
昨天,智譜和 MiniMax 同臺競技的畫面太猛,國產大模型的春節檔剛剛降溫,很多人還在回味。
今天,硅谷的 Google 也來湊熱鬧,端出了 Gemini 3 Deep Think 的升級版。

這次並非常規迭代。
谷歌單獨爲科學研究與工程場景強化了Deep Think推理模式,目標直指高強度抽象思考能力,也代表了 Google AI 在當下最強的智力水平。
通俗點講,他們把重心壓在了硬核智力活上。
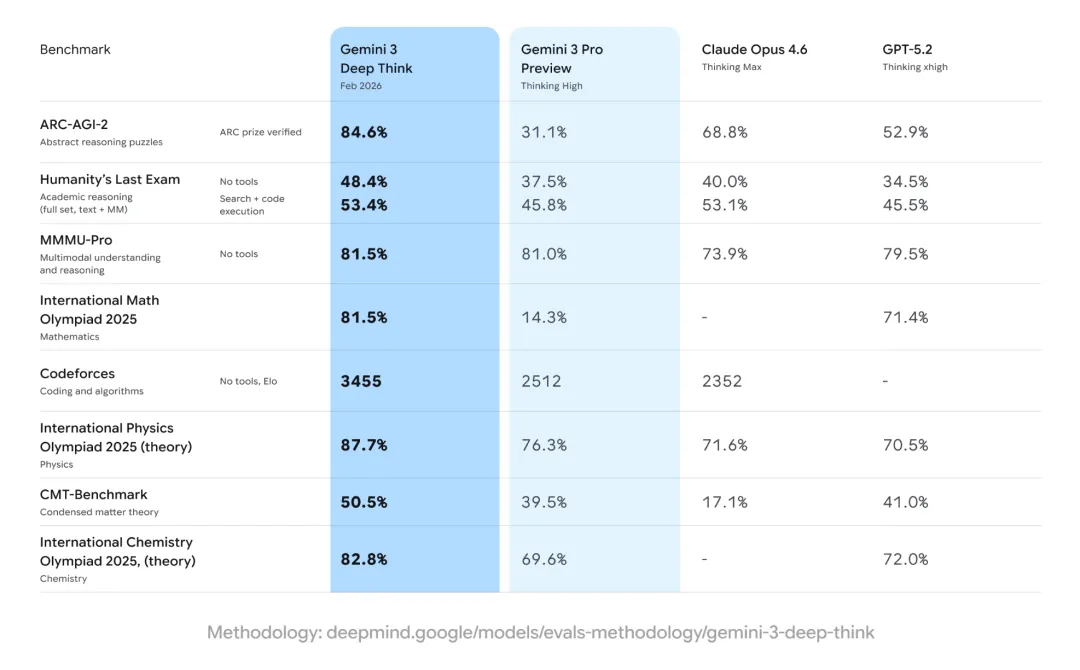
例如 ARC-AGI-2,在這個基準專測抽象推理,被很多人視作接近通用智能門檻的測試場。
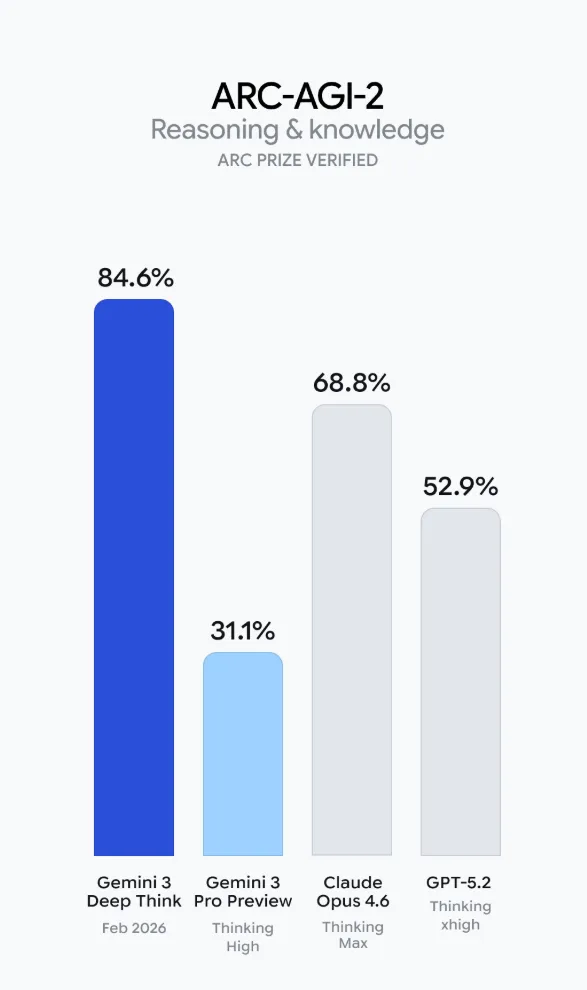
此前,Gemini 3 Pro Preview 只有 31.1%,這次 Deep Think 直接衝到 84.6%。
對比之下,Claude Opus 4.6 Thinking Max 爲 68.8%,GPT-5.2 Thinking xhigh 僅 52.9%。
差距一目瞭然,ARC Prize 基金會出面確認成績,谷歌高層在社交平臺連發動態,話題迅速升溫。
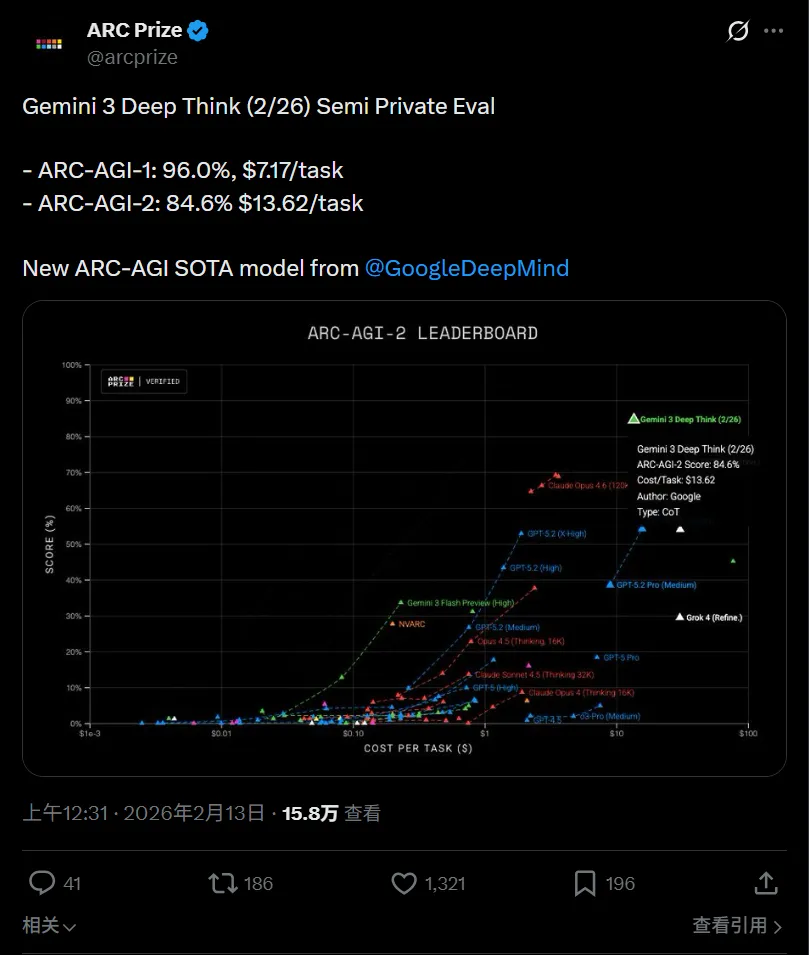
榜單也同步刷新。
在被稱作“人類最後一場考試”的 Humanity’s Last Exam 中,Deep Think 在無外部工具條件下拿到 48.4%;競技編程平臺 Codeforces 上 Elo 達到 3455,已是頂級選手區間。
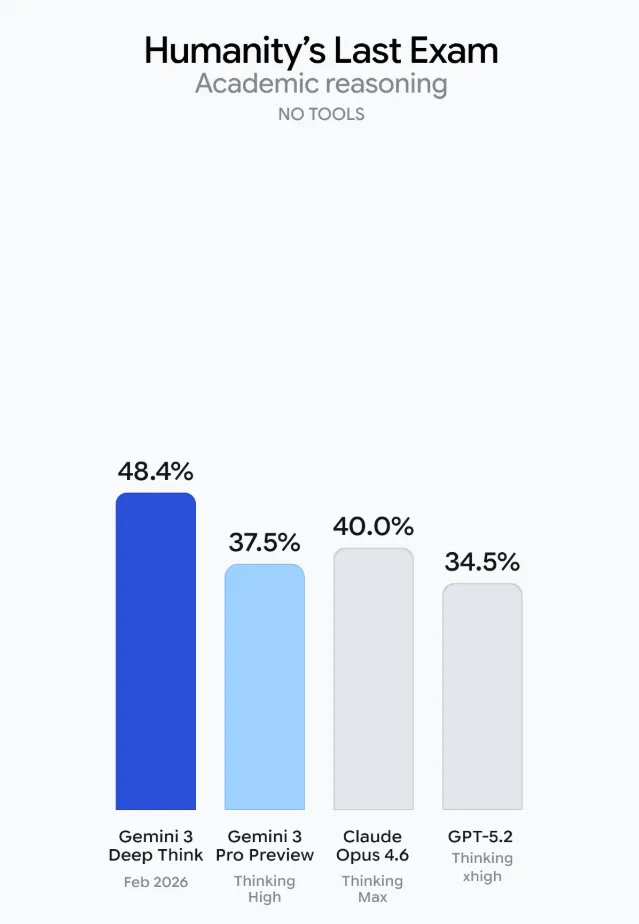
其實在更早的 2025 年,Deep Think 早期版本就達到 IMO 金牌水準,這次升級將並行假設探索能力打磨得更成熟,面對無標準答案的問題依舊穩定推進。
實戰案例也有,Rutgers University 研究人員用它複審高能物理論文,AI 找出了人類同行評審遺漏的邏輯漏洞;Duke University 實驗室藉助它優化 100 微米薄膜晶體生長方案。
還有手繪草圖生成 3D 可打印模型、複雜物理系統建模等能力,也在展示清單之列,,這些應用讓“跑分機器”的質疑聲弱了不少。
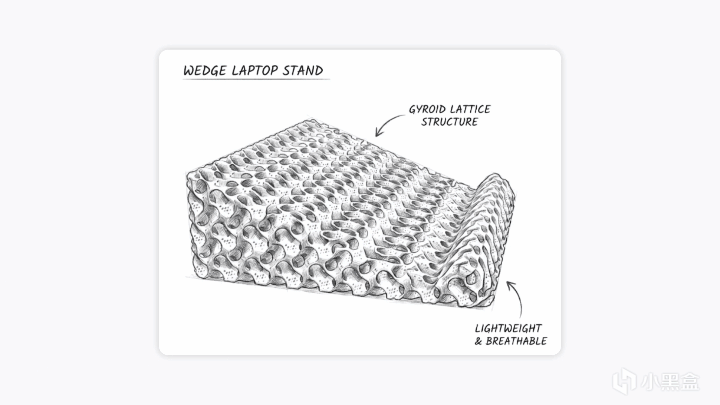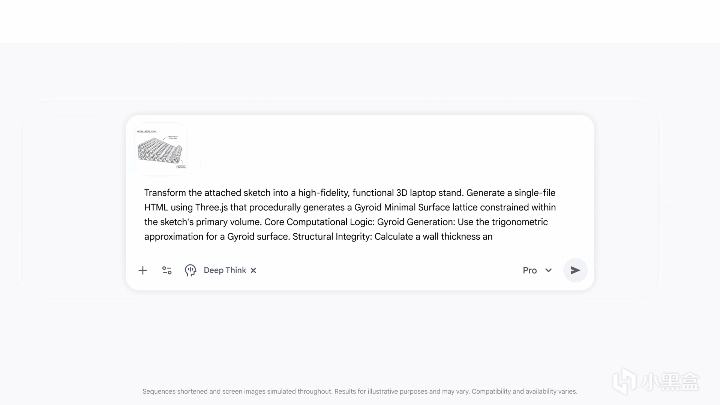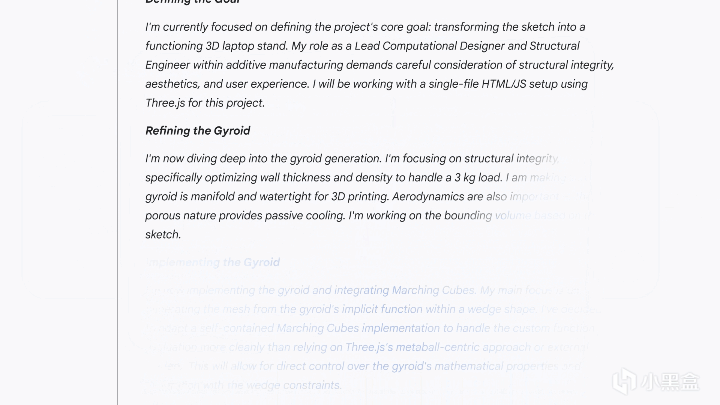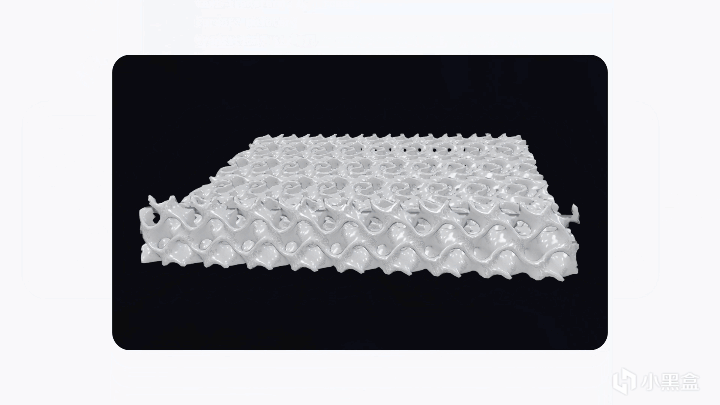
不過這裏也有一個問題——大模型不斷延長思考時間,依賴更高效的並行推理與算力調度換取邏輯深度,這條路徑還能走多遠?
當前躍升顯然建立在規模化算力與算法協同優化之上,短期優勢明顯,長期邊界仍待觀察。
科研輔助、算法工程、部分高階分析崗位都會承壓,效率紅利與職業衝擊並行出現。
和更現實的問題:訪問門檻。
頂級能力集中在少數巨頭手中,API 申請雖已開放,篩選機制依舊嚴格。
技術加速科學進步的同時,也可能擴大資源差距,誰能調用這套深度思考,誰就有機會擁有某種更高的起點。
谷歌在這次春節檔用成績單再一次展示了自己的實力,領先已經擺在檯面,競爭不會停。
至於這是階段性優勢,還是更長週期的結構性領先,時間會給答案(畢竟DeepSeek 還沒發模型)。
讓我們繼續繼續拭目以待。
最後,也提前預祝各位讀者,春節愉快。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














