本文是“遊戲論文速遞“系列的一部分。
系列介紹:https://api.xiaoheihe.cn/v3/bbs/app/api/web/share?h_camp=link&h_src=YXBwX3NoYXJl&link_id=8c847162cc64
內容速通:
自然語言+AI+RTS:新技術和老遊戲類型會碰出怎樣的火花?
這個bot怎麼像真人一樣菜?我們要的是開掛一樣強的bot,還是一個像人一樣有趣的陪練。
用密室解密遊戲測性格:用“遊戲行爲”規避“在問卷裏裝好人”。
本期涉及論文來源於IEEE遊戲彙刊(IEEE Transactions on Games) 第17卷 第4期 2025年12月出版
1.自然語言+AI+RTS:新技術和老遊戲類型會碰出怎樣的火花?
涉及遊戲:研究團隊自研RTS
研究速覽:
要問大家RTS中最難的部分是什麼?可能大部分的回答都是每分鐘數百次的微操。
這項研究提出了一個叫“大規模交戰混合智能”(HIVE)的框架,可以玩家用自然語言指揮最多2000個單位。
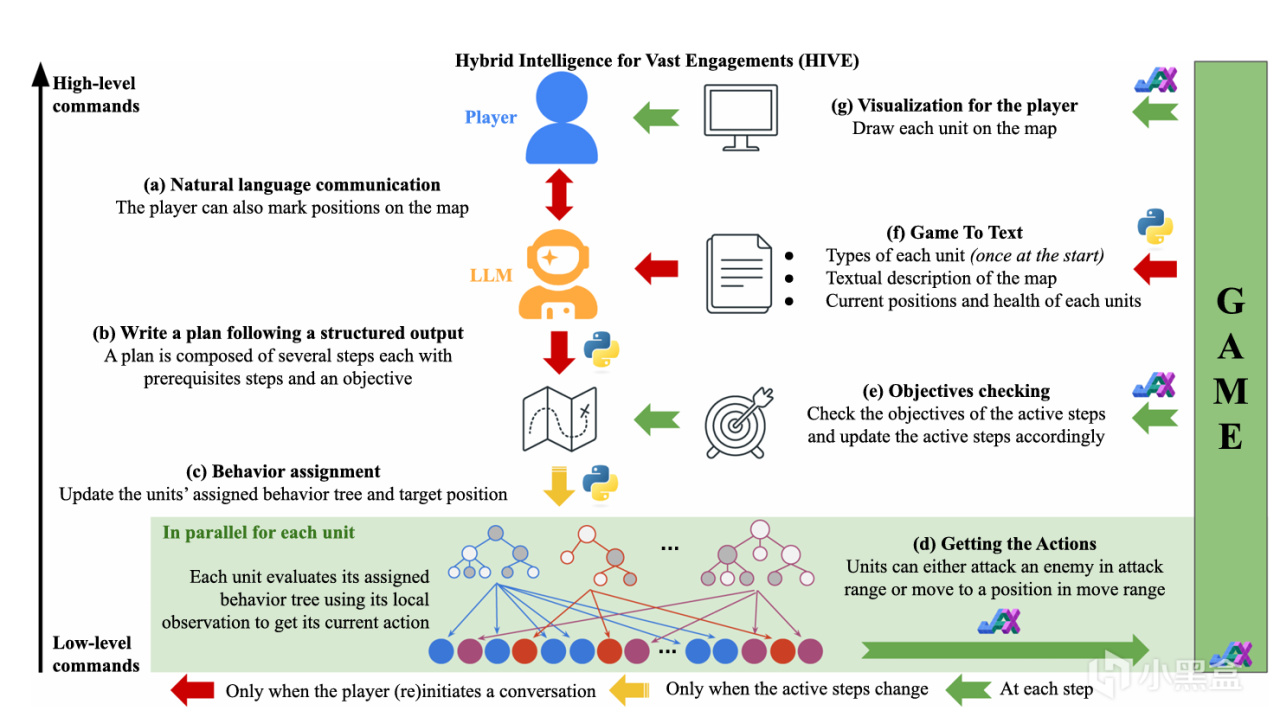
不同於以往還要手忙腳亂地編隊、拉扯,在HIVE裏,你只需要輸入“分兵去堵橋,每個橋上三個坦克十個步兵”,AI就會自動將其轉化爲具體的戰術計劃,並分配給每一個單位執行。
研究者設計了一個包含防禦、進攻、兵種剋制(如騎兵克弓箭手)的RTS基準測試。
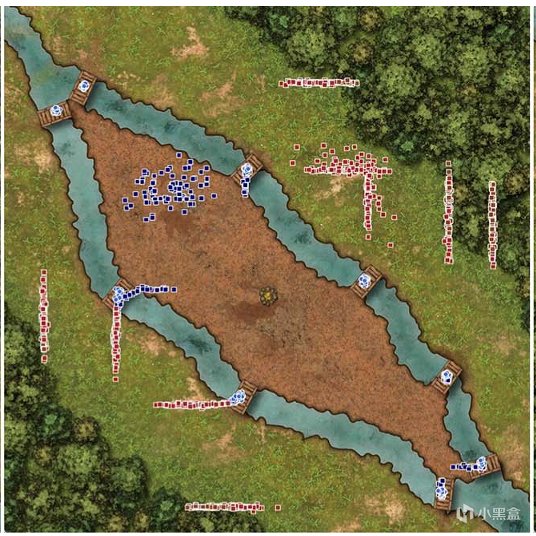
結果顯示,模型確實能把自然語言轉化成羣體調度方案,但缺點也很明顯:空間-視覺信息處理喫力、長線戰略規劃不穩、對輸入表達方式很敏感。
偶爾會出現描述不完全準確但執行還湊合能贏的情況。整體更像“你當元帥,模型當參謀”,而不是全自動代打。
我的評價:
機槍陣地右移五米!
中文標題:利用語言實現協同:一個LLM驅動的多智能體控制框架與基準
原標題:Harnessing Language for Coordination: A Framework and Benchmark for LLM-Driven Multiagent Control
發表時間:2025年12月
2. 這個bot怎麼像真人一樣菜?我們要的是開掛一樣強的bot,還是一個像人一樣有趣的陪練
涉及遊戲:
研究速覽:
學術界開發bot總是奔着“強”,但是實際中游戲對bot的需求是“更似人”,而且對算力要求不能太高,延遲需要足夠小。
這個研究就是針對這個問題的。
研究使用少量射線投射(ray-cast)代替學術界常用的投餵每幀的畫面,爲bot構建了一個輕量的感知架構。

在訓練上採用模仿學習、監督學習方式,用人類軌跡數據讓模型學人怎麼走位、怎麼反應。
評估上也不只看勝率,而是還看性能、推理耗時,以及類似圖靈測試的“讓玩家看錄像,評估打的像不像真人”,還用行爲分佈/熱力圖等角度檢查風格相似度。
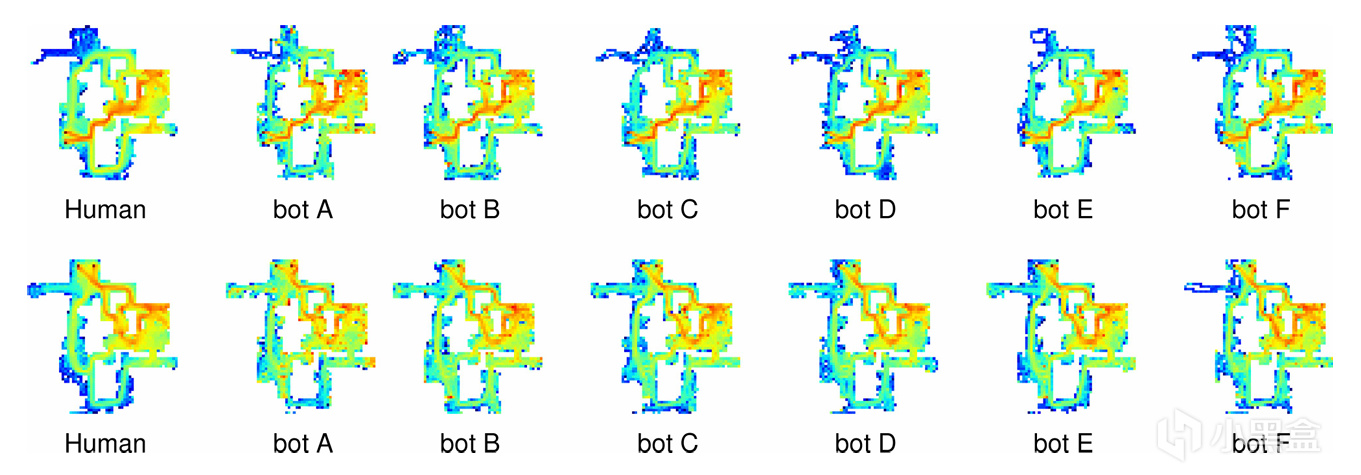
結論很明確:在有限的算力條件下,這個bot能做出更像人類、更照顧玩家體驗的行爲。這條路線或許在掉線補位、訓練賽陪練這些情景下更有用。
我的評價:
好消息:bot學會像我一樣描邊了。
壞消息:bot跟我一隊。
中文標題:使用計算高效傳感器的戰術射擊遊戲擬人化Bot
原標題:Human-Like Bots for Tactical Shooters Using Compute-Efficient Sensors
發表時間:2025年12月
3. 用密室解密遊戲測性格:用“遊戲行爲”規避“在問卷裏裝好人”
涉及遊戲:團隊自研解密遊戲
研究速覽:
性格測試一直是互聯網上的廣受討論的熱點。但是這篇文章的作者認爲大家填問卷測試的時候都太裝了。測出來的是你心裏你的樣子,而不是你實際的樣子。
所以作者把性格測評塞進了一個密室逃脫遊戲裏,按照玩家的解謎節奏、探索傾向、與NPC互動等行爲,用AI預測 OCEAN 五大人格(開放性、盡責性、外向性、宜人性、神經質)。
難點在於訓練數據:要做監督學習就得有大量帶標籤的數據,僱人玩他們的遊戲來收集訓練集又貴又慢。
於是他們先用有預定義性格的AI去模擬不同性格玩家的玩法,用真人玩家與AI玩法的相似度做性格測試判斷指標。
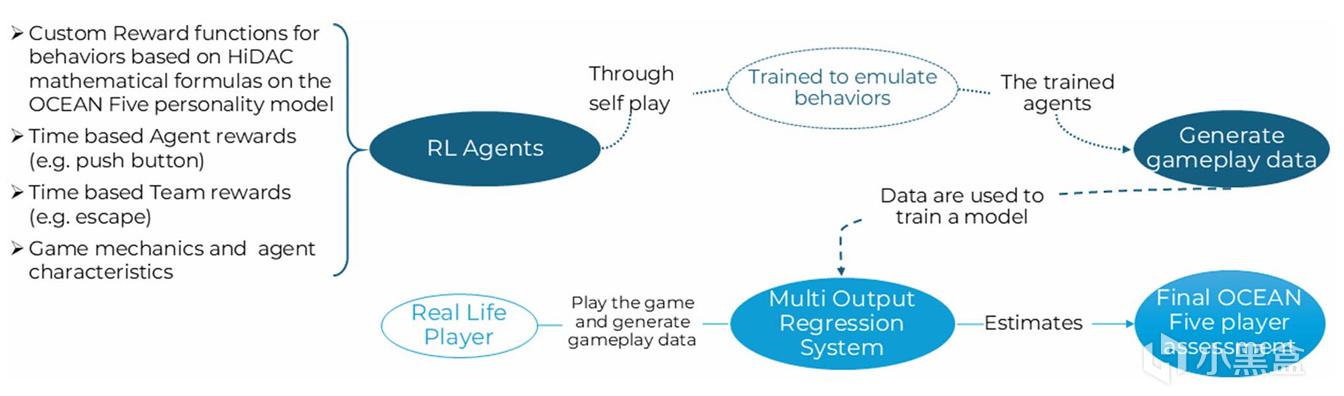
實驗表明,在希臘和意大利的學生樣本中,遊戲推斷的人格畫像與問卷測試結果有較強相關性。說明用玩遊戲測試人格至少在技術路徑上跑通了。
我的評價:
你填問卷時可能連自己都騙過去了,但是你玩遊戲時顫抖是視野已經證明了你是一個玩遊戲手喜歡抖的人。
中文標題:在遊戲環境中使用人工智能的人格評估系統
原標題:Personality Assessment System Using Artificial Intelligence in a Game Environment
發表時間:2025年12月
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















