
昨天,智谱和 MiniMax 同台竞技的画面太猛,国产大模型的春节档刚刚降温,很多人还在回味。
今天,硅谷的 Google 也来凑热闹,端出了 Gemini 3 Deep Think 的升级版。

这次并非常规迭代。
谷歌单独为科学研究与工程场景强化了Deep Think推理模式,目标直指高强度抽象思考能力,也代表了 Google AI 在当下最强的智力水平。
通俗点讲,他们把重心压在了硬核智力活上。
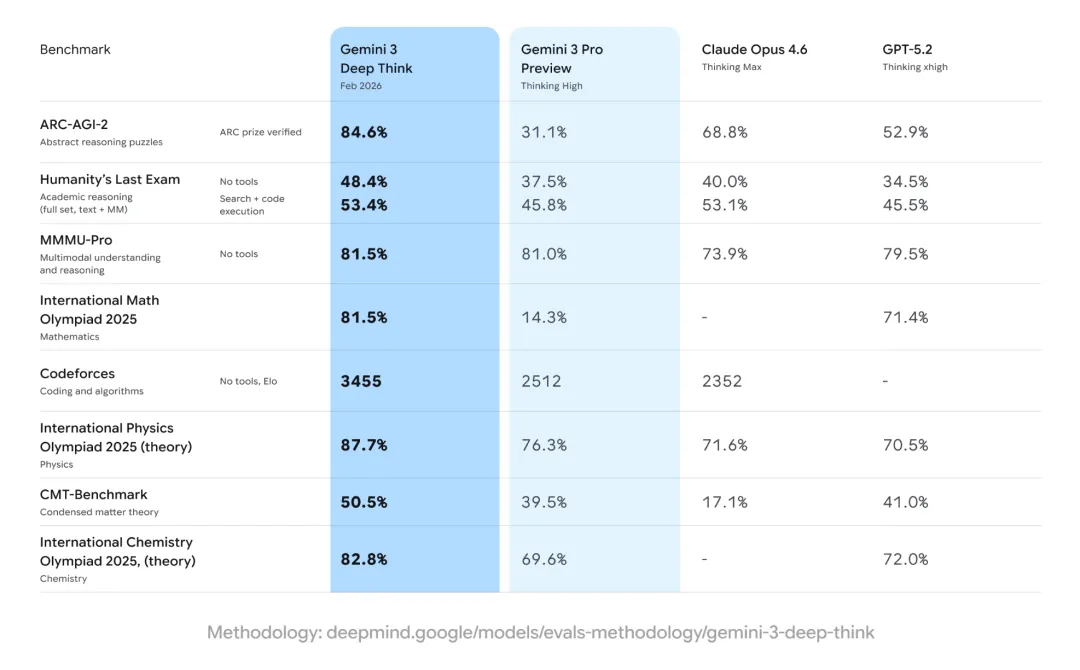
例如 ARC-AGI-2,在这个基准专测抽象推理,被很多人视作接近通用智能门槛的测试场。
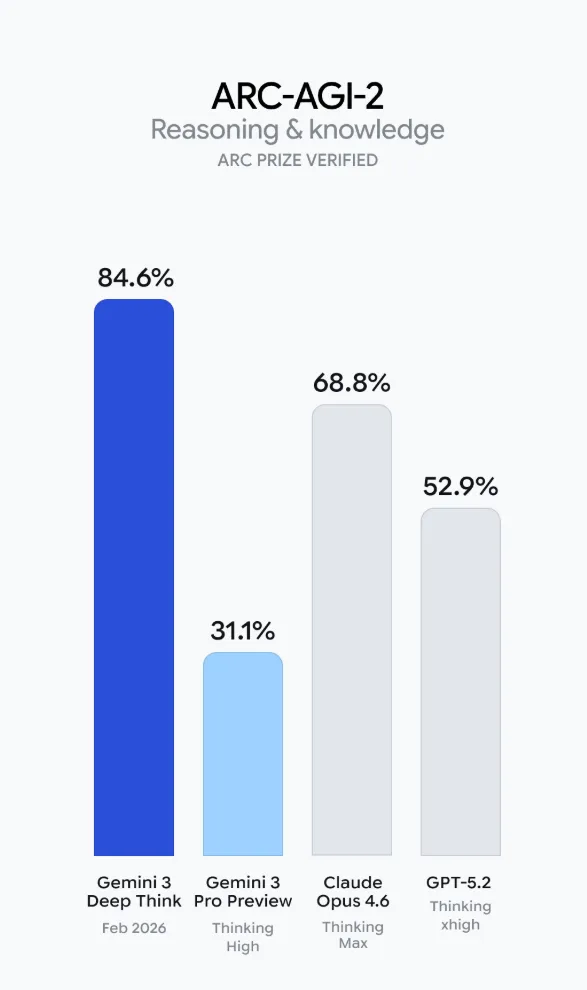
此前,Gemini 3 Pro Preview 只有 31.1%,这次 Deep Think 直接冲到 84.6%。
对比之下,Claude Opus 4.6 Thinking Max 为 68.8%,GPT-5.2 Thinking xhigh 仅 52.9%。
差距一目了然,ARC Prize 基金会出面确认成绩,谷歌高层在社交平台连发动态,话题迅速升温。
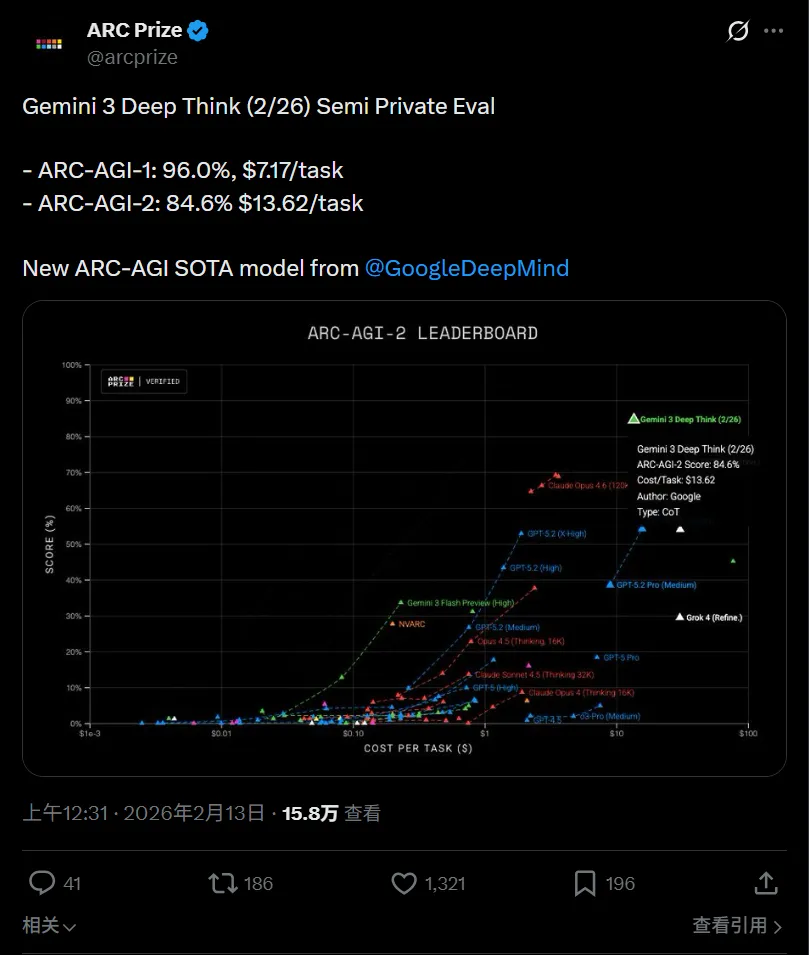
榜单也同步刷新。
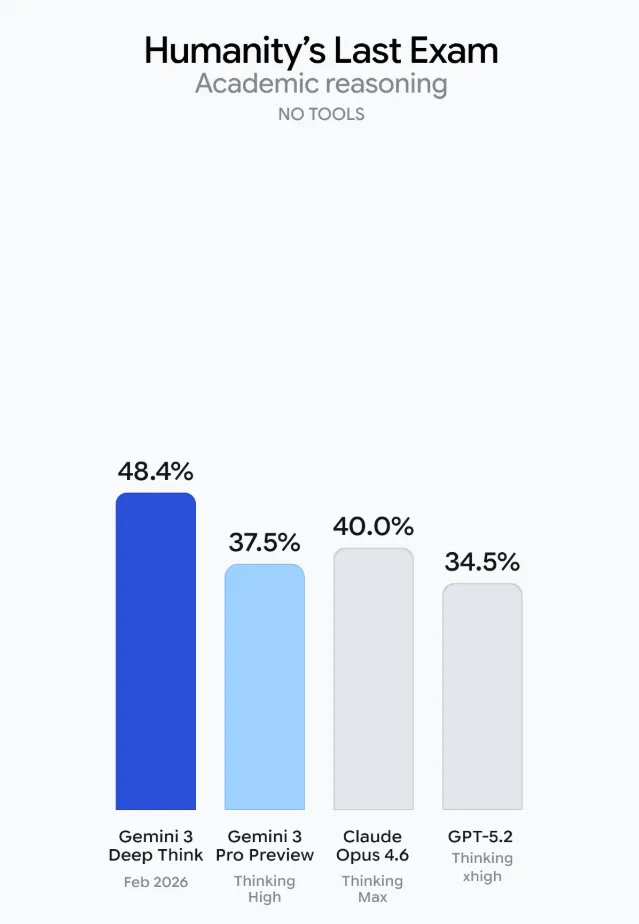
在被称作“人类最后一场考试”的 Humanity’s Last Exam 中,Deep Think 在无外部工具条件下拿到 48.4%;竞技编程平台 Codeforces 上 Elo 达到 3455,已是顶级选手区间。
其实在更早的 2025 年,Deep Think 早期版本就达到 IMO 金牌水准,这次升级将并行假设探索能力打磨得更成熟,面对无标准答案的问题依旧稳定推进。
实战案例也有,Rutgers University 研究人员用它复审高能物理论文,AI 找出了人类同行评审遗漏的逻辑漏洞;Duke University 实验室借助它优化 100 微米薄膜晶体生长方案。
还有手绘草图生成 3D 可打印模型、复杂物理系统建模等能力,也在展示清单之列,,这些应用让“跑分机器”的质疑声弱了不少。
不过这里也有一个问题——大模型不断延长思考时间,依赖更高效的并行推理与算力调度换取逻辑深度,这条路径还能走多远?
当前跃升显然建立在规模化算力与算法协同优化之上,短期优势明显,长期边界仍待观察。
科研辅助、算法工程、部分高阶分析岗位都会承压,效率红利与职业冲击并行出现。
和更现实的问题:访问门槛。
顶级能力集中在少数巨头手中,API 申请虽已开放,筛选机制依旧严格。
技术加速科学进步的同时,也可能扩大资源差距,谁能调用这套深度思考,谁就有机会拥有某种更高的起点。
谷歌在这次春节档用成绩单再一次展示了自己的实力,领先已经摆在台面,竞争不会停。
至于这是阶段性优势,还是更长周期的结构性领先,时间会给答案(毕竟DeepSeek 还没发模型)。
让我们继续继续拭目以待。
最后,也提前预祝各位读者,春节愉快。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com









![小红书起号干货喂饭教程(真焚决👍)[穿搭分享]](https://imgheybox1.max-c.com/bbs/2026/04/07/0274f95c4bd4bc3bbd267bea322c2cf1.webp?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)




