12 月 1 日,DeepSeek 發佈了兩款新模型 —— DeepSeek V3.2 和 DeepSeek-V3.2-Speciale。
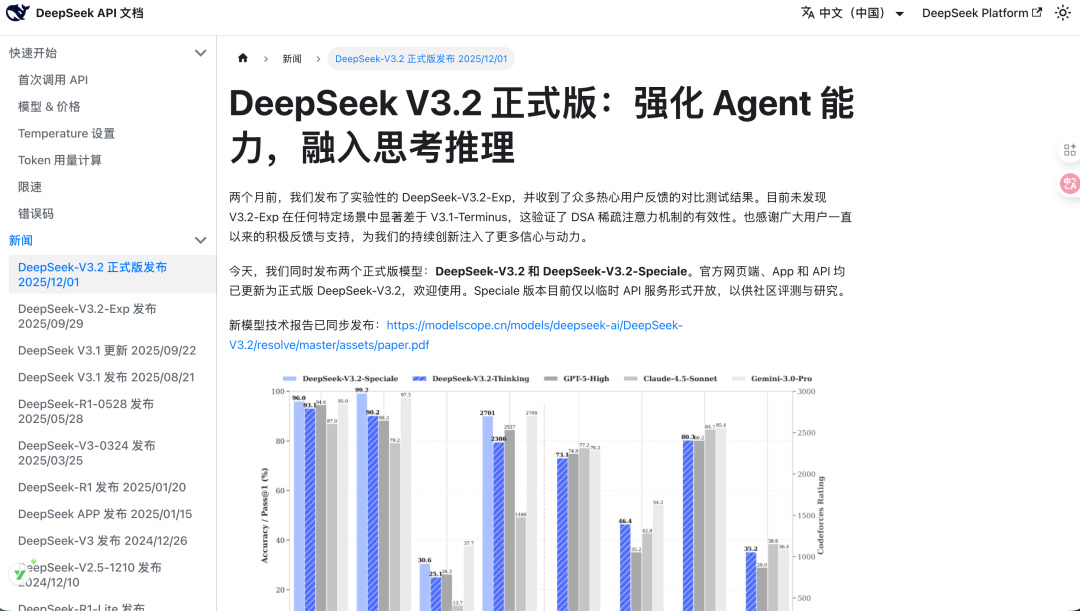
前者和 GPT-5 能打的有來有回,後面的高性能版更是直接把 GPT 爆了,開始和閉源模型天花板 —— Gemini 打了個五五開。
這是這家公司今年第九次發佈模型,雖然大家期待的 R2 還沒有來。
所以,DeepSeek 是怎麼用更小的數據,更少的顯卡,做出能和國際巨頭來抗衡的模型?
我們翻開了他們的論文,想把這件事給大家講清楚。
爲了做到這個目標,DeepSeek 又整了不少新招:
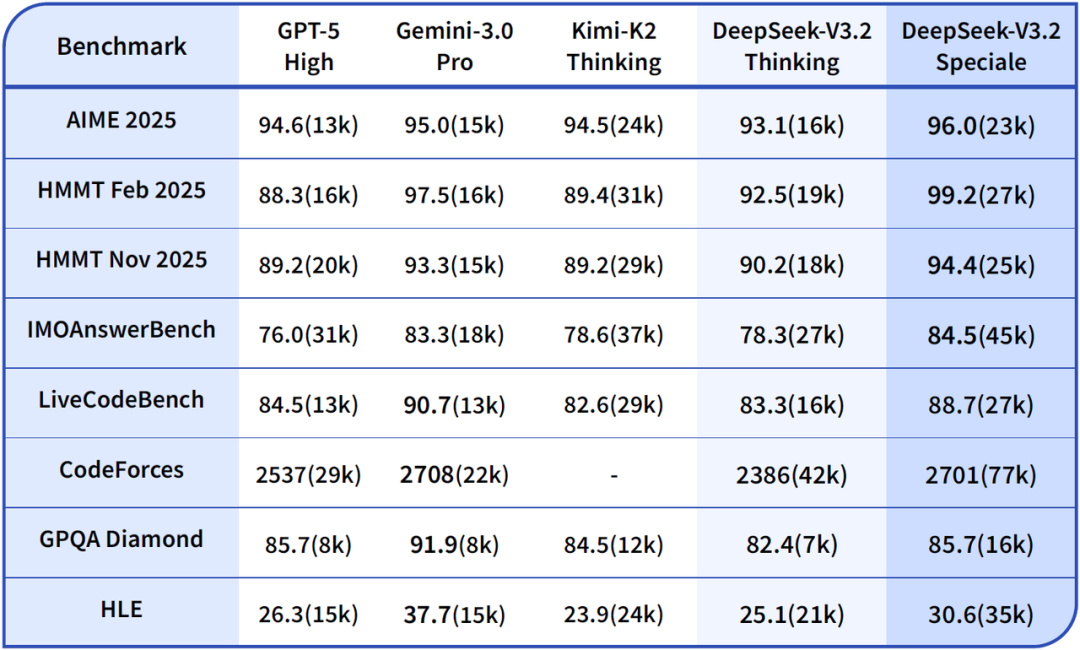
先是把咱們的老朋友 DSA —— 稀疏注意力給轉正了。

大家平時和大模型聊天的時候會發現,你在一個對話框裏聊的越多,模型就越容易胡言亂語。
甚至聊的太多了,還會直接不讓你聊了。

這是因爲大模型原生的注意力機制導致的問題,在這套老邏輯的影響下,每個 token 出來,都要和前面的每一個 token 互相算在一起做一次計算。

DeepSeek 想這樣不行啊,於是就給大模型里加了固定頁數的目錄(稀疏注意力),相當於幫模型劃重點了。
而在有了目錄之後,以後每次只需要計算這個 token 和這些目錄的關係就行了,相當於就是看書先讀目錄,看完目錄,對哪一章感興趣,再去仔細看這章的內容就好。
這樣一來,就能讓大模型讀長文的能力變的更強。
在下面這張圖裏可以看到,隨着句子越來越長,傳統的 V3.1 的推理成本是越來越高。
但是用上了稀疏注意力的 3.2 則沒什麼變化。。。
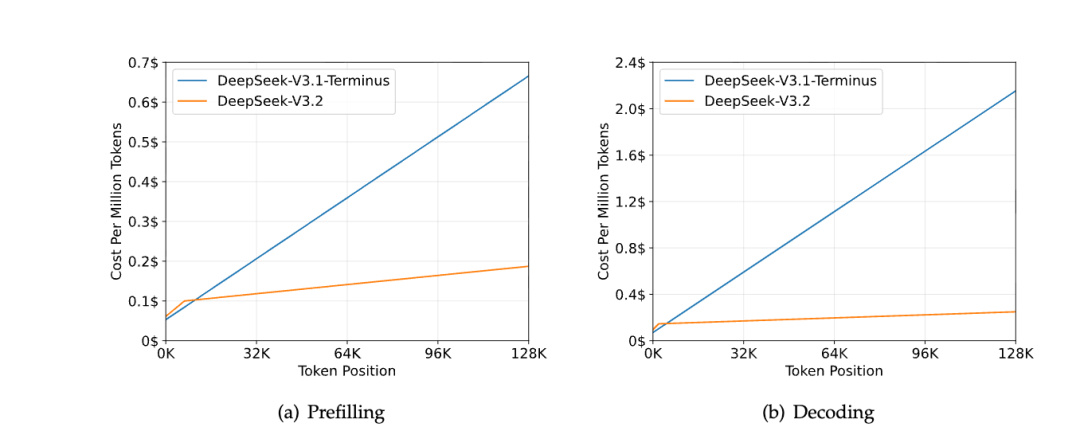
屬於是超級省錢冠軍了。
另一方面,DeepSeek 開始重視起了開源模型的後訓練工作。
前面的大規模預訓練,相當於從小學到高二,把所有課本、練習冊、卷子全過一遍,這一步大家都差不多,不管是閉源模型,還是開源模型,都在老老實實的唸書。
但到了高考衝刺階段就不一樣了,在模型的後訓練階段,閉源模型一般都會請名師,猛刷題,開始搞起各種強化學習,最後讓模型來考一個不錯的成果。
但開源模型在這塊花的心思就比較少了,按照 DeepSeek 的說法,過去的開源模型在訓練後階段計算投入普遍偏低。
這就導致這些模型可能基礎能力是已經到位的了,但就是難題刷少了,結果導致考出來的成績不太好。
同時還推出了個能思考超長時間的特殊版本 ——DeepSeek V3.2 Speciale。
這玩意的思路是這樣的:
過去的大模型因爲上下文長度有限制,所以在訓練的時候都會做一些標註懲罰的工作,如果模型深度思考的內容太長了,那就會扣分。
而到了 DeepSeek V3.2 Speciale 這兒,所以 DeepSeek 乾脆取消掉了這個扣分項,反而鼓勵模型想思考多久就思考多久,想怎麼思考就怎麼思考。
最終,讓這個全新的 DeepSeek V3.2 Speciale 成功的和前幾天爆火的 Gemini 3 打的有來有回。
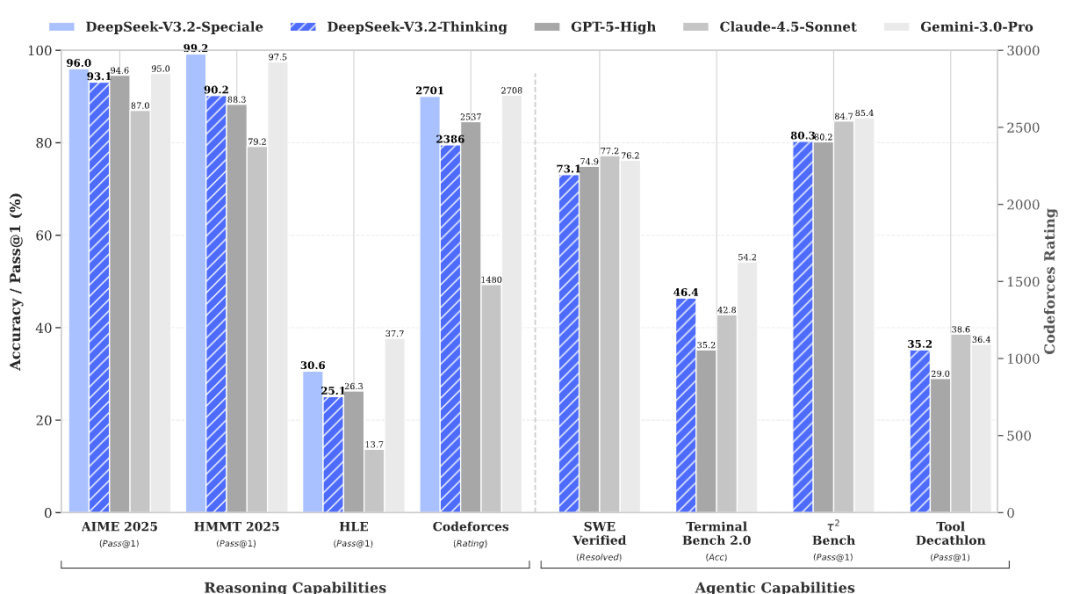
此外DeepSeek 還很重視模型在智能體方面能力。
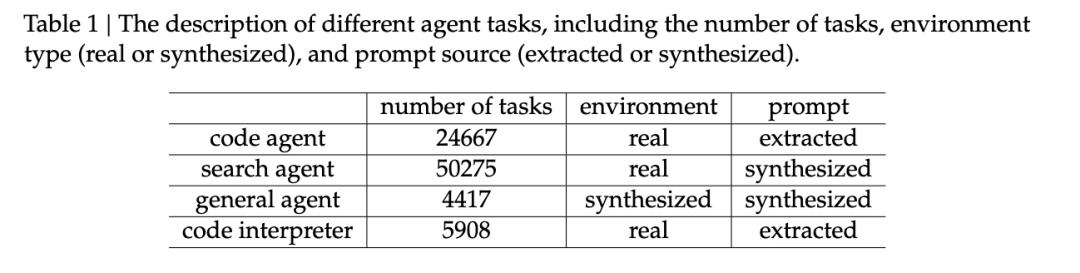
一方面,爲了提高模型的基礎能力,DeepSeek 構建了一個虛擬環境,合成了成千上萬條數據來輔助訓練。
DeepSeek-V3.2 用 24667 個真實代碼環境任務、50275 個真實搜索任務、4417 個合成通用 agent 場景、5908 個真實的代碼解釋任務做後訓練。
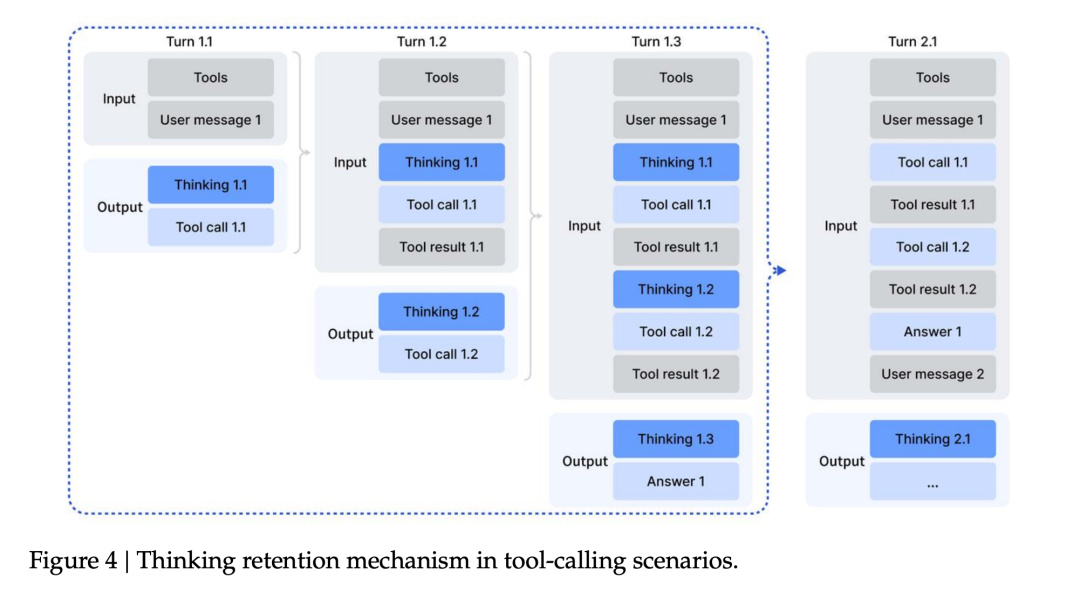
另一方面,DeepSeek 還優化了模型使用各種工具的流程。
模型一旦去調用外部工具,前面那段思考基本就算寫完收工了,等工具查完結果再回來,它往往又要重新鋪一遍思路。
這就導致一種很蠢的體驗——哪怕只是去查一下“今天幾月幾號” 這種小事,模型也會從頭開始重建整套推理鏈,非常浪費時間。。。
在 V3.2 這裏,DeepSeek 忍不了了,直接把這套邏輯推翻重做。
現在的規則變成:在一整串工具調用的過程中,模型的“思考過程”會一直保留下來,只有當用戶發來一條新的提問時,纔會重置這一輪推理;而工具的調用記錄和結果,會像聊天記錄一樣一直留在上下文裏。
通過這修改模型架構,重視後訓練,強化 Agent 能力的三板斧,DeepSeek 才終於讓自己的新模型,有了能和世界頂尖開源模型再次一戰的能力。
當然,即使做了這麼多改進,DeepSeek 的表現也算不上完美。
但託尼最喜歡 DeepSeek 的一點,就是他們願意承認自己的不足。
而且還會直接在論文裏寫出來。
比如這次論文就提到了,這次的 DeepSeek V3.2 Speciale 雖然能和谷歌的 Gemini 3 Pro 來打的五五開。

但是要回答相同的問題,DeepSeek 需要花費更多的 token。
題目是:
蜂鳥類在足形目中獨特地擁有雙側成對的橢圓形骨,這是一種嵌入在膨脹的十字翼腱膜的尾狀骨中,嵌入壓低多粒骨的尾狀骨。這塊籽骨支撐着多少對對腱?請用數字回答。
結果發現 Gemini 只要 4972 個 Tokens 就能把問題給答出來。

而到了 DeepSeek 這邊,則用了 8077 個 Tokens 才把問題給搞明白。

光看用量的話,DeepSeek 的的 Tokens 消耗量高了快六成,確實是有不小的差距。
但是話又說回來了。
DeepSeek 雖然消耗的 token 多,但是人家價格便宜啊。。。
還是剛纔那個問題,我回頭仔細看了眼賬單。
DeepSeek 8000 多個 tokens,花了我 0.0032 美元。
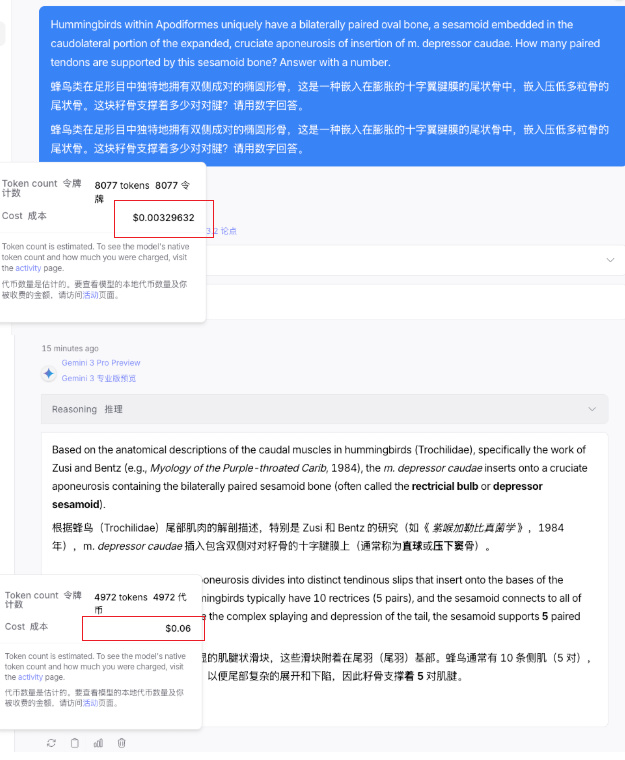
從這個角度上來看,怎麼感覺還是 DeepSeek 更香一些。。。
最後,讓我們回到論文的開頭。
正如 DeepSeek 所言,最近半年來,開源模型和閉源模型的差距正在不斷加大。

但他們還是用自己的方式,在不斷追趕這份差距。
而 DeepSeek 的各種節省算力,節約數據的操作,其實讓我想到了上個月,一場關於 Ilya Sutskever 的訪談。

AlexNet只用了兩塊GPU。Transformer剛出現時的實驗規模,大多在8~64塊GPU範圍內。按今天的標準看,那甚至相當於幾塊GPU的規模,ResNet也一樣。沒有哪篇論文靠龐大的集羣才能完成。
比起算力的堆砌,對算法的研究也一樣重要。
這正是 DeepSeek 在做的事情。
從 V2 的 MoE,到 V3 的多頭潛在注意力(MLA),再到如今 DeepSeek Math V2 的自驗證機制,V3.2 的稀疏注意力(DSA)。
而是在想辦法,如何用有限的數據,來堆積出更多的智能。
巧婦狂作無米之炊
所以,R2 什麼時候來呢?
撰文
:早起
編輯
:江江 & 面線
美編
:
煥妍
圖片、資料來源
:DeepSeek 官網、論文


更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















