今天有小夥伴給我說又發現了一個新的類似於 AutoGLM 的項目,我其實並沒有太大的情緒波動的。

去年下半年(是的,歡迎來到2026)“智能體 + GUI 自動化”相關的項目實在太多了,展示階段一個比一個流暢,真要落到實際使用裏,往往很快就會暴露出邊界以及各種各樣的問題(比如豆包手機慘遭封殺)。
很符合我對未來得幻想,這泰褲了,不是嗎?

看得多了,自然會多一層保留。
MAI-UI 給我的第一感受,是它在界定問題時顯得比較剋制。項目整體傳遞出的信號很明確:它關注的並不是“讓模型看起來更聰明”,而是嘗試回答一個更具體的問題——模型究竟該如何理解 GUI 這個複雜且充滿干擾項的環境。(同時其模型還做到了SOTA!)
這個切入點,本身就值得單獨聊一聊,我們先說一個再常見不過的場景。
老婆發消息:記得去盒馬買之前我給你說過的東西,你應該在備忘錄記了吧?
這句話對人來說幾乎不需要解釋,但對系統來說,全是未顯式表達的信息。
買啥東西?
備忘錄?什麼備忘錄?
什麼是盒馬?怎麼去盒馬買東西?
MAI-UI 想處理的,正是這種人類默認共識很多、但機器完全缺乏背景的中間地帶。
User instruction: 去盒馬買菜,買一份雪花牛肉卷、一份娃娃菜、一份金針菇,再隨便買一個豆製品。對了,去日曆中待辦裏檢查下我老婆有什麼要在盒馬買的,我確認下要不要一起買。
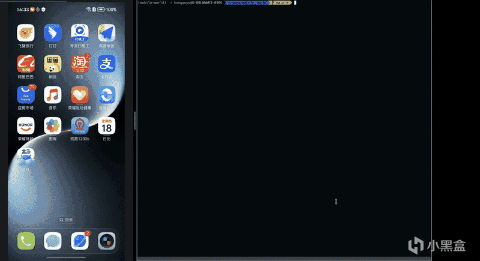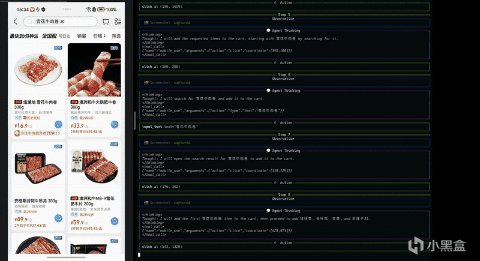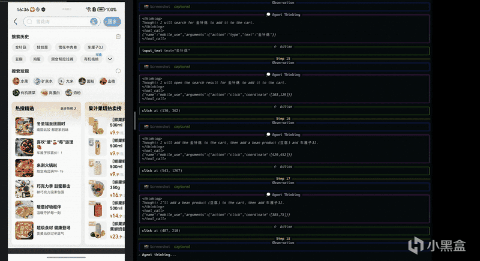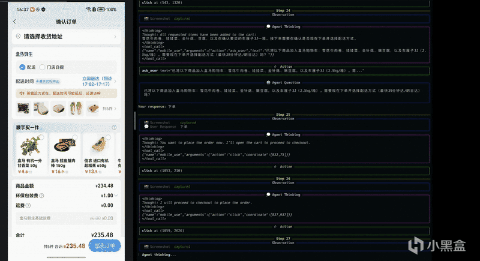
其實它得工作方式並不複雜,還是“自然語言指令 - 當前界面的截圖 - 判斷當前界面元素、狀態 - 決定下一步動作”這一過程,整個過程強調的是對界面的理解與推理,而非執行一條預先寫死的操作路徑。
這一點在 UI 自動化語境下非常重要。
在傳統自動化方案裏,這些工具對界面變化是十分敏感的,按鈕稍微換個位置、文案改一行,流程就可能直接失效。MAI-UI 的關注點明顯不在“位置”,而在“語義”:界面當前在表達什麼、允許做什麼。
另一個讓我覺得比較理性的設計,是它對不確定性的處理方式。
不少自動化系統一旦做出判斷,就會直接執行到底,中途幾乎不留迴旋空間。MAI-UI 在指令存在歧義時,會選擇停下來確認。這種行爲並不新鮮,但在智能體系統中並不常見。
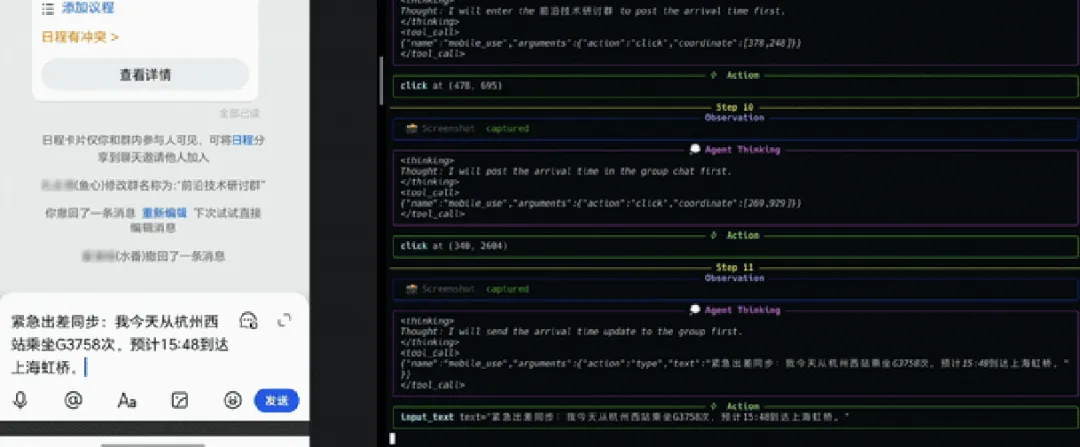
比如“把行程計劃發給大家”這樣的指令,系統可能會確認發送範圍,是羣裏所有人,還是隻包括核心成員。這個細節本身並不驚豔,卻很貼近真實使用環境,也減少了誤操作的風險。
從這個角度看,MAI-UI 並沒有試圖迴避一個事實:
理解人類語言,本身就存在不確定性。
它在設計上承認這一點,而不是假設模型總能給出正確解讀,這種態度至少是務實的。
當然,MAI-UI 的能力並不只停留在界面操作層面。
項目中引入了 MCP 的工具調用機制,在合適的情況下,系統可以直接調用接口或工具完成任務,而不是強行在 GUI 裏模擬人類操作。這讓執行路徑更短,也降低了對界面穩定性的依賴。

這個選擇明顯偏工程取向:不追求“像人一樣點”,優先考慮效率和可控性。對真實系統來說,這樣的取捨通常比視覺上的擬人更重要。
此外,端雲協同的設計也值得一提。並非所有判斷都交給雲端模型處理,一些簡單邏輯在本地完成,複雜推理再交由雲端。這種拆分在成本、延遲和穩定性上都更現實。
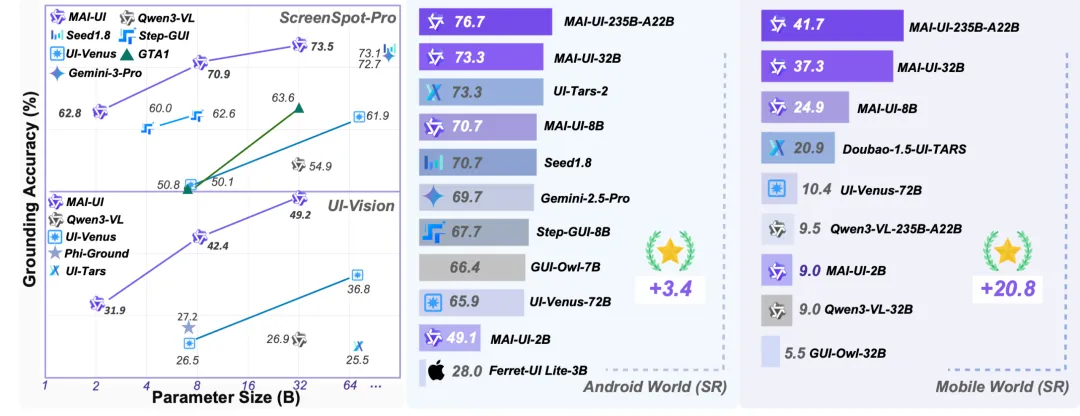
目前從其公開信息來看,MAI-UI 在 ScreenSpot-Pro、AndroidWorld 等 GUI 理解與移動端任務 benchmark 中的表現相對靠前,至少可以再次確認,它並非只是在演示demo裏成立。
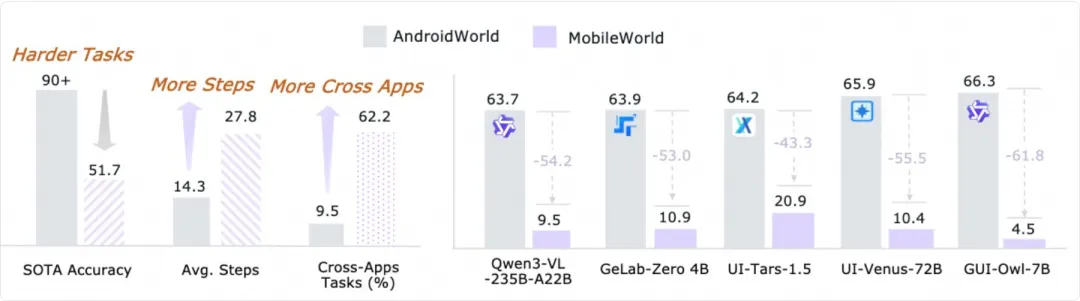
當然,demo 並不等同於真實複雜環境,這一點需要保持清醒。
模型方面,項目提供了從 2B 到 235B 的不同體量選擇,其中 2B 和 8B 開源(阿里:想玩更強的?自己搓/用我們的吧),同時也給出了較完整的部署與使用說明。對感興趣的人而言,這至少意味着項目不是停留在論文階段,想實際跑一跑試試也不算多難。
說到這裏,其實沒必要急着給 MAI-UI 下什麼宏大的結論。
它並不能立刻改變人機交互的形態,也距離“人人可用”還有不少工程工作要做(跟豆包手機甚至是AutoGLM比其實都差得不少)。但如果把視角收緊一些,只看它試圖解決的問題和採取的路徑,這個項目的定位是清晰的,也相對務實。
它沒有把 GUI 簡化成一堆座標,也沒有把智能體想象成萬能執行者,而是嘗試在理解、推理和執行之間找到一個可持續的平衡點。
對於關注智能體、自動化,或者已經被重複界面操作消耗耐心的人來說,MAI-UI 至少值得被放進觀察名單裏。
不一定現在就用,但值得持續關注它接下來會怎麼走。

我是CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















