事情是這樣的,上週,領投 Groq 的 Disruptive CEO 放出了消息,老黃準備吞掉自己的潛在競爭對手,同爲芯片製造商的 Groq。
而這個英偉達史上最大收購案,立刻在科技圈掀起了不小的波瀾。

大夥兒有說英偉達加強壟斷的,有分析 Groq 技術優勢的,不過討論最多的,還是老黃真被前一陣子谷歌的 TPU 給刺激到了。。。
雖然說起 Groq,各位差友應該都比較陌生。如果你覺得聽說過,那大概率是跟馬斯克家的 grok 搞混了。
Groq 的核心產品也很有意思,是一種叫 LPU( Language Processing Unit,語言處理單元 )的新型專用芯片,和 谷歌搞 AI 計算的專用芯片 TPU 放一塊兒,確實有點宛宛類卿那意思。
LPU 同樣拋棄了 GPU 的通用性,專門爲加速 AI 計算而生。

從名字上也看得出來,它甚至還要更專精一點,純純是針對語言模型設計的。
一般來講,模型訓練和推理,怎麼也得來一個顯存。比如咱們要玩個啥模型,看見說明書裏寫着,最低配置 3090,潛臺詞就是顯存沒到 24G,模型跑不起來。

畢竟大模型每計算一步,都得從存儲容器裏把參數取到計算核心,算完了再放回去。而顯存是模型參數最理想的集散中心,它離計算核心近,容量較大,參數來來回回搬運非常快。
要是沒有顯存,參數存到硬盤裏,咱就等吧,模型立刻開爬,算一個字兒都得憋半天。
即使是 TPU,後來爲了兼備模型訓練,也乖乖添加了顯存模塊。
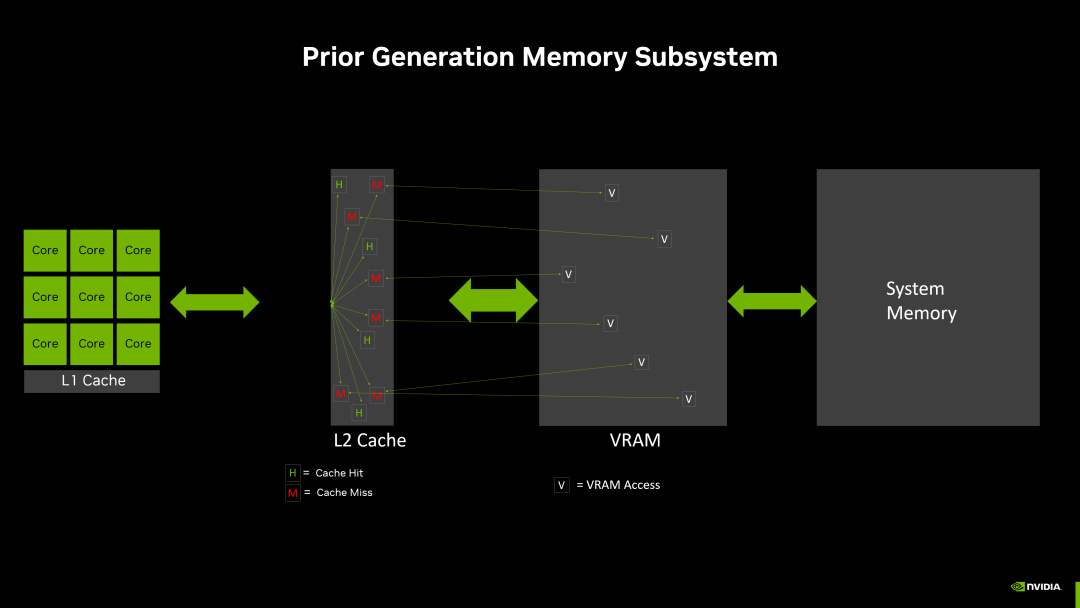
但 Jonathan Ross 不忘初心,LPU 承接第一代 TPU 的概念,只搞模型推理,完全不加顯存。
LPU 盯上了一個離計算核心更近的存儲單元 —— SRAM。問題是,受到晶體管的物理體積限制,它的存儲容量極小,每張卡只有幾十到幾百 MB,根本裝不下模型所有參數。
所以,Groq 直接暴力組裝千卡萬卡集羣,每張卡上只存模型的一小部分,也只算這一小部分,最後合體輸出。
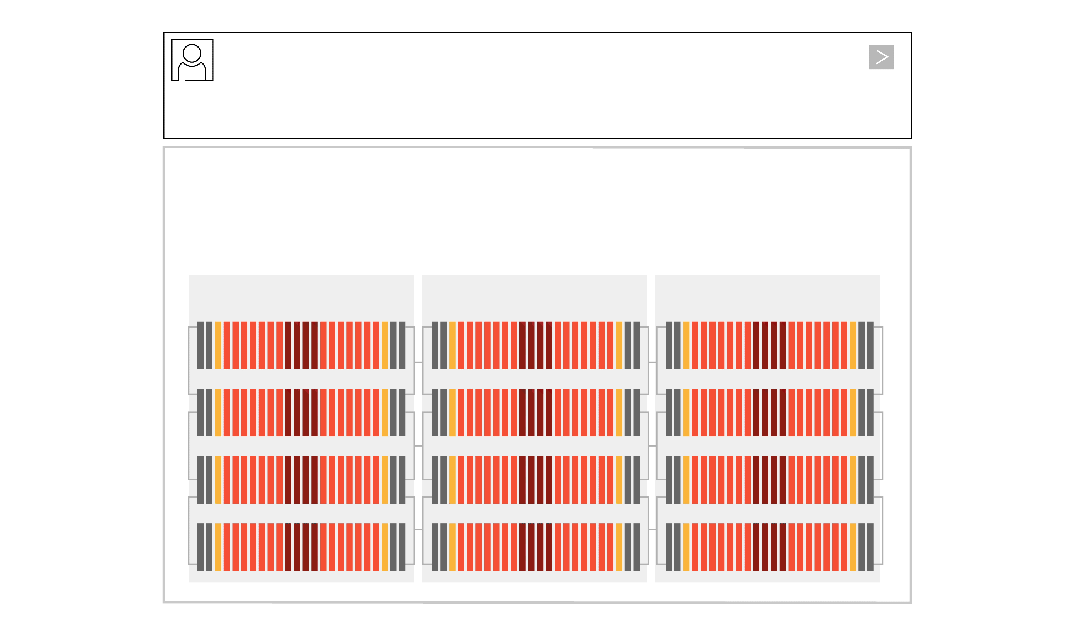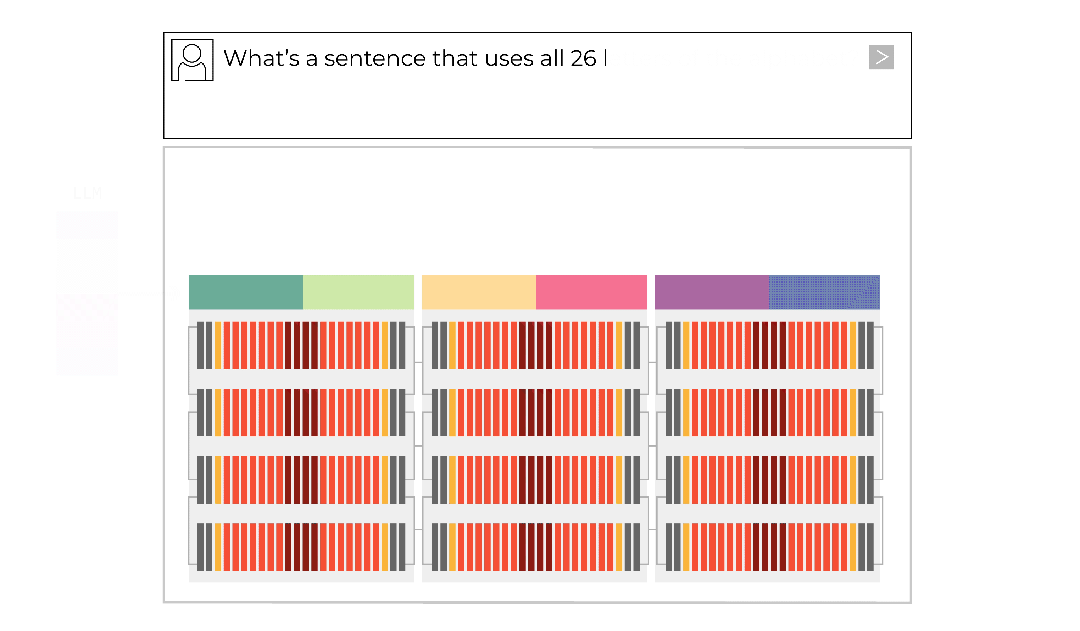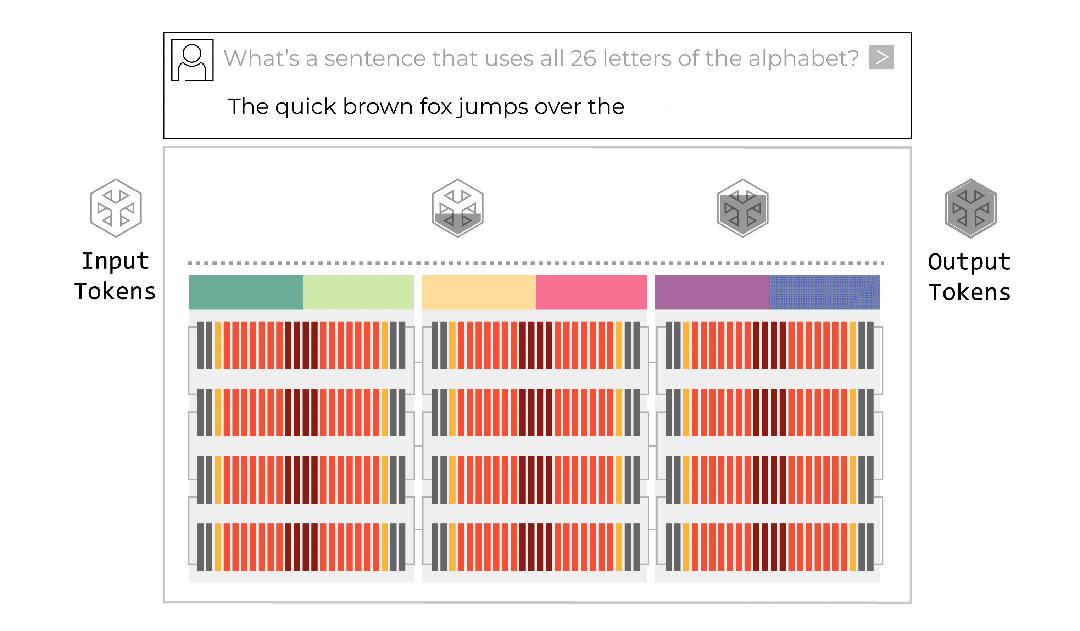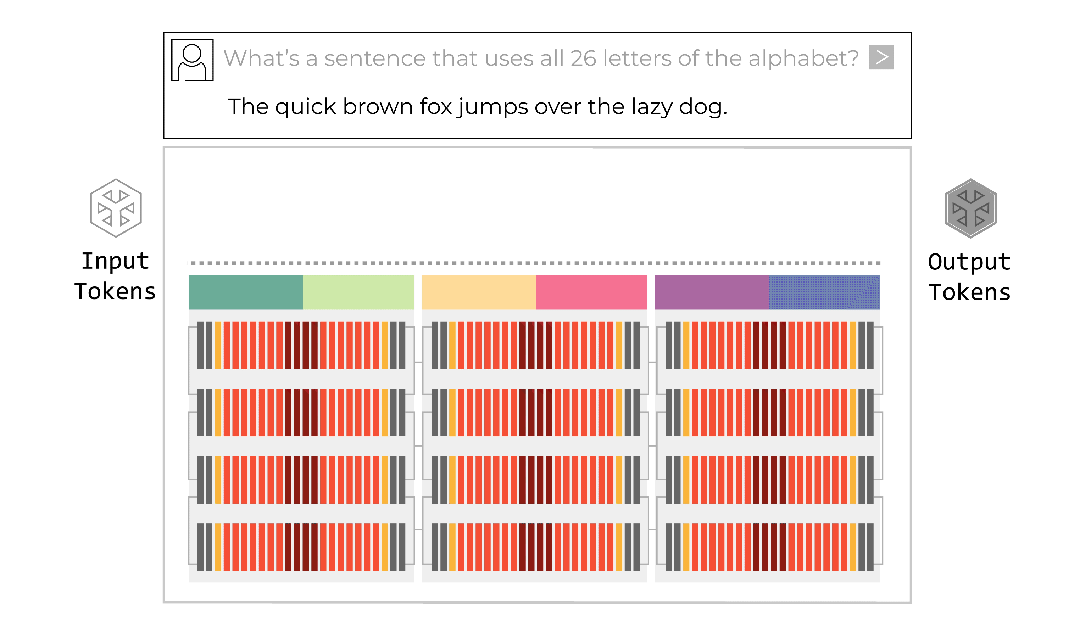
通過這種方式,LPU 的數據存取速度能達到 GPU 的 20 倍以上,模型推理快到飛起。
其實早在一年前,就有不少人覺得 Groq LPU 要對英偉達 GPU 來個大沖擊,把 LPU 和 GPU 拎出來反覆摩擦做比較。
畢竟在當時英偉達 GPU 一家獨大的時候,Groq 能比行業龍頭推理速度再快 10 倍,簡直像天神下凡。
當然,有人看好,就有人看衰。
像是前阿里副總裁賈揚清就做過一個粗略的測算,用 LPU 運營三年,它的採購成本是英偉達 H100 的 38 倍,運營成本則達到 10 倍,意思是 LPU 想替代 GPU,還差得遠呢。

但英偉達的 “ 收購 ”,可不是拋出 200 億美元,Groq 就歸我了。作爲一個已經不可能悶聲發大財的巨頭,壟斷變成了懸在英偉達脖子上的一把大刀。
他們用了一種這幾年在硅谷屢見不鮮的剝殼式收購,把 Groq 直接挖空了。
像是微軟合併 Inflection AI,亞馬遜高走 Adept 等等,都是把技術挖走了,核心人才挖沒了,留下個空殼公司,普通員工一點湯也喝不着。

所以明面上,英偉達並沒有承認收購 Groq,而是和他們簽署了一份非獨家許可協議,授權 NVIDIA 使用 Groq 的推理技術。
意思就是,這技術你也能用,我也能用,賣藝不賣身嗷。
實際呢,Groq 的核心技術給英偉達了,Groq 的首席執行官 Jonathan Ross、總裁 Sunny Madra、以及幾位專注於超高效 AI 推理芯片的核心工程師,也都被英偉達以僱傭的形式搞到手了。
彭博社今年四月發表的一篇報道就表示,目前,訓練成本佔大型雲計算公司數據中心支出的 60% 之多,但分析師預計,到 2032 年,這一比例將降至 20% 左右。
以前大夥兒不計成本買 H100 是爲了把模型訓出來,但現在,像 Groq 這樣主打又快又省的推理芯片,可能纔是大廠們以後爭搶的核心。
可以說,英偉達通過這次曲線收購,補齊了自己在非 HBM 架構上的最後一塊短板。
撰文:莫莫莫甜甜
編輯:江江 & 面線
美編:萱萱
圖片、資料來源:
Groq 官網、NVIDIA 官網
CNBC、DEV、Techspot、Bloomberg、X、Reddit、Github

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














![[6.27]夏促來襲!超多骨折!百款史低新史低這次你一定要入庫!](https://imgheybox1.max-c.com/web/bbs/2026/06/26/bfb8adfbb675422149a024f4b7064470.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)

