
各位肯定都遇到過這種情況:
跟 AI 聊着聊着,它突然開始答非所問,明明前面還好好的,怎麼突然就不對勁了。
個別嚴謹一點的同學可能會以爲是自己沒說清楚,於是換個方式再解釋一遍,結果它更離譜了,開始自說自話,完全不在一個頻道上,使用體驗一言難盡。
這種情況在專業領域被稱爲“上下文漂移”(更常見的說法,幻覺),但顯然,出現這種情況不是你的問題,是 AI 的問題。
最近微軟和 Salesforce 的研究人員做了個實驗,發現這個問題比各位想象的嚴重得多。
他們測試了 15 個目前最強的大語言模型,從小體量的 Llama 3.1-8B 到頂級選手 GPT-4.1、Claude、Gemini 2.5 Pro,發現一個驚人的事實:這些模型在多輪對話中的表現,比單次對話差了 39%。
39% 是什麼概念?
就是你本來能拿 90 分的學生,一到考場就只能考 55 分。
而且這還是平均水平,有些模型掉得更狠。
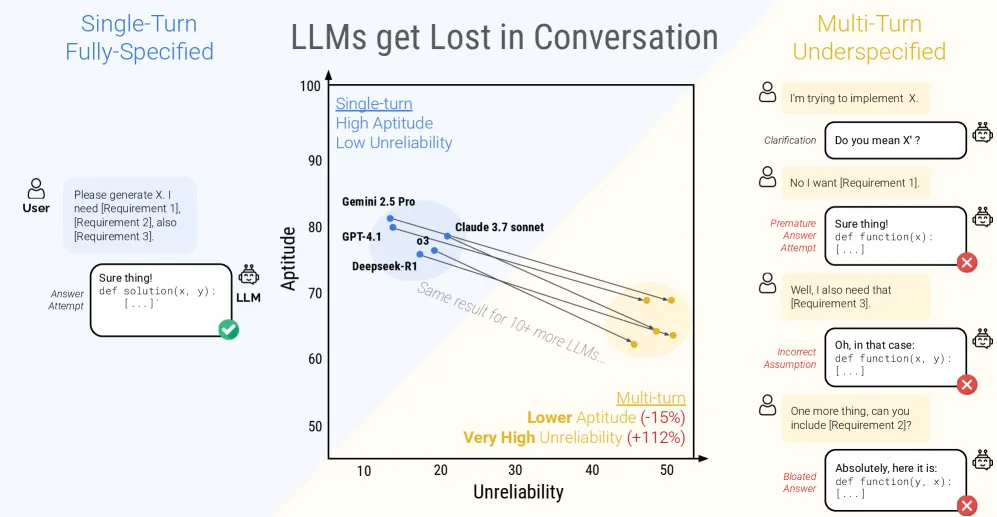
更要命的是,這個問題不分模型大小,也不管你是否開源閉源。哪怕是目前最新最強的那些模型,在多輪對話裏也會大幅翻車。
研究人員模擬了超過 20 萬次對話,發現即便只是兩輪對話,性能就已經開始明顯下降了。
研究人員發現了一個很有意思的現象:這些模型居然會"迷路"。
何意味?(什麼意思呢?)

在對話剛開始的時候,模型會根據你說的話做一些假設,然後就一條路走到黑了。
即使,後面你給了更多信息,它也不會回頭修正自己的判斷,而是繼續沿着錯誤的方向一條路走到黑。
這就像你問路,對方聽了個開頭就覺得你要去火車站,然後不管你後面怎麼補充,他都在給你指去火車站的路。但實際上你要去的是汽車站,不過他已經聽不進去了。
論文裏把這個現象叫做"在對話中迷失"(Get Lost in Conversation)。

聽起來挺詩意,對吧?(我這麼翻譯的所以聽着好聽)但這對用戶來說就是災難。
因爲你根本不知道 AI 什麼時候會突然迷路,它也不知道它已經在錯誤的道路上走了多遠。
更糟糕的是,研究人員發現模型會出現兩種不同的性能下降:
一個是能力下降,就是模型確實變笨了一點;另一個是可靠性暴跌,就是同樣的問題可能給你完全不同的答案。
而後者纔是真正的大問題。
在單輪對話中,能力強的模型通常也比較可靠,比如 GPT-4.1 和 Gemini 2.5 Pro。
但一到多輪對話,所有模型的可靠性都崩了,不管它們原本有多強,這就是所謂的"迷失現象":一旦在對話中走錯了方向,模型就再也回不來了。
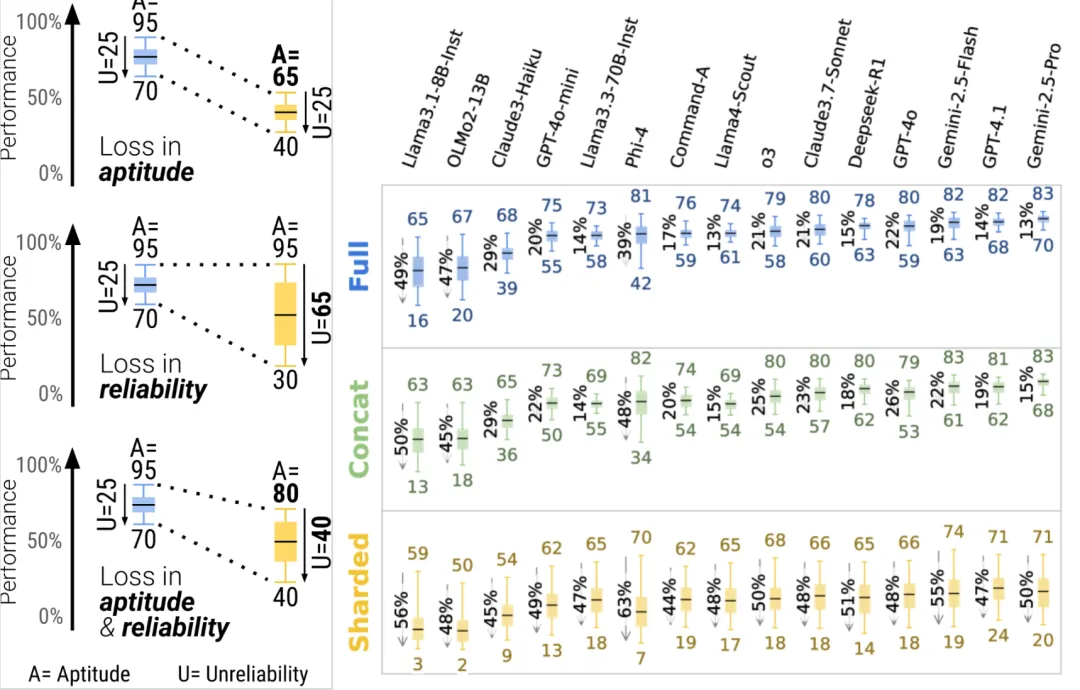
研究人員還深挖了一下,發現模型在多輪對話裏會犯四個典型錯誤:
第一,話太多,回覆特別囉嗦(太棒了,你真是個天才!);
第二,太着急,還沒搞清楚用戶需求就開始給(編)答案;
第三,亂猜測,對不明確的地方自己腦補(你怎麼又引用了個新的函數);
第四,太固執,一旦給了錯誤答案就死咬着不放(你說的對,但是...)。
這幾個問題加在一起,就形成了一個惡性循環:
模型在第一輪對話裏做了錯誤假設,然後基於這個假設給了一個答案,接下來它就會把自己之前的答案當成事實,繼續往下走。
你後面補充再多信息,它也很難跳出這個怪圈了。
研究人員還測試了一些常見的補救措施,比如降低模型的採樣,讓它更保守一點,結果發現基本沒用。該迷路還是迷路,該答錯還是答錯。
唯一有效的辦法是什麼?
重開一個對話。
對,就是這麼簡單粗暴。
當你發現 AI 開始答非所問的時候,最好的辦法就是把之前的需求總結一下,然後開個新對話窗口,把完整的需求一次性說清楚。
這樣模型就不會在中途做錯誤假設了。
但,這也太蠢了吧?
我們花了這麼多年研究多輪對話,搞什麼上下文理解、記憶機制,結果最後發現最靠譜的方法還是重啓?

這就是目前的現實。
那些宣傳自己能長時間對話、深度理解上下文的 AI 產品,其實都在走鋼絲。
對話輪次越多,出錯的概率就越大。
而且更糟糕的是,模型出錯的時候往往還很自信,不會告訴你"我可能理解錯了",而會一本正經地給你錯誤答案。(當然,看模型,某模型:天吶,你真是天才,居然發現了這是錯的!)
有意思的是,研究人員發現在某些特定任務上,比如寫 Python 代碼,模型的表現會稍微好一點,可能是因爲代碼任務的結構比較清晰,不容易產生歧義。
但即便如此,性能下降依然存在,只是沒那麼誇張而已。
它們在單輪對話裏表現好,是因爲所有信息都在眼前,可以一次性處理。但一旦信息分散在多個回合裏,它們就開始手忙腳亂,不知道該優先考慮哪些信息,也不知道什麼時候該推翻之前的假設。

這對那些想用 AI 做複雜任務的人來說,是個壞消息。
因爲真實世界裏的需求,很少能一次性說清楚,你總是需要補充、修正、調整,這就必然涉及多輪對話。
但現在看來,多輪對話恰恰是這些模型的軟肋。
更有趣的是,很多 AI 產品還在拼命強調自己的多輪對話能力,說自己能像人一樣自然交流。但這個研究告訴我們,它們的軟肋其實就是多輪對話,自然,真正的自然交流也就無從談起。
當然,這不是說 AI 沒用,在單輪任務上,這些模型依然很強大——如果你能把需求整理清楚,一次性輸入,它們還是能給你不錯的結果。
問題是,這對用戶的要求太高了。
你得學會怎麼正確地跟 AI 說話,怎麼組織信息,怎麼避免讓它"迷路"。
研究人員在論文裏也承認,多輪對話的可靠性問題,是目前制約前沿模型實際應用的主要瓶頸,在這個問題解決之前,那些關於AI 助手、純 AI 代理的美好願景,可能都得打個折扣。
(例如現在大火的 OpenClaw 也是有專門的記憶文件來存儲能力列表、對話風格等,來方便其在使用中隨時記憶想起,而不是直接將這些存在對話框中)
所以下次當你跟 AI 聊天聊得不順利的時候,你就要知道是怎麼一回事。
這大概率不是你表達有問題,是 AI 已經在對話裏迷路了,這時候最好的辦法,就是果斷結束對話,然後重新開始。

雖然這聽起來很蠢,但目前來看,這就是最靠譜的解決方案。
至於那些號稱能無限對話、完美理解上下文的 AI 產品,你可以試試跟它們聊個幾十上百輪,看看它們還能不能保持清醒。
根據這個研究,答案可能會讓你失望。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















