今天有小伙伴给我说又发现了一个新的类似于 AutoGLM 的项目,我其实并没有太大的情绪波动的。

去年下半年(是的,欢迎来到2026)“智能体 + GUI 自动化”相关的项目实在太多了,展示阶段一个比一个流畅,真要落到实际使用里,往往很快就会暴露出边界以及各种各样的问题(比如豆包手机惨遭封杀)。
很符合我对未来得幻想,这泰裤了,不是吗?

看得多了,自然会多一层保留。
MAI-UI 给我的第一感受,是它在界定问题时显得比较克制。项目整体传递出的信号很明确:它关注的并不是“让模型看起来更聪明”,而是尝试回答一个更具体的问题——模型究竟该如何理解 GUI 这个复杂且充满干扰项的环境。(同时其模型还做到了SOTA!)
这个切入点,本身就值得单独聊一聊,我们先说一个再常见不过的场景。
老婆发消息:记得去盒马买之前我给你说过的东西,你应该在备忘录记了吧?
这句话对人来说几乎不需要解释,但对系统来说,全是未显式表达的信息。
买啥东西?
备忘录?什么备忘录?
什么是盒马?怎么去盒马买东西?
MAI-UI 想处理的,正是这种人类默认共识很多、但机器完全缺乏背景的中间地带。
User instruction: 去盒马买菜,买一份雪花牛肉卷、一份娃娃菜、一份金针菇,再随便买一个豆制品。对了,去日历中待办里检查下我老婆有什么要在盒马买的,我确认下要不要一起买。
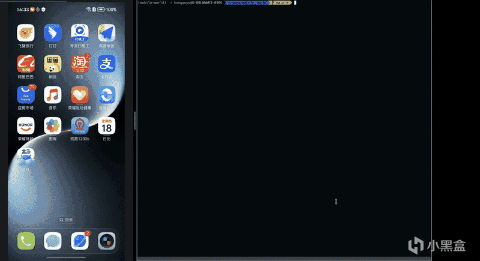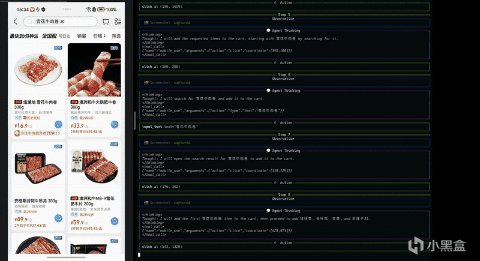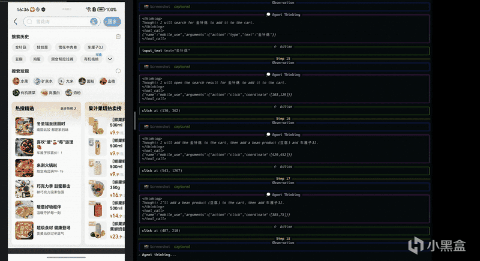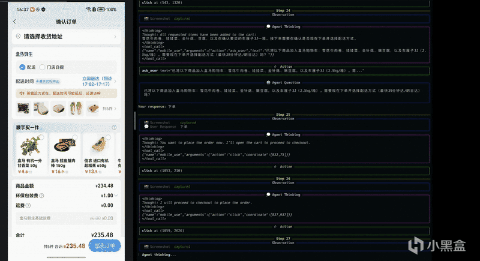
其实它得工作方式并不复杂,还是“自然语言指令 - 当前界面的截图 - 判断当前界面元素、状态 - 决定下一步动作”这一过程,整个过程强调的是对界面的理解与推理,而非执行一条预先写死的操作路径。
这一点在 UI 自动化语境下非常重要。
在传统自动化方案里,这些工具对界面变化是十分敏感的,按钮稍微换个位置、文案改一行,流程就可能直接失效。MAI-UI 的关注点明显不在“位置”,而在“语义”:界面当前在表达什么、允许做什么。
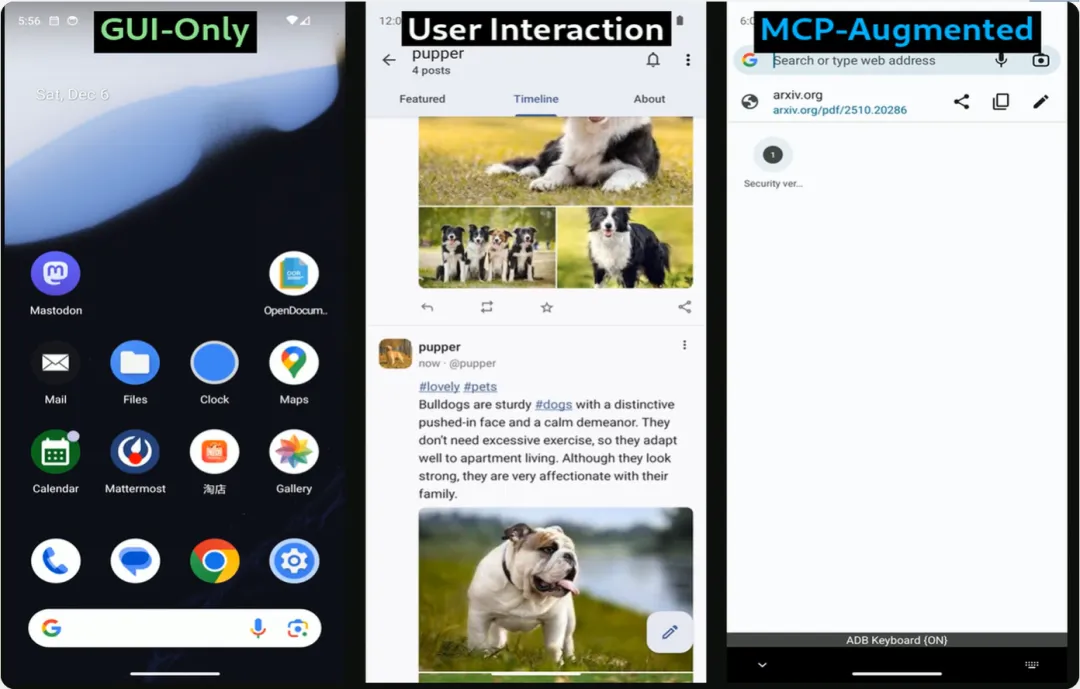
另一个让我觉得比较理性的设计,是它对不确定性的处理方式。
不少自动化系统一旦做出判断,就会直接执行到底,中途几乎不留回旋空间。MAI-UI 在指令存在歧义时,会选择停下来确认。这种行为并不新鲜,但在智能体系统中并不常见。
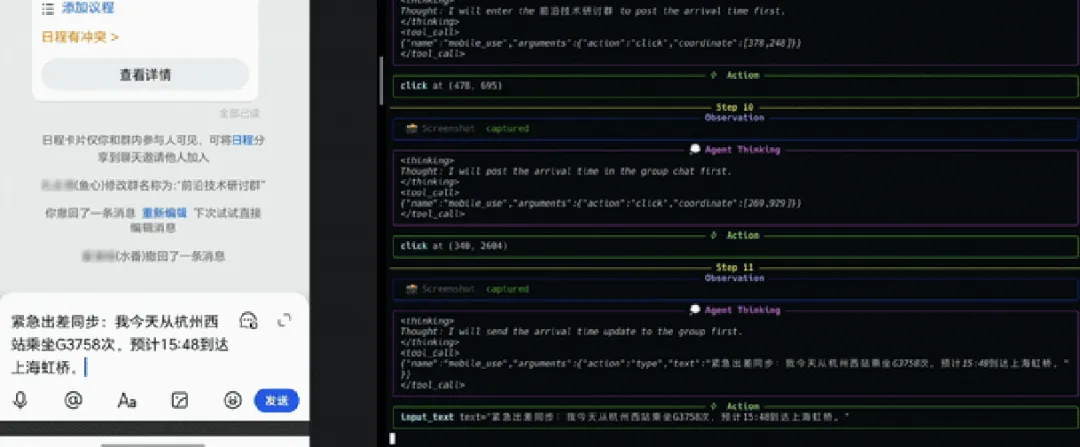
比如“把行程计划发给大家”这样的指令,系统可能会确认发送范围,是群里所有人,还是只包括核心成员。这个细节本身并不惊艳,却很贴近真实使用环境,也减少了误操作的风险。
从这个角度看,MAI-UI 并没有试图回避一个事实:
理解人类语言,本身就存在不确定性。
它在设计上承认这一点,而不是假设模型总能给出正确解读,这种态度至少是务实的。
当然,MAI-UI 的能力并不只停留在界面操作层面。
项目中引入了 MCP 的工具调用机制,在合适的情况下,系统可以直接调用接口或工具完成任务,而不是强行在 GUI 里模拟人类操作。这让执行路径更短,也降低了对界面稳定性的依赖。

这个选择明显偏工程取向:不追求“像人一样点”,优先考虑效率和可控性。对真实系统来说,这样的取舍通常比视觉上的拟人更重要。
此外,端云协同的设计也值得一提。并非所有判断都交给云端模型处理,一些简单逻辑在本地完成,复杂推理再交由云端。这种拆分在成本、延迟和稳定性上都更现实。
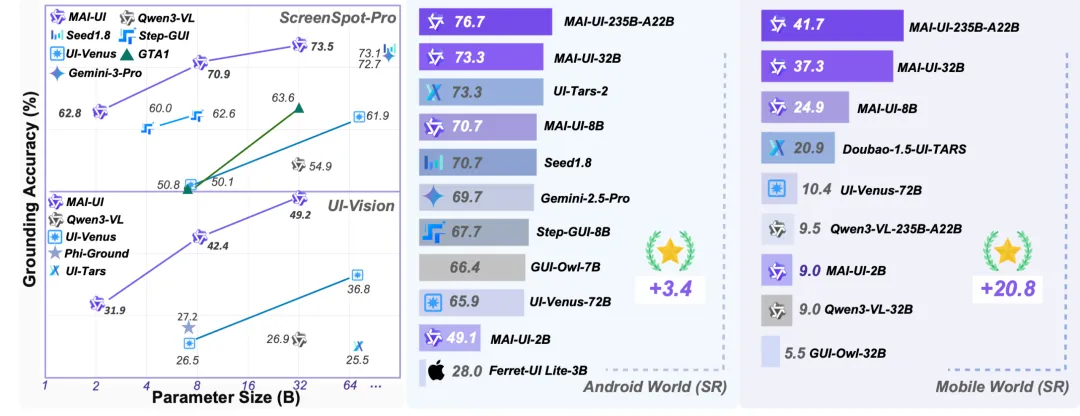
目前从其公开信息来看,MAI-UI 在 ScreenSpot-Pro、AndroidWorld 等 GUI 理解与移动端任务 benchmark 中的表现相对靠前,至少可以再次确认,它并非只是在演示demo里成立。
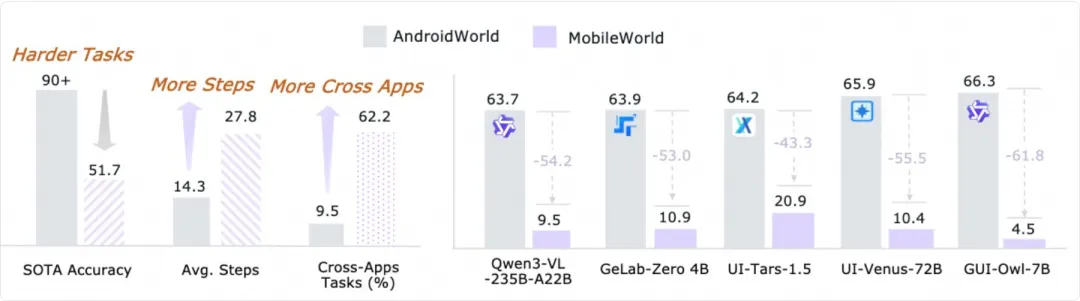
当然,demo 并不等同于真实复杂环境,这一点需要保持清醒。
模型方面,项目提供了从 2B 到 235B 的不同体量选择,其中 2B 和 8B 开源(阿里:想玩更强的?自己搓/用我们的吧),同时也给出了较完整的部署与使用说明。对感兴趣的人而言,这至少意味着项目不是停留在论文阶段,想实际跑一跑试试也不算多难。
说到这里,其实没必要急着给 MAI-UI 下什么宏大的结论。
它并不能立刻改变人机交互的形态,也距离“人人可用”还有不少工程工作要做(跟豆包手机甚至是AutoGLM比其实都差得不少)。但如果把视角收紧一些,只看它试图解决的问题和采取的路径,这个项目的定位是清晰的,也相对务实。
它没有把 GUI 简化成一堆坐标,也没有把智能体想象成万能执行者,而是尝试在理解、推理和执行之间找到一个可持续的平衡点。
对于关注智能体、自动化,或者已经被重复界面操作消耗耐心的人来说,MAI-UI 至少值得被放进观察名单里。
不一定现在就用,但值得持续关注它接下来会怎么走。

我是CyberImmortal,关注我们,带你畅游AI世界!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















