COMPUTEX 2026一開始黃仁勳就來了個大招。如果說此前DGX Spark面向開發者且不具備筆記本那般的便攜性,那麼今天發佈的NVIDIA RTX Spark補全了所有遺憾。RTX Spark芯片可以理解成專爲 AI 智能體時代設計的SoC,包括Grace CPU和Blackwell RTX GPU,CPU與GPU通過NVLink-C2C互聯成一個整體,並附上最高128GB LPDDR5X統一內存,直接是奔着 AI 智能體去的。
事實上OpenClaw和Hermes Agent在GitHub上以爆炸性速度增長,下載量短期內超過Linux、PyTorch等歷史級項目,在OpenRouter等API平臺上,智能體驅動約80%的Token用量。這導致Qwen、DeepSeek等開放式模型已經開始快速迭代,例如4月發佈的Qwen 27B甚至勝過了2月初的近4000億參數雲端模型,證明前端模型已可在終端本地運行,基於RTX Spark平臺的筆記本和微型臺式機投向市場愈發成熟。
而NVIDIA RTX Spark推向市場不僅意味着,AMD、Intel之外,又多了另一種PC形態的新可能,從1985年首個Windows誕生至今,鍵盤、鼠標定義的用戶體驗也不再是唯一,接下來AI 智能體將有可能徹底改變輸入方式,通過語音、視覺、自然語言交互,完成專業軟件創作、代碼編寫,甚至是主動執行任務。
128GB統一內存的NVIDIA RTX Spark是不是真的這麼厲害?在發佈會之後,筆者有幸參與了會後媒體的相關解答,現在讓我們花點時間,更深入一點了解NVIDIA RTX Spark,以及RTX Spark所帶來的PC新暢想。

打造個人AI的超級芯片
會議上對於PC用戶而言最重要的即是RTX Spark,內部代號N1X。這是NVIDIA專門針對AI、創作和遊戲設計的產品,將PC由工具屬性重新定義成智能搭檔。
事實上N1X並非單一型號,而是一個芯片家族,包含多個定位不同的SKU,作爲代表的旗艦芯片N1X 675追求1 Petaflop AI性能,最高擁有128GB LPDDR5X統一內存,並且具備6144 CUDA核心和第五代Tensor Core的Blackwell RTX GPU,具備48個SM,以及20核的Grace CPU,TDP在45W到80W之間。兩者通過NVLink-C2C互聯,從而在PC終端實現數據中心規格的芯片互聯。

與此同時,Grace CPU由MediaTek合作設計定製,強調能效與互聯能力,包括10個高性能Cortex-X925核心,10個能效Cortex-A725核心,屬於ARMv9架構,基於臺積電3N工藝打造。
從目前整理的信息來看,RTX Spark的Grace CPU性能表現比AMD Ryzen AI 9 HX 395略勝一籌。正因爲如此,首發搭載RTX Spark N1X的筆記本也均爲定義性能型高端輕薄本。
因此計劃首發的RTX Spark的筆記本厚度基本控制在了14mm、輕至1.36kg,並使用14-16英寸Tandem OLED G-SYNC屏幕,首發OEM包括華碩、戴爾、惠普、聯想、微軟Surface、微星,宏碁、技嘉隨後跟進。同時,對應的RTX Spark緊湊型桌面主機也蓄勢待發。
以戴爾計劃推出XPS系列的RTX Spark輕薄筆記本爲例,可以預估首發的RTX Spark筆記本產品應該價格不會便宜。
除了旗艦級RTX Spark之外,NVIDIA還計劃推出18核心,9個性能核與9個效能核的N1X 650,採用5120 CUDA核心,40個SM核心的Blackwell RTX GPU,TDP同樣爲45W到80W,內存最高128GB LPDDR5X。
另外還有兩個非X的N1版本,分別是12核(8+4)CPU,2560 CUDA(20個SM),TDP 45W,最高64GB LPDDR5X的主流版本,以及10核 (7+3)CPU,2048 CUDA(16個SM),TDP 45W,最高64GB LPDDR5X的基礎版本。
遊戲與AI一把抓
頂配RTX Spark筆記本的Blackwell RTX GPU基本相當於GeForce RTX 5070性能,再加上略勝Ryzen AI 9 HX 395一籌的CPU表現,1.3kg左右筆記本表現出類似遊戲本的性能表現是足以讓人期待的。
在使用場景中,NVIDIA展示了AI模型到遊戲的可行性。第一個被提出的應用是本地大模型推理,支持120B參數,以及100萬Token上下文,這是非常誇張的。傳統筆記本獨顯顯存通常爲8GB到16GB,GeForce RTX 5090 筆記本電腦 GPU也僅有24GB,運行70B模型壓力很大。而RTX Spark的128GB統一內存讓120B參數模型在FP4/INT4量化下可直接載入,實際值佔據60GB到70GB內存空間,剩餘50GB用於KV Cache和系統運行。

100萬token上下文意味着可一次性處理整本長篇小說、數十萬行代碼庫、或數百頁法律、醫學文檔的全文分析,無需分段切割。
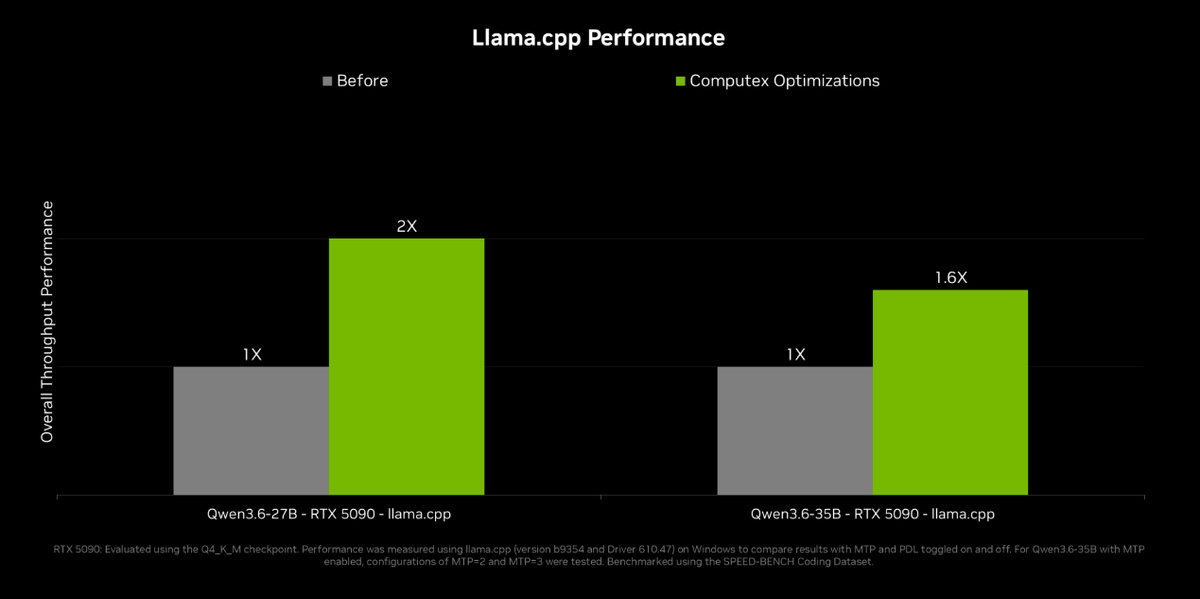
並且Dense Model推理速度提升約1倍,MoE模型提升約1.6倍。由於第五代Tensor Core原生FP4,同等模型體積下內存佔用減半,吞吐量顯著提升。
另外RTX Spark還提供了多GPU擴展的可能性,這是因爲llama.cpp和ComfyUI支持多GPU配置,通過桌面版雙卡串聯,是有機會獲得2倍性能,256GB統一內存。此外,深度研究助手,代碼庫級開發,架構分析、Bug定位、跨文件重構,都可以依賴本地RTX Spark進行。
NVIDIA多次強調RTX Spark將PC從工具升級到了隊友,其中一點就是OpenShell搭配Windows Security Primitives具有了更多實戰意義。目前OpenClaw等智能體無法安全地跑在用戶主力PC上,要麼擔心刪文件、要麼擔心隱私泄露。RTX Spark可以做到權限沙盒化,用戶可精確設定Agent能訪問哪些文件夾、不能碰哪些系統文件。即使Agent被Prompt Injection攻擊,也無法突破預設的權限框架。
當智能體需要調用雲端模型時,OpenShell會自動對請求中的個人信息,比如姓名、地址、公司內部數據,進行脫敏和隱藏。同時敏感計算優先分配給本地模型,只有脫敏後的通用請求才上雲。
由於智能體本身具備跨應用自主執行,這意味着RTX Spark不再侷限於單一App。智能體可同時操作Photoshop生成圖片、Premiere剪輯視頻、瀏覽器搜索素材、本地文件管理器整理工程文件。比如用戶睡覺時,智能體可繼續渲染視頻、批量處理圖片、或監控代碼倉庫提交併自動Review,這也是諸多養蝦人的夢想之一。目前Hermes Agent和OpenClaw已發佈原生Windows應用,集成OpenShell,今天即可下載使用。
在內容創方面,RTX Spark的128GB統一內存允許完整加載90GB以上的場景,通過OptiX和DLSS 4.5 Ray Reconstruction實現交互式近最終質量渲染,意味着整城市模型、電影級角色資產在一款筆記本上即可完成。在今年秋季,Blender 5.3將原生集成DLSS 4.5 Ray Reconstruction作爲降噪器,Viewport實時反饋,專業軟件進駐意味着RTX Spark從誕生之初就開始走向專業化。
視頻製作上,Blackwell GPU原生支持HEVC 4:2:2編解碼,配合128GB內存,可直接在時間線上處理多條12K素材而不需要代理文件。同時ComfyUI用戶可在便攜設備上運行復雜的多模態工作流,生成超高分辨率AI視頻。RTX Spark的處理能力與大容量統一內存相結合,使其成爲運行擴散模型性能最出色的筆記本電腦之一。
目前Adobe也已經加入到Spark平臺中,Premiere和Photoshop爲RTX Spark從底層重構,利用統一內存+TensorRT實現AI功能2倍加速,包括Firefly生成式填充和擴展,讓現在Premiere和Photoshop 10%不到的AI應用,擴展到100%。
同時RTX Video Frame Generation也已經蓄勢待發,通過2x到4x幀生成,讓生成的4K視頻更流暢、時長更長,這項技術同樣也預計秋季推出。
關於遊戲。由於RTX Spark圖形性能約等於GeForce RTX 5070 Laptop級別,支持DLSS 4.5,包含動態多幀生成Dynamic Multi Frame Generation、6x幀生成、第二代 Transformer 超分辨率,NVIDIA Reflex降低40%延遲,以及完整的光線追蹤技術,意味着RTX Spark本身就是一款優秀的遊戲主機,再加上微軟大力推動Windows on Arm平臺,未來PC遊戲環境註定會有ARM參與。
回到RTX Spark本身,這套硬件性能可在1440p分辨率下以100+ FPS繼續3A遊戲。同時Mod作者在使用NVIDIA Remix時候,可使用更高分辨率紋理、更多生成式AI資產,不再受到24GB顯存的限制。同時NVIDIA ACE已經支持本地運行多語言AI NPC模型,128GB內存支持更復雜的角色行爲樹和對話上下文。
喜聞樂見的遊戲同時錄製、Broadcast AI實時摳像,本地AI生成封面/剪輯等直播與內容創作並行操作,在RTX Spark上也不是問題。
最後,RTX Spark也擅長本地代碼智能體部署,例如DeepSeek-Coder、Qwen-Coder,結合百萬Token上下文,可理解整個大型代碼庫。同時智能體可接入GitHub,自動執行Bug修復、QA驗證、跨應用工作流。由於PyTorch、Hugging Face、llama.cpp等框架已優化,使RTX Spark成爲本地AI開發工作站,同時開發者可在輕薄本上直接訓練、微調中小規模模型,無需連接雲端服務器。
寫在最後:全民 AI 智能體的蓄勢待發
從硬件層面來看,RTX Spark是128GB統一內存與1 PFLOP FP4算力本地部署的具體展現,它將原本需要雲端AI服務器完成的工作,壓縮到了1.3kg、14mm厚度輕薄型筆記本中,讓120B大模型和跨應用 AI 智能體在本地運算提供了可能。
重點是,RTX Spark也並非單打獨鬥,背後不僅有微軟Windows on Arm的支持,同時NVIDIA也與共建的OpenShell安全框架,讓本地 AI 智能體首次成爲個人本地可安全、私密、隨身攜帶的標準工作流,而不是現在極客和程序員們通過開源社區不斷嘗試的小衆路子。
目前距離RTX Spark相關產品還有一些時日,NVIDIA還需要與ISV、OEM等諸多廠商展開深入合作,讓RTX Spark平臺逐漸變成一款普世化產品。細想一下,在今年晚些時候,你能看到一款僅有1.3kg左右的XPS 13輕薄型筆記本,卻擁有Alienware外星人級別的遊戲和AI性能,並且默認的部署環境能夠主動幫你解決工作和創作中的一些實際問題,想想是十分帶勁的。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















