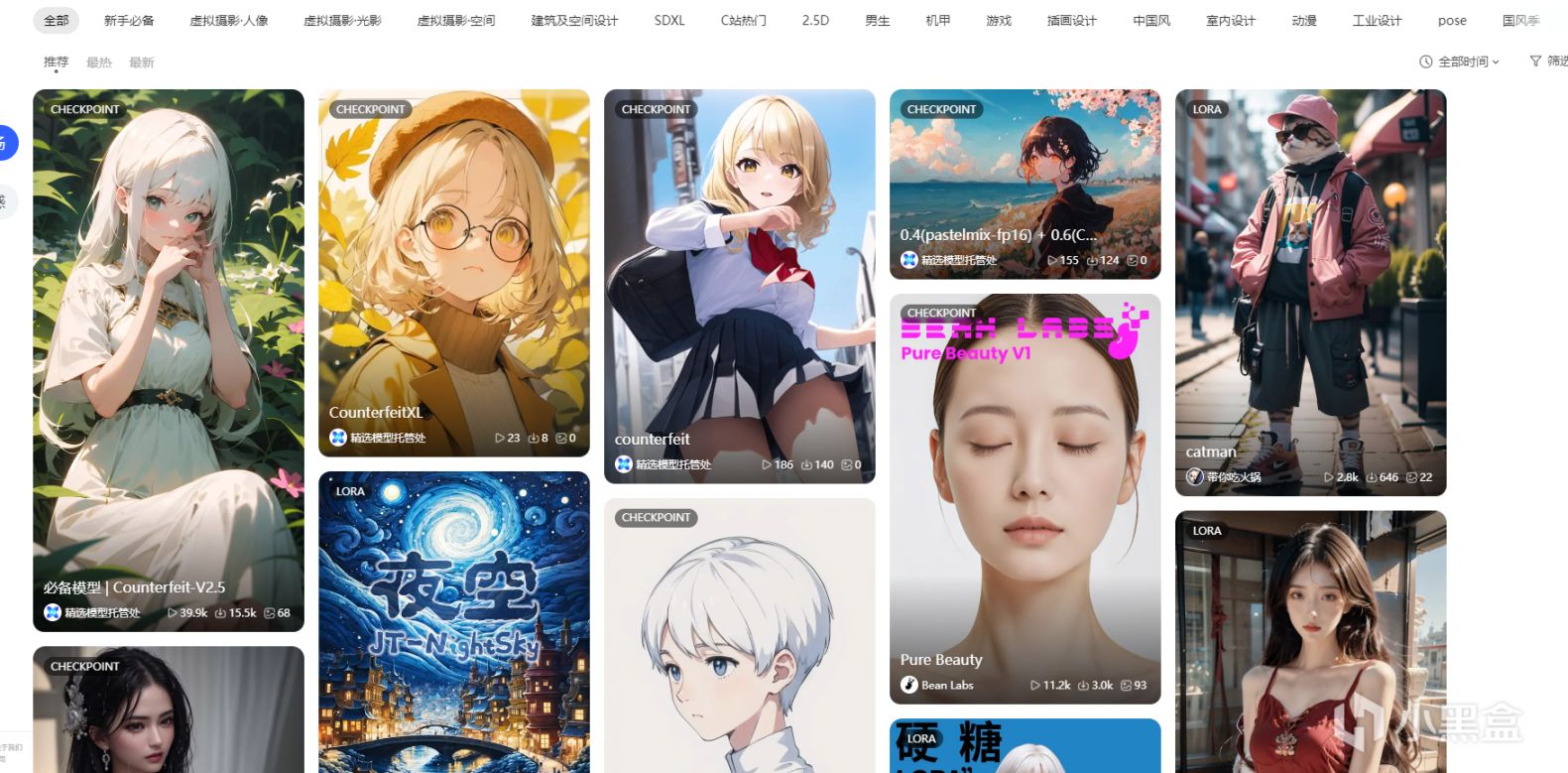
在liblib的主要界面上大多數模型是LORA模型
事實上在經過LORA精確風格以及特化之後,如果沒有特殊要求的話是可以直接超分(超分辨率細化)然後輸出,就是一張較爲完美的圖,但在實際使用中並非如此,總會遇到一些這樣或那樣的問題,例如手有八根手指,人物姿態扭曲成恐怖機器人等等,似乎在如何扭曲人體方面,AI比你想象力強得多。
由此,針對AI繪畫更加確定的插件,ADeailer,ControlNet應運而生,進入了
後Lora時代。
現在我們就處在這個時期,佛祖SD包裏就整合了全套的ControlNet以及超分辨率插件,每一樣插件針對性較強,當然本期並不討論特定的插件,只討論大流程下如何工業化確定性產出較爲確定性的圖紙。
2.AI繪畫
SD(Stable Diffusion)本地或者在線包,儘量不要那種經過大量魔改或者簡化的網站,大量簡化成什麼特定特定風格的網站大多是不具備工業化流程的,他們更多是純純的圖一樂,借用別人的煉丹爐也別借用啥兒童玩具,儘量還是選擇正經點的煉丹爐。
礙於上班摸魚的電腦機能限制,我只能在WWW.LIBLIB.COM的在線SD中藉助服務器進行煉丹,這裏的SD基本沒有魔改,或者說魔改也是往好的方向魔改,並且網頁內的LORA或者ChechPoint等可以直接下載到自己的煉丹爐改裝,因此本期流程我將採用此SD包進行相對的解說。
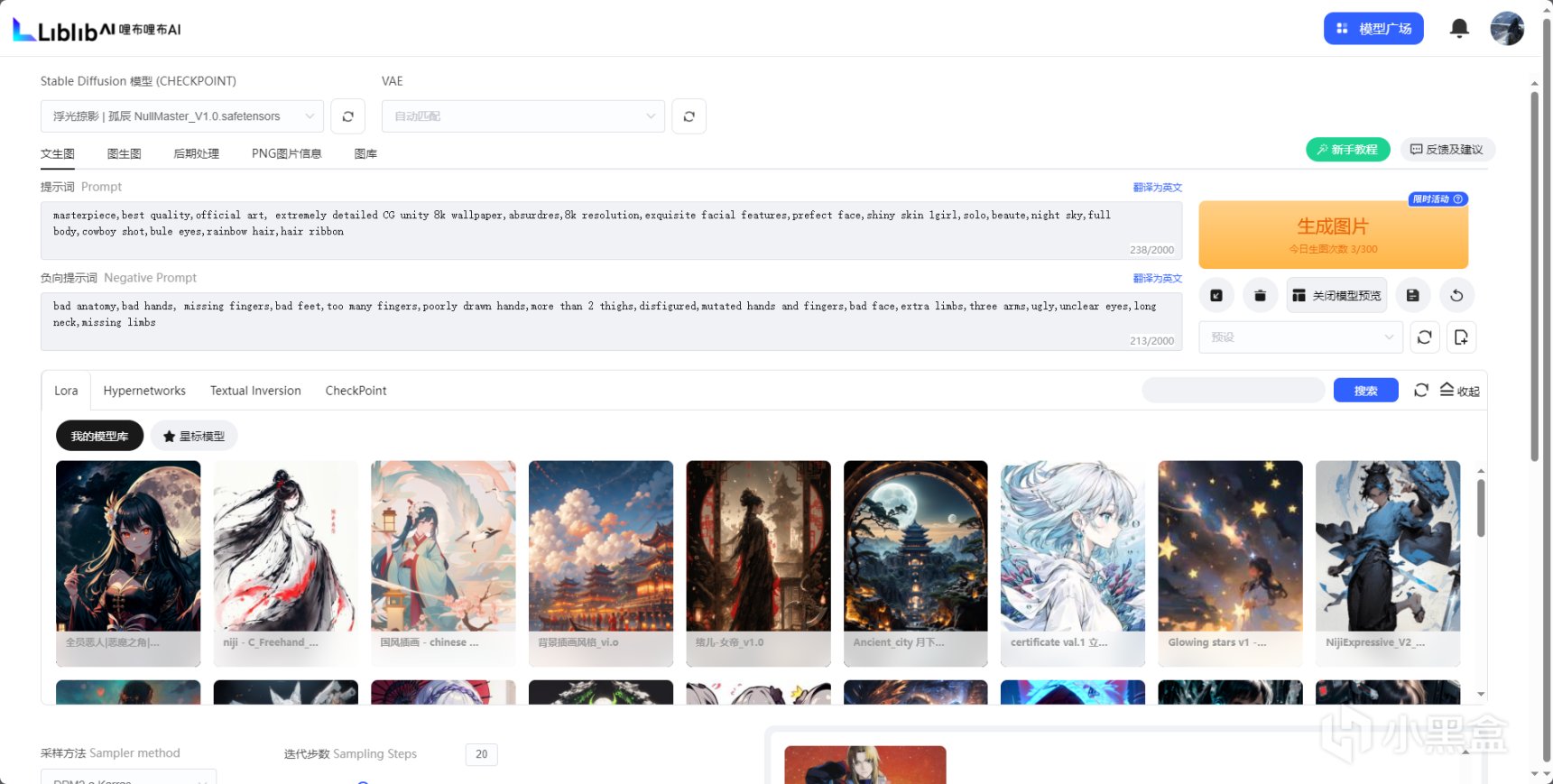
liblib的在線SD頁面,包含ADetailer與ControlNET,以及在線大量的Lora庫
在繪畫之前,要先確定自己想要
繪什麼風格的畫。
首先是大類,確定自己想要畫什麼,是想畫二次元紙片人還是想畫3D類人,又或者是工業化設計例如室內設計,UI設計等。確認之後,就可以選擇自己的大模型進行測試。
例如我想要生成一個3D的美女照片,那麼我就可以先尋找並選擇3D的大模型,可以搜索ChechPoint檢索優秀的大模型。
在此推薦幾個大模型:
墨幽人造人
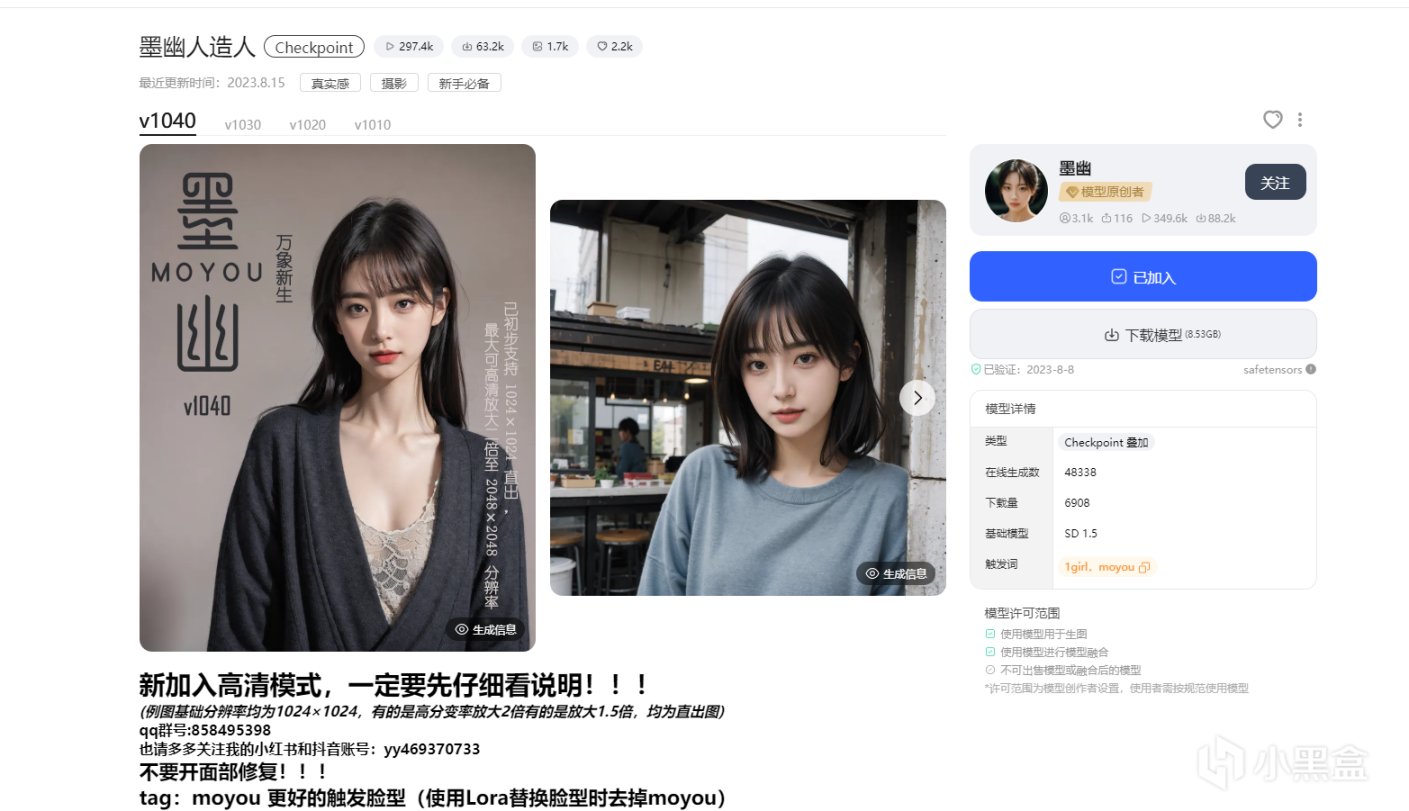
墨幽大佬的人造人,幾乎以假亂真,非常優秀的大模型
majicMIX realistic 麥橘寫實
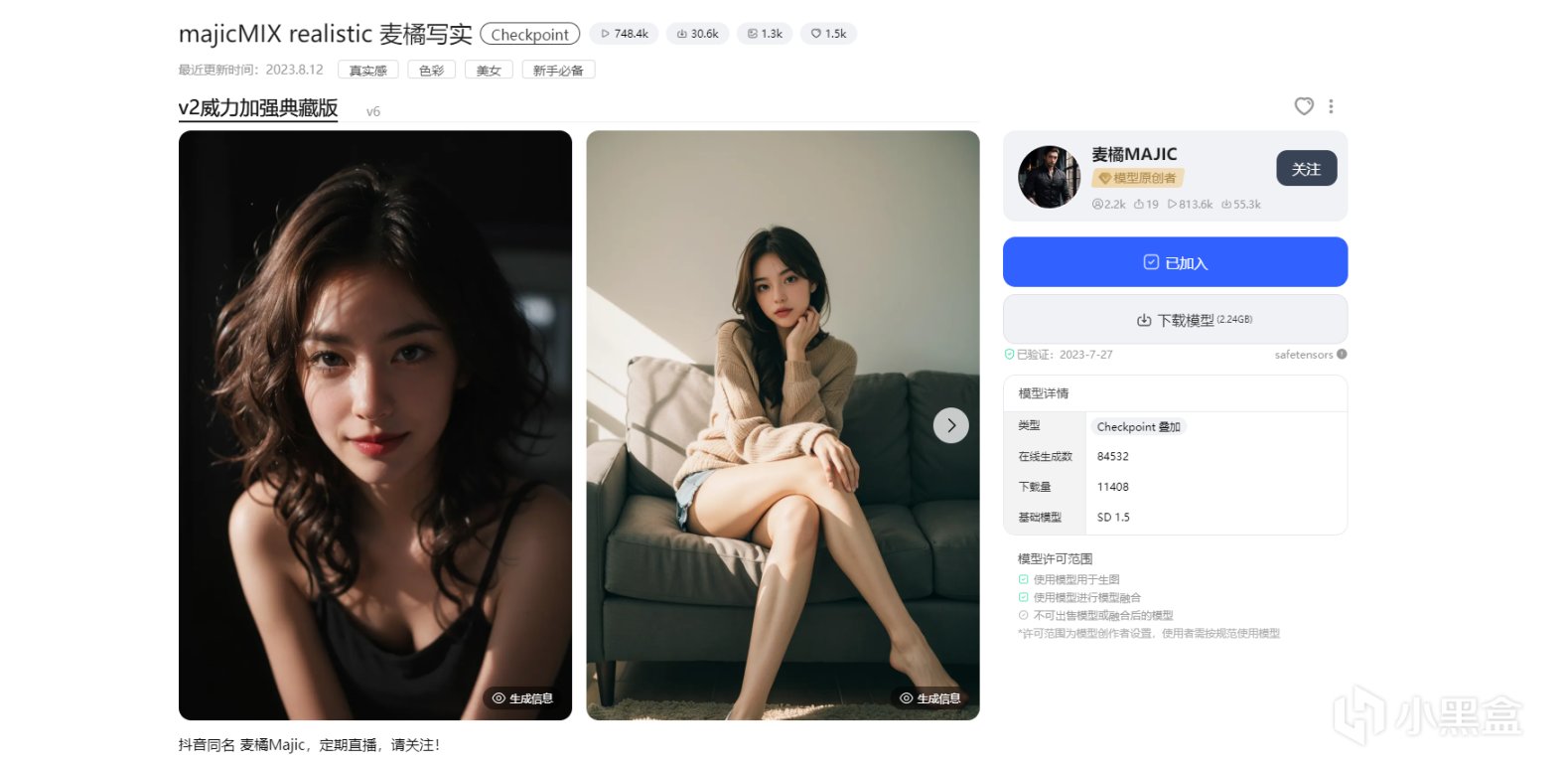
麥橘大佬的底模有不錯的光照效果
無論是使用什麼模型,一定要注意一點,那就是要看別人模型底下的文字描述!
作爲一個初次使用別人模型的使用者,你對模型的瞭解是無法高於作者的,因此模型作者的描述和生成例圖的信息就是你參考的最好例子,可以針對性的先跑幾次熟悉大模型,確定大模型會出什麼樣風格的畫。

墨幽大佬的模型描述
確定所使用的大模型之後,我們就可以繼續推進,開始朝着自己想要畫的方向描述,這一階段就是魔咒,也是大多數人最頭疼的階段。

魔咒,永遠的痛
在此推薦各位使用edge的一個DiffusionDraw插件,雖然這個插件是我剛剛說過魔改過的那種AI繪畫,但是他內置了一個好東西,那就是咒語生成器,而且其默認的負面提示詞也相當適用。

DiffusionDraw,一個繪畫圖一樂的edge插件,但是其咒語生成器非常可靠
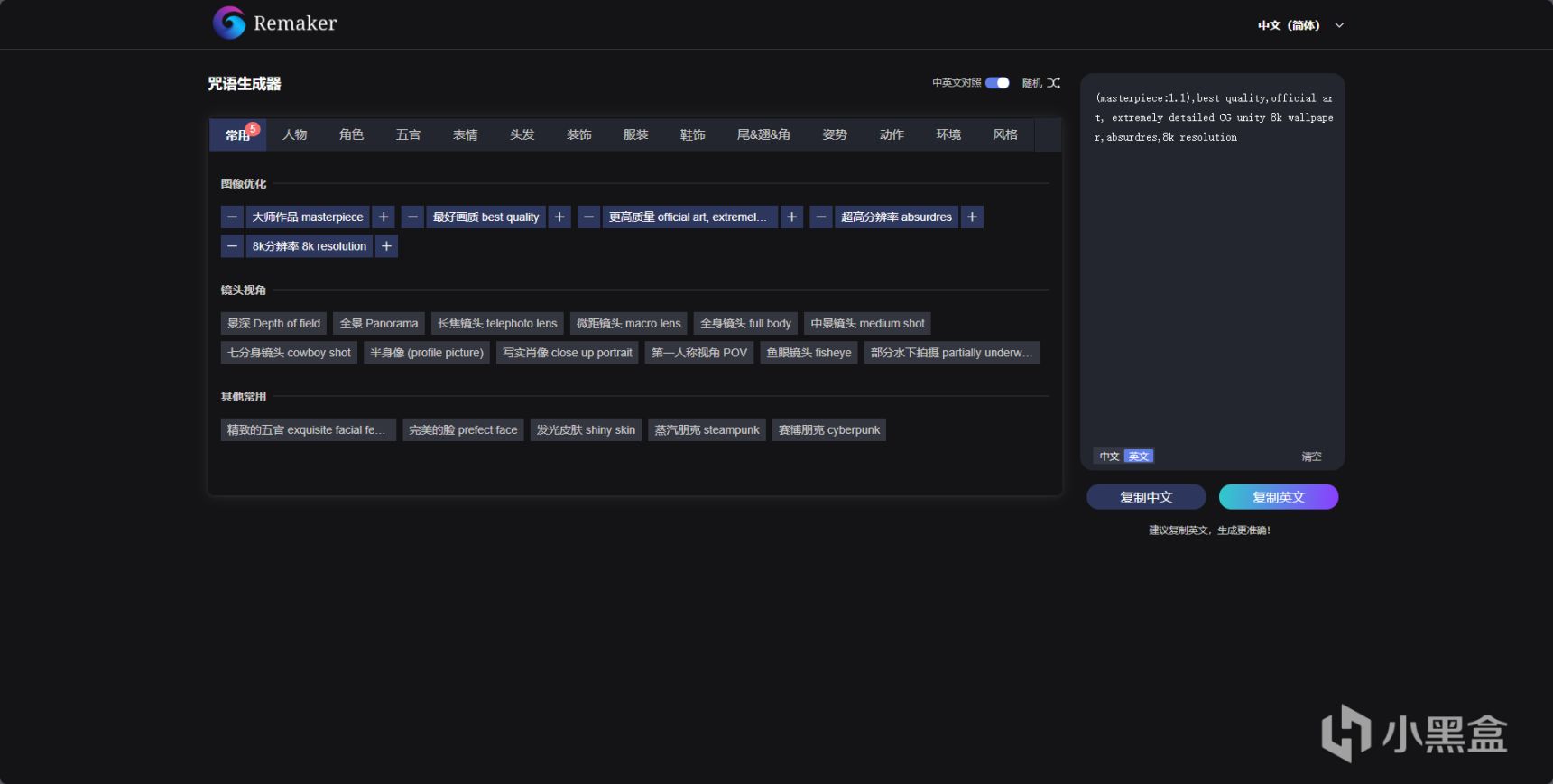
DiffusionDraw的咒語生成器remaker.ai,能夠輔助疊加權重,有大量提示詞輔助你繪畫。
除此之外,其他魔咒網站也相當不錯,例如鱉哲AITag法典等一些用愛發電的網站,魔咒的學問也挺高深,建議各位自己找找視頻,早日成爲卡爾。
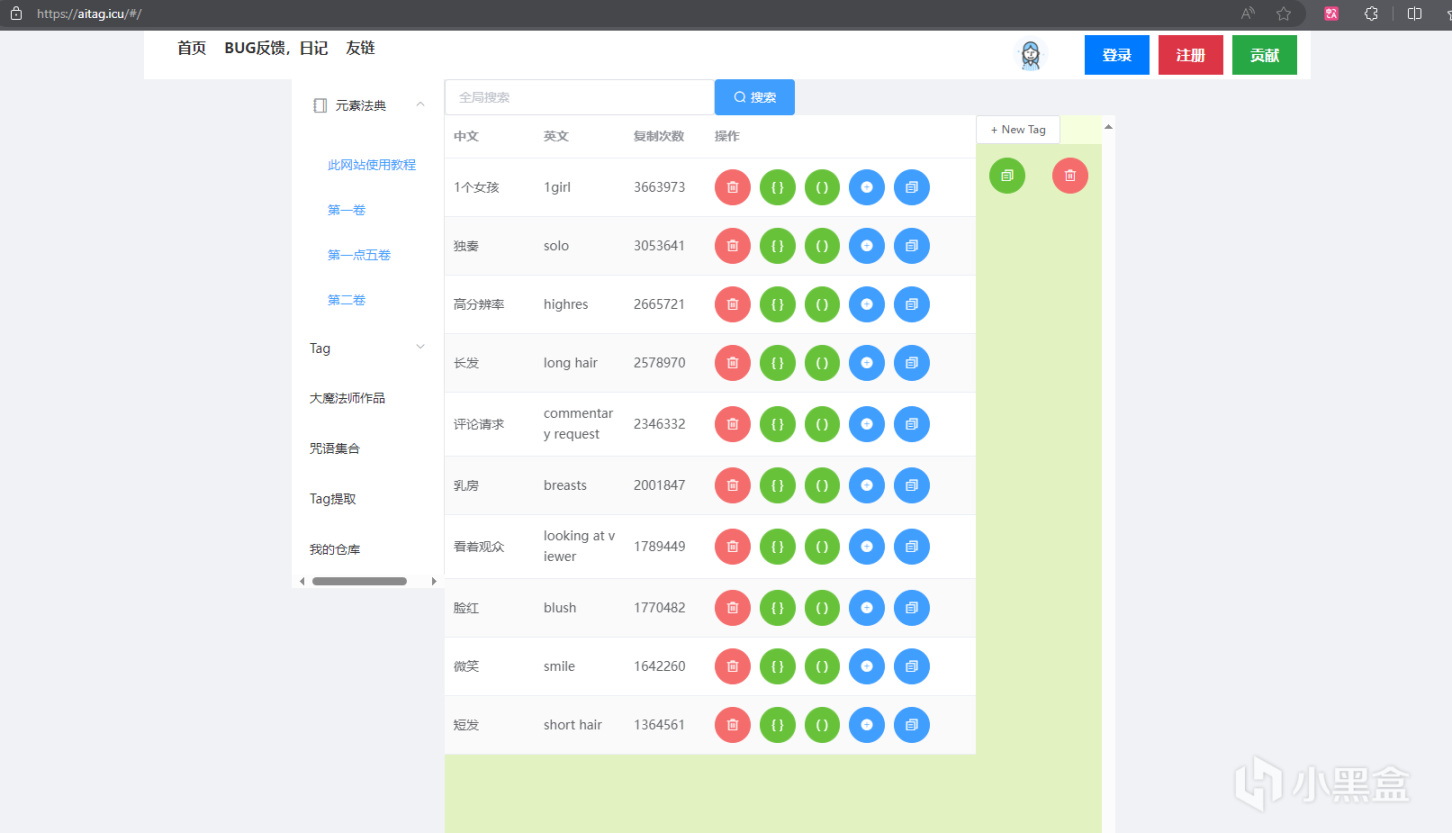
AITag.icu,等等裏面好像混入了一些奇怪的提示詞
確定了模型,魔咒方向之後,我們就可以
選擇Lora,進行風格化了。
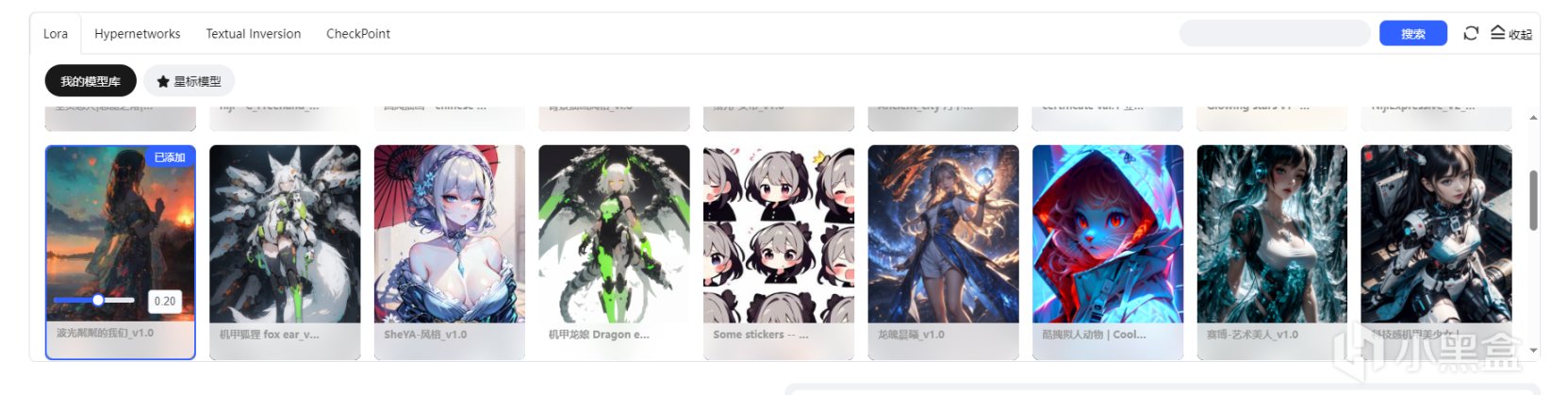
Lora的選擇
在LIBLIB中添加入庫,刷新SD頁面後點擊就可以使用Lora,可以通過拖動或者修改數字的方式來確定Lora的權重,注意,你不能3D的大模型用二次元的Lora,儘量使用統一種類的Lora,除非你想生成虛空和古神那當我沒說。
Lora也要看對應Lora作者的描述,大多數作者會告訴你最佳的或者比較適合的權重大概是多少,當然這只是參考,Lora和大模型不一樣,同一張畫是可以使用多個Lora的,例如我可以給一幅畫加上“夜空梵高風”權重0.2,再加上“波光粼粼”0.3,如此以來就可能能獲得一張背景有梵高的夜空風格,且人物與雲邊波光粼粼(聽起來很違和但是AI會調整得相對不那麼違和)的畫。

隨便跑的,帶0.6放大步驟10,AD修復臉部,大模型爲《唯》系列炫彩動漫,LORA爲上述兩個,迭代步驟40
在調整出圖的時候,一般會採用一種形式,那就是512x512分辨率先進行抽獎,在抽到動作,構圖都比較符合的情況下時,再進行圖生圖操作細化,這也是一種相對穩定的流程,且由於訓練時大多數LORA與大模型就是採用的512分辨率訓練,反而出圖的精度會相對高一些。
不過在網頁上沒法使用超分插件,再加上有出圖限制,我懶人一個,乾脆直接一步到位,確認畫風之後開放大超分來抽獎直接抽1920*1280分辨率的圖。
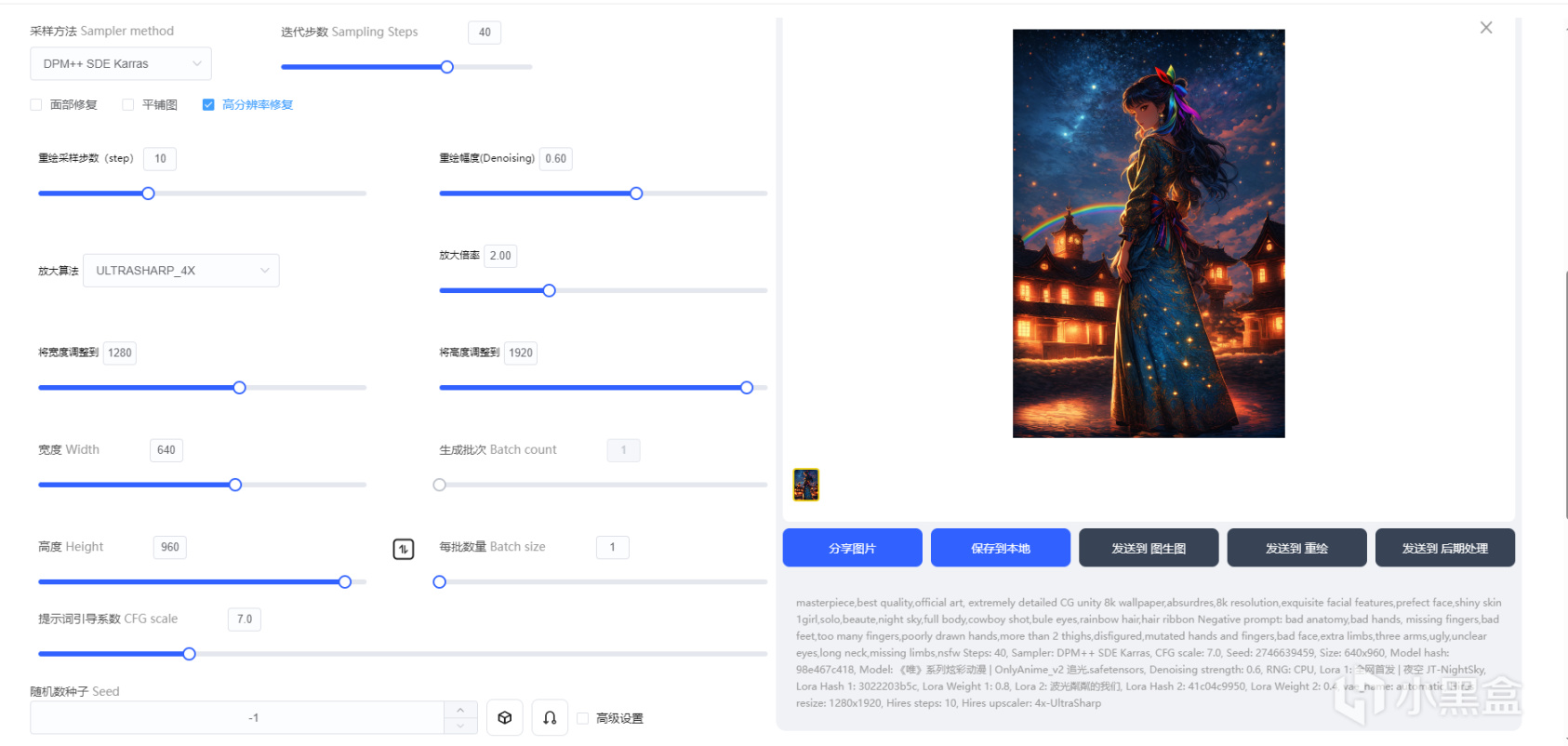
網頁的參數頁,本地SD也有一模一樣的參數頁
參數頁的調整具體要根據你的Lora和大模型上的描述進行,衝突的話優先大模型,在此我僅討論看不懂大模型,Lora的時候,按經驗來說的情況。
採樣方法使用帶Karras屁股的基本沒錯,實際採樣方法對出圖影響不會特別大。
迭代步驟是AI繪畫迭代的次數,在本地中迭代次數越多顯存佔用越大,運算也越慢,因此一般在20-50之間,如果想要細膩的話儘量高於35,但是也不要無腦拉高,否則過擬合一樣不好看。
面部修復,平鋪圖和高分修復代表着出圖時的部分優化或者分辨率擴大,在此着重點一下高分辨率修復,在勾選了高分辨率修復後,會出現“重繪採樣步驟”和“重繪幅度”“放大算法”以及“放大倍率”。高分修復實際上是要針對你迭代出來的圖紙進行重繪以完成擴大的過程,該過程會根據你重繪幅度的大小添加各種細節(也有可能是污染你原本的畫)而放大倍率則是代表你將原本的畫放大拉寬到多少分辨率,在此建議是儘量按整數倍數放大,不然容易出現一部分好,另一部分非常古神的情況。放大算法代表你採用什麼樣的算法來進行放大計算,一般情況下選擇那幾個xxxx_4X的都沒錯,放大運算不會影響很大,當然這個也要注意看模型作者的描述,有一些按對方說的選擇放大算法有奇效。
生成批次與每批數量,這裏可能各位都覺得“不就是出幾張圖嘛”其實不然,如果你是本地SD,選每批數量的話每一批的多張繪畫都會單獨佔用多次顯存,非常容易炸顯存,拉到10張高分圖就算你是24G的4090都得炸,因此建議是調整生成批次,讓每一張生成的圖紙都單獨佔用一次顯存。
隨機數種子在-1時相當於抽獎,如果你有對應的種子(上次的畫)那麼寫入後生成的畫就更傾向於生成原本的那一幅畫,當然實際上也只是限定了範圍的抽獎,再怎麼抽基本也抽不回原本那一幅。
其實到這裏基本上就是普通網頁的簡易煉丹爐所用的路數了,接下來是進行
細化與調整。
ADetailer是一種在繪畫中輔助的插件,它能直接在迭代過程中檢測面部,手部並進行局部重繪,在開啓之後能夠大大避免面部或者手部的崩壞(落淚,有時候單純臉崩或手崩的時候真的心累),其提示詞隨便找幾個負面補上,或者特化面部的提示詞修改例如Bule eyes之類的,它進行面部修改之後再加AI迭代基本會完美契合,而不像後續用塗鴉圖生圖之類會有一些細微的蒙版導致圖需要再進行一次重新迭代。
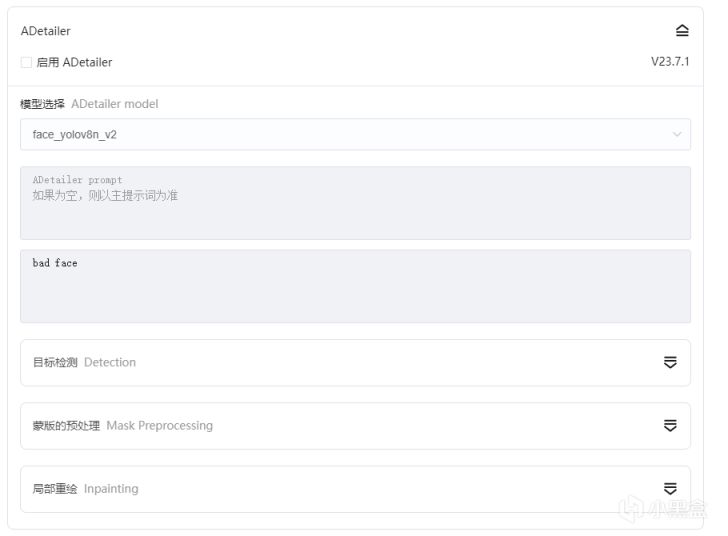
ADetailer以及其參數
ControlNet
強大的工具,其預處理能力賦予了SD精確的控圖能力,讓SD能夠成爲真正的生產工具,本次只會介紹幾個用的多的部分。
ContorlNET之所以強大,是因爲它能夠疊加作用,並且可以導出到PS進行修改,在修改之後再導入進行精確控圖。至於資源佔用的話,實測情況下,我家用的8G 3060TI的悽慘紅顯卡同時跑超分到1920*1080單圖加上三個ContorlNET都是完全沒有問題的,四個偶爾會炸一下顯存。
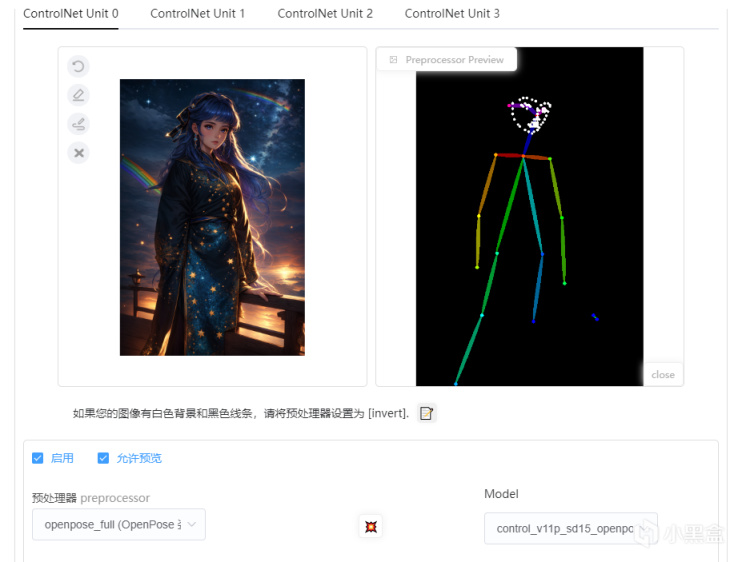
ControlNet工具:ContorlPose
ContorlPose(姿態控制)能夠控制人物的動作姿態,讓人物的表情,動作,能夠確定性的保持,這對於原本AI繪畫左一個上天右一個下地的畫來說相當痛苦,現在只要有一張參考畫,你就能通過參考畫進行骨骼提取,包括面部,至少抽獎也能保證抽到的都是一個動作了。
在選擇預處理器爲ContorlPose(對應功能,例如面部和動作)打開“允許預覽”之後,在Model選擇對應的模型(ContorlPose就爲openpose模型),點擊中間紅色爆炸按鈕,就能夠看到對應人物的動作骨骼,我們也可以單獨保存預覽骨骼,下一次直接導入預覽骨骼到ContorlPose中也可以直接使用。
接下來就是調整權重和步數,以及模型參入權重,控制權重影響骨骼對其畫面的影響程度,如果要想再其基礎上自由發揮一點,可以適當調低,選擇更傾向於自由發揮。
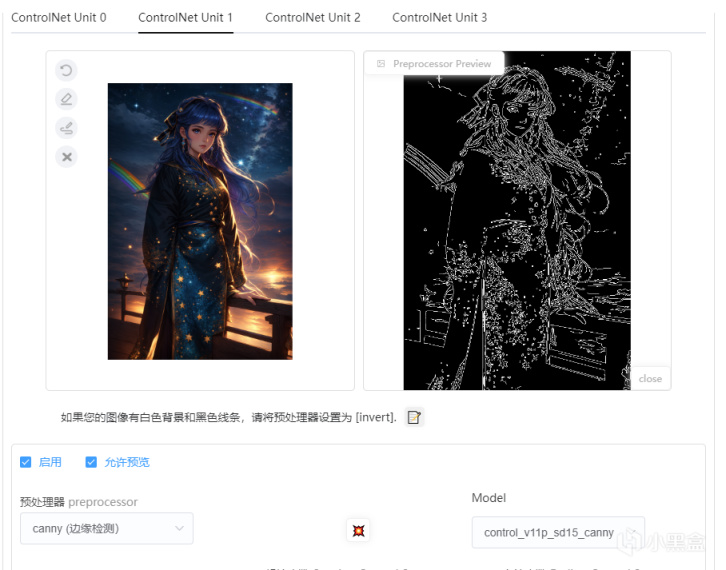
ControlNet工具:Canny
Canny(邊緣描繪)能夠控制AI生成作品的邊緣,在稍作修改的情況下可以生成作品的線稿,如果你對你的畫作不滿意,或者需要進行二次上色,都可以藉助Canny進行二次重繪,這是一個相當有意思的工具。
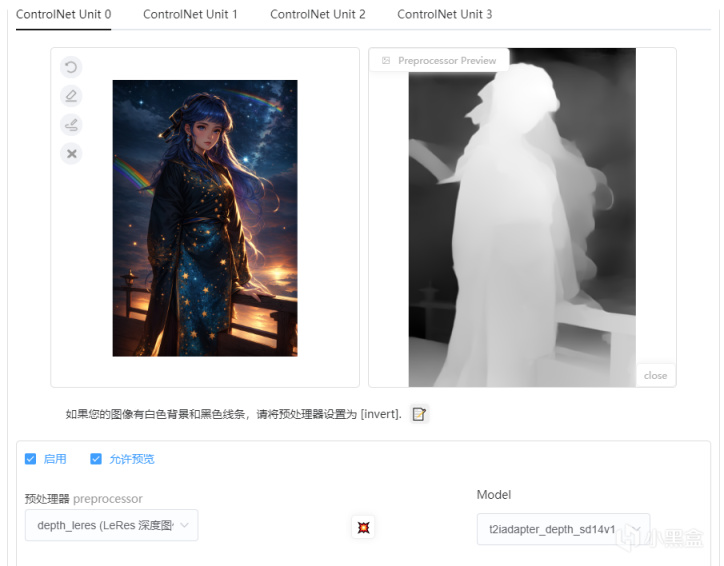
ControlNet工具:depth
總結
AI繪畫,發展一年有餘到現在,已經是相對成熟的流程,我們也能看到各種各樣的AI繪畫,再怎麼去否認,它也已經融入我們的生活成爲我們的一部分,現在很多繪畫者也打不過就加入,將自己的畫訓練爲LORA然後再進行修改或者輔助上色,希望這篇文章能夠給想要入門,卻無處入門的人一點幫助。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













