爲什麼先進的arm架構的蘋果其CPU單核性能可以遠超腐朽的X86陣營的AMD還有intel?
前言
疊甲:所有觀點僅代表個人觀點;所有闡述均經過了極度抽象簡化以便於理解;所有闡述僅舉例,不代表契合實際產品,如有雷同純屬巧合。
本文的內容如下:首先介紹x86引入解碼簇的原因,接着簡述解碼簇的基本結構,然後介紹OD-ILD優化,接着介紹hardware toggle point優化,最後解釋zen5的解碼簇設計選擇和背後可能的挑戰。
可惡的非定長指令集
爲什麼x86需要使用解碼簇的設計?爲什麼只有x86才採用瞭解碼簇的設計?這不得不從一個看似非常不起眼的ISA特性講起了:指令長度。對於Arm、Loongarch這樣的指令集而言,所有的指令長度均爲4Byte,我們將這樣的ISA稱爲定長指令集;而x86的指令可以是1Byte,可以是3Byte,也可以是15Byte等等,我們將這樣的ISA稱爲非定長指令集。我們不妨對比一下兩類指令集的解碼過程
定長指令集解碼
對於定長指令集,所有的指令長度均爲(比如)4Byte,這就意味着指令在地址空間內的擺放都是4字節對齊的。我們在將內容未知的指令碼送入譯碼器前就可知每一條指令的邊界何在,因此我們可以直接將每條指令的指令碼直接送入譯碼器。
直接譯碼
在不將任何rename工作前移的前提下,所有譯碼器的工作近乎可以視爲並行,我們可以方便得擴展譯碼寬度,easy!
非定長指令集解碼
(我們不考慮prefix這些變態特性!)對於非定長指令集,指令的長度任意,這也就意味着指令本身可能從地址空間內的任意位置開始。可惡!我們突然發現兩眼一抹黑,15Byte的內容可能是一條15Byte的nop指令,也可能是15條1Byte的nop指令!從未有過如此美妙的開局。
先確定指令邊界,再譯碼
譯碼過程出現了一個額外的步驟:指令邊界劃分。這使得我們的譯碼工作變成了半串行而非全並行,因爲只有知曉了第一條指令的末尾才能確定第二條指令的起始,以此類推,譯碼器越多,相關鏈越長。這條相關鏈讓x86的譯碼近乎不可能在一個時鐘週期內完成,我們有沒有辦法大幅優化這個過程呢?可以!加錢!

直接譯碼,確定指令邊界後再選擇有效結果
我們用空間換時間,窮舉所有可能!以8Byte內容待譯碼爲例,我們不妨將其拆分成從0-7Byte開始的8種可能,假設每一種可能都足以讓我們得到一條合法指令。我們將8種假設送入8個譯碼器,再根據前位譯碼器的輸出(指令長度)從後續譯碼器的結果中選擇有效的結果。依此,在定長指令集中只需要2個譯碼器的事,我們花了8個譯碼器才解決,而且解決得並不完美。首先仍然有部分串行的內容;其次,如此巨大的扇入扇出、複雜的shuffle和結果select仍然是時序難以承受的;最後,如此巨大的資源消耗效率極低、面積的擴大也會反過來導致時序惡化,我們可能還是得拆分流水級來保證頻率。天哪,難道我們陷入死局了嗎?
Uop Cache
既然非定長指令的譯碼如此費力,我們能不能避免?可以啊,我們將譯碼後的結果存儲下來,之後直接讀取不就可以跳過整個譯碼過程啦?於是我們看到了Uop Cache。Uop Cache的本質是按照基本塊組織的、存儲譯碼後指令的指令Cache。在Uop Cache中我們可以讓譯碼後的中間內容保持定長,從某種程度上將非定長指令集在處理器內部轉化爲了定長指令集,進而允許我們相對方便得擴大從Uop Cache取指的寬度,而無需顧忌譯碼複雜度爆炸的問題。
然而Uop Cache顯然不是完美的,否則全劇已終:
譯碼後的指令信息密度大幅下降,例如原先4Byte的指令碼可能需要8Byte去存儲。這也就意味着使用同量的SRAM,Uop Cache的有效容量只有ICache的一半,無法忍受!憑什麼我們x86要比別人多費這麼多勁兒還收益這麼低?
以基本塊組織的Uop Cache帶來了fragmentation和duplication的問題,導致空間利用效率低,進一步導致有效容量低。好傢伙,和第1點加在一起低上加低。
缺乏預取,難以應付大指令足跡內容。
我們不詳細闡述Uop Cache的故事,這不是本文的重點。那麼我們能不能把Uop Cache踢掉又保證性能呢?
解碼簇
反思,再反思,我們發現一切問題的主要來源都是我們無法確認指令的邊界,如果我們能夠知道指令從何處開始,不就能夠解決這個問題了嗎?我們在哪些情況下可以100%確認指令從哪裏開始呢?跳轉!程序流跳轉到一個新地址,這裏必然是一條指令的開始地址。而且我們會發現,一般而言程序中每5條指令會有1個分支指令,每2條分支指令會發生一次跳轉。
譯碼簇
我們發現,taken branch幫我們斬斷了譯碼簇之間的譯碼器間的相關鏈。儘管每個簇內部的譯碼器之間是部分串行的,但是相關鏈深度已然大幅縮減,組合爆炸的問題大幅緩解。不過我們顯然不會到此滿足,加料開始。
OD-ILD
Uop Cache的問題在於存儲的內容太多了,我們並不想付出如此多的代價,如果我們只存儲一點必要信息,比如指令長度呢?OD-ILD應運而生。我們在取指時同時讀取OD-ILD(實際上也可以將其視爲I-Cache的一部分),倘若命中,則和指令內容一起供給給譯碼簇。以此我們能夠提前劃分指令邊界,跳過部分譯碼邏輯,減少流水線深度,並極大減少了簇內譯碼器間的相關性。
OD-ILD命中
然而OD-ILD的內容與Uop Cache一樣是runtime訓練得到的,當我們第一次訪問某個代碼段時OD-ILD會發生miss,此時我們回退到基礎的譯碼簇流水線,確定指令邊界後將相關預譯碼信息填入OD-ILD中。在這種情況下還要經歷額外的流水線懲罰(因爲要寫OD-ILD)。到此爲止了嗎?似乎還有點不對勁?
Hardware toggle point
一般而言程序中每5條指令會有1個分支指令,每2條分支指令會發生一次跳轉。
我們不禁有幾個疑惑:
如果極端情況下許許多多的指令中都沒有跳轉,即超長基本塊,那麼此時豈不是多譯碼簇就失效了?工資白髮?
就算如此所說,似乎一個基本塊也得有10條指令。那麼每10條指令才能切換一次譯碼簇,豈不是沒法將多譯碼簇用來提升處理器的峯值帶寬了?
taken branch在程序流中的出現太靠天意,似乎不能全指望程序員,不如讓處理器能夠自己往程序裏添加taken branch,hardware toggle point應運而生。
當我們探測到一段程序內沒有如我們預期得出現taken branch時,我們向BTB中插入一個fake taken branch,儘管指令流中沒有,但是處理器仍會將其視作taken branch,每當執行到此處時就可以切換至另一個解碼簇了。fake taken branch的插入會佔用BTB的表項目,而且遵循一定的規則,例如只有常被執行的指令塊我們纔會嘗試爲其插入fake taken branch。至此,我們終於能夠充分利用多解碼簇了,不僅擺脫了Uop Cache,還能夠兼顧單線程的峯值性能。
Zen5的選擇
等等,爲什麼zen5的多解碼簇根本沒法同時運用於一個線程,這不是光速打臉嗎?其僅支持在雙線程運行時,每個線程獨佔一個譯碼簇。
我們不妨分析下zen5目前遇到的困難,zen5相較各種mont的最大區別是它支持SMT,爲什麼SMT會給多解碼簇帶來挑戰呢?我們不得不回到SMT的資源劃分問題上,實際上在大多數的SMT實現中,ROB、instruction queue等隊列是靜態平分給每個線程的,這些隊列有一個共同特點:他們藉助類FIFO的特性天然維持保序特性。這也導致了一個問題,即他們天然厭惡隊列內出現內容空洞。當某一個線程出現例如分支預測錯誤這樣的需要flush流水線的操作時,倘若一個譯碼簇的類FIFO隊列內存在兩個線程的指令,我們
要麼根本無從將他們區分,只能全部flush。這會導致一個線程的性能損失擴大到兩個線程的性能損失,無法忍受。
要麼flush掉屬於一個線程的指令,並在類FIFO隊列中留下大片的空洞。這給我們的隊列管理帶來了巨大的問題。
因此,我們需要大量的額外設計讓SMT能夠混合利用多譯碼簇。嗯,未來可期。更何況zen5並沒有去除Uop Cache,我們還是靜待zen6吧,同時值得期待的還有skymont的後繼darkmont,我們極有可能看到e core的完全體登場,intel是如何處理SMT問題的呢?
說完了這些繼續說
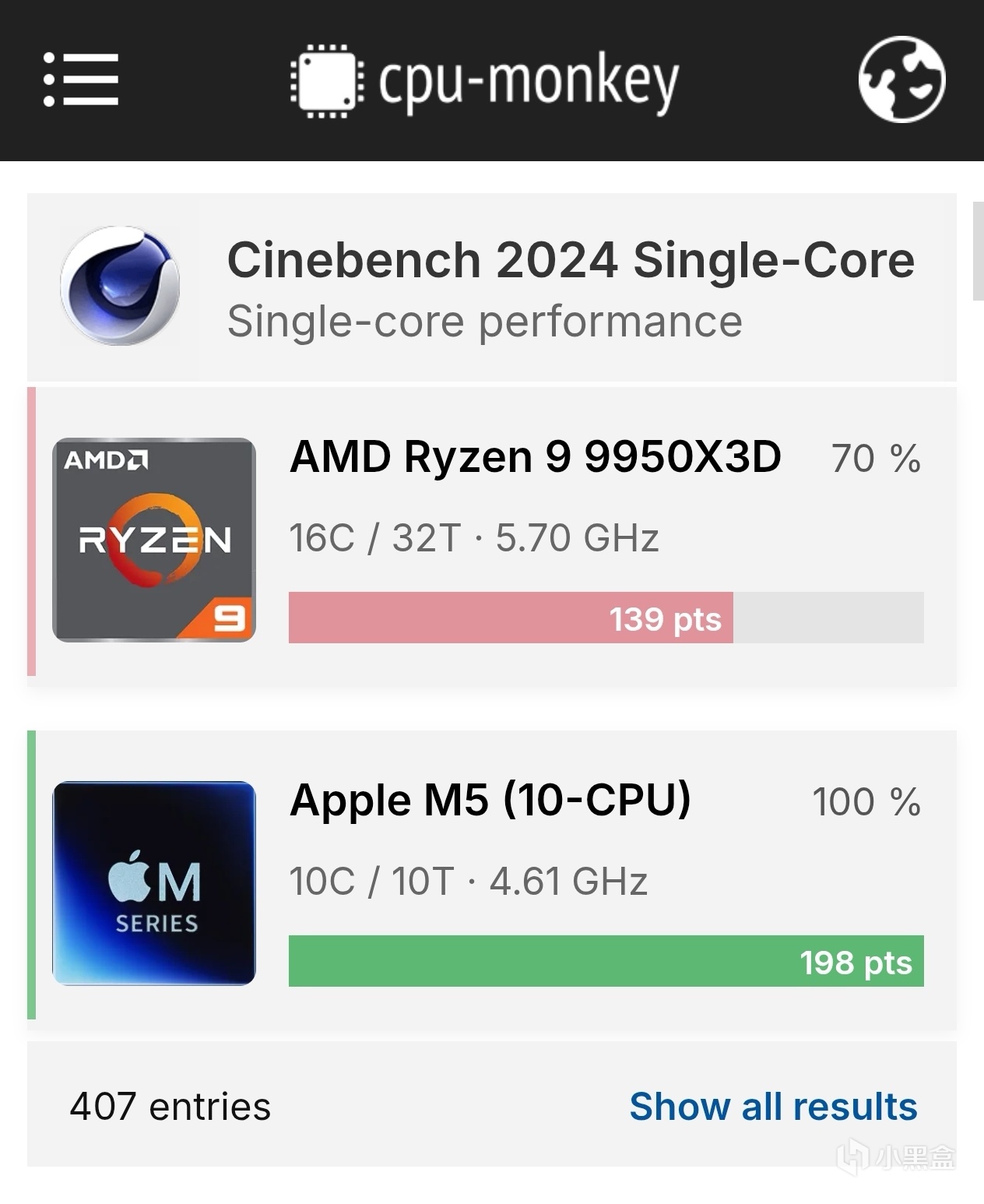
爲什麼Apple Silicon在R24中這麼強(一)—LAP
如你所見,今天我們要講的是,爲什麼,Apple Silicon在Cinebench R24中表現如此的強,連隔壁的X86都甘拜下風,尤其是M4,我看我們的貼吧老哥都跑上192了,簡直是非常的厲害。
首先我們需要明白R24是一個比較重LSU的一個benchmark,那麼M4剛剛好大提升的就是這部分,那麼今天我們引入我們的主題,LSU,LSU是CPU中很重要的一個部分,我們首先需要了解一下什麼是LSU。
LSU 是 “Load–Store Unit”(加載存儲單元)的簡稱,是一個專門負責處理所有訪存指令(即加載 load 和存儲 store 指令)的執行單元。下面從多個角度詳細介紹其功能和內部結構。
1. LSU 的主要功能
(1)執行訪存指令
LSU 主要負責將程序中發出的 load 指令和 store 指令送入內存系統進行處理。這包括根據指令中給出的基地址、偏移量等信息計算出實際訪問的地址,並根據地址從緩存或主存中讀取數據(load),或者將數據寫回內存(store)。
(2)地址生成與虛實地址轉換
爲了確定內存中具體的位置,LSU 內通常會包含一個或多個地址生成單元(AGU)。AGU 負責執行簡單的算術運算(如加法),將基地址與立即數或寄存器內容相加,從而計算出訪問地址。與此同時,在採用虛擬內存的系統中,LSU 還需要將程序使用的虛擬地址轉換成物理地址,這一過程一般依賴於 TLB(Translation Lookaside Buffer)來加速轉換過程。
(3)處理訪存依賴和數據轉發
在現代高性能處理器中,指令往往是亂序執行的。LSU 不僅要確保各條訪存指令按正確的順序完成(即滿足內存一致性和程序順序要求),還需要解決因數據依賴產生的潛在冒險問題。例如,若一條 load 指令依賴於一條尚未完成的 store 指令,LSU 可能會通過“數據前向轉發”(Store-to-Load Forwarding)的機制直接將 store 指令產生的數據傳遞給後續的 load 指令,從而降低延遲並提高流水線利用率。
2. LSU 的內部結構
(1)Load Queue(加載隊列)與 Store Queue(存儲隊列)
爲了管理所有訪存指令,LSU 內部一般設計有兩個隊列:
(2)Load Queue (LDQ): 用於暫存所有待執行的 load 指令,在這些指令執行前,會先進行地址計算和依賴檢查;
(3)Store Queue (STQ): 用於記錄所有 store 指令,特別是在亂序執行中,store 指令可能提前計算出地址和數據,但數據真正寫入內存時需要保證按程序順序提交。通過存儲隊列,LSU 能夠檢測 load 與 store 之間的依賴關係,並在可能出現數據競爭時採用轉發技術。
(4)地址生成單元(AGU)
AGU 負責將 load/store 指令中的地址計算任務具體化,結合基地址與偏移量,生成最終的內存訪問地址。這一步驟對提高訪存操作的效率至關重要。
(5)與緩存/內存系統的接口
LSU 是 CPU 內部執行單元與外部內存系統之間的橋樑。它不僅向緩存(如 L1 數據緩存)發出數據請求,而且還接收緩存或內存返回的數據。在緩存命中情況下,數據可以迅速從緩存傳遞給 CPU;而在緩存未命中時,LSU 會協調從更低級別內存中取數,同時管理等待和重排操作。
總之,LSU(Load–Store Unit)是 CPU 中專門負責處理內存訪問操作的執行單元。它通過內部的地址生成、Load/Store 隊列以及數據轉發等機制,確保 load 和 store 指令能夠高效且正確地與內存系統交互。在支持亂序執行和高指令並行度的現代 CPU 設計中,LSU 的高效實現對於整體性能至關重要。這種設計既要求嚴謹的硬件邏輯,也需要在系統級別上考慮訪存延遲、依賴檢測以及緩存接口等多個方面,從而實現既嚴謹又高效的內存操作管理。這也就是我常說的,一個優秀的u-arch三要素,BPU,LSU,prefetcher,把這三個能夠做好,才能達成performance和energy的最強。
那麼,Apple在LSU有沒有過人之處呢?有的朋友,有的,而且是人無我有的這種。前段時間,春節期間,一個有關CPU side‐channel attack(CPU側信道攻擊)的paper吸引了我的興趣,我發現了2個有關LSU part的巧思,那麼接下來我會與你們分享這個技術。
首先,我們來談談LAP(Load Address Predictor),Apple Silicon 處理器(M2、M3、A15 及更新型號)中包含一個 Load Address Predictor (LAP),用於預測加載指令(load instruction)的目標地址,以減少數據訪問延遲,提高執行效率。其原理:
(1)LAP 記錄過去執行的相同load instruction(加載指令)訪問的address(地址),並基於這些history address(歷史地址)進行predict(預測)。
(2)如果predict(預測)的address(地址)已經緩存(cached),CPU 將會在正式calculate(計算)之前,使用該predicted address(預測地址)preload data(提前加載數據)。
(3)這一機制允許 CPU 在數據尚未真正確定的情況下,利用predicted value(預測值)執行後續指令,從而實現更快的計算。
(4)但如果預測錯誤,CPU 會丟棄錯誤的計算結果,並回滾到正確的執行路徑。
LAP的基本作用也很簡單,LAP是一種basic on 數據流推測執行(Data Speculation Execution) 機制,專門用於優化加載指令(Load Instructions)的execution efficiency(執行效率)。相較於traditional Control Flow Speculation(傳統的控制流推測),LAP關注的是DSE(Data Speculation Execution),通過remember same load instruction(記錄相同加載指令)的history address(歷史訪問地址),LAP是predict(預測)該指令未來可能訪問的地址。如果(predicted address)預測地址cached(已緩存),CPU 直接在推測窗口中加載該地址的數據,並執行後續指令,而無需等待實際內存訪問完成。這樣就可以提高整體的efficiency(效率)。
如圖LAP 預測的地址如果已經在緩存中,則加載時間明顯更短,說明LAP 僅能在緩存命中時生效。最後如果predicted miss(預測錯誤),CPU 丟棄推測結果,並恢復到正確的執行路徑。
由圖可知:SA+RV(上):訪問模式保持 步長一致,但數據存儲爲隨機數。Random(下):訪問地址和數據都是隨機的。目的是分離 LAP 對地址預測和數據內容的影響。
結合這兩張圖,說明即使數據隨機,只要地址訪問模式有規律,LAP 仍然可以預測。說明 LAP 僅預測加載地址,而不考慮數據值。LAP 主要依賴地址模式(Strided),而與數據值無關。訓練閾值 = 500 次,表明 LAP 需要足夠多的訓練數據。
那麼我們來看看LAP的具體工作原理,首先LAP有屬於自己的激活條件。至少 500 次same load instructions(相同的加載指令)才能激活 LAP feature。並且在某些 CPU 上(如 M3),需要更高的training Length(訓練次數)(~1000 次)。
那麼,除了training length,還有Stride(步長)的限制。LAP只能學習固定步長(Strided Access Patterns) 的加載地址模式,stride必須在 255 字節以內(8-bit stride tracking),如果步長大於 255 字節,LAP不會觸發預測。
如圖就是通過不同的訪問模式(Striding和Random),檢驗LAP是否適用於SAP(Strided Access Patterns),隨機訪問模式是否影響預測。結果就是LAP 對固定步長訪問模式有明顯優化作用(Striding 模式加速)。對隨機訪問模式無優化作用(Random 模式執行時間較長)。
該圖展現了不同 Apple 處理器的 Striding vs. Random 運行時間,由圖可知,M1 處理器不支持 LAP,M2/M3 P-core 具備 LAP 。M2/M3 P-core 在 Striding 訪問模式下具有預測優化,隨着訓練次數增加,LAP 提前加載數據,提高執行效率。M3 需要更長的訓練時間(320 次 vs. 120 次),可能表明 Apple 在 M3 處理器上調整了 LAP 觸發條件。但是,M2,M3的E-Core並不支持LAP技術。可能和P與E的stress分配有關。
結合這張圖我們就能清楚的發現,橫軸:訓練長度(Training Length),縱軸:步長(Stride)。顏色深度:藍色區域表示 LAP 高激活概率。黃色區域表示 LAP 失效。由圖可知,LAP 需要 ≥ 500 次訓練才能穩定激活。步長必須 ≤ 255 字節,超出範圍 LAP 不會預測。
最後,預測地址的緩存要求:LAP 不會主動預取(Prefetch)數據,而是僅在預測地址cached(已經緩存)在 L1 cache時纔會推測加載。如果預測地址未緩存,LAP直接終止推測執行,不會進行推測性加載。
接下來,我們說說training和retire。首先LAP通過檢測same load instructions(相同加載指令)在不同時間訪問的address model(地址模式)來學習預測:
1.記錄加載指令的歷史地址:CPU 監視特定的加載指令(Load Instruction),存儲其最近幾次訪問的地址。如果訪問模式符合固定步長(Strided Pattern),LAP進入激活狀態。
2. 在足夠多的訓練後,LAP 開始predict:例如,如果 ldr x0, [x1] 過去幾次load address(加載地址)分別爲:0x1000 → 0x1020 → 0x1040 → 0x1060。發現stride(步長)爲 0x20(32B),LAP 預測下一次地址爲 0x1080。
3.推測執行(Speculative Execution):如果 0x1080 在緩存中,CPU 直接使用該值進行計算,而不會等待實際地址解析完成。如果 0x1080 不在緩存,LAP stall prediction,CPU retire(回退)到正常加載流程。
如圖,基於strided access進行next load address prediction(下一個加載地址推測)。
如果 LAP address prediction miss(預測的地址錯誤)(即 x1 實際指向 0x1060,但 LAP 預測 0x1080),CPU 需要回滾執行狀態:CPU 發現預測錯誤,丟棄錯誤的推測執行結果。恢復正確執行路徑,重新從 x1 指向的正確地址 0x1060 進行加載。但微架構狀態(如緩存和分支預測表)不會回滾,可能導致信息泄露風險。
LAP 預測執行窗口(Speculation Window)
論文的實驗測量了 LAP 在 Apple M2、M3 處理器上的 推測執行窗口,如圖:
1.最長可達 600 CPU 週期。
2.可執行多個後續指令,包括:計算操作(Arithmetic Operations),條件判斷(Conditional Branching),甚至可以調用未被程序正式調用的函數(如圖)。
LAP的推測窗口影響因素
1.緩存狀態:
2.如果預測地址cached:Speculation Window deeper較深,可執行長達 600 個週期的推測計算。
3.如果預測地址不在緩存:LAP 預測終止,Speculation Window shortest極短(< 100 個週期)。
4.加載指令是否 RAW 依賴(Read-After-Write):如果 ldr 指令的目標寄存器在隨後指令中有數據依賴,則Speculation Window maybe short。
5.執行核心(P-Core vs. E-Core):E-Core 沒有 LAP 機制,推測窗口不存在。
那麼,LAP與控制流預測的區別是什麼呢?傳統Spectre依賴控制流預測(Branch Prediction),如:if (x > 10) { ... } else { ... }CPU 可能錯誤預測分支,導致執行錯誤路徑的指令。而,LAP 是數據流預測:其預測 ldr x0, [x1] 訪問的地址,而非控制流路徑。
第二點,LAP與硬件數據預取(DMP)的區別:數據預取器(DMP):如果加載的值類似於指針,DMP 可能會提前預取數據。LAP 不主動預取數據,但會使用預測地址的緩存值進行推測計算。
那麼這麼好的技術,在什麼Apple Silicon和Device有呢?
LAP 適用範圍在論文的實驗結果表明:LAP 僅存在於 Apple M2、M3 處理器的高性能核心(Performance Core, P-core):M1 處理器:未發現 LAP 機制;
M2 處理器:P-core 存在 LAP,E-core 沒有 LAP
M3 處理器:P-core 存在 LAP,但需要更多訓練,E-core 沒有 LAP
Apple 移動設備(A 系列):A15 及更新型號(iPhone 13 mini、iPhone 14 Pro Max、iPhone 15 Pro Max、M4 iPad Pro):支持 LAP。
iPhone 13(標準版)和 iPhone 12 及以下機型沒有 LAP。
哦,這可太可惜了,這麼好的技術Firestorm剛好沒有,我們可憐的類似物Oyron也沒有。
總結一下,LAP 是 Apple Silicon 處理器中的新型數據流推測執行機制,用於 優化加載指令的執行效率。LAP 需要特定訓練條件(500 次相同加載、步長≤255 字節)才能可靠激活。LAP 預測僅在預測地址已緩存時生效,否則推測執行窗口會縮短。LAP 允許長達 600 CPU 週期的推測執行,可能影響數據安全性。LAP 僅存在於 Apple M2/M3 的 P-core 上,E-core 不支持該功能。LAP 與 Spectre(控制流預測)和硬件數據預取(DMP)不同,是另一種微架構優化策略。
那麼,接下來我們推測一下其硬件實現,首先就是LAP在CPU Architecture中的位置,LAP 作爲加載地址預測器(Load Address Predictor),主要影響加載/存儲單元(Load/Store Unit, LSU) 和Frontend Prediction feature(前端預測機制),其大概率存在於:
1.L1 數據緩存(L1D Cache):處理器執行 ldr 指令時,如果 LAP 預測的地址已緩存,數據可以立即獲取,從而減少訪存延遲。如果數據未緩存,LAP 預測終止,CPU 需要正常訪問內存。
2.重排序緩衝區(ROB, Reorder Buffer):由於現代CPU採用亂序執行(Out-of-Order Execution, OoO),LAP 預測的地址加載結果可能會影響後續指令的執行順序。
3.通過預測表(Prediction Table)進行實現:存儲器history address(地址歷史),用於學習步長模式(Strided Pattern)。可能採用按 PC(Program Counter)索引的結構,類似於分支預測器(Branch Predictor)例如TAGE,所以我們在這可以思緒飛揚一下,why not,給TAGE上增加對應的LAP table呢?
接下來我們詳細的分析一下LAP可能的硬件組成,
1.負載地址預測表(LAPT, Load Address Prediction Table)
作用:存儲過去的加載地址歷史,用於模式學習和預測下一個地址。
存儲結構:PC 作爲索引:LAPT 可能使用加載指令的程序計數器(PC) 作爲索引,以便針對特定的 ldr 指令進行學習。
步長記錄(Stride Tracking):記錄相鄰兩次加載之間的步長,如果步長固定,則 LAP 進入預測狀態。
可能的存儲格式:
存儲深度:論文實驗表明 LAP 需要訓練至少 500 次才能穩定激活,因此 LAPT 可能存儲500 條以上的歷史記錄。
2.預測邏輯(Prediction Logic)
模式檢測(Pattern Matching):當 ldr 指令被執行時,LAP查詢LAPT,檢查該指令的歷史加載地址是否具有固定步長。如果連續的地址訪問符合 addr_n = addr_{n-1} + stride,LAP預測 addr_{n+1} 並提前加載數據。
閾值控制(Threshold Control):論文實驗顯示 500 次訓練後 LAP 才能觸發,因此預測邏輯可能有一個訓練閾值,避免誤預測,通過計數器存儲每條 ldr 指令的匹配次數,防止過早觸發預測。
3.預測觸發器(Prediction Trigger)
加載指令執行時,LAP 檢查是否滿足預測條件:
如果滿足:計算預測地址 = last_address + stride。如果預測地址已緩存,則提前加載數據到 CPU 的寄存器。進入推測執行窗口(最大 600 週期),執行後續指令。
如果不滿足:LAP 預測終止,CPU 進行正常的內存訪問。
4.失效回退(Misprediction Recovery)
如果預測錯誤(即 ldr 指令的實際地址不等於預測地址),則:
撤銷推測執行:丟棄所有基於錯誤預測值的計算結果。
恢復正確執行路徑:重新從 ldr 指向的正確地址讀取數據。
但微架構狀態(如緩存內容)不會回滾,可能引發信息泄露風險(如 Spectre)。
根據以上的分析,我們發現有三種實現方式。
1.類似於分支預測器的硬件實現
LAP 預測邏輯可能採用分支預測器(Branch Predictor)類似的結構:
LAPT(類似 BTB):記錄 ldr 指令的歷史加載地址。採用 PC 作爲索引,類似於分支預測表(Branch Target Buffer, BTB)。預測觸發邏輯(類似 GShare):計算步長,並基於步長模式預測下一個加載地址。可能採用哈希索引(Hashed Indexing) 以減少存儲需求。
2。結合硬件數據預取(Data Prefetching),LAP 和數據預取器(DMP)的區別:
DMP(Data Memory-dependent Prefetcher) 會基於數據模式預取地址,而 LAP 只預測加載指令的地址。LAP 不會主動預取數據,只會在預測地址已緩存時觸發推測加載。
3.結合亂序執行(Out-of-Order Execution)
LAP 可能集成到 亂序執行引擎(OoO Execution Engine):存儲-加載轉發(Store-to-Load Forwarding):如果預測地址匹配 L1 緩存,則加載數據。指令隊列(Instruction Queue)優化:預測成功時,CPU 直接使用加載值,不需要等待訪存完成。
不過,以上三個方法我或許會更青睞集成進BPU中。
爲什麼Apple Silicon在R24中這麼強(二)—LVP
那麼,一篇我們說完了LAP,其實還有一個技術,LVP,那麼,LVP是什麼呢?LVP(Load Value Predictor, 負載值預測器)。其是一種u-architecture優化技術,用於緩解Read-After-Write (RAW) 依賴帶來的性能損失。RAW依賴通常會強制 CPU 順序執行相關指令,影響流水線的並行性。LVP通過stress instructions prediction(預測負載指令)的return value(返回值)來Improve the parallelity(提高並行度),從而improve process performance(提升處理器性能)。
首先,我們需要理解什麼是RAW依賴,當一個指令讀取的值取決於前面某個存儲操作的結果時,必須等前面的存儲操作完成,CPU 才能執行這個指令。例如:
int x = load(mem_address);
int y = x + 1; // 依賴於 load 指令
如果 load(mem_address) 需要從主存中取數據(延遲高達數百個週期),那麼 y = x + 1 指令必須等待 load 完成才能執行,從而影響流水線性能。
那麼LVP是怎麼做的呢?LVP通過觀察historical load value(歷史負載值)並predict(預測)未來的load value(負載值),從而在內存訪問完成之前提供一個估算值,使得依賴該值的指令可以提前執行:
1.學習模式:LVP 觀察load instruction(負載指令)多次執行的結果,如果某個load value(負載值)始終一致,它就會將該值作爲預測結果。
2.預測模式:如果 LVP 發現某個load instruction(負載指令)過去返回的值是恆定的,它會在該指令下一次執行時立即提供預測值,而不等待實際內存訪問完成。
3.驗證與回滾:如果預測錯誤,CPU 會丟棄錯誤的計算結果,並重新執行相關指令。
我們來看這個示例,LVP 在循環計算中的典型應用:
for (i=0; i<N; i++)
val = arr[val];
LVP觀察到 val總是被賦值爲foo,於是在未來的迭代中直接預測val = foo,減少因 RAW 依賴造成的流水線停滯。如果預測錯誤,則回滾並重新執行。
由圖所示, Load Value Predictor (LVP) 在優化 Read-After-Write (RAW) 依賴時的工作流程。
具體包含 4 個步驟:
1.CPU 觀察歷史負載值,發現 val 的加載值始終爲 foo。
2.LVP 激活,開始預測未來的 load 結果。
3.CPU 並行執行兩條路徑:
投機執行路徑:使用預測值 foo 計算後續代碼。
實際執行路徑:讀取內存中的真實值。
4.結果確認:
如果預測值正確,則提交投機執行的結果。
如果預測值錯誤,則回滾並重新執行正確的計算。
從中我們可以得知, LVP 通過投機執行來緩解 RAW 依賴,減少等待存儲器訪問的時間,提高流水線並行度。並且LVP通過 “學習過去的負載值” 來提高預測準確性,並通過回滾機制保證錯誤預測時 CPU 狀態的一致性。
接下來我們看看LVP具體怎麼實現的,我們發現,M3、M4 和 A17 Pro 處理器都實現了 LVP,但其設計上有一些限制:
1.預測範圍,支持預測的數據寬度:1B(字節),2B(半字),4B(字),不支持 8B(雙字)(即 64 位),推測是爲了防止 LVP 直接預測指針,影響內存安全。
2.LVP僅對常量值有效:如果load instructions value(負載指令的值)是恆定的(例如 foo),LVP會學習該值並進行預測。如果負載值是遞增或遞減的(stride pattern),LVP不會激活。
3.局部性與訓練機制:LVP基於指令地址(PC)進行訓練,每個特定的load指令最多可以存儲72個不同地址的預測值(即 LVP 採用了類似於 cache set-associative 設計)。循環展開會導致LVP失效,因爲每次展開的 load 指令地址不同,LVP 無法積累足夠的歷史信息。
由這張圖,我們可以發現,M2 P-core:沒有 LVP,執行時間線性增長。M3 P-core:LVP 生效,執行時間顯著減少(約 50%)。M2 E-core 和 M3 E-core:均未顯示 LVP 跡象,執行時間與對照組相同。所以,我們可以獲得結論,LVP 僅在 M3 的 P-core 上生效,而 E-core 不包含 LVP 機制。而M2 處理器不具備 LVP,意味着該優化是 M3 及更高代芯片的新特性。
該圖展示了 LVP 在不同 load 寬度(1B, 2B, 4B, 8B)下的表現。在 M3 P-core 上,分別測試 1B、2B、4B 和 8B 的 load 指令,並記錄執行時間。從結果來看,1B, 2B, 4B 負載 LVP 成功預測,執行時間降低。8B 負載 LVP 僅在返回值爲 0 時激活,否則失效。所以,Apple 可能通過限制 8B 負載的預測,防止LVP直接預測 64-bit 指針值,以減少潛在的安全風險。
該圖對比了 LVP 在加載固定值 vs. 遞增值時的表現,左側(恆定值),LVP 預測生效,執行時間減少。右側(遞增值),LVP 不生效,執行時間與隨機值類似。我們可知,LVP 僅適用於恆定的load值,無法預測遞增/變化模式。
該圖展示了在循環未展開 vs. 完全展開情況下 LVP 是否生效。結果顯示,循環未展開(左圖):LVP 生效,執行時間減少。循環展開(右圖):LVP 失效,執行時間迴歸到正常水平。所以,我們可知,LVP 依賴於特定指令地址,如果指令地址因循環展開而改變,LVP 訓練狀態會丟失,導致預測失效。
首先,該圖展示了 LVP 能夠同時存儲的最多指令數(72 個)。可知,LVP 採用Local Indexing Strategy(局部索引策略),最多能同時維護 72 條 load 預測條目,可能是 4-way set-associative cache(4組相連緩存結構)。
接下來我們看看LVP的行爲特性
1.訓練與預測精度,訓練階段:需要約 250 次training load(訓練加載),LVP 纔會達到高置信度,並穩定預測值。訓練時,如果 CPU 發現負載值 始終一致,LVP 進入預測模式。
2.錯誤預測時的行爲:如果 LVP 預測錯誤,CPU 仍然會使用預測值進行計算,但會在之後檢查真實值並回滾執行狀態。
3.預測狀態的持久性:如果 CPU 核心長時間未執行 LVP 相關指令,預測狀態可能會逐漸丟失。LVP 預測狀態不會跨進程共享,說明 LVP 可能使用進程 ID(PID) 作爲indexing tag(索引標籤),防止預測值泄露到其他應用程序。
該圖展示了 LVP 訓練所需的最少 load 次數,在 250 次之後,預測才變得穩定。我們可知,訓練 load 次數至少需要 250 次,之後 LVP 預測可靠度提高。
並且如圖,測試了 LVP 預測狀態是否會隨時間丟失。結果表明,如果沒有其他負載干擾,LVP 狀態可持續長達 1 秒。但是強負載會導致 LVP 訓練狀態衰減。所以,LVP 預測狀態較爲持久,但會被 CPU 其他高強度任務沖刷掉。
由該圖可知,測試了在 LVP 預測錯誤時,CPU 會繼續執行多少條指令。預測錯誤時 最多執行 110 條 mul 指令(330 cycles)。如果 load 命中緩存,僅執行 10 條指令(30 cycles)。由此可知,預測窗口的深度取決於 load 是否命中緩存,如果 load 需要從內存獲取數據,預測窗口會更長。
接下來我們看看其與u-architecture的關係,
1.LVP 與亂序執行:亂序執行(Out-of-Order Execution, OoOE)允許 CPU 在數據準備好之前執行無關指令,但 仍然受限於數據依賴。且LVP 進一步提升並行性,通過預測數據值,使得即使存在數據依賴,也能讓後續指令提前執行。
2.LVP 與投機執行:投機執行(Speculative Execution)允許 CPU 在分支指令尚未確定時繼續執行可能的路徑,如 Spectre 類漏洞所利用的機制。LVP 與投機執行不同:投機執行預測的是控制流分支預測(branch prediction),LVP 預測的是數據流數據預測(data prediction)。兩者都可能導致瞬態錯誤計算,但 LVP 更專注於提高數據訪問的並行性。
那麼LVP 的實際影響呢?首先運行時性能提升,LVP 可以 顯著減少 RAW 依賴帶來的延遲,特別是在 循環密集型計算 中,可能提升 近 2 倍 的吞吐量。在 M3 處理器上,上面的實驗顯示:如果 load 值是恆定的,M3 的 LVP 可使執行時間減少近 50%。如果 load 值是隨機變化的,LVP 不會生效,導致性能下降到正常水平。但是新技術也會對微架構安全性產生影響,手下嗎需要小心選擇可預測的負載,否則可能誤導後續計算。其次需要控制誤預測帶來的回滾開銷,否則可能適得其反,導致比傳統 RAW 依賴更嚴重的性能損失。最後需要配合其他投機執行保護機制,確保在預測錯誤時正確恢復 CPU 狀態,避免影響數據一致性。
總結一下吧,蘋果 M3 處理器的 LVP 機制是爲了提高數據訪問效率而設計的微架構優化,主要作用是預測負載指令的返回值,減少 Read-After-Write 依賴帶來的流水線阻塞。
(1)優勢:
1.可以大幅提升LSU performance(內存訪問性能),尤其是在loop calculate(循環計算) 和instructions pipeline(指令流水線)優化方面。
2.採用了多層次保護措施(不預測 64-bit 指針、不跨進程預測),減少了安全風險。
(2)侷限性:
1.僅支持 1B、2B、4B 負載預測,不支持 8B 負載(防止指針推測)。
2.不適用於遞增/遞減負載值(只對恆定值有效)。
3.不能跨進程共享狀態,限制了部分全局優化的可能性。
總體而言,LVP 作爲 CPU 設計的一種重要優化技術,未來可能會進一步發展,以支持更廣泛的數據模式,同時增強安全性。那麼很顯然,這個東西Firestorm類似物的產品依然沒有,哦好可惜啊
接下來我們對LVP進行一下硬件推測。LVP 作爲一個微架構優化單元,主要用於記錄和預測 CPU 加載指令返回的值,使 CPU 在數據尚未到達時仍能繼續執行依賴該值的指令。它的硬件實現可能包括:LVP 存儲結構(預測緩衝區),LVP 訓練和更新邏輯,LVP 預測和投機執行機制,LVP 回滾和錯誤恢復機制,LVP 與其他 CPU 組件的交互。
1.LVP 預測緩衝區(Prediction Storage)
LVP 需要一個存儲結構來記錄哪些加載指令值得預測,以及其歷史預測值。
(1)結合實驗數據,我們推測:LVP 採用 4 路組相聯緩存結構(4-way set-associative),類似於 CPU 的 L1 緩存。最多可同時追蹤 72 個不同的加載指令,表明其存儲容量較大,可能有一個 72-entry 的預測表,每個 entry 記錄一個加載指令的預測信息。
(2)存儲索引基於 PC(Program Counter):由於 loop unrolling(循環展開)會導致 LVP 失效,說明 LVP 存儲狀態是按指令地址(PC)進行索引的,而不是全局的加載值記錄。可能採用 指令地址的哈希值作爲索引方式,以減少存儲佔用。並且可能會考慮頁內偏移(page offset) 來減少索引衝突。
(3)預測數據的存儲格式:由於 LVP 僅適用於 1B、2B、4B 寬度的加載值,可能使用按字節存儲的表結構 來存儲預測值,而非直接存儲完整的 64-bit 值。不會預測 8B(64-bit)值,但如果爲 0 則會預測,表明 Apple 可能採取了一個硬件安全策略,避免直接學習和預測指針值。
2. LVP 的索引與訓練機制,LVP 需要在 CPU 執行過程中不斷觀察和學習哪些加載指令的返回值是可預測的。
LVP 訓練機制:
(1)訓練數據的收集:LVP 僅對固定加載值(constant loads)進行訓練,而不會訓練步長遞增的加載值(striding values),表明 LVP 採用了一種簡單但安全的模式匹配機制。實驗表明大約 250 次相同的加載值執行後,LVP 開始提供可靠預測。在此過程中,每 60 次訓練 LVP 的預測可靠性會增加,說明訓練數據可能使用了一個 基於計數器的置信度模型(confidence counter):
低於 60 次:不激活預測
60-120 次:部分預測
120-240 次:預測率逐步提高
250 次以上:預測值趨於穩定
(2)訓練狀態的存儲:由於 LVP 在 1 秒內可保持穩定,表明其狀態存儲可能位於 CPU 內部的獨立預測緩衝區,而不是 L1/L2 緩存。LVP 訓練狀態不會跨進程傳播,表明 LVP 存儲可能使用 進程 ID(PID)或 ASID(Address Space ID) 作爲other index(額外索引),確保預測不會影響其他進程。
3. LVP 的預測和投機執行
預測機制
(1)預測的觸發條件:
加載指令的值在歷史執行中出現高度重複(即前 250 次均返回相同值)。
該指令的 PC 地址已被 LVP 記錄。
該指令的數據寬度在 1B、2B 或 4B 之間。
(2)投機執行窗口:
如果加載值未命中緩存(cache miss),LVP 的投機執行窗口最長可達 330 cycles。
如果加載值命中緩存(cache hit),LVP 的投機窗口縮短至 30 cycles。
這表明 LVP 可能受到 CPU 投機執行流水線的限制,僅能在一定的窗口內繼續執行。
4. LVP 的回滾與錯誤恢復,如果 LVP 預測值錯誤,CPU 需要回滾錯誤的計算結果,並重新執行正確的計算。
(1)錯誤檢測:真實加載值到達後,CPU 會將其與 LVP 預測值進行比較。
如果匹配:則繼續執行,不需要任何修改。
如果不匹配:回滾錯誤計算(類似於投機執行中的錯誤恢復),並重新執行受影響的指令。
(2)回滾機制:LVP 預測錯誤後的回滾機制可能類似於現代 CPU 的投機執行回滾:
ROB(Reorder Buffer)管理 LVP 預測的指令結果。
如果 LVP 預測錯誤,ROB 會 丟棄錯誤的投機計算結果,並重新執行正確的計算。
5. LVP 與其他 CPU 組件的交互
(1)與 L1/L2 緩存的交互:LVP 主要作用於 L1 數據緩存(L1D)訪問,而不會涉及 L2/L3 緩存。只有當 L1D Cache Miss 發生 時,LVP 纔會發揮作用。
(2)與投機執行機制的交互:LVP 預測的值直接參與 CPU 的投機執行流水線,並在最終值到達時進行回滾驗證。
(3)與 DIT(Data Independent Timing)機制的交互:Apple M3 處理器實現的 DIT(數據無關時間) 機制允許用戶態進程關閉 LVP。DIT 機制的啓用不需要高權限,表明 Apple 允許開發者手動控制 LVP 的行爲,以降低安全風險。
6. 改進方向:提高預測範圍和增加安全機制。
總結:Load Value Predictor (LVP) 採用 PC index(索引)+4-way set-asscociative cache(4 路組相聯存儲結構),結合Counter confidence model(計數器置信度模型)進行predict (預測)。LVP 主要優化 L1D 緩存 Miss 導致的 RAW 依賴,但具有嚴格的預測範圍限制,以避免指針泄露。它與 投機執行流水線、DIT 機制以及 CPU 回滾機制緊密集成,在提升 CPU 性能的同時,提供一定的安全保護。
那麼,以上就是我所分享的兩個LSU技術,可以看到,Apple在CPU的積累確實很強,其他家沒有重視的Apple去做了實現,雖然這只是一個很小的技術,對整體u-arch performance能帶來的improve,可能微乎其微,但是,積少成多,造就了目前天花板級別的u-arch,這不是類似物們可以copy到的,平心靜氣好好做architecture不會差的。
作者yy:這篇文章我儘量在用比較通俗易懂的方式進行着講解,如有問題請大佬們多多包涵。
論文引用:
Kim J, Chuang J, Genkin D, et al. FLOP: Breaking the Apple M3 CPU via False Load Output Predictions[J].
Kim J, Genkin D, Yarom Y. SLAP: Data Speculation Attacks via Load Address Prediction on Apple Silicon[J].
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
![任天堂前銷售負責人預判:Switch 2 硬件漲價已成定局[cube_摘墨鏡][cube_摘墨鏡]](https://imgheybox1.max-c.com/bbs/2026/04/05/3b368916849076608f90f840878267fb.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)
















