COMPUTEX 2026一开始黄仁勋就来了个大招。如果说此前DGX Spark面向开发者且不具备笔记本那般的便携性,那么今天发布的NVIDIA RTX Spark补全了所有遗憾。RTX Spark芯片可以理解成专为 AI 智能体时代设计的SoC,包括Grace CPU和Blackwell RTX GPU,CPU与GPU通过NVLink-C2C互联成一个整体,并附上最高128GB LPDDR5X统一内存,直接是奔着 AI 智能体去的。
事实上OpenClaw和Hermes Agent在GitHub上以爆炸性速度增长,下载量短期内超过Linux、PyTorch等历史级项目,在OpenRouter等API平台上,智能体驱动约80%的Token用量。这导致Qwen、DeepSeek等开放式模型已经开始快速迭代,例如4月发布的Qwen 27B甚至胜过了2月初的近4000亿参数云端模型,证明前端模型已可在终端本地运行,基于RTX Spark平台的笔记本和微型台式机投向市场愈发成熟。
而NVIDIA RTX Spark推向市场不仅意味着,AMD、Intel之外,又多了另一种PC形态的新可能,从1985年首个Windows诞生至今,键盘、鼠标定义的用户体验也不再是唯一,接下来AI 智能体将有可能彻底改变输入方式,通过语音、视觉、自然语言交互,完成专业软件创作、代码编写,甚至是主动执行任务。
128GB统一内存的NVIDIA RTX Spark是不是真的这么厉害?在发布会之后,笔者有幸参与了会后媒体的相关解答,现在让我们花点时间,更深入一点了解NVIDIA RTX Spark,以及RTX Spark所带来的PC新畅想。

打造个人AI的超级芯片
会议上对于PC用户而言最重要的即是RTX Spark,内部代号N1X。这是NVIDIA专门针对AI、创作和游戏设计的产品,将PC由工具属性重新定义成智能搭档。
事实上N1X并非单一型号,而是一个芯片家族,包含多个定位不同的SKU,作为代表的旗舰芯片N1X 675追求1 Petaflop AI性能,最高拥有128GB LPDDR5X统一内存,并且具备6144 CUDA核心和第五代Tensor Core的Blackwell RTX GPU,具备48个SM,以及20核的Grace CPU,TDP在45W到80W之间。两者通过NVLink-C2C互联,从而在PC终端实现数据中心规格的芯片互联。

与此同时,Grace CPU由MediaTek合作设计定制,强调能效与互联能力,包括10个高性能Cortex-X925核心,10个能效Cortex-A725核心,属于ARMv9架构,基于台积电3N工艺打造。
从目前整理的信息来看,RTX Spark的Grace CPU性能表现比AMD Ryzen AI 9 HX 395略胜一筹。正因为如此,首发搭载RTX Spark N1X的笔记本也均为定义性能型高端轻薄本。
因此计划首发的RTX Spark的笔记本厚度基本控制在了14mm、轻至1.36kg,并使用14-16英寸Tandem OLED G-SYNC屏幕,首发OEM包括华硕、戴尔、惠普、联想、微软Surface、微星,宏碁、技嘉随后跟进。同时,对应的RTX Spark紧凑型桌面主机也蓄势待发。
以戴尔计划推出XPS系列的RTX Spark轻薄笔记本为例,可以预估首发的RTX Spark笔记本产品应该价格不会便宜。
除了旗舰级RTX Spark之外,NVIDIA还计划推出18核心,9个性能核与9个效能核的N1X 650,采用5120 CUDA核心,40个SM核心的Blackwell RTX GPU,TDP同样为45W到80W,内存最高128GB LPDDR5X。
另外还有两个非X的N1版本,分别是12核(8+4)CPU,2560 CUDA(20个SM),TDP 45W,最高64GB LPDDR5X的主流版本,以及10核 (7+3)CPU,2048 CUDA(16个SM),TDP 45W,最高64GB LPDDR5X的基础版本。
游戏与AI一把抓
顶配RTX Spark笔记本的Blackwell RTX GPU基本相当于GeForce RTX 5070性能,再加上略胜Ryzen AI 9 HX 395一筹的CPU表现,1.3kg左右笔记本表现出类似游戏本的性能表现是足以让人期待的。
在使用场景中,NVIDIA展示了AI模型到游戏的可行性。第一个被提出的应用是本地大模型推理,支持120B参数,以及100万Token上下文,这是非常夸张的。传统笔记本独显显存通常为8GB到16GB,GeForce RTX 5090 笔记本电脑 GPU也仅有24GB,运行70B模型压力很大。而RTX Spark的128GB统一内存让120B参数模型在FP4/INT4量化下可直接载入,实际值占据60GB到70GB内存空间,剩余50GB用于KV Cache和系统运行。

100万token上下文意味着可一次性处理整本长篇小说、数十万行代码库、或数百页法律、医学文档的全文分析,无需分段切割。
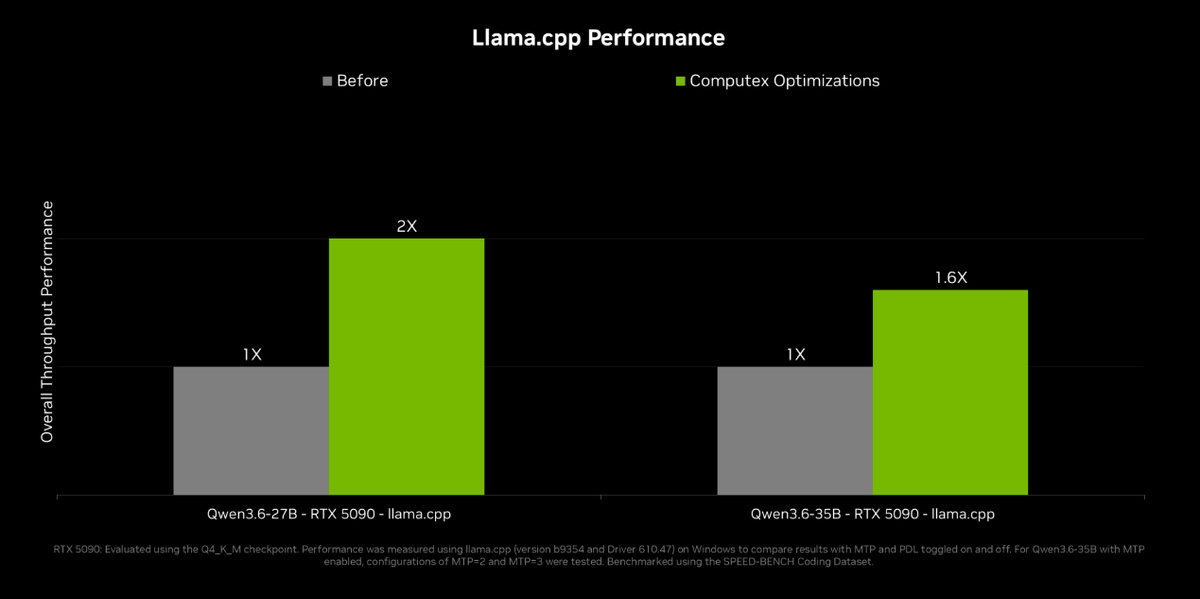
并且Dense Model推理速度提升约1倍,MoE模型提升约1.6倍。由于第五代Tensor Core原生FP4,同等模型体积下内存占用减半,吞吐量显著提升。
另外RTX Spark还提供了多GPU扩展的可能性,这是因为llama.cpp和ComfyUI支持多GPU配置,通过桌面版双卡串联,是有机会获得2倍性能,256GB统一内存。此外,深度研究助手,代码库级开发,架构分析、Bug定位、跨文件重构,都可以依赖本地RTX Spark进行。
NVIDIA多次强调RTX Spark将PC从工具升级到了队友,其中一点就是OpenShell搭配Windows Security Primitives具有了更多实战意义。目前OpenClaw等智能体无法安全地跑在用户主力PC上,要么担心删文件、要么担心隐私泄露。RTX Spark可以做到权限沙盒化,用户可精确设定Agent能访问哪些文件夹、不能碰哪些系统文件。即使Agent被Prompt Injection攻击,也无法突破预设的权限框架。
当智能体需要调用云端模型时,OpenShell会自动对请求中的个人信息,比如姓名、地址、公司内部数据,进行脱敏和隐藏。同时敏感计算优先分配给本地模型,只有脱敏后的通用请求才上云。
由于智能体本身具备跨应用自主执行,这意味着RTX Spark不再局限于单一App。智能体可同时操作Photoshop生成图片、Premiere剪辑视频、浏览器搜索素材、本地文件管理器整理工程文件。比如用户睡觉时,智能体可继续渲染视频、批量处理图片、或监控代码仓库提交并自动Review,这也是诸多养虾人的梦想之一。目前Hermes Agent和OpenClaw已发布原生Windows应用,集成OpenShell,今天即可下载使用。
在内容创方面,RTX Spark的128GB统一内存允许完整加载90GB以上的场景,通过OptiX和DLSS 4.5 Ray Reconstruction实现交互式近最终质量渲染,意味着整城市模型、电影级角色资产在一款笔记本上即可完成。在今年秋季,Blender 5.3将原生集成DLSS 4.5 Ray Reconstruction作为降噪器,Viewport实时反馈,专业软件进驻意味着RTX Spark从诞生之初就开始走向专业化。
视频制作上,Blackwell GPU原生支持HEVC 4:2:2编解码,配合128GB内存,可直接在时间线上处理多条12K素材而不需要代理文件。同时ComfyUI用户可在便携设备上运行复杂的多模态工作流,生成超高分辨率AI视频。RTX Spark的处理能力与大容量统一内存相结合,使其成为运行扩散模型性能最出色的笔记本电脑之一。
目前Adobe也已经加入到Spark平台中,Premiere和Photoshop为RTX Spark从底层重构,利用统一内存+TensorRT实现AI功能2倍加速,包括Firefly生成式填充和扩展,让现在Premiere和Photoshop 10%不到的AI应用,扩展到100%。
同时RTX Video Frame Generation也已经蓄势待发,通过2x到4x帧生成,让生成的4K视频更流畅、时长更长,这项技术同样也预计秋季推出。
关于游戏。由于RTX Spark图形性能约等于GeForce RTX 5070 Laptop级别,支持DLSS 4.5,包含动态多帧生成Dynamic Multi Frame Generation、6x帧生成、第二代 Transformer 超分辨率,NVIDIA Reflex降低40%延迟,以及完整的光线追踪技术,意味着RTX Spark本身就是一款优秀的游戏主机,再加上微软大力推动Windows on Arm平台,未来PC游戏环境注定会有ARM参与。
回到RTX Spark本身,这套硬件性能可在1440p分辨率下以100+ FPS继续3A游戏。同时Mod作者在使用NVIDIA Remix时候,可使用更高分辨率纹理、更多生成式AI资产,不再受到24GB显存的限制。同时NVIDIA ACE已经支持本地运行多语言AI NPC模型,128GB内存支持更复杂的角色行为树和对话上下文。
喜闻乐见的游戏同时录制、Broadcast AI实时抠像,本地AI生成封面/剪辑等直播与内容创作并行操作,在RTX Spark上也不是问题。
最后,RTX Spark也擅长本地代码智能体部署,例如DeepSeek-Coder、Qwen-Coder,结合百万Token上下文,可理解整个大型代码库。同时智能体可接入GitHub,自动执行Bug修复、QA验证、跨应用工作流。由于PyTorch、Hugging Face、llama.cpp等框架已优化,使RTX Spark成为本地AI开发工作站,同时开发者可在轻薄本上直接训练、微调中小规模模型,无需连接云端服务器。
写在最后:全民 AI 智能体的蓄势待发
从硬件层面来看,RTX Spark是128GB统一内存与1 PFLOP FP4算力本地部署的具体展现,它将原本需要云端AI服务器完成的工作,压缩到了1.3kg、14mm厚度轻薄型笔记本中,让120B大模型和跨应用 AI 智能体在本地运算提供了可能。
重点是,RTX Spark也并非单打独斗,背后不仅有微软Windows on Arm的支持,同时NVIDIA也与共建的OpenShell安全框架,让本地 AI 智能体首次成为个人本地可安全、私密、随身携带的标准工作流,而不是现在极客和程序员们通过开源社区不断尝试的小众路子。
目前距离RTX Spark相关产品还有一些时日,NVIDIA还需要与ISV、OEM等诸多厂商展开深入合作,让RTX Spark平台逐渐变成一款普世化产品。细想一下,在今年晚些时候,你能看到一款仅有1.3kg左右的XPS 13轻薄型笔记本,却拥有Alienware外星人级别的游戏和AI性能,并且默认的部署环境能够主动帮你解决工作和创作中的一些实际问题,想想是十分带劲的。

更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















