【前言】
大家在使用PDF資料時應該都有過類似的經歷吧:文件裏的文字是圖片類型的,不能自由複製和編輯,或者在進行PDF轉Word時出現文檔格式錯亂的問題,今天這款OCR工具就能幫你解決這個問題。
Umi-OCR是免費開源的離線OCR軟件,支持Windows10/11,可以批量識別普通圖片並識別文字內容導出,以及還有支持忽略指定區域的特殊功能,例如可以屏蔽掉視頻右上角水印和遊戲的 UI 內容。含中英識別庫,支持多國語言擴展包。
【軟件特點】
免費:本項目所有代碼開源,完全免費。
方便:解壓即用,離線運行,無需網絡。
批量:可批量導入處理圖片,結果保存到本地多種格式文件。也可以即時截屏識別。
高效:採用識別引擎。只要電腦性能足夠,通常比在線OCR服務更快。
精準:默認使用PPOCR-v3模型庫。除了能準確辨認常規文字,對手寫、方向不正、雜亂背景等情景也有不錯的識別率。可設置忽略區域排除水印、設置文塊後處理合併排版段落,得到規整的文本。
【軟件截圖】

軟件截圖
【功能展示】

截圖OCR
截圖OCR
打開這一頁後,就可以用快捷鍵喚起截圖,識別圖中的文字。比QQ的識別屏幕好用很多,準確率也高很多。左側的圖片預覽欄,可直接用鼠標劃選複製。右側的識別記錄欄,可以編輯文字,允許劃選多個記錄複製。也支持在別處複製圖片,粘貼到Umi-OCR進行識別。
文本後處理

文本後處理
可以整理OCR結果的排版和順序,使文本更適合閱讀和使用。預設方案:
多欄-按自然段換行:適合大部分情景,自動識別多欄佈局,按自然段規則進行換行。
多欄-總是換行:每段語句都進行換行。
多欄-無換行:強制將所有語句合併到同一行。
單欄-按自然段換行/總是換行/無換行:與上述類似,不過 不區分多欄佈局。
單欄-保留縮進:適用於解析代碼截圖,保留行首縮進和行中空格。
不做處理:OCR引擎的原始輸出,默認每段語句都進行換行。
上述方案,均能自動處理橫排和豎排(從右到左)的排版。(豎排文字還需要OCR引擎本身支持)
批量OCR
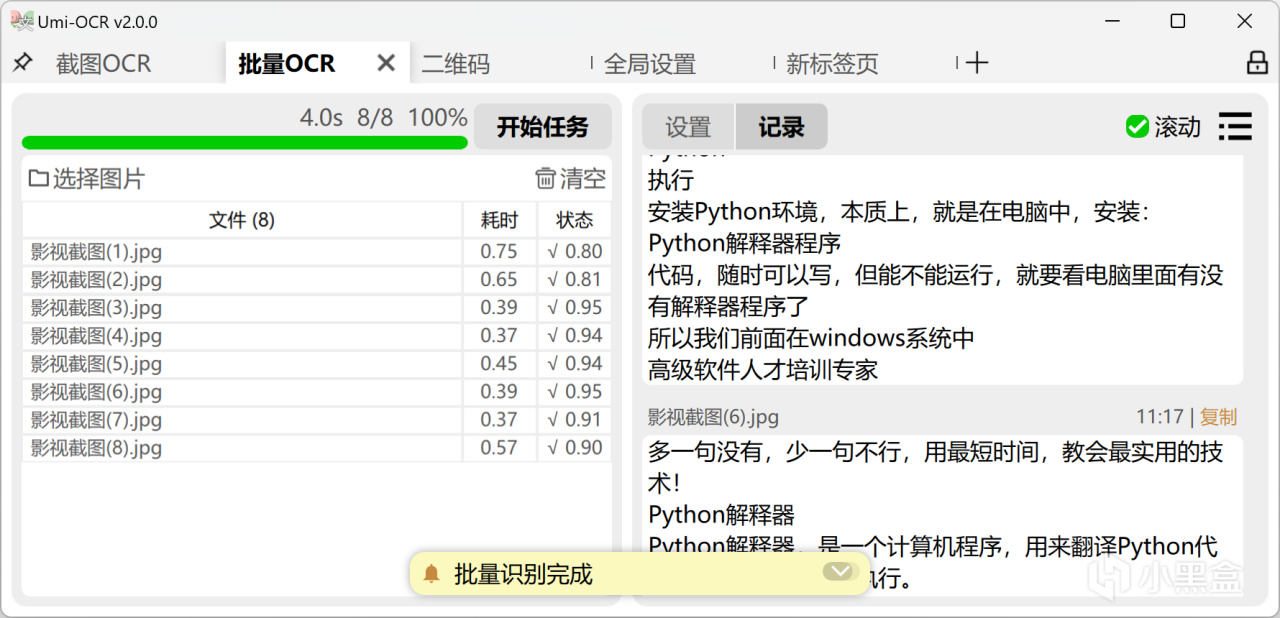
批量OCR
支持格式:jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff。
保存識別結果的支持格式:txt, jsonl, md, csv(Excel)。
與截圖OCR一樣,支持文本後處理功能,整理OCR文本的排版和順序。
沒有數量上限,可一次性導入幾百張圖片進行任務。
支持任務完成後自動關機/待機。
如果要識別像素超大的長圖或大圖,請調整:頁面的設置→文字識別→限制圖像邊長→【調高數值】。
擁有特殊功能 忽略區域 。
以上只是列舉了一些比較常用的功能,軟件很有很多實用的功能,真的強烈推薦!
【下載地址】
「Umi-OCR PDF一鍵識別文字」
https://pan.quark.cn/s/c67ffc441c25
長按可以複製
感謝大家的點贊和收藏支持,我會持續爲大家推薦好用好玩實用的軟件分享,歡迎關注我。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















